GPT-4 已经发布一个多月了,但识图功能还是体验不了。来自阿卜杜拉国王科技大学的研究者推出了类似产品 ——MiniGPT-4,大家可以上手体验了。
对人类来说,理解一张图的信息,不过是一件微不足道的小事,人类几乎不用思考,就能随口说出图片的含义。就像下图,手机插入的充电器多少有点不合适。人类一眼就能看出问题所在,但对 AI 来说,难度还是非常大的。GPT-4 的出现,开始让这些问题变得简单,它能很快的指出图中问题所在:VGA 线充 iPhone。其实 GPT-4 的魅力远不及此,更炸场的是利用手绘草图直接生成网站,在草稿纸上画一个潦草的示意图,拍张照片,然后发给 GPT-4,让它按照示意图写网站代码,嗖嗖的,GPT-4 就把网页代码写出来了。但遗憾的是,GPT-4 这一功能目前仍未向公众开放,想要上手体验也无从谈起。不过,已经有人等不及了,来自阿卜杜拉国王科技大学(KAUST)的团队上手开发了一个 GPT-4 的类似产品 ——MiniGPT-4。团队研究人员包括朱德尧、陈军、沈晓倩、李祥、Mohamed H. Elhoseiny,他们均来自 KAUST 的 Vision-CAIR 课题组。- 论文地址:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
- 论文主页:https://minigpt-4.github.io/
- 代码地址:https://github.com/Vision-CAIR/MiniGPT-4
MiniGPT-4 展示了许多类似于 GPT-4 的能力,例如生成详细的图像描述并从手写草稿创建网站。此外,作者还观察到 MiniGPT-4 的其他新兴能力,包括根据给定的图像创作故事和诗歌,提供解决图像中显示的问题的解决方案,根据食品照片教用户如何烹饪等。MiniGPT-4 效果到底如何呢?我们先从几个示例来说明。此外,为了更好的体验 MiniGPT-4,建议使用英文输入进行测试。首先考察一下 MiniGPT-4 对图片的描述能力。对于左边的图,MiniGPT-4 给出的回答大致为「图片描述的是生长在冰冻湖上的一株仙人掌。仙人掌周围有巨大的冰晶,远处还有白雪皑皑的山峰……」假如你接着询问这种景象能够发生在现实世界中吗?MiniGPT-4 给出的回答是这张图像在现实世界并不常见,并给出了原因。
接着,在来看看 MiniGPT-4 图片问答能力。问:「这棵植物出现了什么问题?我该怎么办?」MiniGPT-4 不但指出了问题所在,表示带有棕色斑点的树叶可能由真菌感染引起,并给出了治疗步骤:
几个示例看下来,MiniGPT-4 看图聊天的功能已经非常强大了。不仅如此,MiniGPT-4 还能从草图创建网站。例如让 MiniGPT-4 按照左边的草稿图绘制出网页,收到指令后,MiniGPT-4 给出对应的 HTML 代码,按照要求给出了相应网站:
借助 MiniGPT-4,给图片写广告语也变得非常简单。要求 MiniGPT-4 给左边的杯子写广告文案。MiniGPT-4 精准的指出了杯子上有嗜睡猫图案,非常适合咖啡爱好者以及猫爱好者使用,还指出了杯子的材质等等:
MiniGPT-4 还能对着一张图片生成菜谱,变身厨房小能手:


此外,值得一提的是,MiniGPT-4 Demo 已经开放,在线可玩,大家可以亲自体验一番(建议使用英文测试):Demo 地址:https://0810e8582bcad31944.gradio.live/项目一经发布,便引起网友广泛关注。例如让 MiniGPT-4 解释一下图中的物体: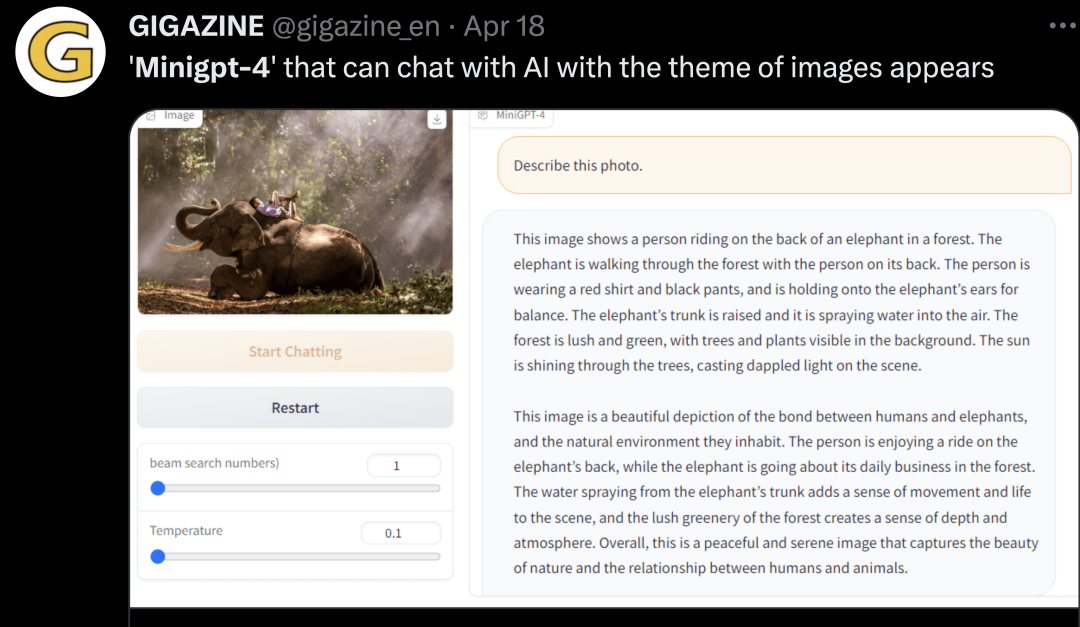
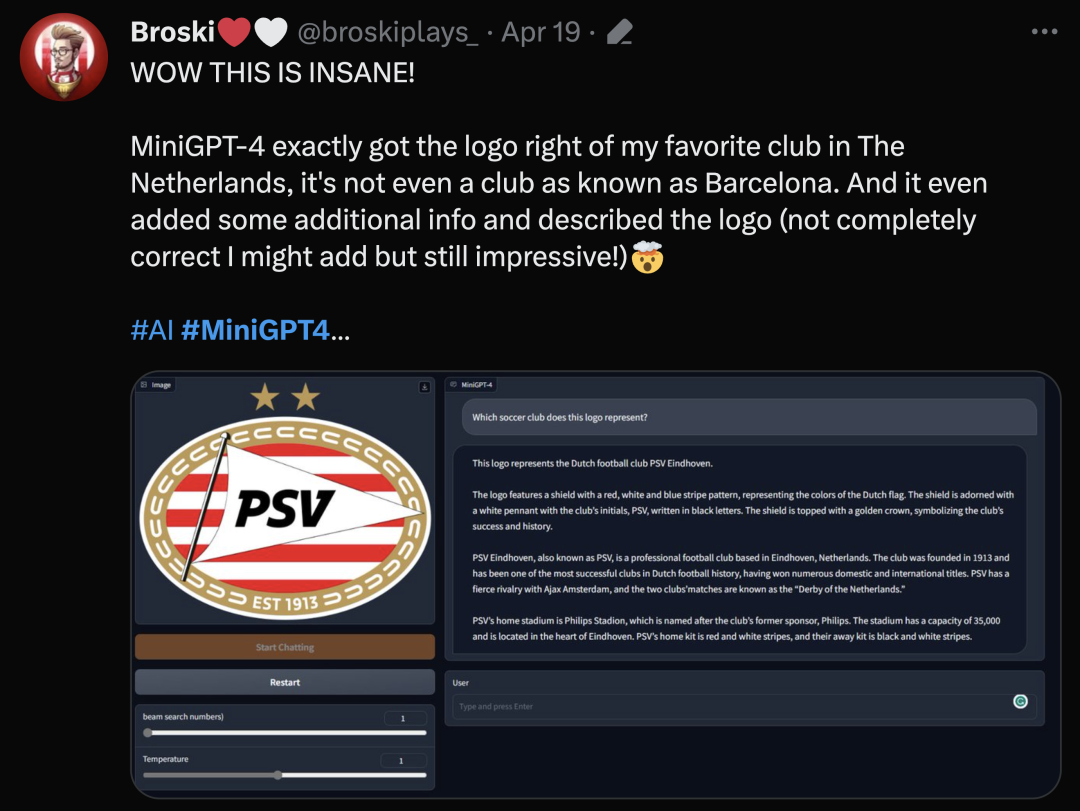
作者认为 GPT-4 拥有先进的大型语言模型(LLM)是其具有先进的多模态生成能力的主要原因。为了研究这一现象,作者提出了 MiniGPT-4,它使用一个投影层将一个冻结的视觉编码器和一个冻结的 LLM(Vicuna)对齐。MiniGPT-4 由一个预训练的 ViT 和 Q-Former 视觉编码器、一个单独的线性投影层和一个先进的 Vicuna 大型语言模型组成。MiniGPT-4 只需要训练线性层,用来将视觉特征与 Vicuna 对齐。MiniGPT-4 进行了两个阶段的训练。第一个传统的预训练阶段使用大约 5 百万对齐的图像文本对,在 4 个 A100 GPU 上使用 10 小时进行训练。第一阶段后,Vicuna 能够理解图像。但是 Vicuna 文字生成能力受到了很大的影响。为了解决这个问题并提高可用性,研究者提出了一种新颖的方式,通过模型本身和 ChatGPT 一起创建高质量的图像文本对。基于此,该研究创建了一个小而高质量的数据集(总共 3500 对)。第二个微调阶段使用对话模板在此数据集上进行训练,以显著提高其生成可靠性和整体可用性。这个阶段具有高效的计算能力,只需要一张 A100GPU 大约 7 分钟即可完成。- VisualGPT: https://github.com/Vision-CAIR/VisualGPT
- ChatCaptioner: https://github.com/Vision-CAIR/ChatCaptioner
此外,项目中还使用了开源代码库包括 BLIP2、Lavis 和 Vicuna。
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
整理不易,请点赞和在看