CVPR2023|天大联合卡迪夫大学发布SemanticHuman:部件级、精细语义、灵活可控的3D人体编辑表征
新智元报道
新智元报道
【新智元导读】SemanticHuman兼顾精细语义与几何刻画的三维人体表示,可实现部件级别的灵活可控编辑。
近年来三维人体表示学习受到越来越多的关注,不过现有工作由于受限于粗糙的语义和有限的表示能力无法灵活、可控、准确地表示人体,尤其是在缺乏配对监督数据的情况下。
针对上述问题,天津大学团队联合英国卡迪夫大学在CVPR2023的工作中提出一种兼顾精细语义与几何刻画的三维人体表示——SemanticHuman。
项目主页:http://cic.tju.edu.cn/faculty/likun/projects/SemanticHuman
代码:https://github.com/2017211801/SemanticHuman
具体来说,作者通过提出一种部件感知的骨骼分离的解耦策略,在隐编码和人体部件的几何测量之间建立起明确的对应关系,不仅为表示提供了细粒度的语义、高效且强大的几何刻画能力,而且方便设计鲁棒的无监督损失,从而摆脱对配对监督数据的依赖。
借助该表示所学习到的具有几何意义的隐空间,用户可以通过调节隐编码实现人体生成与编辑、人体形状风格转移等一系列有趣的应用,相关代码已经开源!
1. 研究背景与动机
学习人体的低维表示在人体重建、人体生成与编辑等各种应用中具有重要作用,对于一种人体表示,可以从两个方面去评价它的好坏。
首先是表示的几何刻画能力,即通过某种表示重建出的人体在多大程度上保留了原始的输入人体的几何;
其次是表示的语义颗粒度,即表示的参数是否有明确且精细的几何或物理意义。
现有的人体表示工作大致可以分为传统方法与基于学习的方法:
传统方法如SCAPE[1]、SMPL[2],在语义层面,它们把人体解耦成姿态与形状,从而可以通过控制对应参数来改变人体属性;在几何刻画层面,它们采用PCA对人体形状进行建模,然而这种基于线性空间的方法无法处理人体网格中复杂的非线性结构。
而基于学习的方法大多以编码器-解码器框架为基础,通过在输入与输出间施加几何约束来确保隐编码尽可能多地保留输入网格的几何细节,得益于神经网络强大的非线性拟合能力,这类方法在几何刻画层面显著优于传统方法;在语义层面,有监督的方法通过为每个网格配对一个具有中性姿态的网格来显式地约束隐编码的语义,但是制作配对监督数据耗时耗力,限制了其后续应用,无监督的方法通过设计新颖的无监督损失来隐式赋予隐编码明确的语义,但是其损失函数不够鲁棒,重建出的人体往往有明显的伪影。
并且上述表示方法的语义都太过粗糙,只停留在对人体全局属性的描述,无法支持部件级别的灵活可控编辑。
作者就以此为出发点,提出了一种既不需要配对监督数据又可以兼顾精细语义与几何刻画的三维人体表示——SemanticHuman。
图1:SemanticHuman示意图。(左图) 获得输入人体的隐编码,(右图) 通过改变隐编码实现部件级别的灵活可控编辑
2. 方法思路与细节
2.1总览
作者的研究动机与目的已经在上文阐明,那么先前工作为什么无法做到呢?
作者认为这是因为先前工作都遵循把人体解耦为姿态和形状的解耦思路,这种基于人体全局属性的解耦思路不仅限制了表示语义的精细程度而且不便于设计鲁棒且有效的无监督损失,为此作者提出了一种全新的基于人体局部的解耦思路,并且基于此思路设计了一系列新颖且有效的网络架构、训练流程与损失,下面将详细介绍。
2.2部件感知的骨骼分离的解耦策略
作者的解耦思路来源于一个关键观察,即人体是由多个部件组成的,并且每个部件都有一根由三维关节点定义的骨骼,如图2 (a) 和 (b) 所示。
图2:解耦思路示意图。(a) 人体部件,(b) 人体骨骼与关节点,(c) 解耦思路概述,(d) 两点连线与骨骼形成的夹角
另外对于一些几何结构比较简单的人体部件,如腰部、手臂和腿部,其几何形状可近似成以骨骼为主轴的圆柱体,这也就意味着这些部位的几何形变可以被建模为沿其骨骼方向的变化以及沿其骨骼正交方向的变化,如图2 (b) 中小图所示。
受这一观察的启发,作者提出一种部件感知的骨骼分离的解耦策略,解耦思路概述如图2 (c) 所示。
具体来说,作者将人体部件的几何形变解耦为与骨骼相关的变化(比如骨骼长度和方向的变化)和与骨骼无关的变化(比如形状尺寸和风格的变化),它们分别由第k个部位的骨骼隐编码和形状嵌入表示。
这种全新的基于人体局部的解耦策略不仅可以为表示提供了细粒度的语义,以实现部件级别的灵活可控编辑,还可以准确且高效地刻画几何结构,并且有利于无监督损失的构建,从而摆脱对配对监督数据的依赖。
2.3网络架构
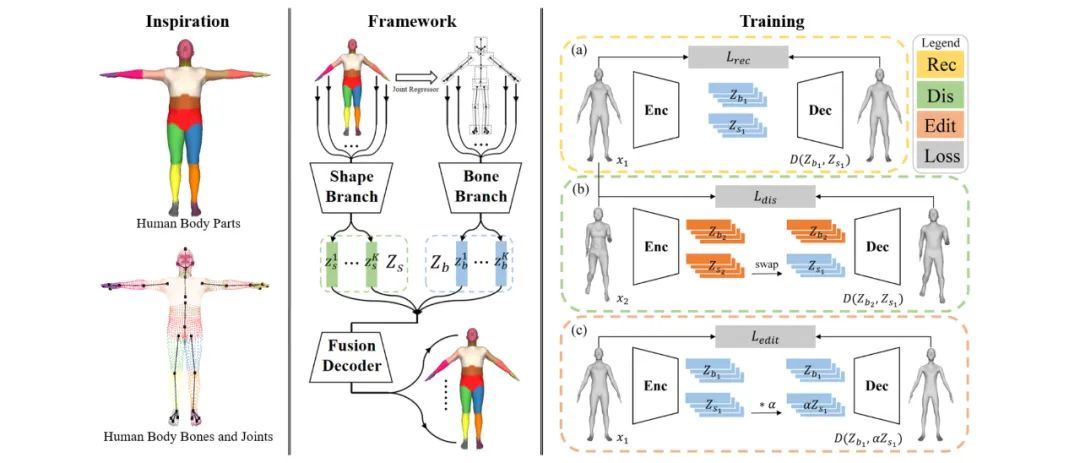
网络架构以经典的编码器-解码器结构为基础,融合其解耦思路中的“部件感知”、“骨骼分离”特点,把编码器拆分为骨骼支路和形状支路,并且把一个全连接层拆成多个局部全连接层,这样设计不仅有利于人体特征的提取与聚合,得以更加有效地建模几何细节,而且显著降低了模型参数量,设计细节如图3所示。
图3:网络架构示意图
具体来说,输入一个网格x,编码器的骨骼支路和形状支路分别编码其每个部件的骨骼信息与形状特征,得到骨骼隐编码和形状隐编码
其中
和
表示第k个部位的局部隐编码。
然后局部隐编码被送入对应的全连接层中得到局部特征,最终通过图卷积网络聚合不同部件的特征重建出输入的网格。
2.4训练流程与损失
在上述网络框架的基础上,作者通过设计不同的训练分支和对应的损失来分别达到精确几何重建、无监督解耦、部件级别人体编辑的目的,训练总览如图4所示。
图4:训练流程示意图。整个训练流程由 (a) 重建分支、(b) 解耦分支、(c) 编辑分支组成
整个训练流程的损失函数如下,三种损失分别实现对应的任务:
重建分支:如图4 (a) 所示,作者采用如下的重建损失来实现精确的几何重建:
x是输入网格,Lvert和Ledge分别从顶点和边的层面对重建的网格进行几何约束,以实现精确的几何重建。
解耦分支:在重建分支的约束下,表示已经具备刻画复杂几何的能力,可是其隐空间仍
然是耦合的,因此作者采用如下的解耦损失来实现无监督解耦:
给定两个输入网格x1和x2,x_swp表示生成的网格,它由来自x2的骨骼隐编码和来自x1的形状隐编码解码得到,如图4 (b) 所示,Ldis_b和Ldis_s分别用于保留属于x2的骨骼信息和属于x1的几何特征。
通过这种方式,该表示可以通过无监督学习实现解耦。因为骨骼由关节点决定,所以应该具有与相似的关节点位置,因此定义如下,其中为关节回归器:
然而如何保留人体的局部几何特征是一个很有挑战性的问题,一个简单的想法是用欧式距离矩阵来描述人体部件的几何特征,如下式所示:
其中x^k是指x的第k个部件,指x^k的顶点间的欧式距离矩阵,如果x^k有n^k个顶点那么其矩阵大小为
。
然而骨骼的长度是耦合在该矩阵中的,这会导致不彻底的解耦从而影响人体编辑的精度。
为了缓解这个问题,作者提出方向自适应权重(orientation-adaptive weighting, OAW)策略。具体来说,对于人体部件x^k,作者首先通过连接每对顶点形成一条线,然后计算该线与骨骼方向所形成的夹角,从而构建一个大小为
角度矩阵
,如图3 (d) 所示。显然该夹角越大代表该线对沿着
的形状变化的贡献越大。
接着作者采用下面的阈值处理和归一化函数来获得大小同为的权重矩阵
:
加权后的欧式距离矩阵定义为:
其中表示矩阵的逐元素相乘,OAW策略尽可能地将骨长信息与欧式距离矩阵分离,从而实现更彻底的解耦和更高精度的编辑。
编辑分支:在解耦分支的约束下,网络学习到的隐空间已经实现了人体部件骨骼与形状的
无监督解耦,因此用户可以通过修改输入的关节点位置控制人体部件骨骼的方向和长度,但是对于部件的形状仍然无法实现可控的编辑。为了解决这个问题,作者提出了如图4 (c) 所示的编辑分支,通过监督生成的网格按照期望变形,从而实现部件级别的形状编辑:
其中是从均匀分布中随机采样的标量,
表示由
生成的网格。
具体来说,监督
的第k个部位具有由
描述的形状。
由于捕获的是沿着
的成对的欧式距离,所以当部件沿着
缩放时该矩阵中的元素也应该相应的缩放,此外还引入了
来确保编辑过程中的骨骼信息保持不变。
3. 实验结果
作者DFAUST和SPRING数据集上评估了所提出方法的几何表示能力(重建精度)和编辑能力(语义)。
3.1重建实验
作者首先比较了四类方法来验证该方法的重建精度,分别是基于谱域卷积的方法COMA[3],基于螺旋卷积的方法Neural3DMM[4]和Spiralplus[5],基于注意力的方法Pai3DMM[6]和Deep3DMM[7],以及无监督解耦方法Unsup[8],采用输入网格与重建网格间的平均顶点欧式距离来评价重建精度。
如表1所示,该方法在更少的参数量下显示了更出色的几何表示能力。图5显示了一些重建结果与误差图,可以观察到该方法的重建精度显著优于其他方法,尤其在几何细节丰富的部件上(如人脸人手)。
表1:重建实验定量表。
图5:重建实验定性图
3.2编辑实验
作者还展示了该方法在三个编辑任务上的灵活编辑能力:编辑骨骼方向和长度,以及编辑部件形状大小。由于骨骼方向相当于姿势,所以作者在该任务上与无监督姿势和形状解耦工作 Unsup[8]比较;而骨长和形状大小属于形状信息,因此作者在这两项任务上与人体重塑工作HBR[9]进行比较。由于这些编辑任务没有真值,所以作者利用关节点误差Ejoint和周长误差Ecirc来评估编辑骨骼和形状的准确性,其公式如下所示:
其中是求部件围度的函数,表2给出了量化的编辑结果。该方法不仅在所有的编辑任务中取得了最好的性能,而且还好地保留了其他未编辑的属性。图6展示了一些可视化结果,与Unsup[8]和HBR[9]相比,该方法可以更准确、合理、灵活地编辑人体。
表1:编辑实验定量表
图6:编辑实验定性图
作者在demo最后还展示了人体生成与编辑、人体形状风格转移等一系列有趣的应用:
4. 作者简介
孙晓琨,天津大学21级硕士研究生,主要研究方向:三维视觉、人体重建与表示
冯桥,天津大学21级硕士研究生,主要研究方向:计算机视觉、计算机图形学
https://fengq1a0.github.io
李雄政,天津大学19级博士研究生,主要研究方向:计算机视觉、计算机图形学
张劲松,天津大学21级博士研究生,主要研究方向:计算机视觉、计算机图形学,https://zhangjinso.github.io/
来煜坤,英国卡迪夫大学教授,主要研究方向:计算机图形学,几何处理,图像处理和计算机视觉,http://users.cs.cf.ac.uk/Yukun.Lai/
杨敬钰,天津大学教授,主要研究方向:计算机视觉、智能图像/视频处理、计算成像与三维重建http://tju.iirlab.org/yjy
李坤(通讯作者),天津大学教授、博导,主要研究方向:三维视觉、人工智能生成内容(AIGC)http://cic.tju.edu.cn/faculty/likun
微信扫码关注该文公众号作者