【新智元导读】以后的爆款歌曲可能要被AI承包了!最近,AI初创公司Suno震撼推出V3音乐生成模型,惊艳了全世界。只需几秒,即可生成2分钟动听的音频。网友纷纷表示:音乐的ChatGPT时刻来临!
「人类大概很快就会进入,只听自己用AI做曲子的时代」!

最近,AI初创公司Suno AI重磅推出了第一款可制作「广播级」的音乐生成模型——V3,一时间在网上掀起轩然大波。
仅用几秒的时间,V3便可以创作出2分钟的完整歌曲。
为了激发人们的创作灵感,Suno v3还新增了更丰富的音乐风格和流派选项,比如古典音乐、爵士乐、Hiphop、电子等新潮曲风。
最重要的是,现在已经向所有用户免费开放!

网友们纷纷上线创作,各种AI生成的歌曲简直让人「颅内高潮」。
在Suno主页中,有一个AI生成歌曲的排行榜,其中排名第一的是C-A-P-Y-B-A-R-A、第二首是Cyberpunk Starter,第三首是中文版的「水调歌头」。
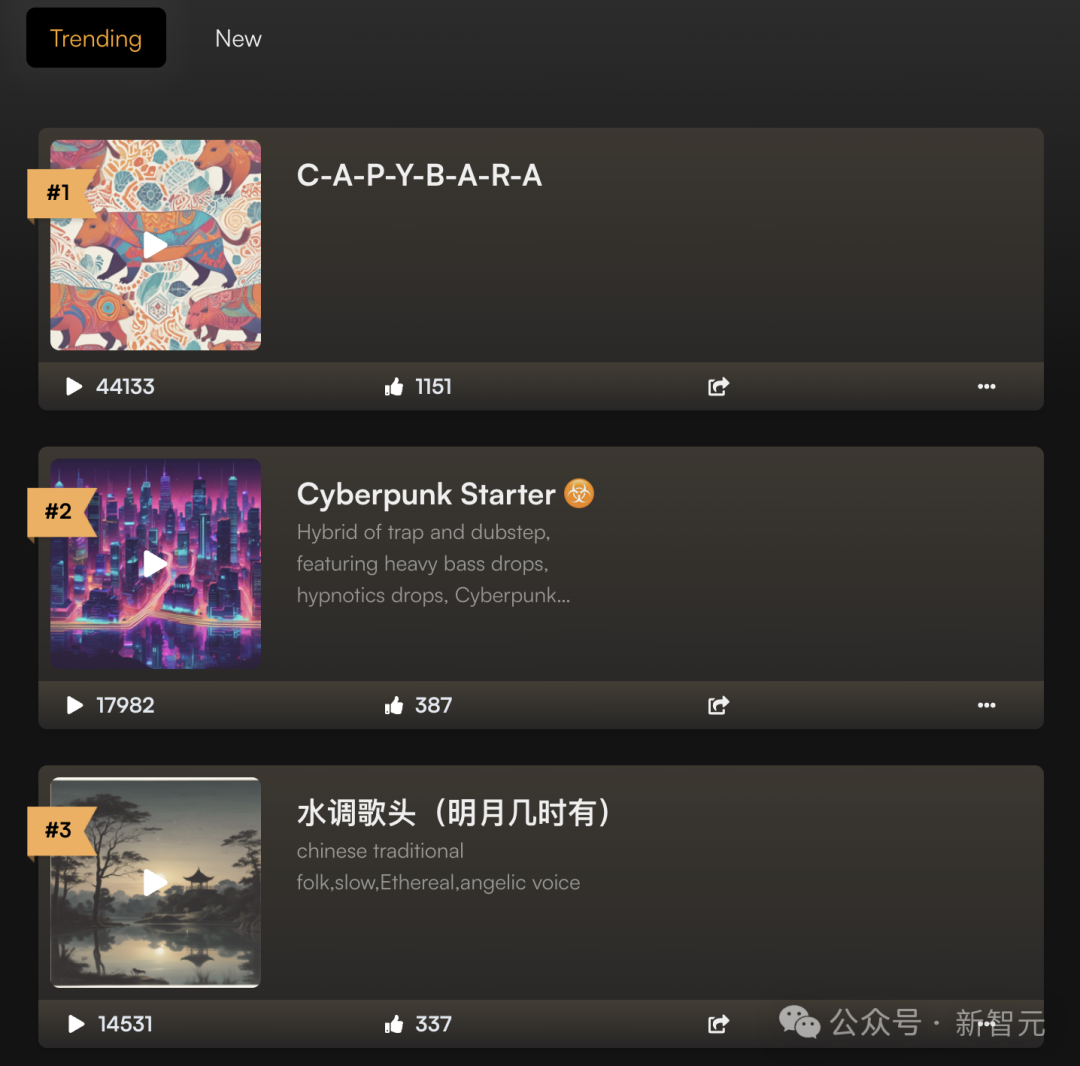
接下来,听一下这首「水调歌头·明月几时有」,唱出了中国古典美。
还有这首现代感的音乐「著了魔」,听完真的有种恋爱的赶脚。再来一首英文歌曲Woods and Wonder。有人表示,「简直离了大谱!Suno AI V3的效果感觉秒杀一大片唱作歌手了,以后还会有原创吗」?Suno官方称,V4已经在开发中,并将在未来推出一些全新的的功能。就在这几天,外媒爆料OpenAI正进军好莱坞,与电影制片人、导演建立合作关系。而此前,就连好莱坞大导Tyler Perry直言,自己在看完Sora制作的视频后,直接搁置了自己影视工作室8亿美元的扩建计划!现在,除了电影制作领域,音乐行业也即将被AI攻陷了。
Suno V3诞生后,众多网友纷纷表示,自己只想听AI写的歌。网友「向阳乔木」让Claude 3写歌词,然后让Suno V3配乐。给Claude 3输入提示,「一首敲击金属风格,讲古战场厮杀残酷」。不得不称赞,Claude 30 Opus真的非常强大,看完歌词那种战场画面感出来了。还有网友HylaruCoder填入了《东风破》的歌词。国外网友做了一个AI工具大联动,Midjourney生图、Runway让其动起来,最后再让Suno配乐。再来听一首日语版的AI歌曲,pika还为其配上了视频,绝绝子!开发者Leeoxiang用「将近酒」生成了一首歌,并感慨道,「要是有这么好听的《将近酒》小时候背唐诗就不会这么痛苦了」。Perplexity AI的首席执行官表示,这是下一个AI独角兽。持怀疑态度的人会说这是个加油站。客观事实是惊人的迭代速度、声音和音质,以及看到我自己越来越多地使用Suno而不是Spotify的习惯。网友Yangyi总结了Suno从9月30秒音频生成到现在的2分钟,半年的时间AI发生了翻天覆地的变化。
在Suno想要创造一个任何人都能通过自然语言就能无门槛创造音乐的工具。用户只用几个简短的词,用户就可以用任何语言创作一首歌曲。官方宣称,不少知名的艺术家已经在使用Suno了,但Suno的核心用户群依然还是没有任何音乐制作经验的普通人。最近他们更新了最新的版本v3, 可以在几秒钟内制作出两分钟的完整歌曲。相比与之前的版本,v3生成的音乐质量更高,而且能制作各种各样的风格和流派的音乐和歌曲。提示词的连贯性也有了大幅提升,歌曲结尾的质量也获得了极大的提高。而且伴随着v3版本的推出,他们还发布了AI音乐水印系统,每段由平台生成的音乐都添加了人声无法识别的水印,从而在未来能够保护用户在Suno的创作,也能打击抄袭,防止将Suno产生的音乐进行滥用。
4个创始人Shulman、Freyberg、Georg Kucsko和Martin Camacho都是机器学习专家。在创立Suno之前,他们一起在剑桥的一家公司名叫Kensho Technologies的公司工作。其中Shulman和Martin Camacho都是业余的音乐爱好者,在Kensho上班时他们就经常一起即兴演奏乐曲。在Kensho工作期间,四人的主要任务是开发一种AI语音转录技术,用来转录上市公司的财报电话会议。后来他们发现,在AI文生图和文本生成领域发生的变革,在音频领域好像没有引起什么波澜,于是他们想自己在这个方向做点事情。一开始,他们做了个叫Bark的文本转语音程序。但当他们对早期Bark用户进行调查时,发现用户真正想要的是音乐生成工具。Suno目前只有12名员工,不过现在他们正在扩大规模,在现有的临时办公位置上他们正在加盖办公室。他是创始团队在Kensho时的机器学习团队主管,在创立Suno之前,他还是一名MIT斯隆管理学院的兼职讲师。对于Suno,他希望以后,全世界有10亿人能通过它来制作自己的音乐。在他看来,现在能够制作音乐的人比想要消费音乐的人少太多了,这实在是一个非常不平衡的情况。但是,音乐生成需要解决一个非常大的困难就是,音频不像文字那样是离散的形态。按照Shulman的说法,因为高质量音频的采样率通常为44khz或48Khz,这意味着「每秒48000个token」。所以,在去年,即便是见证了大语言模型和文生图的爆发式增长,很多AI研究人员认为,对于声音领域,这样的产品的初现,也许还要好多年的时间。Shulman说他们找到了很多新的方法和技巧才走到今天,未来他们还需要更多直观的方法让用户通过任何想要的方式来生成歌曲和音乐。他也是毕业于哈佛大学,曾经是4人共同工作过的公司Kensho的1号员工,首席构架师。他和Shullman有着几乎一模一样的履历,也是哈佛大学的物理学博士博士毕业,曾经在Kensho和MIT斯隆管理学院任职。本科毕业于乔治华盛顿大学,后来在多家公司担任运营和产品等职务。https://twitter.com/op7418/status/1771011983779000494
https://www.rollingstone.com/music/music-features/suno-ai-chatgpt-for-music-1234982307/