【新智元导读】自曝996作息的OpenAI研究员Jason Wei表示,Sora代表着视频生成的GPT-2时刻。竞争的关键,就是算力和数据了。国内有可能成功「复刻」Sora吗?华人团队的这份37页技术报告,或许能给我们一些启发。
今天,这张图在AI社区热转。
它列举了一众文生视频模型的诞生时间、架构和作者机构。
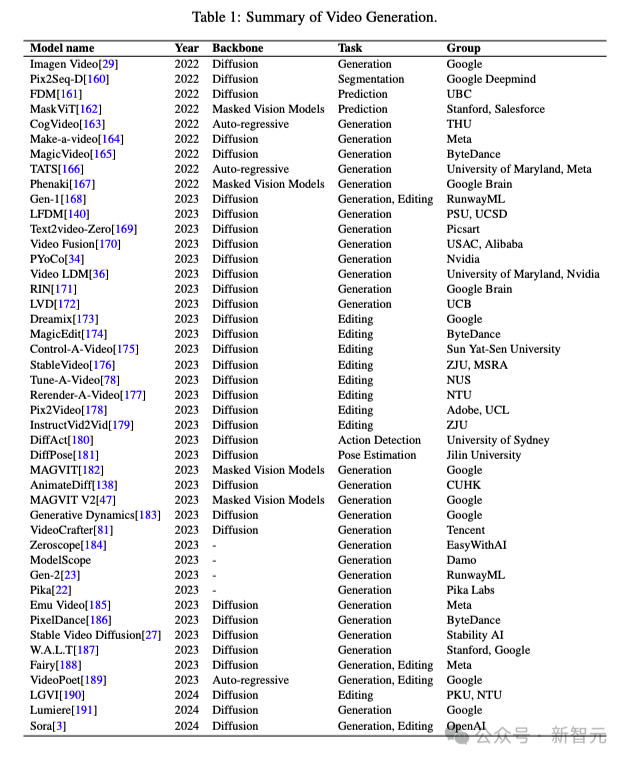
毫不意外,谷歌依然是视频模型开山之作的作者。不过如今AI视频的聚光灯,全被Sora抢去了。

同时,自曝996作息时间表的OpenAI研究员Jason Wei表示——
「Sora是一个里程碑,代表着视频生成的GPT-2时刻。」
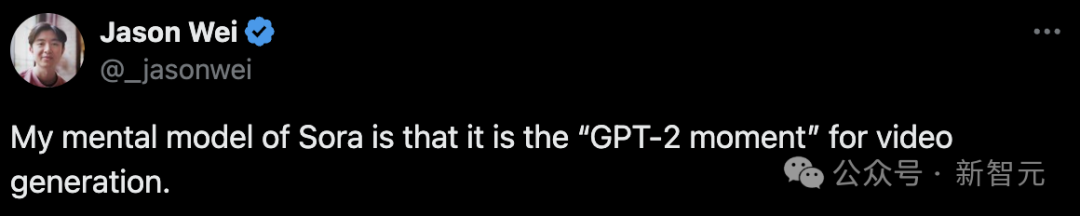
对于文字生成领域,GPT-2无疑是一个分水岭。2018年GPT-2的推出,标志着能够生成连贯、语法正确的文本段落的新时代。
当然,GPT-2也难以完成一篇完整无误的文章,会出现逻辑不一致或捏造事实的情况。但是,它为后续的模型发展奠定了基础。
在不到五年内,GPT-4已经能够执行串联思维这种复杂任务,或者写出一篇长文章,过程中并不会捏造事实。
而今天,Sora已经也意味着这样的时刻。

它能创作出既有艺术感又逼真的短视频。虽然还不能创作出长达40分钟的电视剧,但角色的一致性和故事性已经非常引人入胜!
Jason Wei相信,在Sora以及未来的视频生成模型中,保持长期一致性、近乎完美的逼真度、创作有深度的故事情节这些能力,都会逐渐成型。

好莱坞知名导演Tyler Perry在看到Sora生成的视频后,大为震惊,决定撤掉自己亚特兰大工作室耗资8亿美元的扩建计划。
因为以后拍摄的大片中,可能不需要找取景地,或者搭建实景了。

所以,Sora会颠覆电影产业吗?Jason Wei表示,它就像现在的GPT-4一样,可以作为一种辅助工具提升作品质量,所以距离专业的电影制作还有一段距离。
而现在,视频和文本的最大区别就是,前者的信息密度较低,所以在视频推理等技能的学习上,就会需要大量的算力和数据。
因此,高质量视频数据的竞争会非常激烈!就像现在各家都在争抢高质量的文本数据集。


另外,将视频与其他信息模式结合起来,作为学习过程的辅助信息将极为关键。
并且在未来,拥有视频处理经验的AI研究人员会变得非常抢手!不过,他们也需要像传统的自然语言处理研究者那样,适应新的技术发展趋势。
没有中间物理模型,但已具备革命性
OpenAI的TikTok账号,还在不断放出Sora的新作品。
Sora离好莱坞大片距离还有多远?让我们来看看这个电影中经常出现的场景——瓢泼大雨中,一辆车在夜色中飞速穿过城市街道。
A super car driving through city streets at night with heavy rain everywhere, shot from behind the car as it drives
再比如,Sora生成的工地上,叉车、挖掘机、脚手架和建筑工人们也都十分逼真。
并且,它还拍出了微型摄影的效果,让一切都看起来像一个缩影。
AI公司创始人swyx总结说,根本原因还是因为Sora没有中间物理模型,这完全是LeCun所提世界模型的对立面。不过,它依然为电影制作流程创造了质的飞跃,大大降低了成本。虽然Runway可以实现类似功能,但Sora将一切都提升到了一个新的水平。以下是Sora和Pika、Runway Gen-2、AnimateDiff和LeonardoAI的比较。人人都能拍自己的电影
在不久的将来,或许我们每个人都可以在几分钟内生成自己的电影了。比如,我们可以用ChatGPT帮忙写出剧本,然后用Sora进行文字转视频。在未来,Sora一定会突破60s的时间限制。
想象一下,在你的脑海里拍出一部从未存在过的电影,是什么感觉或者,我们可以用Dall-E或者Midjourney生成图像,然后用Sora生成视频。D-ID可以让角色的嘴部、身体动作和所说的台词保持一致。
ElevenLabs,可以为视频中的角色配音,增强视频的情感冲击力,创造视觉和听觉叙事的无缝融合。去年ChatGPT发布后,一下子涌现出千模大战的盛况。而这次Sora距离诞生已有半个月了,各家公司仍然毫无动静。恰恰在最近,华人团队也发布了非常详细的Sora分析报告,或许能给这个问题一些启发。最近,来自理海大学的华人团队和微软副总裁高剑峰博士,联合发布了一篇长达37页的分析论文。通过分析公开的技术报告和对模型的逆向工程研究,全面审视了Sora的开发背景、所依赖的技术、其在各行业的应用前景、目前面临的挑战,以及文本转视频技术的未来趋势。其中,论文主要针对Sora的开发历程和构建这一「虚拟世界模拟器」的关键技术进行了研究,并深入探讨了Sora在电影制作、教育、营销等领域的应用潜力及其可能带来的影响。
论文地址:https://arxiv.org/abs/2402.17177
项目地址:https://github.com/lichao-sun/SoraReview如图2所示,Sora能够表现出精准地理解和执行复杂人类指令的能力。而在制作能够细致展现运动和互动的长视频方面,Sora也取得了长足的进展,突破了以往视频生成技术在视频长度和视觉表现上的限制。这种能力标志着AI创意工具的重大飞跃,使得用户能将文字叙述转化为生动的视觉故事。研究人员认为,Sora之所以能达到这种高水平,不仅是因为它能处理用户输入的文本,还因为它能理解场景中各个元素复杂的相互关系。如图3所示,过去十年里,生成式计算机视觉(CV)技术的发展路径十分多样,尤其是在Transformer架构成功应用于自然语言处理(NLP)之后,变化显著。研究人员通过将Transformer架构与视觉组件相结合,推动了其在视觉任务中的应用,比如开创性的视觉Transformer(ViT)和Swin Transformer。与此同时,扩散模型在图像与视频生成领域也取得了突破,它们通过U-Net技术将噪声转化为图像,展示了数学上的创新方法。从2021年开始,AI领域的研究重点,便来到了那些能够理解人类指令的语言和视觉生成模型,即多模态模型。随着ChatGPT的发布,我们在2023年看到了诸如Stable Diffusion、Midjourney、DALL-E 3等商业文本到图像产品的涌现。然而,由于视频本身具有的时间复杂性,目前大多数生成工具仅能制作几秒钟的短视频。在这一背景下,Sora的出现象征着一个重大突破——它是第一个能够根据人类指令生成长达一分钟视频的模型,其意义可与ChatGPT在NLP领域的影响相媲美。如图4所示,Sora的核心是一个可以灵活地处理不同维度数据的Diffusion Transformer,其主要由三个部分组成:1. 首先,时空压缩器会把原始视频转映射到潜空间中。2. 接着,视觉Transformer(ViT)模型会对已经被分词的潜表征进行处理,并输出去除噪声后的潜表征。3. 最后,一个与CLIP模型类似的系统根据用户的指令(已经通过大语言模型进行了增强)和潜视觉提示,引导扩散模型生成具有特定风格或主题的视频。在经过多次去噪处理之后,会得到生成视频的潜表征,然后通过相应的解码器映射回像素空间。数据预处理
- 可变的持续时间、分辨率和高宽比
如图5所示,Sora的一大特色是它能够处理、理解并生成各种大小的视频和图片,从宽屏的1920x1080p视频到竖屏的1080x1920p视频,应有尽有。如图6所示,与那些仅在统一裁剪的正方形视频上训练的模型相比,Sora制作的视频展示了更好的画面布局,确保视频场景中的主体被完整捕捉,避免了因正方形裁剪而造成的画面有时被截断的问题。Sora对视频和图片特征的精细理解和保留,在生成模型领域是一个重大的进步。它不仅展现了生成更真实和吸引人的视频的可能性,还突出了训练数据的多样性对生成式AI取得高质量结果的重要性。- 统一的视觉表征
为了有效处理各种各样的视觉输入,比如不同长度、清晰度和画面比例的图片和视频,一个重要的方法是把这些视觉数据转换为统一的表征。这样做还有利于对生成模型进行大规模的训练。具体来说,Sora首先将视频压缩到「低维潜空间」,然后再将表征分解成「时空patches」。- 视频压缩网络
如图7所示,Sora的视频压缩网络(或视觉编码器)的目标是降低输入数据的维度,并输出经过时空压缩的潜表征。技术报告中的参考文献显示,这种压缩技术是VAE或矢量量化-VAE(VQ-VAE)基础上的。然而,根据报告,如果不进行图像的大小调整和裁剪,VAE很难将不同尺寸的视觉数据映射到一个统一且大小固定的潜空间中。针对这个问题,研究人员探讨了两种可能的技术实现方案:这一过程需要将视频帧转换成固定大小的patches,与ViT和MAE模型采用的方法相似(如图8所示),然后再将其编码到潜空间中。通过这种方式,模型可以高效地处理具有不同分辨率和宽高比的视频,因为它能通过分析这些patches来理解整个视频帧的内容。接下来,这些空间Token会按时间顺序排列,形成空间-时间潜表征。这种技术包含了视频数据的空间和时间维度,不仅考虑了视频画面的静态细节,还关注了画面之间的运动和变化,从而全面捕捉视频的动态特性。利用三维卷积是实现这种整合的直接而有效的方法- 潜空间patches
在压缩网络部分还有一个关键问题:在将patches送入Diffusion Transformer的输入层之前,如何处理潜空间维度的变化(即不同视频类型的潜特征块或patches的数量)。根据Sora的技术报告和相应的参考文献,patch n' pack(PNP)很可能是一种解决方案。如图10所示,PNP将来自不同图像的多个patches打包在一个序列中。在这里,patch化和token嵌入步骤需要在压缩网络中完成,但Sora可能会像Diffusion Transformer那样,进一步将潜在的patch化为Transformer token。- Diffusion Transformer
建模
- 图像Diffusion Transformer
DiT和U-ViT是最早将视觉Transformers用于潜在扩散模型的工作之一。与ViT一样,DiT也采用多头自注意力层和点卷积前馈网络,交错一些层归一化和缩放层。此外,DiT还通过自适应层归一化(AdaLN)并增加了一个额外的MLP层进行零初始化,这样初始化每个残差块为恒等函数,从而极大地稳定了训练过程。U-ViT将所有输入,包括时间、条件和噪声图像patches,都视为token,并提出了浅层和深层Transformer层之间的长跳跃连接。结果表明,U-ViT在图像和文本到图像生成中取得了破纪录的FID分数。类似于掩码自编码器(MAE)的方法,掩码扩散Transformer(MDT)也在扩散过程中加入了掩码潜模型,有效提高了对图像中不同对象部分之间上下文关系的学习能力。如图12所示,MDT会在训练阶段使用侧插值进行额外的掩码token重建任务,以提高训练效率,并学习强大的上下文感知位置嵌入进行推理。与DiT相比,MDT实现了更好的性能和更快的学习速度。在另一项创新工作中,Diffusion Vision Transformers(DiffiT)采用了时间依赖的自注意力(TMSA)模块来对采样时间步骤上的动态去噪行为进行建模。此外,DiffiT还采用了两种混合分层架构,分别在像素空间和潜空间中进行高效去噪,并在各种生成任务中实现了新的SOTA。- 视频Diffusion Transformer
由于视频的时空特性,在这一领域应用DiT所面临的主要挑战是:(1)如何从空间和时间上将视频压缩到潜空间,以实现高效去噪;(2)如何将压缩潜空间转换为patches,并将其输入到Transformer中;(3)如何处理长距离的时空依赖性,并确保内容的一致性。Imagen Video是谷歌研究院开发的文本到视频生成系统,它利用级联扩散模型(由7个子模型组成,分别执行文本条件视频生成、空间超分辨率和时间超分辨率)将文本提示转化为高清视频。如图13所示,首先,冻结的T5文本编码器会根据输入的文本提示生成上下文嵌入。随后,嵌入信息被注入基础模型,用于生成低分辨率视频,然后通过级联扩散模型对其进行细化,以提高分辨率。Blattmann等人提出了一种创新方法,可以将2D潜扩散模型(Latent Diffusion Model, LDM)转换为视频潜扩散模型(Video Latent Diffusion Model, Video LDM)。语言指令跟随
为了提高文本到视频模型跟随文本指令的能力,Sora采用了与DALL-E 3类似的方法。该方法涉及训练一个描述性字幕生成模型,并利用该模型生成的数据进一步微调。通过这种指令调优,Sora能够满足用户的各种要求,确保对指令中的细节给予精确的关注,进而生成的视频能够满足用户的需求。提示工程
- 文本提示
文本提示对于指导Sora等文本到视频模型,制作既具有视觉冲击力,又能精确满足用户创建视频需求至关重要。这就需要制作详细的说明来指导模型,以效弥补人类创造力与AI执行能力之间的差距。最近研究工作,如VoP、Make-A-Video和Tune-A-Video等,都展示了提示工程如何利用模型的NLP能力来解码复杂指令,并将其呈现为连贯、生动和高质量的视频叙事。如图15所示经典Sora演示,「一个时髦的女人走在霓虹灯闪烁的东京街头...... 」提示中,包含了人物的动作、设定、角色出场,甚至是所期望的情绪,以及场景氛围。就是这样一个精心制作的文本提示,它确保Sora生成的视频与预期的视觉效果非常吻合。提示工程的质量取决于对词语的精心选择、所提供细节的具体性,以及对其对模型输出影响的理解。- 图像提示
图像提示就是要给生成的视频内容和其他元素(如人物、场景和情绪),提供一个视觉锚点。此外,文字提示还可以指示模型将这些元素动画化,例如,添加动作、互动和叙事进展等层次,使静态图像栩栩如生。通过使用图像提示,Sora可以利用视觉和文本信息将静态图像转换成动态、由叙事驱动的视频。在图16中,展示了AI生成的视频「一只头戴贝雷帽、身穿高领毛衣的柴犬」、「一个独特的怪物家族」、「一朵云组成了SORA一词」,以及 「冲浪者在一座历史悠久的大厅内乘着巨浪」。这些例子展示了通过DALL-E生成的图像提示Sora可以实现的功能。- 视频提示
最近的研究,如Fast-Vid2Vid表明,好的视频提示需要具体,且灵活。这样既能确保模型在特定目标(如特定物体和视觉主题的描述)上获得明确的指导,又能在最终输出中富有想象力的变化。例如,在视频扩展任务中,提示可以指定扩展的方向(时间向前或向后)和背景或主题。在图17(a)中,视频提示指示Sora向后延伸一段视频,以探索原始起点的事件。(b)所示,在通过视频提示执行视频到视频的编辑时,模型需要清楚地了解所需的转换,例如改变视频的风格、场景或氛围,或改变灯光或情绪等微妙的方面。(c)中,提示指示Sora连接视频,同时确保视频中不同场景中的物体之间平滑过渡。
最后,研究团队还针对Sora可能在电影、教育、游戏、医疗保健和机器人领域产生的影响做了预测。随着以Sora为代表的视频扩散模型成为前沿技术,其在不同研究领域和行业的应用正在迅速加速。这项技术的影响远远超出了单纯的视频创作,为从自动内容生成到复杂决策过程等任务提供了变革潜力。电影
视频生成技术的出现预示着电影制作进入了一个新时代,用简单的文本中自主制作电影的梦想正在变为现实。研究人员已经涉足电影生成领域,将视频生成模型扩展到电影创作中。比如使用MovieFactory,利用扩散模型从ChatGPT制作的脚本中生成电影风格的视频,整个工作流已经跑通了。MobileVidFactory只需用户提供简单的文本,就能自动生成垂直移动视频。而Sora能够毫不费力地让用户生成效果非常炸裂的电影片段,标志着人人都能制作电影的时刻来临了。这会大大降低了电影行业的准入门槛,并为电影制作引入了一个新的维度,将传统的故事讲述方式与人工智能驱动的创造力融为一体。这些AI的影响不仅仅是让电影制作变得简单,还有可能重塑电影制作的格局,使其在面对不断变化的观众喜好和发行渠道时,变得更加容易获得,用途更加广泛。机器人
正是因为大模型的爆发,再加上视频模型的迭代升级,让机器人进入了一个新时代——尤其,视频扩散模型释放了机器人新能力,使其能够与环境互动,并以前所未有的复杂度和精确度执行任务。将web-scale扩散模型引入机器人技术,展示了利用大规模LLM增强机器人视觉和理解能力的潜力。比如,在DALL-E加持下的机器人,能够准确摆好餐盘。另一种视频预测新技术——潜在扩散模型(Latent diffusion model。它可以通过语言指导,让机器人能够通过预测视频中的动作结果,来理解和执行任务。此外,机器人研究对环境模拟的依赖,可以通过视频扩散模型——能创建高度逼真的视频序列来解决。这样一来,就能为机器人生成多样化的训练场景,打破真实世界数据匮乏所带来的限制。研究人员相信,将Sora等技术整合到机器人领域有望取得突破性发展。利用Sora的强大功能,未来的机器人技术将取得前所未有的进步,机器人可以无缝导航并与周围环境进行互动。另外,对于游戏、教育、医疗保健等行业,AI视频模型也将为此带来深刻的变革。最后,好消息是,Sora现在虽然还没有开放功能,但我们可以申请红队测试。从申请表中可以看出,OpenAI正在寻找以下认知科学、化学、生物、物理、计算机、经济学等领域的专家。https://twitter.com/_jasonwei/status/1762930762180161795https://arxiv.org/abs/2402.17177