CLIPPO 是一种统一的模型,用单个编码器和对比损失来执行图像、文本和多模态任务,优于传统的 NLP 基线和之前基于像素的掩码语言模型。
近年来,基于 Transformer 的大规模多模态训练促成了不同领域最新技术的改进,包括视觉、语言和音频。特别是在计算机视觉和图像语言理解方面,单个预训练大模型可以优于特定任务的专家模型。然而,大型多模态模型通常使用模态或特定于数据集的编码器和解码器,并相应地导致涉及的协议。例如,此类模型通常涉及在各自的数据集上对模型的不同部分进行不同阶段的训练,并进行特定于数据集的预处理,或以特定于任务的方式迁移不同部分。这种模式和特定于任务的组件可能会导致额外的工程复杂性,并在引入新的预训练损失或下游任务时面临挑战。因此,开发一个可以处理任何模态或模态组合的单一端到端模型,将是多模态学习的重要一步。本文中,来自谷歌研究院(谷歌大脑团队)、苏黎世的研究者将主要关注图像和文本。
Image-and-Language Understanding from Pixels Only论文地址:https://arxiv.org/abs/2212.08045https://github.com/google-research/big_vision许多关键统一加速了多模态学习的进程。首先经证实,Transformer 架构可以作为通用主干,并且在文本、视觉、音频和其他领域上表现良好。其次,许多论文探索了将不同的模态映射到单个共享嵌入空间以简化输入 / 输出接口,或开发一个用于多个任务的单一接口。第三,模态的替代表示允许在一个领域中利用另一个领域设计的神经架构或训练程序。例如,[54] 和 [26,48] 分别表示文本和音频,通过将这些形式呈现为图像(在音频的情况下为频谱图)进行处理。本文将对使用纯基于像素的模型进行文本和图像的多模态学习进行探索。该模型是一个单独的视觉 Transformer,它处理视觉输入或文本,或两者一起,所有都呈现为 RGB 图像。所有模态都使用相同的模型参数,包括低级特征处理;也就是说,不存在特定于模态的初始卷积、tokenization 算法或输入嵌入表。该模型仅用一个任务训练:对比学习,正如 CLIP 和 ALIGN 所推广的那样。因此模型被称作 CLIP-Pixels Only(CLIPPO)。 在 CLIP 设计用于图像分类和文本 / 图像检索的主要任务上,尽管没有特定的 tower 模态,CLIPPO 的表现也与 CLIP 相似(相似度在 1-2% 之内)。令人惊讶的是,CLIPPO 不需要任何从左到右的语言建模、掩码语言建模或显式的词级损失,就可以执行复杂的语言理解任务。特别是在 GLUE 基准测试上,CLIPPO 优于经典的 NLP 基线,如 ELMO+BiLSTM+attention,此外,CLIPPO 还优于基于像素的掩码语言模型,并接近 BERT 的分数。有趣的是,当简单地将图像和文本一起渲染时,CLIPPO 也可以在 VQA 上获得良好的性能,尽管从未在此类数据上进行预训练。与常规语言模型相比,基于像素的模型的一个直接优势是不需要预先确定词汇。因此,与使用经典 tokenizer 的等效模型相比,多语言检索的性能有所提高。最后,该研究还发现,在某些情况下训练 CLIPPO 时,之前观察到的模态差距有所减少。CLIP 已经成为一种强大的、可扩展的范式,用于在数据集上训练多用途视觉模型。具体来说,这种方法依赖于图像 /alt-text 对,这些可以从网络上大规模自动收集。因此,文本描述通常是有噪音的,并且可能由单个关键字、关键字集或潜在的冗长描述组成。利用这些数据,联合训练两个编码器,即嵌入 alt-text 的文本编码器和将相应图像嵌入共享潜在空间的图像编码器。这两个编码器使用对比损失进行训练,鼓励相应图像和 alt-text 的嵌入相似,同时与所有其他图像和 alt-text 的嵌入不同。一旦经过训练,这样的编码器对可以以多种方式使用:它可以通过文本描述对固定的视觉概念集进行分类(零样本分类); 嵌入可用于检索给定文本描述的图像,反之亦然;或者,视觉编码器可以通过对标记的数据集进行微调或通过在冻结的图像编码器表示上训练头部,以有监督的方式传输到下游任务。原则上,文本编码器可以作为一个独立的文本嵌入使用,不过据悉,还没有人针对这种应用展开深入探讨,一些研究引用了低质量的 alt-text 导致文本编码器的语言建模性能较弱。以前的工作表明,图像和文本编码器可以用一个共享 transformer 模型(也称为单塔模型,或 1T-CLIP)实现,其中图像使用 patch embedding 嵌入,tokenized 文本使用单独的 word embedding 嵌入。除了模态特定的嵌入外,两种模态的所有模型参数都是共享的。虽然这种类型的共享通常会导致图像 / 图像 - 语言任务的性能下降,但它也使模型参数的数量减少了一半。CLIPPO 将这一想法更进一步:文本输入呈现在空白图像上,随后完全作为图像处理,包括初始的 patch embedding(参见图 1)。通过与之前的工作进行对比训练,生成了一个单一的视觉 transformer 模型,它可以通过单一的视觉接口来理解图像和文本,并提供了一个可以用于解决图像、图像 - 语言和纯语言理解任务的单一表示。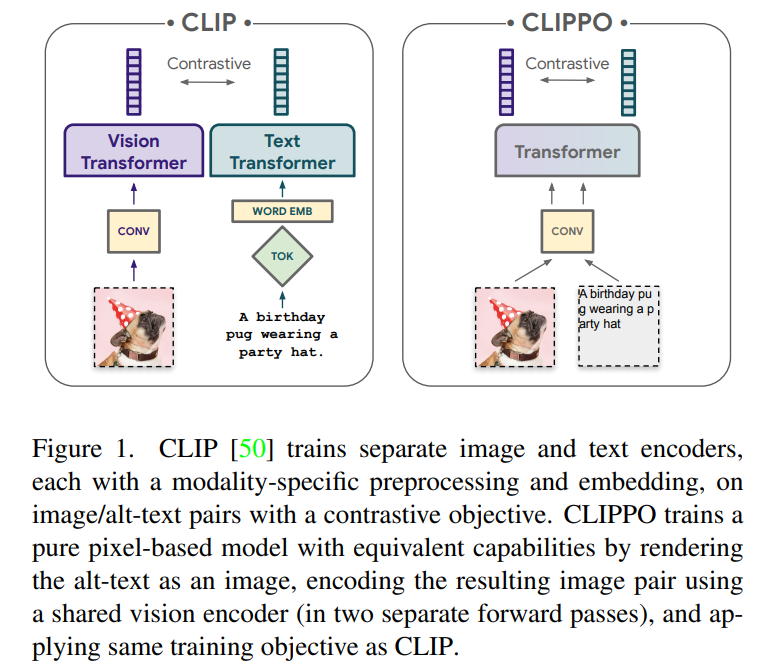
除了多模态多功能性,CLIPPO 还减轻了文本处理的常见困难,即开发适当的 tokenizer 和词汇表。这在大量多语言设置的上下文中特别有趣,其中文本编码器必须处理数十种语言。可以发现,在图像 /alt-text 对上训练的 CLIPPO 在公共图像和图像语言基准上的表现与 1T-CLIP 相当,并且在 GLUE 基准上与强大的基线语言模型竞争。然而,由于 alt-texts 的质量较低,通常不是语法句子,仅从 alt-texts 学习语言理解从根本上是有限的。因此,可以在图像 /alt-texts 对比预训练中加入基于语言的对比训练。具体而言,需要考虑到从文本语料库中采样的连续句对,不同语言的翻译句对,后翻译句对,以及有单词缺失的句子对。图像分类与检索。表 1 显示了 CLIPPO 的性能,可以看到,与 CLIP∗ 相比,CLIPPO 和 1T-CLIP 产生了 2-3 个百分点的绝对下降。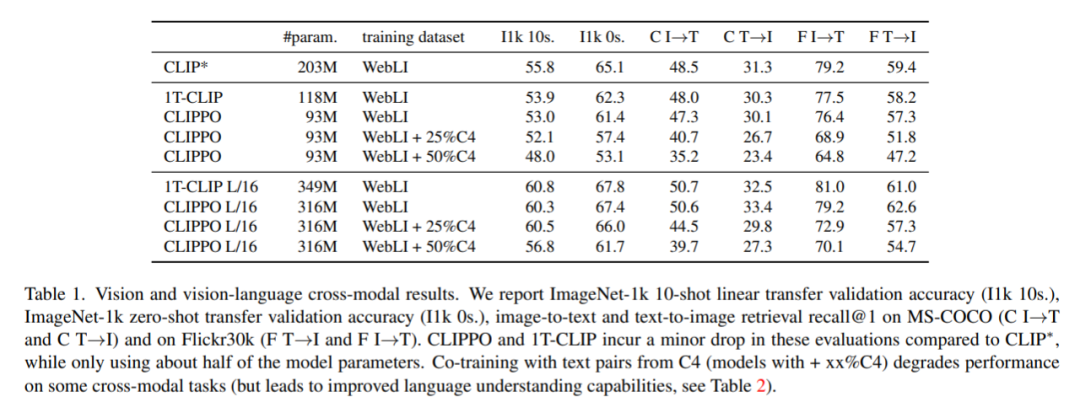
VQA。图 2 中报告了模型和基线的 VQAv2 评分。可以看到,CLIPPO 优于 CLIP∗ 、1T-CLIP,以及 ViT-B/16,获得了 66.3 的分数。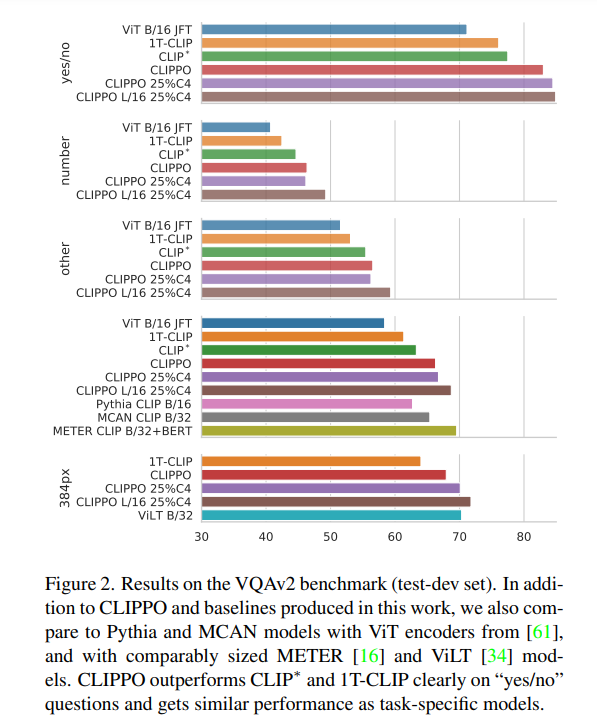
图 3 表明,CLIPPO 实现了与这些基线相当的检索性能。在 mT5 的情况下,使用额外的数据可以提高性能;在多语言上下文中利用这些额外的参数和数据将是 CLIPPO 未来一个有趣的方向。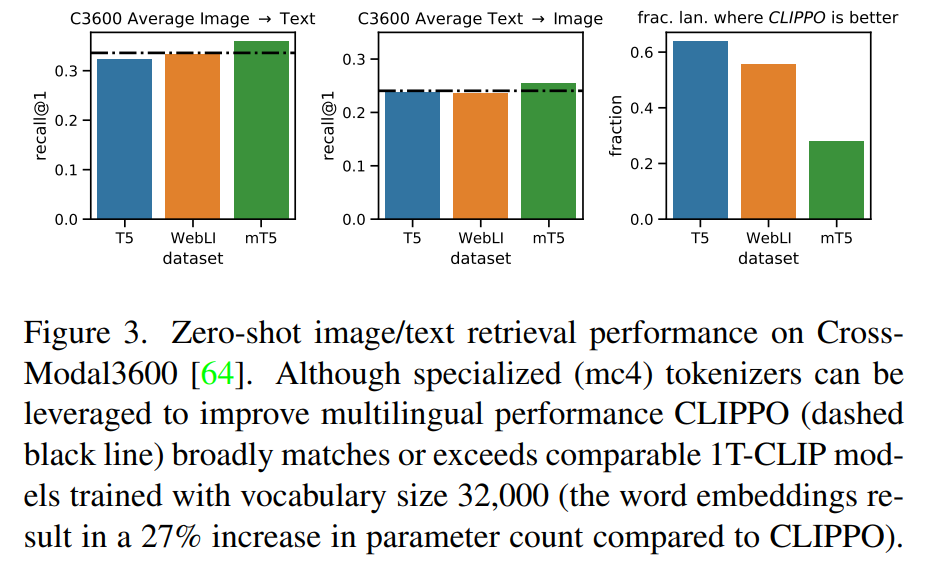
表 2 显示了 CLIPPO 和基线的 GLUE 基准测试结果。可以观察到,在 WebLI 上训练的 CLIPPO 与 BiLSTM+Attn+ELMo 基线(其具有在大型语言语料库上训练的深度词嵌入)相比具有竞争力。此外,我们还可以看到,CLIPPO 和 1T-CLIP 优于使用标准对比语言视觉预训练训练的语言编码器。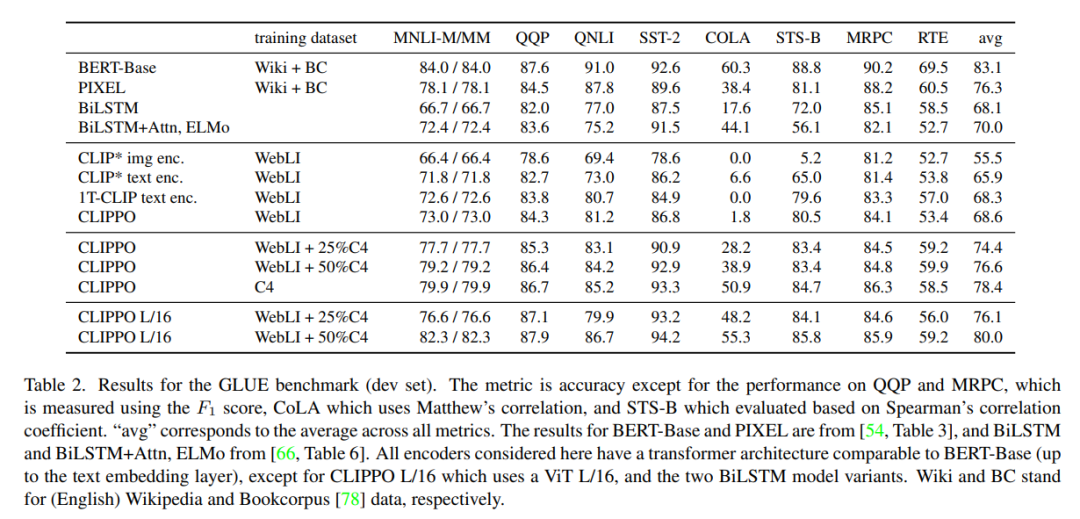
CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
多模态学习 交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-多模态学习 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态学习+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!

▲扫码进群
整理不易,请点赞和在看