©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 科学空间
研究方向 | NLP、神经网络
近年来,RNN 由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有 RWKV [1]、RetNet [2]、Mamba [3] 等。当将 RNN 用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。
当然,任何事情都有两面性,相比于 Attention 动态增长的 KV Cache,RNN 的常数空间复杂度通常也让人怀疑记忆容量有限,在 Long Context 上的效果很难比得上 Attention。在这篇文章中,我们表明 Causal Attention 可以重写成 RNN 的形式,并且它的每一步生成理论上也能够以 的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明 Attention 的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟 RNN 一样本质上都是常数量级的记忆容量(记忆瓶颈)。RNN 的支持者通常会给出一个看上去让人难以反驳的观点:想想你的大脑是 RNN 还是 Attention? 直觉来想,RNN 推理的空间复杂度是常数,而 Attention的 KV cache 是动态增长的,再考虑到人的脑容量是有限的,从这一点来看不得不说确实 RNN 更接近人脑。然而,即便可以合理地认为脑容量限制了人每步推理的空间复杂度是常数,但它并没有限制每步的时间复杂度是常数,又或者换个说法,即便人的每步时间复杂度是常数,但人处理长度为 L 的序列时未必只扫描一遍序列(比如“翻书”),所以总的推理步数可能明显超出L,从而导致了非线性的时间复杂度。 考虑到这一点,笔者“突发奇想”:是否可以一般化地考虑常数空间复杂度、非线性时间复杂度的 RNN 模型,来补足主流 RNN 的所没有的能力(比如上面说的翻书)?对于语言模型任务,假设样本是 a b c d e,那么训练任务就是输入 a b c d,预测 b c d e,常见的 RNN 如下图:
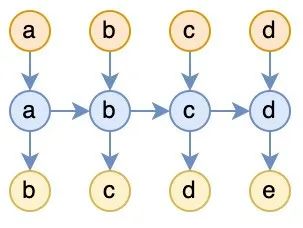
▲ 图一:常见RNN
这种 RNN 的问题就是没有翻书能力,每个输入读完就丢了。而 Attention 的特点就是每读一个 token,就完整地翻一遍历史,虽然这个做法可能存在效率问题,但它无疑是引入翻书能力的最简单粗暴的方式。而为了给 RNN 补上翻书能力,我们完全可以模仿 Attention 的做法来使用 RNN:
▲ 图二:不断“翻书”的RNN
跟 Attention 一样,每读一个新的 token,就翻一遍完整的历史。当然,也可以说这其实没有设计一种新的 RNN,只是 RNN 的一种新用法,单纯修改了输入,不管是 RWKV 还是 Mamba 都可以套上去。在这种用法之下,解码依旧可以在常数空间复杂度内完成,但每一步推理的时间复杂度在线性增长,从而总的时间成本是 。注意力也是RNN
事实上,图二所代表的模型非常广泛,甚至于 Attention 也只不过是它的一个特例,如下图所示:
▲ 图三:Causal Attention对应的RNN
跟图二相比,图三有几个箭头虚化了,代表这几处位置实际上是断开的,所以说 Attention 只不过是图二的一个特例。具体来说,Attention 的计算公式为: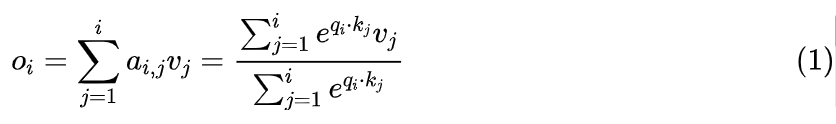
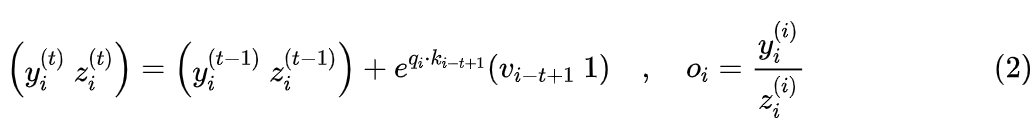
根据笔者所阅读的文献,最早提出上式并用它来优化 Attention 计算的文献是《Self-attention Does Not Need O(n^2) Memory》[4],上式的分块矩阵版本正是当前主流的加速技术 Flash Attention 的理论基础。由于在 Self Attention 中,Q、K、V 都是由同一个输入通过 token-wise 的运算得到,所以上述递归形式正好就可以表示为图三。 当然,图三只画出了一层 Attention,多层自然也可以画出来,但连接看起来会有点复杂,比如两层的情况如下图所示:
▲ 图四:两层Attention对应的RNN
本文开头已经说了,RNN 的常见优点是可以常数空间复杂度、线性时间复杂度进行推理,既然 Attention 也可以写成 RNN,那么自然的问题是在这种写法下它也有这两个优点吗?很明显,由于 Attention 对应的 RNN 是一个序列长度增加到了 的 RNN,所以线性时间复杂度那是不用想了,唯一值得思考的是能不能做到常数空间复杂度?大家的第一反应也许是不能,因为众所周知 Attention 解码有一个动态线性增长的 KV cache。但这只是通常情况下比较高效率的实现,如果我们不计成本地用时间换空间,那么空间复杂度可以进一步降低到多少呢?答案可能让人意外:如果真的将时间换空间做到极致,那么确实可以将空间复杂度降低到 !其实这个结论并不难想象。首先,图三所示的单层 Attention,形式跟普通的单层 RNN 没什么两样,因此显然是可以用固定大小的储存空间就可以完成推理。接着,我们来看图四所示的多层 Attention,它的层与层之间的连接比较复杂,所以通常需要将历史 K、V 缓存起来才能比较高效地计算,但如果我们坚决不存 KV cache,那么每一层、每一步推理所输入的 K、V,完全从最原始输入进行重新计算得到(重计算),这会导致非常多的重复计算,所以总的时间复杂度会远超平方复杂度,非常不环保,但空间复杂度确实可以保持在 。以两层 Attention 为例,第二层 Attention 用到了第一层 Attention 的输出作为输入,而第一层 Attention 的每个输出都可以在 空间内计算得到,所以只要我们愿意牺牲效率去重计算,第二层 Attention 也只需要在 空间就可以完成。依此类推,第三层 Attention 用到了第二层 Attention 的输出作为输入,第 N 层 Attention 用到了第 N-1 层 Attention 的输出作为输入,由于上一层都可以通过重计算在 空间就可以完成,所以每一层乃至整个模型都可以在 空间完成计算。这就再次回到了文章开头的观点:如果 Attention 相比 RNN 真的存在什么优势,那也只是靠更多的计算达到的,直觉上的扩大了“内存”,只是用空间换时间的表象,它跟 RNN 一样本质上都具有常数容量的记忆瓶颈。当然,也许有读者觉得:用时间换空间不是很常见的做法吗?这看上去并不是什么有价值的结论?的确,时间换空间确实很常见,但并非总是能做到的。换句话说,并不是所有问题都可以通过时间换空间来将空间复杂度降低到 的,这是一个常见但非平凡的特性。
 之所以指出 Attention 的这一特性,并不是真的要用这个特性去推理,而是通过它来帮助我们进一步思考 Attention 的能力瓶颈。首先,真的要抠细节的话, 其实是不对的,更严格来说应该是 ,因为平方复杂度的 RNN 需要反复扫描历史序列,这至少需要把原始输入和生成过程的输出都存下来,即至少需要存 L 个整数 token id,这个所需要的空间是 的,如果 L 足够大,那么 将会比 更大。然而,这里的 主要说的是 LLM 中间的计算层所需要的最少空间,相当于作为 RNN 时的 hidden_state,至少有 (hidden_size * num_layers * 2) 个分量,而 的空间则体现在输入和输出。一个直观的类比是将 Attention 当作一台具有无限硬盘、固定内存的计算机,它不断从硬盘中读取数据,然后在内存中进行计算,同时把结果写进硬盘中。我们知道,如果内存本身很大而处理的数据不大时,那么我们自己在编程时通常都会更加“任性”一点,甚至可能将所有数据加载到内存,中间计算过程完全不依赖于硬盘的读写。同样,在“大模型、短序列”背景之下训练出来的 LLM,会更倾向于使用模型 scale 带来 级别的固定“内存”,而不是由序列长度带来的动态“硬盘”,因为在当前 LLM 的 scale 之下前者会足够大,SGD 会“偷懒”将模型当成一个具有无限静态内存的机器来训练(因为对短序列来说内存总是足够),但实际上模型的静态内存是有限的,因此对于那些不可能在 空间完成的任务,基于 Attention 的模型也不能够泛化到任意长度的输入。举个例子,我们要计算 的十进制表示y,用 Attention 进行条件建模 p(y|x),训练语料就是 拼接,只算 y 的 loss。注意这里的y可以由输入x唯一确定,那么理论上应该可以学出 100% 的准确率。但如果没有思维链(CoT)来动态增加序列长度,模型只能将所有计算过程隐式地放到“内存”中,这对于短输入总是有效的。但事实上,内存是有限的,而计算 所需要的空间则随着 x 的增加而增加,所以必然存在一个足够大的 x,使得 p(y|x) 的准确率无法做到 100%(哪怕是训练准确率)。这跟《Transformer升级之路:“复盘”长度外推技术》所讨论的长度外推问题不一样,它不是由位置编码的 OOD 导致的,而是没有足够 CoT 引导时“大模型、短序列”的训练所带来的的能力缺陷。那为什么当前主流的 scale up 方向依然是增大 LLM 的内存,即增加模型的 hidden_size 和 num_layers,而不是去研究诸如 CoT 等增加 seq_len 的方案呢?后者当然也是主流研究之一,但核心问题是如果内存成为瓶颈,会降低模型的学习效率和普适性。就好比内存不大而数据量很大时,我们就需要及时保存结果到硬盘中并清空内存,这意味着算法上要更加精巧、难写,而且有可能还要根据具体的任务来定制算法细节。那什么情况下会出现内存瓶颈呢?以 LLAMA2-70B 为例,它的 num_layers 为 80、hidden_size 为 8192,两者相乘是 640K,再乘个 2 刚好是 1M 左右。换句话说,当输入长度达到 1M tokens 的这个级别,那么 LLAMA2-70B 的“内存”就可能成为瓶颈。尽管目前训练 1M tokens 级别的 LLM 依然不容易,但已经不再是遥不可及,比如 Kimi 就已经上线了 1M 级别的模型内测。 所以,不断增加模型的 context length(硬盘),以容纳更多的输入和 CoT,同时提高模型本身的 scale,使得“内存”不至于是瓶颈,就成为了当前LLM的主旋律。 同时,这还否定了笔者之前的一个想法:是否可以通过缩小模型规模、增加 seq_len 来达到跟大模型一样的效果?答案大概是不行,因为小模型存在内存瓶颈,要靠 seq_len 带来的硬盘来补足的话,需要给每个样本都设置足够长的 CoT 才行,这难度比直接训练大模型更加大,如果只是通过 repeat 等简单方案来增加 seq_len,由于没有带来额外信息,那么是没有有实质收益的。不过,如果增加 seq_len 是通过 prefix tuning 的方式来实现的,那么是有可能补足空间复杂度上的差距的,因为 prefix 的参数并非由输入序列计算出来,而是单独训练的,这就相当于额外插了一系列“内存条”,从而增大了模型的内存。
之所以指出 Attention 的这一特性,并不是真的要用这个特性去推理,而是通过它来帮助我们进一步思考 Attention 的能力瓶颈。首先,真的要抠细节的话, 其实是不对的,更严格来说应该是 ,因为平方复杂度的 RNN 需要反复扫描历史序列,这至少需要把原始输入和生成过程的输出都存下来,即至少需要存 L 个整数 token id,这个所需要的空间是 的,如果 L 足够大,那么 将会比 更大。然而,这里的 主要说的是 LLM 中间的计算层所需要的最少空间,相当于作为 RNN 时的 hidden_state,至少有 (hidden_size * num_layers * 2) 个分量,而 的空间则体现在输入和输出。一个直观的类比是将 Attention 当作一台具有无限硬盘、固定内存的计算机,它不断从硬盘中读取数据,然后在内存中进行计算,同时把结果写进硬盘中。我们知道,如果内存本身很大而处理的数据不大时,那么我们自己在编程时通常都会更加“任性”一点,甚至可能将所有数据加载到内存,中间计算过程完全不依赖于硬盘的读写。同样,在“大模型、短序列”背景之下训练出来的 LLM,会更倾向于使用模型 scale 带来 级别的固定“内存”,而不是由序列长度带来的动态“硬盘”,因为在当前 LLM 的 scale 之下前者会足够大,SGD 会“偷懒”将模型当成一个具有无限静态内存的机器来训练(因为对短序列来说内存总是足够),但实际上模型的静态内存是有限的,因此对于那些不可能在 空间完成的任务,基于 Attention 的模型也不能够泛化到任意长度的输入。举个例子,我们要计算 的十进制表示y,用 Attention 进行条件建模 p(y|x),训练语料就是 拼接,只算 y 的 loss。注意这里的y可以由输入x唯一确定,那么理论上应该可以学出 100% 的准确率。但如果没有思维链(CoT)来动态增加序列长度,模型只能将所有计算过程隐式地放到“内存”中,这对于短输入总是有效的。但事实上,内存是有限的,而计算 所需要的空间则随着 x 的增加而增加,所以必然存在一个足够大的 x,使得 p(y|x) 的准确率无法做到 100%(哪怕是训练准确率)。这跟《Transformer升级之路:“复盘”长度外推技术》所讨论的长度外推问题不一样,它不是由位置编码的 OOD 导致的,而是没有足够 CoT 引导时“大模型、短序列”的训练所带来的的能力缺陷。那为什么当前主流的 scale up 方向依然是增大 LLM 的内存,即增加模型的 hidden_size 和 num_layers,而不是去研究诸如 CoT 等增加 seq_len 的方案呢?后者当然也是主流研究之一,但核心问题是如果内存成为瓶颈,会降低模型的学习效率和普适性。就好比内存不大而数据量很大时,我们就需要及时保存结果到硬盘中并清空内存,这意味着算法上要更加精巧、难写,而且有可能还要根据具体的任务来定制算法细节。那什么情况下会出现内存瓶颈呢?以 LLAMA2-70B 为例,它的 num_layers 为 80、hidden_size 为 8192,两者相乘是 640K,再乘个 2 刚好是 1M 左右。换句话说,当输入长度达到 1M tokens 的这个级别,那么 LLAMA2-70B 的“内存”就可能成为瓶颈。尽管目前训练 1M tokens 级别的 LLM 依然不容易,但已经不再是遥不可及,比如 Kimi 就已经上线了 1M 级别的模型内测。 所以,不断增加模型的 context length(硬盘),以容纳更多的输入和 CoT,同时提高模型本身的 scale,使得“内存”不至于是瓶颈,就成为了当前LLM的主旋律。 同时,这还否定了笔者之前的一个想法:是否可以通过缩小模型规模、增加 seq_len 来达到跟大模型一样的效果?答案大概是不行,因为小模型存在内存瓶颈,要靠 seq_len 带来的硬盘来补足的话,需要给每个样本都设置足够长的 CoT 才行,这难度比直接训练大模型更加大,如果只是通过 repeat 等简单方案来增加 seq_len,由于没有带来额外信息,那么是没有有实质收益的。不过,如果增加 seq_len 是通过 prefix tuning 的方式来实现的,那么是有可能补足空间复杂度上的差距的,因为 prefix 的参数并非由输入序列计算出来,而是单独训练的,这就相当于额外插了一系列“内存条”,从而增大了模型的内存。
在这篇文章中,我们从平方复杂度 RNN 的角度审视了 Attention,并发现了它具有常数空间复杂度的瓶颈,这表明 Attention 相比 RNN 本质上并没有增加“内存”,而只是增加了非常多的计算量。这个瓶颈的存在,表明 Attention 对某些任务的长度泛化可能存在理论上的困难(内存不足),如何引导模型更好地利用 seq_len 维度所带来的动态“硬盘”,也许是解决这个困难的关键之处。[1] https://arxiv.org/abs/2305.13048[2] https://arxiv.org/abs/2307.08621[3] https://arxiv.org/abs/2312.00752[4] https://arxiv.org/abs/2112.05682

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
