
来源:内容由半导体行业观察(ID:icbank)编译自nextplatform,谢谢。
当谈到操作系统和现在的 CPU 指令集时,有专有的,有可许可的和可修改的,具有标准的功能基础,并有一些独创性的空间,还有真正的开源。你认为哪一个在最长的比赛中获胜?几十年来,对于数据中心中的许多应用程序,操作系统遵循了从专有系统到开放系统再到开源的路径,从大型机上的 MVS 和小型机上的 VMS、OS/400 和 MPE 等稳固的平台发展成为大型机级服务器,到 Solaris、HP-UX、AIX 和许多 Unix 变体,它们最终遵循一个通用的 1,170 个 API 以提供少量的应用程序可移植性,最后到开源 Linux,它最初是一个基本的 Unix-类似于内核,并且已经发展成为一个真正的平台。专有平台,最著名的是微软的 Windows Server,还有来自蓝色巨人的 IBM i 和 z/OS,它们仍然在数据中心中持续存在并激增,尤其是 IBM 的 AIX,作为最后一个商业 Unix 发行版,就其所有意图和目的而言,它是一个专有平台,有望随着 Solaris 和 HP-UX 消亡。历史不需要重复,但如果有充分的理由,它看起来肯定会强制重复。很难与开源的哲学和社区争论,这就是为什么我们中的许多人(包括我们在The Next Platform 的这里)认为开源芯片是不可避免的。因此,我们一直密切关注 RISC-V 的努力,以创建一个开源芯片架构,该架构涵盖从最小的嵌入式设备到大型系统和超级计算机。但重要的是不要太兴奋。体系结构及其操作系统得以持续存在,因为它需要数万亿行代码和数千万程序员才能运行这个世界,而且您无法一次更改所有内容。事实上,你不可能在几十年内改变一切。遗留应用程序及其平台出于良好的经济原因而持续存在,投资摊销只是其中的一部分。为改变而改变不是企业负担得起的,它们只会在确实需要时才改变。因此,Windows Server 是操作系统的 X86,或者 X86 是芯片的 Windows Server,这取决于你如何看待它,两者都将在一定程度上对抗 Linux 和 Arm,因为没有人会重写 Windows 生产力工具集或企业中所有那些无数行的 Visual Basic 和 C# 代码。就像一些大型机应用程序在 Unix 系统的巨大压力下仍然存在一样,从很多方面来看,这些系统可以说是更好、更便宜的平台。尽管 RISC 有很多好处,但企业仍然厌恶风险。降低风险,就像近年来随着亚马逊的 Graviton、阿里巴巴的倚天和Ampere Computing 的 Altra的崛起而出现的 Arm 服务器 CPU 一样。然而,你总是会为活在过去付出额外的代价。我们现在正在 AWS 上看到这种情况,因为Graviton2 实例为相同数量的工作提供比 X86 实例高 10% 到 40% 的性价比。在我们观察数据中心的三年半时间里,我们制定了一条经验法则,该法则非常适用,因为摩尔定律和其他竞争压力影响了系统。至少对于数据库处理系统,大型机每单位工作的成本大约是 Unix 系统的两倍,而 Unix 系统每单位工作的成本大约是 Windows Server 或 Linux 系统的两倍。较小的专有系统最初的出价比 Unix 贵一点,但由于 1990 年代末和 2000 年代初的竞争压力,剩下的少数系统全部标准化。Arm 平台最终可能会在性价比方面提供另一个 2 倍的功能。从 X86 通过 SPARC 回到 X86 再到 ARM 再到 RISC-V 的道路
如果 AWS 放弃 Graviton 与 X86 相比的 40%,你可以打赌它的 Graviton 平台甚至比定价更便宜,而且该公司也在这里获得了一些利润。或者,如果不是,AWS 正在玩一场长期游戏,以便在它控制自己的平台后进一步提高利润率。考虑到所有这些,我们考虑了 Ventana Micro Systems,它于 2021 年 9 月退出了隐身模式,并且一直在努力研究基于 RISC-V 指令集的服务器 CPU 设计。我们采访了联合创始人 Balaji Baktha(首席执行官)和 Greg Favor(首席架构师),了解了 Ventana 正在开发的现在称为Veyron RISC-V CPU 系列的最新信息。目前尚不清楚为什么 Ventana 的名字中有“微”——习惯的力量?向 Sun Microsystems 和 Advanced Micro Devices 以及 Applied Micro Circuits 致敬?– 因为它的愿望一点也不微观。Baktha 和 Favor 之前都走过这条路,试图将新的 ISA 推入数据中心。因此他们知道该做什么,同样重要的是,他们知道不该做什么。Baktha 一直从事半导体行业,在 Dot-Com 繁荣期间,他是一家 iSCSI 芯片初创公司的联合创始人之一,该公司于 2001 年被 Adaptec 收购,后来被 Microsemi 收购。Baktha 于 2002 年搬到 Marvell,负责其无线、存储、嵌入式和新兴市场的多个业务部门,帮助运营 Pi Mobile 和 Insilica 一段时间,然后创立了 Veloce Technologies,于 2010 年成立,是第一个 64-位 Arm 服务器和存储芯片。Applied Micro 于 2015 年 7 月收购了 Veloce,其知识产权和设计团队实际上是 X-Gene 产品线的基础,自The Next Platform成立以来我们一直密切关注该产品线这些年来。Applied Micro 将两代 X-Gene 处理器投入该领域,但没有达到逃逸速度,该技术最终通过 MACOM 成为 2017 年 Ampere Computing 的基础。在 2018 年 7 月共同创立 Ventana 以开发 RISC-V 服务器芯片之前,Baktha 曾涉足帮助初创企业并担任 Apex Semiconductor 的董事长。在过去的两年里,Baktha 一直是 RISC-V International 的董事会成员,这大致类似于 Linux 风格的 CPU 社区。Greg Favor 之前与 Baktha 有过交集,他们一起工作也就不足为奇了。早在 1983 年,Favor 就开始在 Zilog 担任设计工程师,然后在一家名为 Nexgen Microsystems 的芯片初创公司担任高级设计工程师,该公司在 1990 年代后期的 586/Pentium 几代中创建了一系列克隆 X86 处理器,为英特尔提供了一些胃灼热。在 Nexgen 工作一年后,Favor 决定自己出击,并于 1989 年创立了 Tera Microsystens,在那里他是 Sparc 工作站处理器克隆的首席架构师,名为 microCORE,有趣的是,惠普使用 1,000 纳米工艺制造了该处理器。像许多芯片设计师一样,Favor 经常四处走动,以便总是有有趣的工作。在 Dot-Com 繁荣之后,他是宽带网络芯片设备制造商 Redback Networks 的处理器设计师,并于 2005 年在隐秘的 CPU 制造商 Montalvo Systems 工作了三年,该公司于 2008 年被 Sun Microsystems 收购,当时它正处于垂死挣扎寻找自救的方法。2009 年,当 Sun 被 Oracle 收购时,Favor 转任 Applied Micro 的处理器工程副总裁 - 你猜对了。因此,从某种意义上说,Favor 从事的是 Baktha 多年前开始的 Arm 服务器相关工作。Applied Micro 在 2017 年被卖给了 MACOM,但 MACOM 真正想要的并不是 X-Gene Arm 服务器芯片,而是它在通信电路方面的专业知识。这就是为什么 X-Gene 设计和许多创建它的团队最终落入凯雷集团手中,成为 Ampere Computing 的基础。Favor 在 Ampere Computing 工作了一年,休假一年从事一些隐秘的工作,然后在 2019 年成为 Baktha of Ventana 的联合创始人。这将 Baktha 和 Favor 带到了 RISC-V,许多人称之为 MIPS 架构的第五代,以及真正开放架构的好处,并避免让其他人完全控制可以添加和不能添加的内容的暴政到一个架构。Baktha 表示,对于 Arm,像 Veloce 和 AppliedMicro 这样的芯片设计者会弄清楚超大规模和云构建者需要什么,弄清楚如何实施它,向 Arm Holdings 展示如何去做,然后收取架构许可费以访问他们的功能帮助定义和构建。“在 Arm 上花费 1 亿美元之后,”Baktha 告诉The Next Platform,“我们意识到这是一个封闭的生态系统,这不是开放的,我们只是从垄断变成了双头垄断,我们意识到,好吧,够了。”因此,Baktha 和 Favor 抓住了 RISC-V 架构和一群架构师,并模拟了如何扩展它以支持针对特定数据中心工作负载的 CPU 核心之上和之外的各种加速,甚至早在 2018 年,它就可以预期在任何地方比基本 RISC-V 设计提升了 30% 到 70%。“众所周知,如果你看看 CPU 从 16 纳米到 10 纳米再到 7 纳米时获得的原始性能,它已经在下降,”Baktha 说,并补充说这是一个我们都知道的故事一切顺利。“你花费了数十亿美元来获得 7% 或 8% 的性能提升。但是通过引入两件事——领域特定的加速和可组合性——我们能够在晶体管优势的基础上实现 30% 到 70% 的优势。但从根本上说,要实现这一目标,关键在于提出一个单插槽性能数字,该数字与 X86 和 Arm 供应商在 250 至 300 瓦的范围内所能提供的性能相当或更好。如果你做不到,继续前进,那就别费心了。您还需要使用缓存一致性架构来加速工作负载。如果你不做缓存一致性架构,如果你做的是两级计算——CPU 和 CPU,无论如何——那就是输家的游戏。所以如果你能把这两件事结合起来,你就有了一个成功的公式。这是 Ventana 打造世界级处理器的立业前提。我们以 5 纳米 TSMC 为起点开始做这件事,我们已经能够达到 3.6 GHz,我们的核心功率是首屈一指的。”从 RISC-V 开始,Ventana 拥有全新的平台和高度精简的指令集,而 Veyron V1 处理器内核为每个内核配备了 Baktha 所说的“强大”的私有 L1 和 L2 缓存。这些核心与高性能(和专有)互连互连,存在互连层次结构,实际上,允许将 16 核小芯片粘合在一起形成更大的处理器复合体,而不是拥有一个大结构,它变成作为许多架构的瓶颈,Veyron 互连可以扩展内存、I/O 和芯片互连,从而可以保持核心的供电。Veyron 处理器具有服务器级芯片所期望的所有标准虚拟化挂钩以及内存和 I/O 中断。目前,Ventana 在 Veyron V1 上展示了其 16 核小芯片的设计,并与一家未具名的合作伙伴合作开发 I/O 芯片。(Alphawave Semi?Marvell?我们根据您稍后会看到的一些信息猜测 Marvell)这似乎意味着 Ventana 将使用类似 NUMA 的方法来构建插槽,就像 AMD 对其 Epyc 处理器所做的那样,中间有一个 I/O 和内存芯片,核心的小芯片挂在上面。但是这个有一些有趣的曲折,看起来像。根据我们得到的介绍,Veyron 互连是一种“高性能并行 D2D 互连”,具有“最低延迟和功耗”并且“高度可扩展”。幻灯片增加了一些洞察力: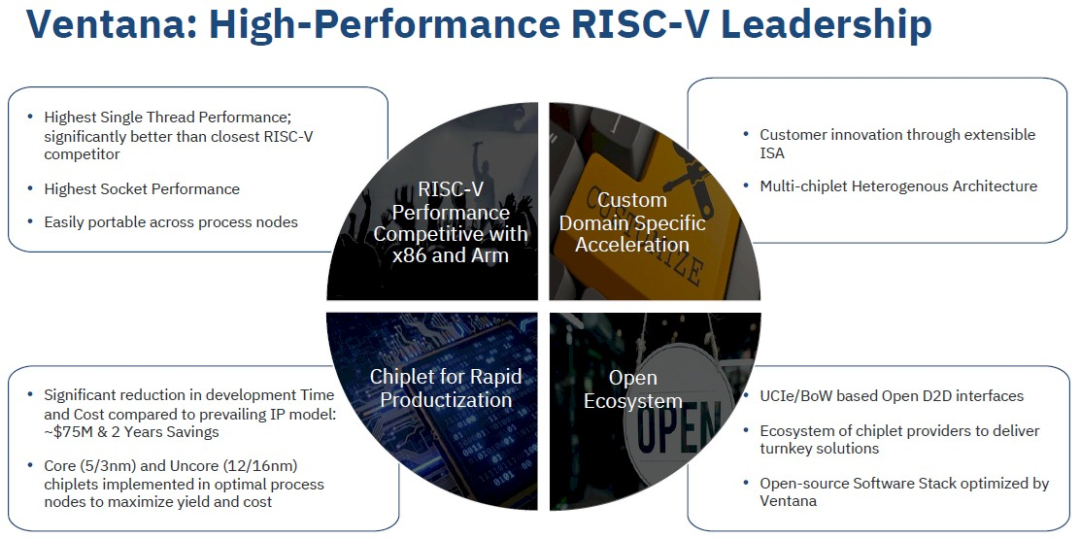
如果您查看右下角的饼图,您会看到标有 Veyron 将使用“基于 UCIe/BoW 的开放式 D2D 接口”的项目符号,这确实很有趣。您还将在右侧看到与 Veyron V1 和 V2 处理器一起使用的小芯片组合。在 Veyron V1 中,核心小芯片采用台积电的 5 纳米工艺实现,而非核心芯片(事实证明是 I/O 和内存芯片)采用 16 纳米工艺蚀刻。对于 Veyron V2,看起来内核缩小到 3 纳米工艺,I/O 和内存芯片将缩小到 12 纳米。考虑到 GlobalFoundries 没有 16 纳米工艺,我们假设台积电是这些 I/O 芯片的代工厂。(然而,它确实有 14 纳米和 12 纳米。)节点的混合旨在最大限度地提高芯片良率,并降低组装计算复合体的成本。
V1 内核确实看起来像现代 RISC 处理器,具有八宽指令流水线。在 5 纳米,它可以将时钟速度推高至 3.6 GHz。不要太兴奋。这不是基本时钟速度,许多核心复合体中的所有内核都已启动,就我们而言,这是最重要的时钟速度。Favor 表示,如果客户希望将所有内核的性能提升到 3 GHz 以上,那么每个内核将消耗大约 2 瓦特。如果可以降至 2.5 GHz,则每个内核的功耗将在 1 瓦到 1.5 瓦之间。如果您想让所有核心都满负荷运行,同时保持较低的热量,您可以以 1.8 GHz 至 2 GHz 的频率驱动它,并且每个核心的功率仍远低于 1 瓦。Baktha 表示,在相同的性能范围内,X86 内核的性能将是 2 到 4 倍。Favor 解释说:“每个内核都是一个积极的、乱序的、高性能的、英特尔级性能内核。” “当有些人说高性能时,他们并不是这个意思。每个核心大约有两平方毫米,所以它远不及 X86 核心那么大,而且它也是单线程的,所以没有超线程。因此,每个线程都是一个相对较小但功能强大的核心,相对省电。从缓存层次结构的角度来看,每个内核中基本上有 1 兆字节的private cash ——0.5 兆字节的一级指令缓存——以及一系列专利创新,使我们能够获得大型一级缓存的好处,在小缓存的延迟。然后我们在层次结构中有超过半兆字节的数据缓存。然后还有一个高达 48 兆字节的 cluster0level 共享 L3 缓存。”准确地说,V1 内核有一个 512 KB L1 指令缓存和一个合理的 64 KB L1 数据缓存,然后是另一个相当瘦的 512 KB L2 数据缓存。(AMD 的“Genoa”Epyc 9004 和 Ampere Computing 的 Altra Max 每个内核有 1 MB 的二级缓存,而英特尔的“Sapphire Rapids”Xeon SP 每个内核有 2 MB 的二级缓存。)但是 Veyron V1 有一个巨大的 48 MB 的 L3每个 V1 核心复合体的缓存,这是一个巨大的 576 MB L3 缓存,用于 12 芯片复合体和令人头脑麻木的 768 MB L3 缓存。Genoa 最高为每个插槽 384 MB 的 L3 缓存,Sapphire Rapids 最高为 112.5 MB,而 Altra Max 最高仅为 16 MB。如果内存子系统能够保持高速缓存的供给并且它不会一直丢失,那么 Veyron V1 的性能应该相当惊人。整洁的一点是连贯总线,D2D 接口实际上实现了 Arm 的 AMBA CHI 互连接口的建议,进一步的图表表明它在 BoW(线束)并行传输上运行 AMBA CHI,特别是那个开放计算项目一直在推动。“核心集群上的一切都通过基于增强版 AMBA CHI 的高带宽、低延迟一致总线连接在一起。但是,如果你愿意的话,从集群到 SOC 再到世界其他地方的接口只是标准的 CHI。Veyron 互连在一个插槽中可扩展至 12 个小芯片,用于 192 个内核,但看起来整个规模将保留给 Veyron V2。将于今年下半年早些时候出样的 Veyron V1 将配备 8 个 16 核小芯片,一个插槽中总共有 128 个核。这与今年晚些时候推出的 AMD 基于“Bergamo”Epyc Zen 4 的 X86 服务器芯片一样好,与 Ampere Computing 使用其当前的 Altra Max Arm 服务器芯片所做的一样好。
Ventana 不只是销售自己成熟的服务器 CPU。它与 I/O 和内存芯片合作,并创建了 V1 内核,它希望为客户提供可选的消费方式,并节省将计算复合体(很可能是混合计算复合体)推向市场的资金。客户可以获得芯片 IP 许可,他们可以购买小芯片并将其与他们自己的自定义 I/O 和内存集线器(可能带有加速器)混合使用,或者他们可以购买具有特定数量的 V1 内核的复合体Ventana 与其未具名合作伙伴创建的 I/O 和内存集线器。这给我们带来了性能,Ventana 提供了这张图表,显示了英特尔“Ice Lake”Xeon SP、AMD Epyc 7763 和 AWS Graviton3 处理器上每个插槽的实际 SPEC 整数吞吐量性能与 Veyron V1 的估计性能的对比: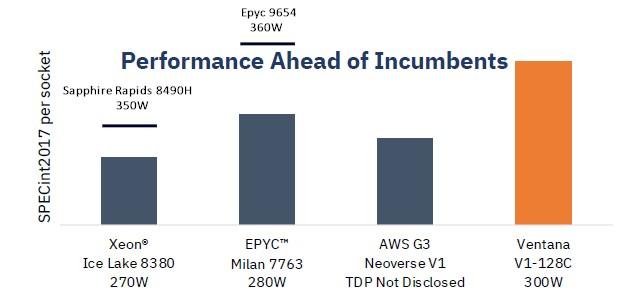
显然,我们现在拥有更新的英特尔和 AMD 芯片,它们将缩小性能差距,但显然,这对于首次通过 RISC-V 服务器插槽来说非常好。只是为了好玩,我们估计了新的顶级 60 核 Sapphire Rapids Xeon SP-8490H 和类似的新顶级 96 核 Genoa Epyc 9654 的 SPECint2017 性能。Ventana 现在正在为基于 FPGA 的 Veyron V1 提供开发套件,并将在今年第三季度开始样品,尽早完成。很快,RISC-V 将在数据中心运行。我们将密切关注谁对此感兴趣,以及为什么。*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3337期内容,欢迎关注。
『半导体第一垂直媒体』
实时 专业 原创 深度
识别二维码,回复下方关键词,阅读更多
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装
回复 投稿,看《如何成为“半导体行业观察”的一员 》
回复 搜索,还能轻松找到其他你感兴趣的文章!