
本文摘要:
采用少量手动修改+自动代码转换的方式,将大型多线程程序改造成协程。在某些重IO、高并发的场景中,帮助业务取得了性能翻倍的效果。
RocksDB是业界知名的可嵌入的、持久化的KV数据库,它使用一套日志结构的存储引擎,为快速而又低延迟的存储设备做了特殊优化处理。RocksDB使用C++编写,2013年开源,其代码风格成熟稳定,测试覆盖率高,项目中还附带了丰富的性能测试工具。可以说,研究RocksDB原理,并学习其工程实践,是每个做存储和底层系统优化的工程师都绕不开的话题。RocksDB本身是多线程模型,支持并发读写。众所周知,协程相比较于线程,在IO繁重或者并发量大时,有着更轻量且更高效的特性。据测试,在系统负载较高时,一次线程切换的时间最高可达30μs;而使用协程,最低仅需十几个ns,相差了几个数量级。PhotonLibOS(以下简称Photon)是阿里云存储DADI团队开源的一款高性能协程库和IO引擎,我们曾经拿自己用协程实现的IO程序与fio比较过,以及用协程实现的网络程序与Nginx比较过,都取得了更好的性能。恰逢存储内部的某个业务团队正在使用RocksDB,且网络+存储的整体方案遇到了一些性能瓶颈,于是,我们便开始调研用协程改造RocksDB,这是Photon第一次在大规模的成熟软件上进行嫁接尝试。先说结论:改造的过程出奇地顺利,没有变更RocksDB的主逻辑,只是手动修改了200多行代码,然后利用一个能够扫描代码并自动转换成协程版本的小脚本,就顺利地完成了编译和运行。按照业务需求,我们使用的是2019年的RocksDB 6.1.2版本,总共3175个test case。经过测试,Photon协程版本的RocksDB通过了3170个case,成功率达到99.87% 。经过初步分析,失败的5个都是因为涉及到了线程自身的特性,或者test case里显式地认为自身运行在线程环境里,协程版本无法满足因此失败。且这些失败的case不会影响RocksDB的正常运行。在性能方面,利用自带的db_bench工具,在四种典型的KV读写场景下测试对比了Photon版本RocksDB与原版RocksDB的OPS,两者达到了相近的数据;在某些重IO、高并发的场景下,会比原版的性能更好(见后文)。常见的并发模型有:多线程、异步回调、有栈协程、无栈协程。Photon基于有栈协程实现并发。如下图,Photon没有依据传统惯例将协程命名为coroutine或者fiber,而是仍然将其命名为thread。多个thread运行在一个vcpu里,而这里的vcpu即是大家熟知的OS线程。每个vcpu同一时间只会运行在一个core上,即使vcpu可能发生跨core迁移,但是这些对于协程(thread)来说是感知不到的。之所以这样命名,是因为Photon一直以来都将协程看做是一种轻量级线程,并且在给协程设计API时,也尽量去兼容了POSIX标准和C++ std的语法,以至于如果不是特别提醒,开发者都会很难判断这是一个多线程程序还是协程程序。这些工作也为后面的RocksDB改造埋下了伏笔,使得我们可以轻易地只用少量代码就实现对一个超大型项目的重构。在语法上,由于有栈协程不依赖编译器特性(如C++20的async和await),协程的切换点被封装到了IO操作或者事件内部,因此对旧代码侵入性较小。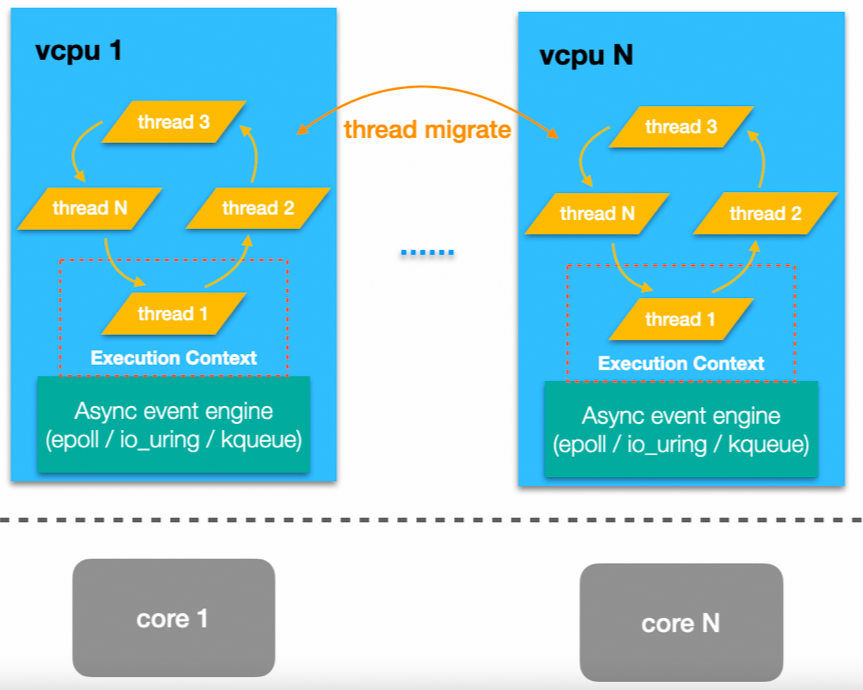
Photon的每个vcpu都包含一个异步事件引擎。所谓事件,其来源可能有以下几个方面:由于需要确定协程的调用顺序以及IO的执行时机,因此Photon自身除了是一个协程库,也是一个高性能的事件调度器。它支持多种异步引擎,如epoll、io_uring、kqueue等。在5.x以上的高版本Linux内核上,我们推荐使用io_uring引擎。在适当的时机,调度器会通过io_uring的一次系统调用进行批量的IO提交和收割,这种方式减少了系统调用的数量,从而提升了系统的整体性能。除了性能以外,普通用户能够感知到的io_uring与epoll的最大变化是,io_uring引擎天然支持异步文件IO。而且经过封装后,它写出来的代码却是同步调用的,不再需要类似libaio的注册与回调,也不需要内存对齐。因此,我们在使用这套IO接口改造RocksDB原先的同步psync IO时没有遇到任何麻烦,只是简单地替换了一下函数名。在一个并发的系统中,一般有多种方式实现同步。除了POSIX规定的那些经典的互斥锁、信号量之外,有些语言框架会提出自己的同步语义。比如Golang的channel,实际上是贯彻了它的一种哲学,即“不要通过共享内存来通信,而是通过通信来共享内存”。Photon的互斥锁和信号量基本上延续了POSIX的设计,只不过针对协程场景稍稍进行了改造。我们知道,多线程的同步原语一般都是依赖内核提供的Futex功能,Futex最核心的两个syscall分别是FUTEX_WAKE和FUTEX_WAIT。同理,Photon的mutex实现的很像一个用户态的Futex,也需要利用协程的唤醒和睡眠功能,并且通过链表的方式管理任务。关于原子操作的使用,在线程和协程上基本相同。唯一的不同是,如果业务能够确定某个变量只会被单vcpu内的协程使用,则不需要使用原子变量。因为单vcpu本身就是线程安全的.下面开始介绍RocksDB改造步骤,主要分为三个方面:1. 首先将所有的线程、同步原语等标准C++元素查找替换成Photon的协程版本。这里举一个经典的使用条件变量同步的例子:bool condition = false;std::mutex mu;std::condition_variable cv;
new std::thread([&] { std::this_thread::sleep_for(std::chrono::seconds(1)); std::lock_guard<std::mutex> lock(mu); condition = true; cv.notify_one();});
std::unique_lock<std::mutex> lock(mu);while (!condition) { cv.wait(lock);}
bool condition = false;photon::std::mutex mu;photon::std::condition_variable cv;
new photon::std::thread([&] { photon::std::this_thread::sleep_for(std::chrono::seconds(1)); photon::std::lock_guard<photon::std::mutex> lock(mu); condition = true; cv.notify_one();});
photon::std::unique_lock<photon::std::mutex> lock(mu);while (!condition) { cv.wait(lock);}
不难看出,规则很简单,即是在所有的std前面添加了photon::前缀。我们之所以这么设计,是为了最大程度地兼容标准,降低用户对新库的学习成本。研究photon::std::thread的代码可以发现,它其实是一个模板类,支持传入普通全局函数、类的成员函数、lambda等。每次new一个thread,就会产生一个协程在后台运行。我们知道,RocksDB本身内置了一个线程池,用于在后台执行compaction和flush等任务。经过替换后,它也自然变成了一个协程池。此外,在协程场景下,原先的sleep_for和wait函数都不再会阻塞调用线程,而是会让出CPU,由调度器决定下一个执行的协程,并执行栈切换。2. 第二步,删除所有线程专属的函数调用,比如类似pthread_setname_np这种给线程改名的函数,或者那些用于变更当前线程在内核的IO优先级的syscall。3. 最后,将thread_local关键字替换成photon::thread_local_ptr。众所周知,C++11开始引入这个关键字来表示线程局部变量,以便替换原先旧版本编译器的__thread,或者是pthread库提供的specific_key功能。RocksDB重度依赖线程局部变量,每次IO都会查找本线程内缓存的Version数值并进行比较,如果失效了,才会考虑去抢锁或者原子变量,以便获取最新的Version。同理,Photon程序也需要这种局部性的缓存机制,从而每个协程都可以保留一份独立数据。thread_local Value value = "123";
static photon::thread_local_ptr<Value, std::string> value("123");
为了方便大家验证,我们在github上fork了一份RocksDB的代码,并且往它的6.1.2分支上提了一个Pull Request,包含了上述所说的Photon相关的200多行改动。详细执行步骤请查阅photon-bench.md文件,值得注意的是,当前协程程序需要显式指定vcpu的数量,默认设置为8。为了公平起见,测试使用了taskset命令,限制多线程程序最大可以使用的core数量也为8。在并发数上,RocksDB的默认值是64,这个数值对于协程和线程来说会保持一致。测试机器为高配云主机,使用6.x内核,gcc 8编译器。1000万个Key,冷加载。测试时间1分钟,最终数据如下(单位:OPS/s)。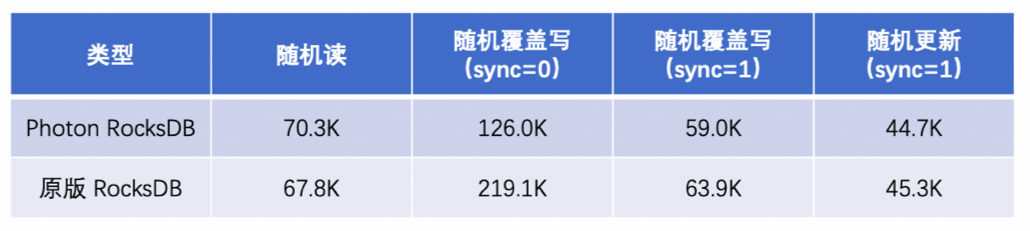
分析可知,当读或者开启同步写时,Photon版与原版的性能基本一致;当关闭同步写时,数据不用即时落盘。由于RocksDB基于LSM的存储引擎可以高效地将随机写转换为顺序写,因此在page cache的参与下,顺序写性能得到极大优化,整个过程转变为CPU密集型任务,协程的特性无法被发挥出来,故性能降低。此外,CPU密集型场景下新版性能不如原版还有一个重要的原因就是,新版代码只做了语法替换,而没有进行针对性的调优。举个例子来说,原版多线程在某些情况下会使用asm volatile("pause")进行CPU忙等,那么可否在协程场景下修改为协程的sleep?原版中包含一个core_local模块,它在协程场景下应该如何改造,等等。这里受限于篇幅,不一一列举。
看到这里有人可能会问,既然做单机测试时,协程版本的RocksDB貌似并没有很出彩,那么为什么还要做这些改造工作。其实,协程化的最大价值在于发掘一个基于网络的数据库的最大性能,特别是多连接、高并发的场景下。长久以来,epoll循环一直是实现一个高性能网络服务器的不二之选。不管是类似Java netty、boost asio的异步回调方案,还是类似Golang的协程方案,留给开发者的问题一直是如何在少量的线程里实现高并发的IO。回到RocksDB的场景下,它本身对多线程很友好,但嵌入到网络服务器之后,就不得不引入线程池技术来分发和维护数据读写请求。一边是异步多路复用系统,一边是同步系统,中间的连接器反而容易成为性能瓶颈。 另一方面,由于RocksDB默认开启了group commit技术,在并发场景下会将多个请求合并成一次IO,因此并发数越高,性能将会越好。协程可轻松支持百万并发,而线程的高并发往往会伴随着严重的竞争。我们针对业务团队的需求,将RocksDB嵌入在一个RPC server内,使用较小的KV size,较小的key的总数,同时增大客户端的并发数到1000。准备了两个方案用于测试,分别是:结果如下(单位:OPS/s)

在这个测试中,为了对多线程更友好一些,我们甚至放开了taskset的限制,让多线程程序可以最多使用到64个物理CPU core。然而随着线程数的增长,线程池方案逐渐遇到了瓶颈。反观协程方案,仅仅使用了8个线程(vcpu),就达到了前者两倍的性能。我们通过引入Photon库,花费少量代码,成功地将一个大规模的数据库软件改造成协程。一方面验证了协程在重IO、高并发场景下的理论优势,另一方面也检验了Photon自身的成熟度,输出了DADI技术在存储加速领域的最佳实践。需要声明的是,由于我们本身并不是RocksDB的专家,对其的改造仅停留在语法层面。我们相信运行在协程上之后,RocksDB的内部逻辑和调优手段还会存在一些需要调整的地方,以便适应协程、线程、CPU core的三级模型,最大化地增加cache命中率,降低资源争抢概率,解决目前协程版本RocksDB在CPU密集型任务下性能没有完全发挥出来的问题。关于这些工作,就需要后续再慢慢研究了。最后补充一句,PhotonLibOS的开源地址是:
https://github.com/alibaba/PhotonLibOS
如果大家对C++协程及高性能IO感兴趣,欢迎前来试用。