不要think step by step!谷歌最新自然语言推理算法LAMBADA:「反向链推理」才是答案
新智元报道
新智元报道
【新智元导读】谷歌发布全新反向推理算法LAMBADA,无惧搜索空间爆炸!
自动推理绝对算是自然语言处理领域的一大难题,模型需要根据给定的前提和知识推导出有效且正确的结论。
尽管近年来NLP领域借着大规模预训练语言模型在各种「自然语言理解」如阅读理解和问答等任务中取得了极高的性能,但这些模型在逻辑推理方面的性能仍然十分滞后。
去年5月「思维链」(Chain of Thought, CoT)横空出世,有研究人员发现,只需要在prompt中加入「Let's think step by step」就能让GPT-3的推理性能大幅提升,比如在MultiArith中就将推理准确率从之前的17.7%一下提升到了78.7%
但诸如CoT和Selection Inference等方法都是以前向(forward direction)的方式从公理(axioms)中搜索证明过程(proof)以推导出最终结论(conclusion),存在搜索空间组合爆炸的问题,因此对于较长的推理链,失败率较高。
最近,Google Research开发了一种反向链(Backward Chaining)算法LAMBADA(LAnguage Model augmented BAckwarD chAining),将经典推理文献中得出的「反向推理效率明显高于前向推理」这一结论应用于语言模型(LM)中。
论文链接:https://arxiv.org/abs/2212.13894
LAMBADA将推理过程分解为四个子模块,每个模块都由few-shot prompted语言模型推理实现。
最终LAMBADA相比当下sota的前向推理方法在两个逻辑推理数据集上实现了显著的性能提升,特别是在问题要求深度和准确的证明链情况下,LAMBADA的性能提升更加明显。
「反向推理」成版本答案?
「反向推理」成版本答案?
逻辑推理,特别是对非结构化自然文本的逻辑推理,是构建自动知识发现的基础构件,也是未来各种科学领域进步的关键。
虽然许多NLP任务的发展都受益于预训练语言模型不断扩大的规模,但根据观察,提升模型的尺寸对解决复杂推理问题的提升十分有限。
在经典文献中,有两种主要的逻辑推理方法:
1、前向链式推理(Forward Chaining, FC),即从事实和规则出发,在做出新的推理并将其加入理论之间进行迭代,直到目标陈述可以被证明或推翻;
2、后向链式推理(Backward Chaining, BC),即从目标出发,将其递归分解为子目标,直到子目标可以根据事实被证明或推翻。
以前用语言模型进行推理的方法大多采用前向链式推理的思路,要求从整个集合中选择一个事实和规则的子集,这对LM来说可能是困难的,因为它需要在一个大的空间里进行组合搜索。
此外,决定何时停止搜索并宣布证明失败在FC中也是非常困难的,有时甚至需要一个专门对中间标签进行训练的模块。
事实上,经典的自动推理文献在很大程度上偏重于后向链式推理或目标导向的求证策略。
LAMBADA
LAMBADA意为「反向链式技术增强的语言模型」,研究人员通过实验证明了BC更适合于基于文本的演绎逻辑推理(deductive logical reasoning)。
BC不需要大量的组合搜索来选择子集,而且有更自然的停止搜索标准(halting criteria)。
LAMBADA主要专注于对事实进行自动推理,即自然语言断言,如「好人是红色的」,这些断言是连贯的(coherent),但不一定基于真实情况。
一个规则由自然语言声明编写,形式上可以改写为「如果P那么Q」,例如「粗暴的好人是红色的」(Rough, nice people are red)可以改写为「如果一个人是粗暴的好人,那么他们是红色的」(If a person is rough and nice, then they are red)。
其中P被称为规则的前项(antecedent),Q被称为规则的后项(consequent)。
一个理论theory C由事实F={f1, f2, . . , fn}和规则R={r1, r2, . . , rm}组成,G代表一个想根据事实和规则来证明或反驳的目标。
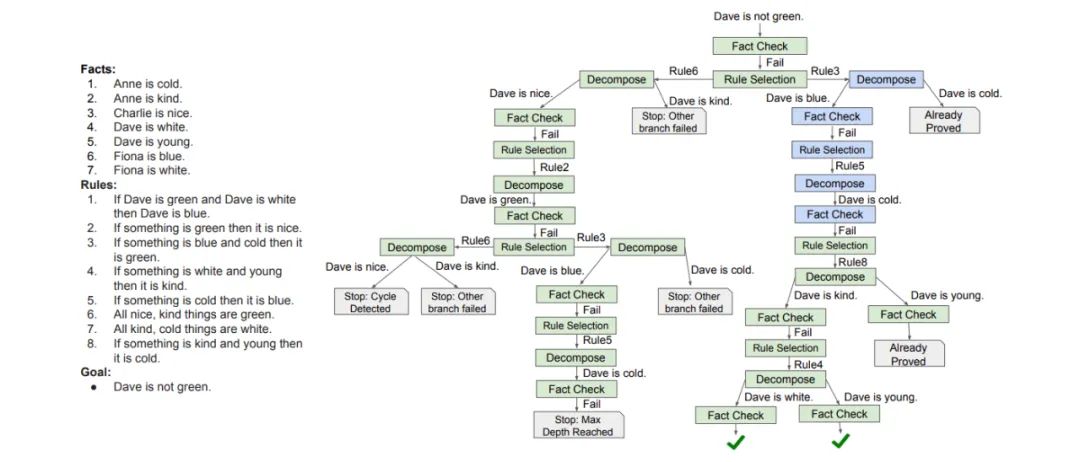
例1、一个带有虚构角色和规则的理论实例C
F={"菲奥娜是好人","菲奥娜是粗人"}
R={"如果某人很聪明,那么他就是好人","粗暴的好人是红色的","作为好人和红色意味着他是圆的"}。
基于上述理论,人们可能想证明或反驳一个目标,如「菲奥娜是红色的?」。
后向链法推理
一条规则是否适用于一个目标,是通过逻辑学中的一个叫做unification的操作来确定的。
例如,对于例1中的目标「Fiona是红色的?」,第二条规则的后果与目标相同,所以可以适用;但另外两条规则的后果不同,所以不适用。
考虑例1中的理论和目标,BC从目标「Fiona是红色的?」开始推理。
首先,BC验证该目标是否可以从任何事实中被证明或反驳。由于没有任何事实可以证明或反驳这个目标,所以接下来会验证这个目标是否与任何规则的结果相统一,结果发现它与第二条规则「粗糙的好人是红色的」相统一。
因此,该目标可以被分解成两个子目标:1)菲奥娜是粗暴的吗?和2)菲奥娜是好人吗?。
由于这两个子目标都可以从事实中得到证明,BC的结论是原始目标可以得到证明。
对于一个目标,BC的结果要么是证明,要么是否定,要么是不知道(例如目标「菲奥娜很聪明?」)。
LAMBADA中的语言模型
LAMBADA中的语言模型
为了将BC用于基于文本的推理,研究人员引入了四个基于LM的模块:事实检查(Fact Check)、规则选择(Rule Selection)、目标分解(Goal Decomposition)和符号一致性(Sign Agreement)。
事实检查
给出理论中的一组事实F和一个目标G,事实检查模块验证是否存在一个事实f∈F,使得f包含G(在这种情况下,目标被证明)或者f包含G的否定(在这种情况下,目标被否定)。
如果找不到这样的事实,那么G的真相仍然是未知的。
事实检查的实现包括两个子模块:第一个子模块从与目标最相关的事实集中选择一个事实,第二个子模块根据这个事实来验证目标是否可以被证明或否定。
由于事实选择子模块在第一次尝试时可能无法确定最佳的事实,如果在调用子模块一轮后,目标的真相仍然未知,可以删除所选的事实,然后再次调用子模块;这个过程可以重复多次。
规则选择
给出理论中的一组规则R和一个目标G,规则选择模块确定规则r∈R,使r的结果与G相统一,然后用这些规则将目标分解为子目标。
如果不能确定这样的规则,那么G的真相仍然是未知的。
规则选择同样包括两个子模块:第一个子模块确定每个规则的结果(与目标无关),第二个子模块将规则的结果和目标作为输入,并确定哪一个与目标相统一。
需要注意的是,由于BC的递归性质,规则选择模块在证明一个目标的过程中可能会被多次调用。由于识别每条规则的结果与目标无关,这个子模块只需要被调用一次。
目标分解
给定一个规则r和一个目标G,使r的结果与G统一,目标分解模块确定需要证明的子目标,以使G被证明或被否定。
在成功证明r的前项的情况下,目标是被证明还是被否定取决于目标的符号(sign)是否与r的结果符号一致。
例如对于目标「Fiona是红色的?」,由于目标的符号与第二条规则的结果符号一致,并且规则的前项被证明,可以得出结论,目标被证明。
符号一致性
给定一个规则r和一个目标G,符号一致模块验证r的结果符号是否与目标的符号一致或不一致。
实验部分
实验部分
研究人员选择Chain of Thought(CoT)、基于显式推理的sota神经推理方法、sota模块推理方法Selection Inference(SI)作为对比基线模型。
实验的数据集采用ProofWriter和PrOntoQA,这些数据集对LM推理具有挑战性,包含需要证明链长度达5跳的例子,以及目标既不能从提供的理论中证明也不能反驳的例子。
实验结果显示,LAMBADA明显优于其他两个基线,特别是在包含UNKNOWN标签的ProofWriter-PUD数据集上(与CoT相比有44%的相对改善,与SI在深度-5上相比有56%的改善),以及在PrOntoQA的较高深度上(与CoT相比有37%的相对改善,与SI在深度-5上相比有113%的改善)。
这些结果显示了LAMBADA在逻辑推理方面的优点,也显示了后向链(在LAMBADA中是推理的backbone)与前向链(在SI中是backbone)相比可能是更好的选择。
这些结果还揭示了CoT方法在处理UNKNOWN标签时的一个缺陷:与标签为证明(PROVED)或否定(DISPROVED)的例子不同,对于标签为UNKNOWN的例子,没有自然的思维链。
对于更深(3+)的证明链问题上,在三个数据集上,SI产生的预测接近于多数类预测。
可以发现,在二元情况下,它倾向于过度预测DISPROVED;在三元分类情况下,倾向于过度预测UNKNOWN,这使得它在PrOntoQA的深度-5中的表现甚至比多数类更差,因为该深度的PROVED标签比DISPROVED多。
不过研究人员也惊讶地发现,CoT对于ProofWriterPD数据集的性能仍然相对较高,而且准确率没有降低。
总之,在这些数据集上,LAMBADA具有更高的推理准确性,与其他用虚假的证明痕迹找到正确结论的技术相比,LAMBADA更有可能产生有效的推理链,同时也比其他基于LM的模块化推理方法更有查询效率。
研究人员表示,该实验结果强烈地表明,未来关于用LM进行推理的工作应该包括后向链或目标导向的策略。
微信扫码关注该文公众号作者