在回答复杂的问题时,人类可以理解不同模态的信息,并形成一个完整的思维链(Chain of Thought, CoT)。深度学习模型是否可以打开「黑箱」,对其推理过程提供一个思维链呢?近日,UCLA 和艾伦人工智能研究院(AI2)提出了首个标注详细解释的多模态科学问答数据集 ScienceQA,用于测试模型的多模态推理能力。在 ScienceQA 任务中,作者提出 GPT-3 (CoT) 模型,即在 GPT-3 模型中引入基于思维链的提示学习,从而使得模型能在生成答案的同时,生成相应的推理解释。GPT-3 (CoT) 在 ScienceQA 上实现了 75.17% 的准确率;并且人类评估表明,其可以生成较高质量的解释。像人类一样有效地学习并完成复杂的任务是人工智能追求的长远目标之一。人类在决策过程中可以遵循一个完整的思维链(CoT)推理过程,从而对给出的答案做出合理的解释。然而,已有的机器学习模型大多依赖大量的输入 - 输出样本训练来完成具体的任务。这些黑箱模型往往直接生成最终的答案,而没有揭示具体的推理过程。科学问答任务(Science Question Answering)可以很好地诊断人工智能模型是否具有多步推理能力和可解释性。为了回答科学问题,一个模型不仅需要理解多模态内容,还需要提取外部知识以得出正确答案。同时,一个可靠的模型还应该给出揭示其推理过程的解释。然而,目前的科学问答数据集大多缺乏对答案的详细解释,或者局限于文字模态。因此,作者收集了全新的科学问答数据集 ScienceQA,它包含了 21,208 道来自中小学科学课程的问答多选题。一道典型的问题包含多模态的背景(context)、正确的选项、通用的背景知识(lecture)以及具体的解释(explanation)。
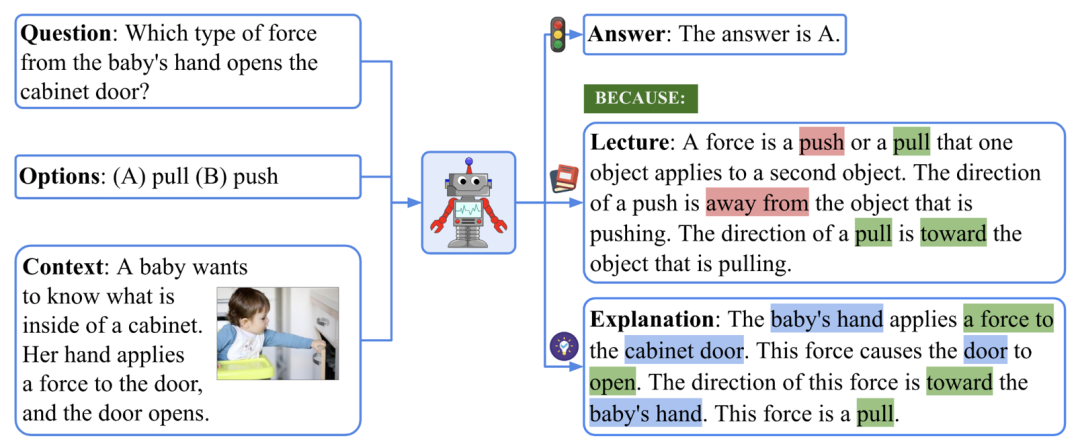
要回答上图所示的例子,我们首先要回忆关于力的定义:「A force is a push or a pull that ... The direction of a push is ... The direction of a pull is ... 」,然后形成一个多步的推理过程:「The baby’s hand applies a force to the cabinet door. → This force causes the door to open. → The direction of this force is toward the baby’s hand. 」,最终得到正确答案:「This force is a pull. 」。在 ScienceQA 任务中,模型需要在预测答案的同时输出详细地解释。在本文中,作者利用大规模语言模型生成背景知识和解释,作为一种思维链(CoT)来模仿人类具有的多步推理能力。实验表明,目前的多模态问答方法在 ScienceQA 任务不能取得很好的表现。相反,通过基于思维链的提示学习,GPT-3 模型能在 ScienceQA 数据集上取得 75.17% 的准确率,同时可以生成质量较高的解释:根据人类评估,其中 65.2% 的解释相关、正确且完整。思维链也可以帮助 UnifiedQA 模型在 ScienceQA 数据集上取得 3.99% 的提升。
论文标题:
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
https://arxiv.org/abs/2209.09513
https://scienceqa.github.io/
https://github.com/lupantech/ScienceQA
https://scienceqa.github.io/explore.html
https://scienceqa.github.io/leaderboard.html

ScienceQA数据集
数据集统计
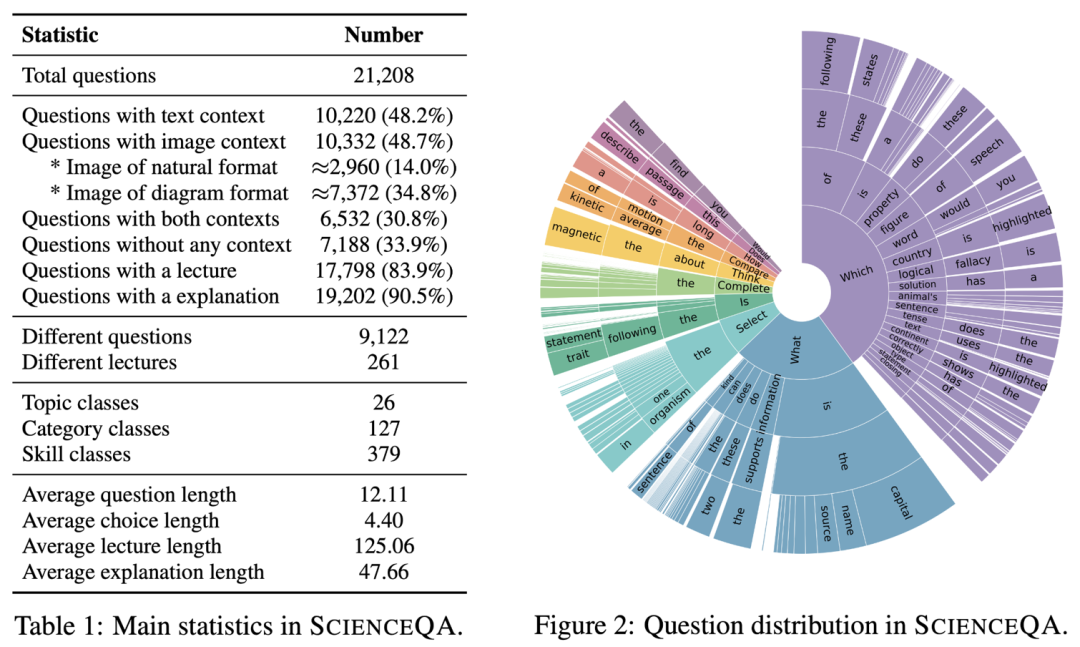
ScienceQA 包含 21208 个例子,其中有 9122个不同的问题(question)。10332 道(48.7%)有视觉背景信息,10220 道(48.2%)有文本背景信息,6532 道(30.8%)有视觉 + 文本的背景信息。绝大部分问题标注有详细的解释:83.9% 的问题有背景知识标注(lecture),而 90.5% 的问题有详细的解答(explanation)。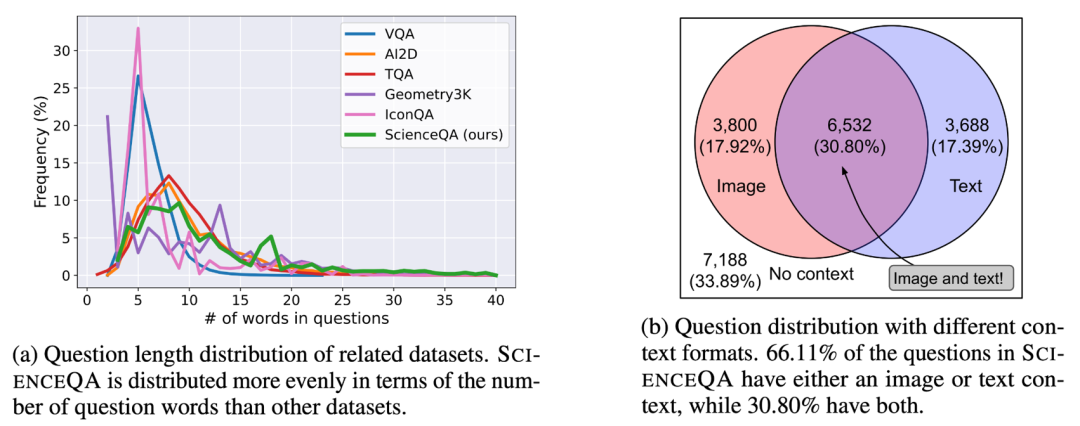
不同于已有的数据集,ScienceQA 涵盖自然科学、社会科学和语言学三大学科分支,包含 26 个主题(topic)、127 个分类(category)和 379 个知识技能(skill)。
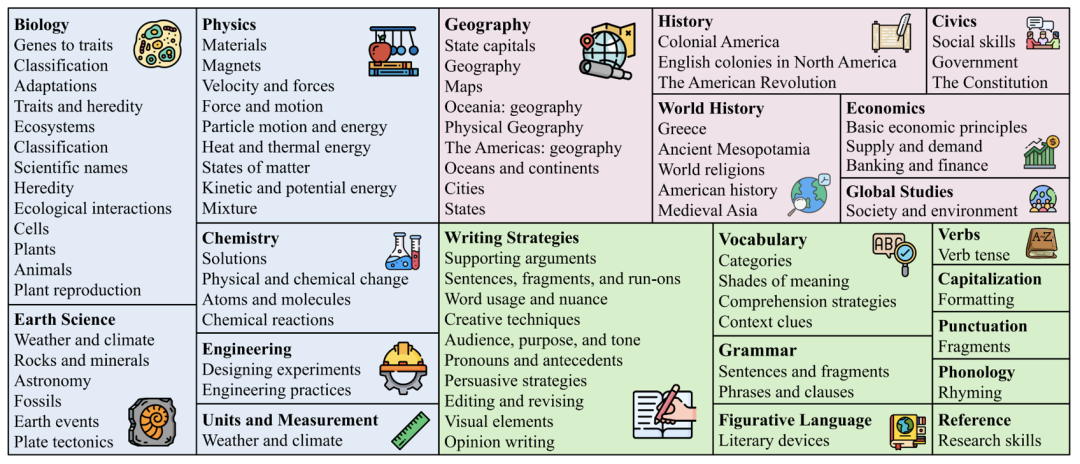
如下图的词云分布所示,ScienceQA 中的问题具有丰富的语义多样性。模型需要理解不同的问题表达、场景和背景知识。

ScienceQA 是第一个标注详细解释的多模态科学问答数据集。相比于已有的数据集,ScienceQA 的数据规模、题型多样性、主题多样性等多个维度体现了优势。
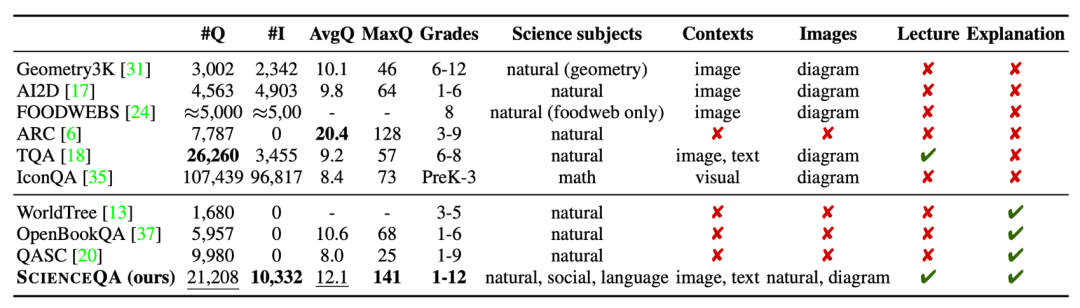
▲ ScienceQA 数据集与其它科学问答数据集的比较Baselines
作者在 ScienceQA 数据集了评估不同的基准方法,包括 VQA 模型如 Top-Down Attention、MCAN、BAN、DFAF、ViLT、Patch-TRM 和 VisualBERT,大规模语言模型如 UnifiedQA 和 GPT-3,以及 random chance 和 human performance。对于语言模型 UnifiedQA 和 GPT-3,背景图片会被转换成文本形式的注释(caption)。最近的研究工作表明,在给定合适的提示后,GPT-3 模型可以在不同的下游任务表现出卓越的性能。为此,作者提出 GPT-3 (CoT) 模型,在提示中加入思维链(CoT),使得模型在生成答案的同时,可以生成对应的背景知识和解释。具体的提示模板如下图所示。其中 Ii 表示训练例子,It 表示测试例子。训练例子包含问题(Question)、选项(Options)、背景(Context)和答案(Answer)元素,其中答案由正确答案、背景知识(Lecture)和解释(Explanation)组成。GPT-3 (CoT) 会根据输入的提示信息,补全测试例子的预测答案、背景知识和解释。

不同的基准和方法在 ScienceQA 测试集上的准确率结果如下表所示。当前最好的 VQA 模型之一的 VisualBERT 只能达到 61.87% 的准确率。在训练的过程引入 CoT 数据,UnifiedQA_BASE 模型可以实现 74.11% 的准确率。而 GPT-3 (CoT) 在 2 个训练例子的提示下,实现了 75.17% 的准确率,高于其它基准模型。人类在 ScienceQA 数据集上表现优异,可以达到 88.40% 的总体准确率,并且在不同类别的问题上表现稳定。
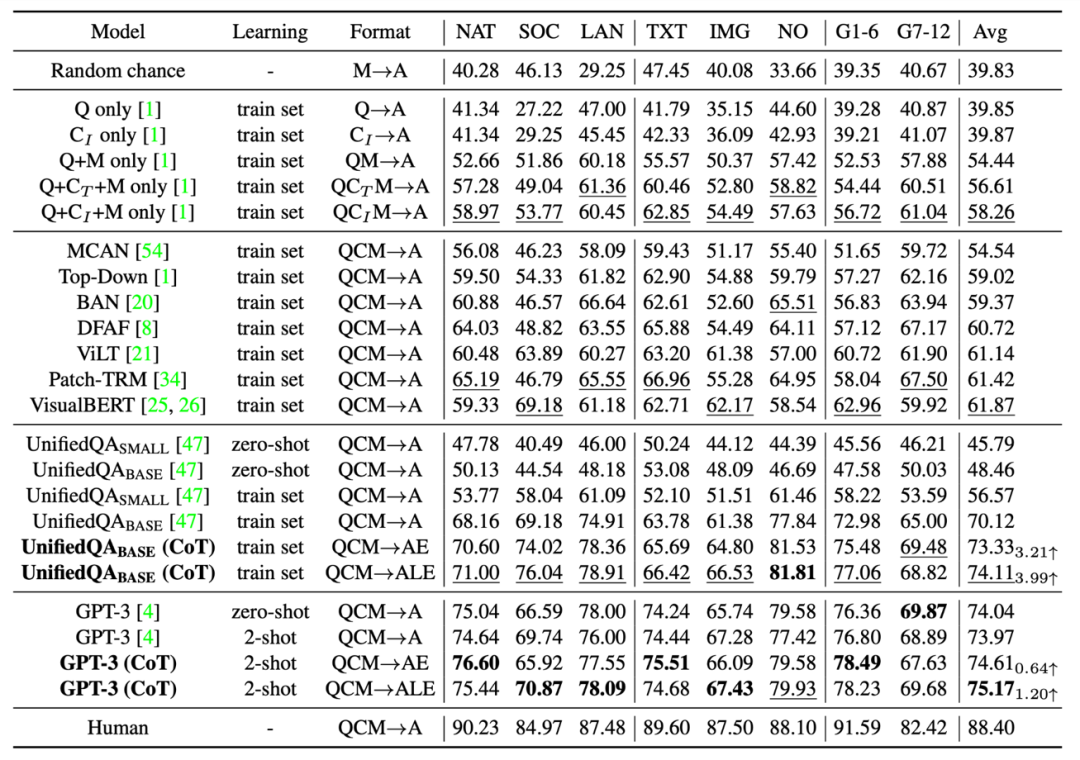
▲ 不同的方法在 ScienceQA 测试集上的结果作者用自动评估指标如 BLEU-1、BLEU-2、ROUGE-L 和 Sentence Similarity 评估了不同方法生成的解释。由于自动评估指标只能衡量预测结果和标注内容的相似性,因此作者进一步采用了人工评估的方法,来评估生成解释的相关性、正确性和完整性。可以看到,GPT-3 (CoT) 生成的解释中 65.2% 符合了 Gold 标准。

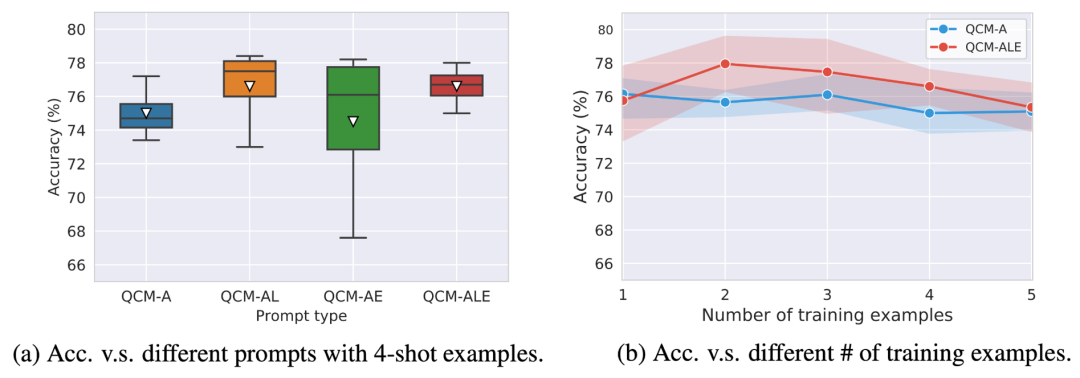
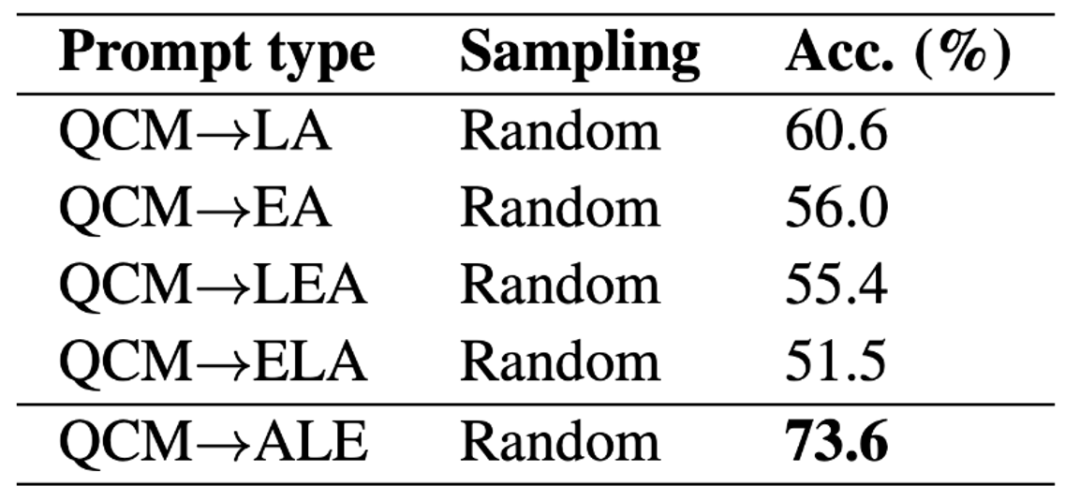
作者比较了不同的提示模板对 GPT-3 (CoT) 准确率的影响。可以看到在 QAM-ALE 的模板下,GPT-3 (CoT) 可以获得最大的平均准确率和最小的方差。另外,GPT-3 (CoT) 在 2 个训练例子的提示下,表现最佳。
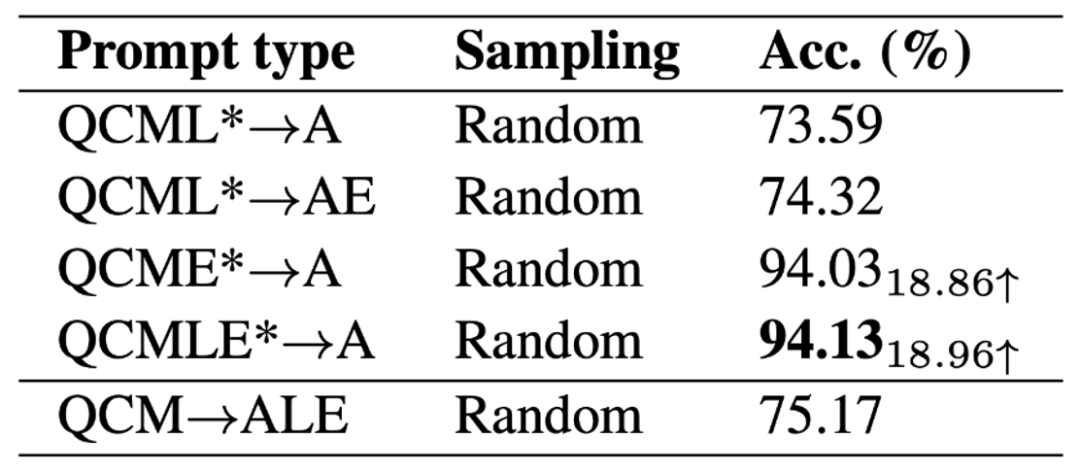
为了探索 GPT-3 (CoT) 模型的性能上限,作者把标注的背景知识和解释加入模型的输入(QCMLE*-A)。我们可以看到 GPT-3 (CoT) 可以实现高达 94.13% 的准确率。这也提示了模型提升的一个可能方向:模型可以进行分步推理,即先检索到准确的背景知识和生成准确的解释,然后把这些结果作为输入。这个过程和人类解决复杂问题的过程很相似。
作者进一步讨论了 GPT-3 (CoT) 在生成预测时,不同的 ALE 位置对结果的影响。在 ScienceQA 上的实验结果表明,如果 GPT-3 (CoT) 先生成背景知识 L 或解释 E,再生成答案 A,其预测准确率会大幅下降。其主要原因是背景知识 L 和解释 E 有较多的词语数量,如果先生成 LE,GPT-3 模型有可能用完最大词数,或者提前停止生成文本,从而不能得到最终的答案 A。
如下 4 个例子中,GPT-3 (CoT) 不但能生成正确的答案,也能给出相关、正确且完整的解释。这说明 GPT-3 (CoT) 在 ScienceQA 数据集上表现出较强的多步推理和解释能力。
▲ GPT-3 (CoT) 生成正确答案和解释的例子在下面的三个例子中,GPT-3 (CoT) 虽然生成了正确的答案,但是生成的解释不相关、不正确或者不完整。这说明 GPT-3 (CoT) 对于生成逻辑一致的长序列还面临较大的困难。
▲ GPT-3 (CoT) 能生成正确答案、但是生成的解释不正确的例子在下面的四个例子中,GPT-3 (CoT) 不能生成正确的答案,也不能生成正确的解释。其中的原因有:1)当前的 image captioning 模型还不能准确地描述示意图、表格等图片的语义信息,如果用图片注释文本表示图片,GPT-3 (CoT) 还不能很好地回答包含图表背景的问题;2)GPT-3 (CoT) 生成长序列时,容易出现前后不一致(inconsistent)或不连贯(incoherent)的问题;3)GPT-3 (CoT) 还不能很好地回答需要特定领域知识的问题。

▲ GPT-3 (CoT) 能生成错误答案和解释的例子
结论与展望
作者提出了首个标注详细解释的多模态科学问答数据集 ScienceQA。ScienceQA 包含 21208 道来自中小学科学学科的多选题,涵盖三大科学领域和丰富的话题,大部分问题标注有详细的背景知识和解释。ScienceQA 可以评估模型在多模态理解、多步推理和可解释性方面的能力。作者在 ScienceQA 数据集上评估了不同的基准模型,并提出 GPT-3 (CoT) 模型在生成答案的同时,可以生成相应的背景知识和解释。大量的实验分析和案例分析对模型的改进提出了有利的启发。
[1] Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, Ashwin Kalyan, et al. Learn to explain: multimodal reasoning via thought chains for science question answering. In Advances in neural information processing systems (NeurIPS), 2022.
[2] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.[3] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In Advances in neural information processing systems (NeurIPS), 2020.[4] Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. UnifiedQA: Crossing format boundaries with a single qa system. In Findings of the Association for Computational Linguistics (EMNLP), 2020.[5] Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
