
©PaperWeekly 原创 · 作者 | 陈卓群
单位 | 清华大学

Searching a High Performance Feature Extractor for Text Recognition Network论文链接:
https://ieeexplore.ieee.org/document/9887897代码链接:
https://github.com/AutoML-Research/TREFE
引言
文本识别(Text Recognition)是一项旨在从图像中提取文本字符串的技术,对于工业界和学术界都有着很大的吸引力。而文本所具有的形色各异的外观、大小、字体、背景、书写风格和排版,都使得 TR 成为了一项非常有挑战性的问题。如 Fig1 所示,传统的 TR 系统可以大致被分为三个部分:1. 图像预处理模块,针对自然语言场景中的实际情况,把输入图像转化为一个更便于识别的形式。主要实现方式有图像校正、超分辨率和降噪;2. 特征提取器,用来从文本图像中提取特征。目前大部分特征提取器的实现形式都是通过 CNN 和 RNN 的结合,CNN 从图像中提取视觉特征,然后通过 RNN 增强时序依赖特征,生成鲁棒的序列特征;3. 识别头,用来输出字符序列。目前较为流行的做法是基于神经网络的 CTC、字符分割、基于注意力的序列到序列、基于注意力的并行解码等。特征提取器在 TR 中发挥着关键的作用,并且占据着大量的数据计算和存储开销。但由于手动调参的成本较高,因此对于特征提取器的结构个性化方面探索较少。现有方法往往直接使用起初为其他任务设计的 CNN 和 RNN 网络(如 TABLE 1),包括用于图像分类的 ResNet 和用于机器翻译的 BiLSTM,并没有针对 TR 任务进行调优。除此之外,TR 系统在部署到终端时,通常会有推理延迟的限制,现有的设计方案并没有考虑到这一点,在手动调整 TR 系统以适应延迟的同时,很难保证高精度的识别。 近期研究表明,神经架构搜索(NAS)可以在图像分类、语义分割、目标检测等计算机视觉任务中产出良好的神经架构,受此启发,摒弃此前需要专家手动设计架构的方法,本文提议使用 one-hot NAS 来搜寻高性能的 TR 特征提取器。具体来说,我们首先为视觉和序列特征提取器设计一个特定于 TR 任务的搜索空间。对于视觉部分,该搜索空间支持对卷积类型和下采样路径进行选择;对于序列部分,本文提议使用 Transformer 替代,其比 TR 任务中常用的 BiLSTM 具有更强的并发性,但是 Vanilla Transformer 很难优于 BiLSTM。因此,本文进一步探索了 Transformer 近期的发展,并搜寻 Transformer 的变体。 由于合成的超网之巨大,本文提议使用两阶段 one-hot NAS 方法。在第一个阶段,受神经网络渐进逐层训练的启发,本文采用了一种贪婪的逐块训练的方式。在第二个阶段,摒弃进化算法或随机搜索,本文使用自然梯度下降以更高效地从超网中搜寻更精悍的架构,部署环境的资源限制也可以很好地在本阶段引入,导致最终选择出的架构更有可部署性。在一系列的标准数据集上的大量实验表明,合成的 TR 模型在准确性和推理速度上都优于现存 SOTA 模型。
空间模型是一个卷积神经网络 (CNN),每一个卷积层 可以被表示为 ,其中 为输入图像张量,ct 是卷积类型, 是高度和宽度维度上的步长。下采样路径将图像与卷积运算一起下采样到特征图 (feature map),可以显著影响 CNN 的性能。本文通过探索视觉模型的架构并自动搜索每一层中的 值。整个空间结构可以通过 和 ,其中 是卷积层数, 是候选卷积操作的集合, 是候选步长值的集合。我们假定视觉模型的输入尺寸为 和 的具体选择过程如下:1. 令 ,保证垂直方向的下采样步长不超过水平方向,以避免使得相邻字符更难区分。此外,当 为 (2,1) 或 (2,2) 时,该层的分辨率会降低,因此将滤波器的数量加倍。2. 包括卷积核尺寸为 和扩展因子为 的反瓶颈卷积 (MBConv) 层。3. 我们使用大小为 1×W/4 的输出 feature map,由于空间模型的输入大小为 32×W,因此对于每个下采样路径,都有:
Figure 3 (a) 展示了视觉模型搜索空间的 层结构。每个蓝色的节点对应一个 1 层的 的 feature map 。每条绿色的边对应一个候选的卷积层 运算 ,而每条灰色的边对应 中一个候选的步长。一条连接从初始尺寸 ([32, W]) 到最后一个 feature map R 寸 的蓝色节点的路径表示一个候选视觉模型。对于自然语言处理系统中的序列模型,LSTM 已经逐渐被 Transformer 替代,Transformer 在并行性和提取长期上下文特征方面都更有优势。但是由于在命名实体识别和自然语言推理等任务上的性能可能不及 BiLSTM,直接应用 Vanilla Transformer 可能并不理想。设每个变换层为 ,其中 是输入张量,rt 是变换层的类型。序列模型的结构定义为 ,其中 为候选层的集合, 为变换层的数量。受 Transformer 最新进展的启发,本文提议通过以下四个方面改进其设计:1. Transformer 以长度为 的 维特征序列 为输入, 通过三个多层感知器 (MLP 被转换为 query , key 和 value 尺寸均为 。本文添加从上一层至当前层的残差路径,以促进注意力分数的传播,第 层(不包括输入层)的注意力分数可表示为: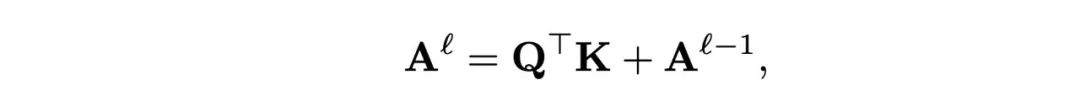
2. 添加相对距离表征 Rel 以提高注意力分数 A 的距离和方向意识:

4. 用门控线性单元(GLU)代替前向网络(FFN)中的 MLP:其中 x 为多头自注意力(MHSA)的输出,⊗ 为元素积符号,σ 为 sigmoid 函数,这使得 FFN 可以与预测相关的特征。 对于 N 层序列模型,我们将 Figure 4 的 N 个副本附到 Figure 3(a)中的序列模型输出,在 Figure 3(b)中,每个蓝色的矩形代表一个 transformer 层,每个黑色节点表示该层上的设计选择。Figure 3(b)中沿着黑色节点连接的品红色路径构成了一个候选的序列模型。
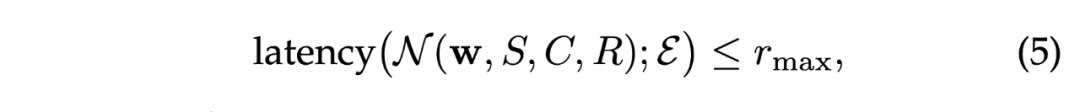
其中 为网络权重为 ,由 决定特征提取器结构的 TR 模型, 为环境, 为资源的预算。为简单起见,这里只考虑了一个资源约束,多个资源限制的情况同理。假设一个在视觉模型中有 层、在序列模型中有 层的特征提取器,令 为网络的训练损失, 为网络在验证集上的效果。则对目标架构 的搜索可以表示为:

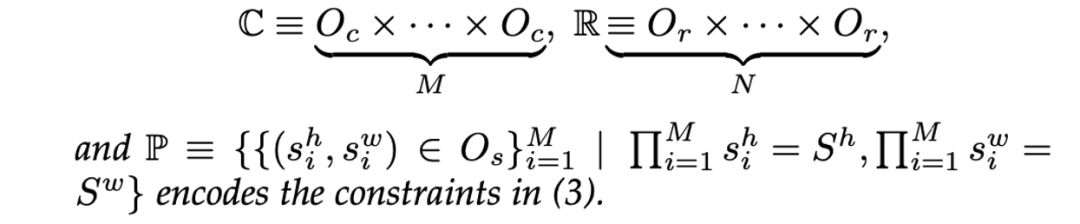
值得注意的是,(6) 是一个双层优化问题,解决起来成本非常高,尤其是训练每个候选架构 以获得权重 时,因此直接优化 (6) 是不现实的。2.2 搜索算法
受最新进展启发,本文提议使用 one-shot NAS 来解决(6),通过仅训练一个超网来简化搜索。然而由于搜索空间巨大,单阶段的方法需要训练整个超网,这需要大量的 GPU 内存,因此本文提出使用两阶段方法。
在one-shot NAS中设计超网
超网设计有两个基本要求,应包括搜索空间中的所有候选,以及每个候选都可以被表示为超网中的一条路径。
本文提出的超网有两个部分,视觉模型和序列模型。视觉部分(Figure 3(a))是一个 3D 网格,其中每条边决定了一个转换表征的运算,从 [32,W] 到 [1,W/4] 的连接路径表示下采样路径,运算的选择和下采样路径共同决定了 CNN。Figure 3(b) 展示了超网中的序列模型部分。
最主要的挑战是如何充分且公平地训练超网中的所有候选架构,一个典型的解决方案是对架构进行均匀采样,然后进行训练,但在巨大的搜索空间中,均匀采样是无效的。为了缓解这个问题, 本文提议将超网 (表示为 ) 划分为 个更小的块 并逐一优化他们。由于视觉模型比序列模型大得多,因此把整个序列模型看作一个块 ,把视觉模型分为 个大小相等的块 (Figure 3(a))。具体训练过程如 Algorithm 1 所示。

搜索子网
超网中的路径对应特征提取器的架构,设从 Algorithm 1 返回的超网的训练权重为 ,由于约束 已经被超网结构隐式编码,且超网权重已被训练,问题 (6) 可简化为:为了避免直接使用进化算法 (EA) 带来的早熟问题,本文考虑对 使用随机松弛,将 (7) 转化为: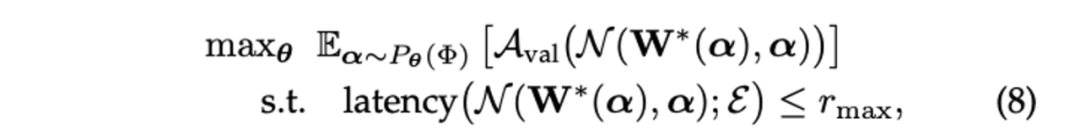
其中 表示期望, 是搜索空间上的指数分布,从 中采样有助于探索更多不同的架构。Algorithm 2 展示了搜索过程,为了优化 ,我们首先使用指数分布 对架构的小批量 进行采样。对于每个采样架构,测量其时延和验证集性能。与超网训练相比,这花费的时间可以忽略不计。不满足延迟要求的架构将被丟弃舍弃,采样的架构和相应的性能分数用于通过自然梯度下降更新 。具体来说,在第 次迭代时, 更新为:


其中 是步长, 为 Fisher 信息矩阵, 为梯度,Algorithm 3 展示了整个训练过程。

实验结果
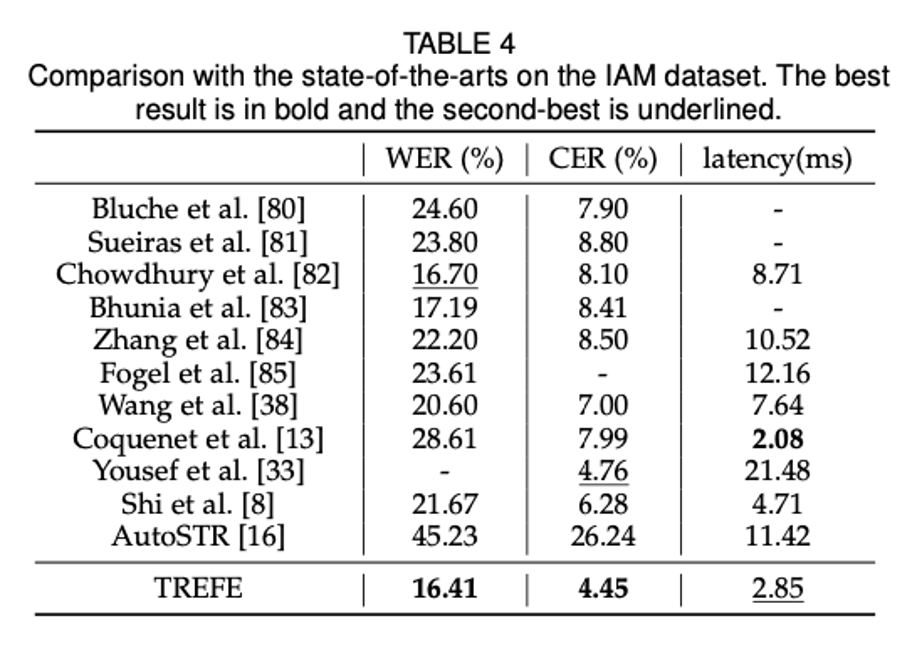
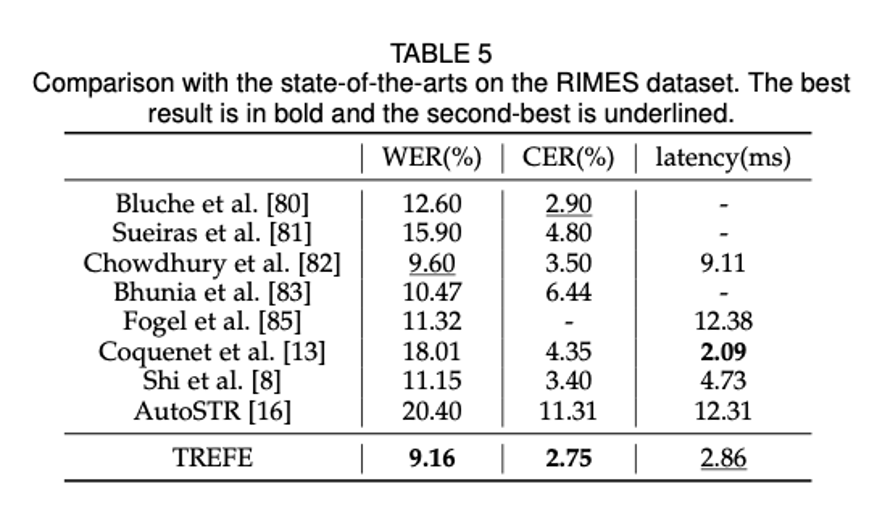
本文将 TREFE 与 SOTA 方法在手写文本和场景文本识别任务上进行了对比,为了简单起见,没有使用任何词汇或语言模型。
场景文本识别:

手写文本识别:

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
