关于 PyTorch 炼丹,本文作者表示:「如果你有 8 个 GPU,整个训练过程只需要 2 分钟,实现 11.5 倍的性能加速。」
最近,知名机器学习与 AI 研究者 Sebastian Raschka 向我们展示了他的绝招。据他表示,他的方法在不影响模型准确率的情况下,仅仅通过改变几行代码,将 BERT 优化时间从 22.63 分钟缩减到 3.15 分钟,训练速度足足提升了 7 倍。作者更是表示,如果你有 8 个 GPU 可用,整个训练过程只需要 2 分钟,实现 11.5 倍的性能加速。首先是模型,作者采用 DistilBERT 模型进行研究,它是 BERT 的精简版,与 BERT 相比规模缩小了 40%,但性能几乎没有损失。其次是数据集,训练数据集为大型电影评论数据集 IMDB Large Movie Review,该数据集总共包含 50000 条电影评论。作者将使用下图中的 c 方法来预测数据集中的影评情绪。基本任务交代清楚后,下面就是 PyTorch 的训练过程。为了让大家更好地理解这项任务,作者还贴心地介绍了一下热身练习,即如何在 IMDB 电影评论数据集上训练 DistilBERT 模型。如果你想自己运行代码,可以使用相关的 Python 库设置一个虚拟环境,如下所示:现在省略掉枯燥的数据加载介绍,只需要了解本文将数据集划分为 35000 个训练示例、5000 个验证示例和 10000 个测试示例。需要的代码如下: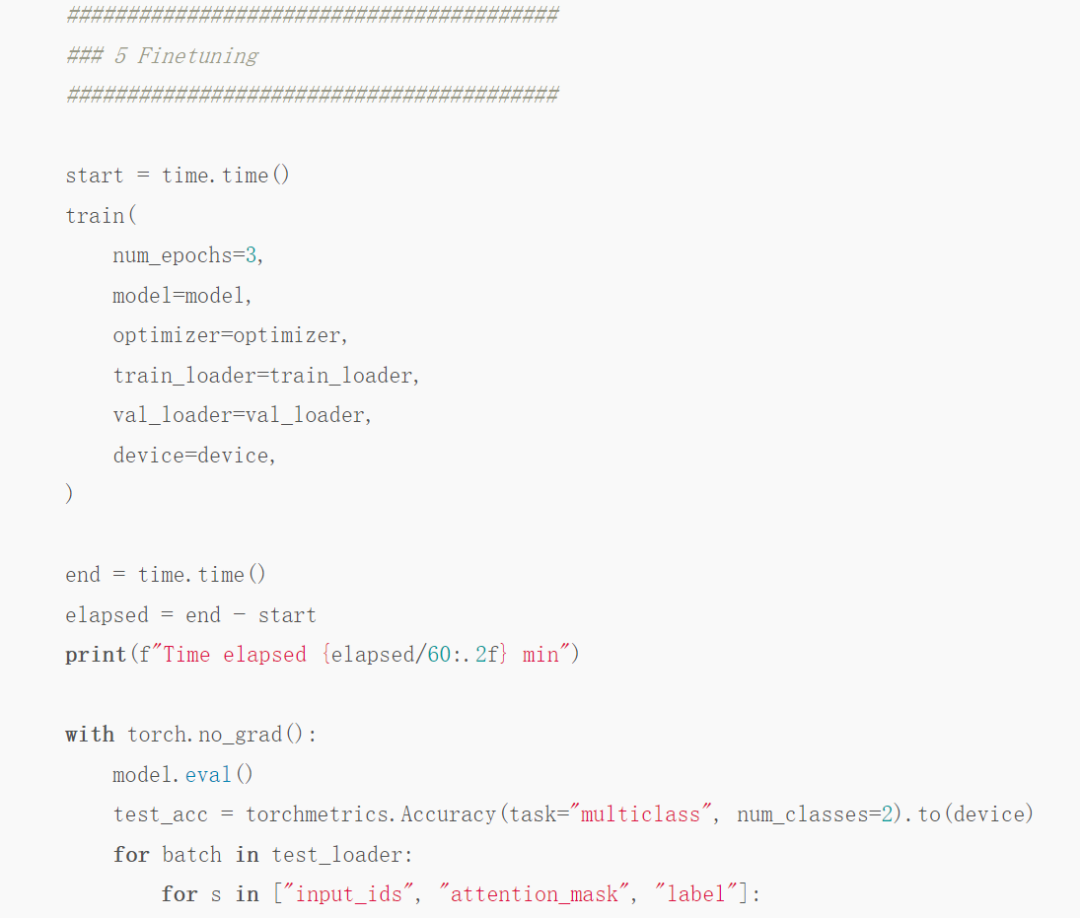
https://github.com/rasbt/faster-pytorch-blog/blob/main/1_pytorch-distilbert.py然后在 A100 GPU 上运行代码,得到如下结果:

正如上述代码所示,模型从第 2 轮到第 3 轮开始有一点过拟合,验证准确率从 92.89% 下降到了 92.09%。在模型运行了 22.63 分钟后进行微调,最终的测试准确率为 91.43%。接下来是改进上述代码,改进部分主要是把 PyTorch 模型包装在 LightningModule 中,这样就可以使用来自 Lightning 的 Trainer 类。部分代码截图如下:
完整代码地址:https://github.com/rasbt/faster-pytorch-blog/blob/main/2_pytorch-with-trainer.py上述代码建立了一个 LightningModule,它定义了如何执行训练、验证和测试。相比于前面给出的代码,主要变化是在第 5 部分(即 ### 5 Finetuning),即微调模型。与以前不同的是,微调部分在 LightningModel 类中包装了 PyTorch 模型,并使用 Trainer 类来拟合模型。
之前的代码显示验证准确率从第 2 轮到第 3 轮有所下降,但改进后的代码使用了 ModelCheckpoint 以加载最佳模型。在同一台机器上,这个模型在 23.09 分钟内达到了 92% 的测试准确率。需要注意,如果禁用 checkpointing 并允许 PyTorch 以非确定性模式运行,本次运行最终将获得与普通 PyTorch 相同的运行时间(时间为 22.63 分而不是 23.09 分)。进一步,如果 GPU 支持混合精度训练,可以开启 GPU 以提高计算效率。作者使用自动混合精度训练,在 32 位和 16 位浮点之间切换而不会牺牲准确率。在这一优化下,使用 Trainer 类,即能通过一行代码实现自动混合精度训练:
上述操作可以将训练时间从 23.09 分钟缩短到 8.75 分钟,这几乎快了 3 倍。测试集的准确率为 92.2%,甚至比之前的 92.0% 还略有提高。最近 PyTorch 2.0 公告显示,PyTorch 团队引入了新的 toch.compile 函数。该函数可以通过生成优化的静态图来加速 PyTorch 代码执行,而不是使用动态图运行 PyTorch 代码。由于 PyTorch 2.0 尚未正式发布,因而必须先要安装 torchtriton,并更新到 PyTorch 最新版本才能使用此功能。
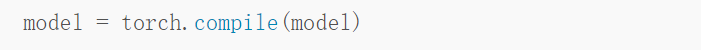
上文介绍了在单 GPU 上加速代码的混合精度训练,接下来介绍多 GPU 训练策略。下图总结了几种不同的多 GPU 训练技术。想要实现分布式数据并行,可以通过 DistributedDataParallel 来实现,只需修改一行代码就能使用 Trainer。
经过这一步优化,在 4 个 A100 GPU 上,这段代码运行了 3.52 分钟就达到了 93.1% 的测试准确率。最后,作者探索了在 Trainer 中使用深度学习优化库 DeepSpeed 以及多 GPU 策略的结果。首先必须安装 DeepSpeed 库:

这一波下来,用时 3.15 分钟就达到了 92.6% 的测试准确率。不过 PyTorch 也有 DeepSpeed 的替代方案:fully-sharded DataParallel,通过 strategy="fsdp" 调用,最后花费 3.62 分钟完成。以上就是作者提高 PyTorch 模型训练速度的方法,感兴趣的小伙伴可以跟着原博客尝试一下,相信你会得到想要的结果。原文链接:https://sebastianraschka.com/blog/2023/pytorch-faster.html探寻隐私计算最新行业技术,「首届隐语开源社区开放日」报名启程
春暖花开之际,诚邀广大技术开发者&产业用户相聚活动现场,体验数智时代的隐私计算生态建设之旅,一站构建隐私计算产业体系知识:
隐私计算领域焦点之性
分布式计算系统的短板与升级策略
隐私计算跨平台互联互通
隐语开源框架金融行业实战经验
3月29日,北京·798机遇空间,隐语开源社区开放日,期待线下面基。点击阅读原文,立即报名。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]