人工智能产业应用发展的越来越快,开发者需要面对的适配部署工作也越来越复杂。层出不穷的算法模型、各种架构的AI硬件、不同场景的部署需求、不同操作系统和开发语言,为AI开发者项目落地带来极大的挑战。
为了解决AI部署落地难题,我们发布了新一代面向产业实践的推理部署工具FastDeploy。FastDeploy旨在为AI开发者提供模型部署最优解,具备全场景、简单易用、极致高效三大特点(下文将详细解读)。开发者可以通过FastDeploy这款产品,满足全场景的高性能部署需求,大幅提升AI产业部署的开发效率。抢先看看硬件合作伙伴和AI部署工程师眼中的FastDeploy。(上下滑动查看)12月12日-12月30日,《产业级AI模型部署全攻略》系列直播课程,FastDeploy联合10家硬件公司与大家直播见面。欢迎大家扫码报名获取直播链接,加入交流群与行业精英共同探讨AI部署话题。

扫码报名,获取直播链接
https://github.com/PaddlePaddle/FastDeploy接下来让我们详细了解FastDeploy的简单易用、全场景、高性能3大特性。FastDeploy精心的完成了API设计,确保使用不同编程语言的开发者能够享受到统一的API体验。并且,无论使用哪一种编程语言,都只需要3行核心代码就可以实现预置模型的高性能推理。- 一键体验预置150+热门模型,覆盖20多主流产业应用场景
FastDeploy覆盖20多主流场景,提供了150多个SOTA产业模型的端到端示例,模型类型覆盖CV、NLP、Speech和跨模态等领域,让开发者可以从场景入手,通过预置模型,使用FastDeploy快速部署起来。FastDeploy 预置150多个产业SOTA模型FastDeploy配套了10多个基于EasyEdge的端到端的部署工程Demo,可以更便捷地在端上设备体验到AI模型的效果,满足开发者产业实践中快速集成的需求。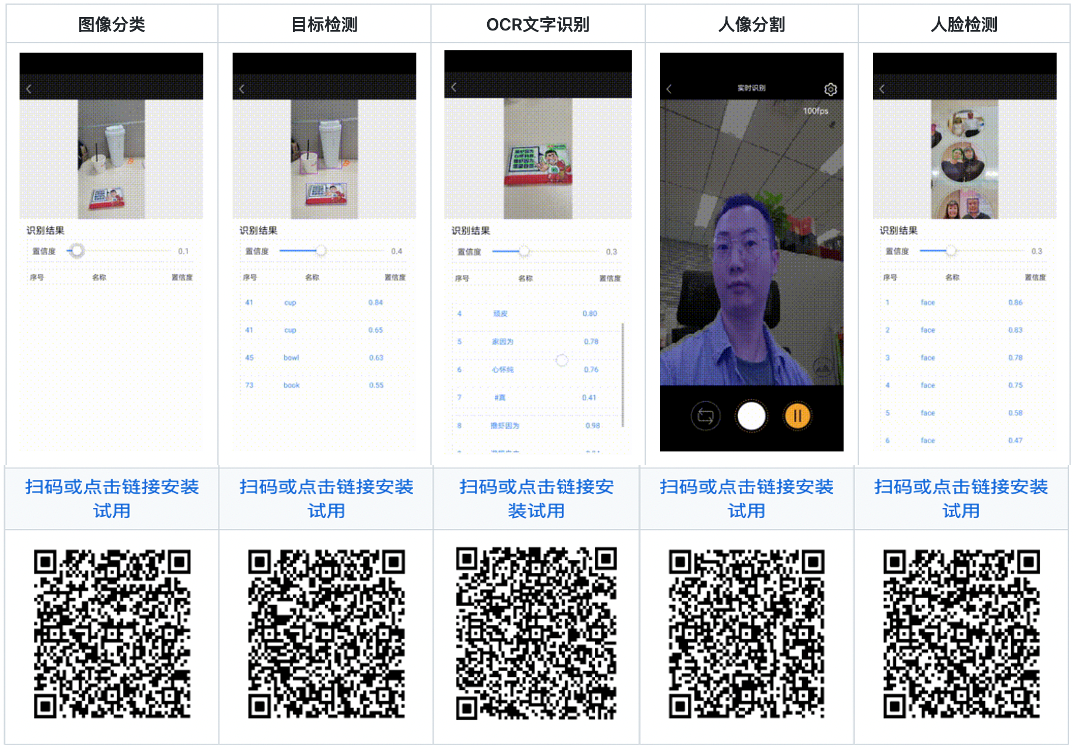
统一多端部署API,一行代码,灵活切换多推理引擎后端- 统一多端部署API,一行代码,灵活切换多推理引擎后端
FastDeploy统一多端部署API,只需要一行代码,便可灵活切换多个推理引擎后端。可以非常方便地从服务端部署的代码切换到移动边缘端部署。FastDeploy切换推理引擎后端
接下来看看多框架支持的功能,FastDeploy中内置了X2Paddle和Paddle2ONNX模型转换工具。只需要一行命令便可完成其他深度学习框架到飞桨以及ONNX的相互转换,让其他框架的开发者也能通过FastDeploy体验到飞桨模型压缩与推理引擎的端到端优化效果。FastDeploy一行代码切换多端部署
FastDeploy硬件适配基于飞桨硬件适配统一方案进行扩展,最大化AI模型的部署通路。目前在FastDeploy的版本中也和Intel、NVIDA、瑞芯微、芯原、Graphcore、昆仑芯、飞腾、算能、昇腾等硬件厂商完成了硬件适配,也期待与更多硬件生态伙伴共同在FastDeploy上开发更多的端到端推理部署方案。
性能方面,FastDeploy集成了飞桨压缩与推理的特色,联动自动压缩与推理引擎深度优化,实现了更高效的量化推理部署。利用PaddleSlim ACT自动压缩技术带来的无损压缩体验,以PP-LCNetV2和ERNIE 3.0-Medium模型为例,通过ACT自动压缩技术,操作简易度可以比拟传统离线量化,实现近乎无损的模型压缩效果。FastDeploy一键自动压缩,减少硬件资源消耗
FastDeploy在各模型的部署中,重点关注端到端到的部署体验和性能。在服务端对预处理过程进行融合,降低内存创建开销和计算量。在移动端集成百度视觉技术部自研高性能图像处理库FlyCV。结合FastDeploy多后端支持的优势,相较原有部署代码,所有模型端到端性能大幅提升。
FastDeploy前后预处理优化,减少硬件资源消耗
目前FastDeploy已经支持包括X86 CPU、NVIDIA GPU、Jetson、飞腾 CPU、昆仑 XPU、Graphcore IPU、华为昇腾 NPU、ARM CPU(联发科、瑞芯微、树莓派、高通、麒麟等ARM CPU硬件)、瑞芯微 NPU、晶晨 NPU、恩智浦 NPU等十多类AI硬件。开发者可以通过FastDeploy这款产品,满足全场景的高性能部署需求,大幅提升AI产业部署的开发效率。
本次部署直播月历时3周,将联合10家硬件公司全面讲解云边端硬件部署,手把手云边端实战,体验“开箱即用”的软硬解决方案落地。欢迎大家扫码报名获取直播链接,加入交流群与行业精英深度共同探讨AI部署落地话题。