2023 年 3 月 14 日, GPT-4 发布。自那一天之后,就好像打开了潘多拉魔盒一样,各种 AI 大模型就跟开大会,前后脚地发布。从号称 OpenAI 杀手的 Claude ,到比 GPT 热度还高的 Auto GPT ,再到国产的文心一言、通义千问等等。这股井喷速度,多少让人有些眼花缭乱了。 结果还没歇两天,差评君又遇到了一个非常特殊的参赛选手。
结果还没歇两天,差评君又遇到了一个非常特殊的参赛选手。 按理来说,它是游戏起家的,手握《 海岛奇兵 》、《 皇室战争 》的发行权。但它搞起浏览器也很有一套,欧洲的老牌浏览器 Opera ,被它在海外玩的风生水起。甚至 2018 年的时候,在纳斯达克上市了。做起社交软件来,思路也很清奇。旗下的音乐社交平台 StarMaker,在海外默默做了 6000 多万用户。
按理来说,它是游戏起家的,手握《 海岛奇兵 》、《 皇室战争 》的发行权。但它搞起浏览器也很有一套,欧洲的老牌浏览器 Opera ,被它在海外玩的风生水起。甚至 2018 年的时候,在纳斯达克上市了。做起社交软件来,思路也很清奇。旗下的音乐社交平台 StarMaker,在海外默默做了 6000 多万用户。 曾经控股的同性社交平台 Grindr ,出售后帮他们一把赚到了 30 多亿。。
曾经控股的同性社交平台 Grindr ,出售后帮他们一把赚到了 30 多亿。。
相信肯定很多朋友已经猜到,差评君这次要介绍的是谁了。就是那个总是被人调侃忘了游戏老本行的昆仑万维,这回似乎他们又往舒适圈外面,迈了一大步。早在去年,他们就一次性拿出了绘画、编程、音乐和文本四大板块的 AI 成果。当时,差评君还带大家体验了一把它们的 AI 绘画。
 而这一次,他们又带来了和 AI 团队奇点智源合作的大语言模型——天工。天工算是昆仑从 2021 年起,研究 AI 模型到现在所有心血的集大成者,前前后后烧掉了能有几个亿。在 4 月 17 日的产品演示直播上,昆仑就直接现场实测了天工。
而这一次,他们又带来了和 AI 团队奇点智源合作的大语言模型——天工。天工算是昆仑从 2021 年起,研究 AI 模型到现在所有心血的集大成者,前前后后烧掉了能有几个亿。在 4 月 17 日的产品演示直播上,昆仑就直接现场实测了天工。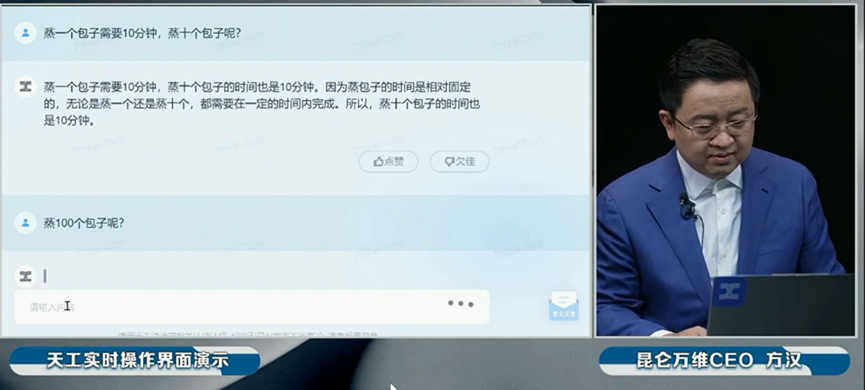
 这回,差评君也是很幸运地拿到了天工的测试资格。下面就让我们上手测试一下,这个烧掉了这么多钱的“ 宝贝儿子 ”,到底能有几斤几两。测了那么多大模型,对比来,对比去的,说到底还是为了提升效率。毕竟,要是根据 OpenAI 创始人的说法,这 AI 继续发展下去,以后咱们可就是全部不用工作了。所以,这次我们就落到实地,看看这些烧了几亿的大模型,到底能省多少力。
这回,差评君也是很幸运地拿到了天工的测试资格。下面就让我们上手测试一下,这个烧掉了这么多钱的“ 宝贝儿子 ”,到底能有几斤几两。测了那么多大模型,对比来,对比去的,说到底还是为了提升效率。毕竟,要是根据 OpenAI 创始人的说法,这 AI 继续发展下去,以后咱们可就是全部不用工作了。所以,这次我们就落到实地,看看这些烧了几亿的大模型,到底能省多少力。 在正式测试开始之前,咱们要先摸底考核一下。作为一个大语言模型,需要具备的基本功有两项,一个是学习,一个是持续对话。只有这两项能力过硬,模型的使用感才会好。首先是学习能力的测试。这里,差评君教了天工一套我自创的规则。给它一些正向情绪的语句,并且把这个语句标注为 “ 0 ” ,负面情绪的语句则标注为 “ 1 ” 。然后,再给它几个语句,让它做标注。结果,效果不错,天工确实是准确地给出了正确的标注,说明它学会了我的规则。
在正式测试开始之前,咱们要先摸底考核一下。作为一个大语言模型,需要具备的基本功有两项,一个是学习,一个是持续对话。只有这两项能力过硬,模型的使用感才会好。首先是学习能力的测试。这里,差评君教了天工一套我自创的规则。给它一些正向情绪的语句,并且把这个语句标注为 “ 0 ” ,负面情绪的语句则标注为 “ 1 ” 。然后,再给它几个语句,让它做标注。结果,效果不错,天工确实是准确地给出了正确的标注,说明它学会了我的规则。 第一关考核通过。
第一关考核通过。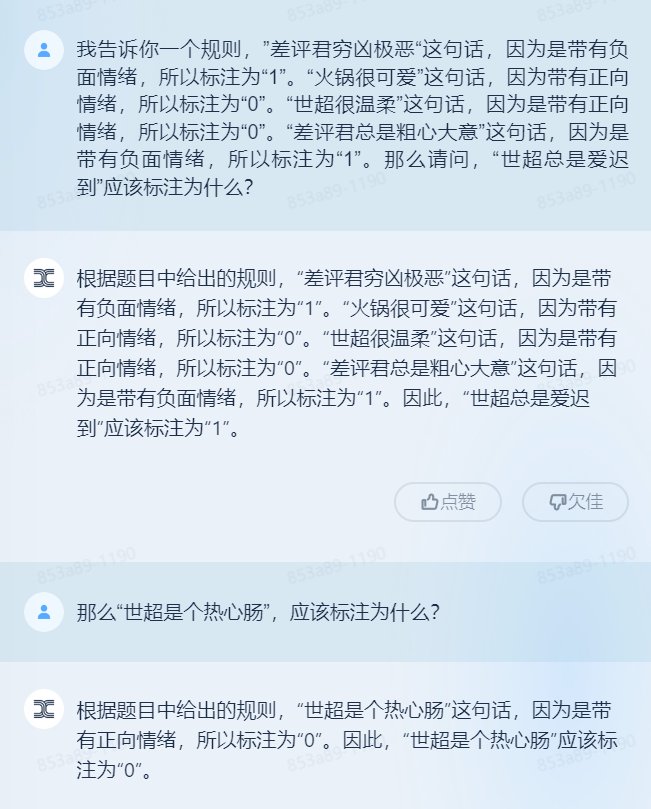
差评君连续地问了天工几个问题,它基本能结合上下文回复我。说明天工是能做到多轮对话的。不过,差评君觉得这个程度,还不够。咱们给天工,再加上点难度。
向上滑动 ▼
 之后,差评君又向天工咨询了宠物饲养的问题。并且,在交谈中,我无意中跟它透露了, “ 我不希望和小明家一样养狗 ” 这个信息。
之后,差评君又向天工咨询了宠物饲养的问题。并且,在交谈中,我无意中跟它透露了, “ 我不希望和小明家一样养狗 ” 这个信息。
之后,又多次问了其它问题,比如养猫需要的注意事项。在几轮对话之后,我重新问了天工: 小明家养了什么宠物?虽然,天工一开始没反应过来,但是稍加引导,它立刻回忆起来前面我提供的信息,并告诉了我正确答案。
小明家养了什么宠物?虽然,天工一开始没反应过来,但是稍加引导,它立刻回忆起来前面我提供的信息,并告诉了我正确答案。
更让差评君比较诧异的是,同样的问题,当我问 ChatGPT 的时候,却把它难住了。甚至是目前大模型里的尖子生 GPT-4 ,居然都没有办法做对。。 在我引导下, GPT-4 甚至已经追溯到了有信息的提问段落,但是没有办法理解 “ 小明养的宠物是狗 ” ,这么一个简单的事实。之所以天工能做到,是因为它支持 20 轮以上的对话。而且,不仅仅是长对话,它还能做到理解语义和记忆上下文,这些进阶技巧。
在我引导下, GPT-4 甚至已经追溯到了有信息的提问段落,但是没有办法理解 “ 小明养的宠物是狗 ” ,这么一个简单的事实。之所以天工能做到,是因为它支持 20 轮以上的对话。而且,不仅仅是长对话,它还能做到理解语义和记忆上下文,这些进阶技巧。 看来天工这小子,基本功夫相当扎实,是能处的。摸清了底之后,我们就能开始正式的测验了。让天工代替一下差评君的工作,测测它是不是块写作大师的料。
看来天工这小子,基本功夫相当扎实,是能处的。摸清了底之后,我们就能开始正式的测验了。让天工代替一下差评君的工作,测测它是不是块写作大师的料。
差评君拿了最近在想的一个选题—— “ 测谎仪到底有没有用?” ,让天工试试手。因为影视作品里很多时候,把这玩意搞得神乎其乎的,甚至有国家,还把测谎仪当成法庭上的证据。
天工告诉了我答案:测谎仪会受到很多因素影响,并不能肯定一个人是否说谎。 带着这些疑问,让我们继续下去。
带着这些疑问,让我们继续下去。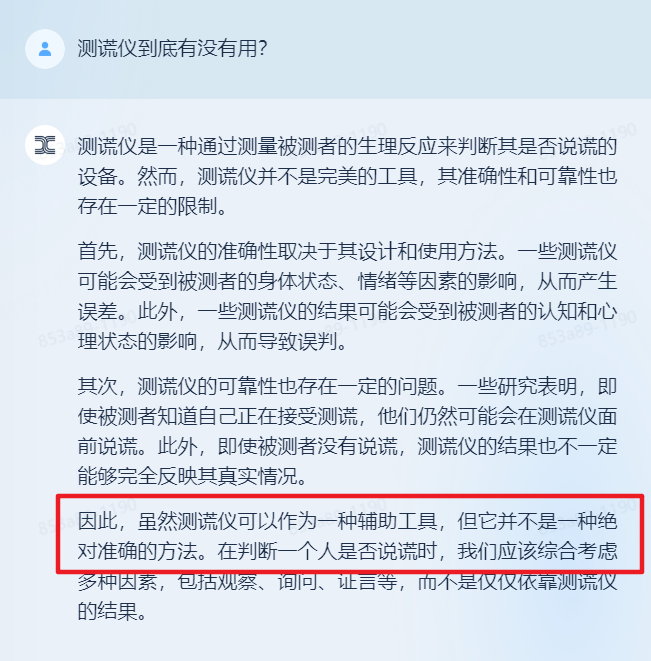
为了解释清楚测谎仪的前世今生,我让天工围绕测谎仪,帮我列一份大纲。
几秒钟之后,一份脉络清晰的大纲就被生产出来了。
从测谎仪的原理、历史、应用以及争议几个方面来解答这个选题,基本上和差评君平时写文章的路线差不多。
 稍微有点惊喜的是,它帮我考虑到了在不同类型案件中,测谎仪可能会有不同的使用范围。
稍微有点惊喜的是,它帮我考虑到了在不同类型案件中,测谎仪可能会有不同的使用范围。

但这还不是极限,我们可以让天工,进一步细化这份大纲。
比如,差评君让它详细讲述了一下,在案件中嫌疑人是怎么使用测谎仪的。
天工基本能分点罗列出来了,逻辑上来讲是挺清晰的。就是文字处理,有点像百度百科的介绍,能读,但是不出彩。。
不过,它倒是贴心地反复提醒差评君,测谎仪这玩意不准的,生怕我上当受骗。

 一些外文的资料,我也可以直接丢给天工去翻译。
一些外文的资料,我也可以直接丢给天工去翻译。
比如这段维基百科里对测谎仪的介绍,天工基本上几秒钟就翻译好了。
通过天工翻译后的内容,我们能知道在测谎仪的程序里,会有测试员故意要求被测者撒谎,以此来证明测谎仪有用。

甚至,差评君发现天工还能当做整理助手使用。
丢一段文字给它,天工能分析数据和信息,一键总结成表格。比如测谎仪的检测,主要是靠呼吸频率、血压心压、皮肤抗性。
 这样一来,原本复杂的资料,就被梳理的很清晰了,能大大节省消化资料的时间。
这样一来,原本复杂的资料,就被梳理的很清晰了,能大大节省消化资料的时间。

不过,当给天工的数据一多,它很容易会处理卡壳。就需要人工去梳理,这样一来二去,效率上有点拉了。

但总的来说,在文本生成方面,天工算是有两把刷子在身上。尤其是表格整理,差评君觉得相当实用了。
不过,光有文本能力还不够,逻辑、代码、数学题等基础测试,差评君也给天工安排上了全套。
测试第一轮代码题的时候,天工的表现还是很不错的。差评君用一句话,让天工帮我做了一个简单的小网站。按钮变动的大小和效果,页面和按钮颜色,都做对了。
黑色的网页中间,有一个蓝色的圆形按钮,当鼠标移动到按钮上,按钮会缓慢放大

就是不知道为什么,最后有点画蛇添足。天工在代码中,多写了一行位移效果,导致按钮放大的同时,还出现了漂移。

但到了第二轮的数学题测验,天工慢慢就有点吃不消了。
面对题干里的各种数据和条件,天工蒙圈了。它一直纠结在了,青蛙跳 3 米花的时间上。。
谢谢你,把我的时间规划到了小数点后两位

后面,差评君又试着问了经典的鸡兔同笼问题,天工也是在带入方程的时候,计算错误了。
 看来很可能是因为数学题的变数太多了,大语言模型很容易在某一步出错。
看来很可能是因为数学题的变数太多了,大语言模型很容易在某一步出错。

所以,当天工遇上变数更多,逻辑更诡异的逻辑题时候,就容易在题目的陷阱里中招。
比如当我问,A 参加跑步比赛,刚刚他超过了第三名,请问他现在是第几名?
 天工给了我正确的回答,A 现在是第三名。
天工给了我正确的回答,A 现在是第三名。
可当我们换一种问法,就会发现天工的逻辑不适用了。
但总的来说,天工有强项,也有弱项。
在逻辑和数学能力上,可能还需要打磨打磨。但在,文科方面,天工还是能拿得出手的。
尤其是多轮对话、制作表格、提高写作效率各方面,已经可以一定程度上解放人力。
 而且,就在差评君拿到测试资格的几天里,天工一直在不断地迭代更新。不仅在各种问题处理上也肉眼可见的进步,而且资料库更新很快。
而且,就在差评君拿到测试资格的几天里,天工一直在不断地迭代更新。不仅在各种问题处理上也肉眼可见的进步,而且资料库更新很快。
虽然天工是不联网的,但我试探性地问了几个顶流国宝的问题,它居然都能对上。 连热腾腾的淄博烧烤梗,天工这小子居然也门清。如此快的更新迭代速度,都是国产 AI 模型互卷带来的结果。在差评君看来,这是个好事。只有井喷的局面出现,才会加速缩短我们与 OpenAI 的差距。而这一次,昆仑万维作为一个新生,但是有水平的玩家,加入了战局。
连热腾腾的淄博烧烤梗,天工这小子居然也门清。如此快的更新迭代速度,都是国产 AI 模型互卷带来的结果。在差评君看来,这是个好事。只有井喷的局面出现,才会加速缩短我们与 OpenAI 的差距。而这一次,昆仑万维作为一个新生,但是有水平的玩家,加入了战局。
我们差评获得了 5 个邀请码,请大家留言自己想和「天工」互动的问题,点赞最高的 5 个读者将获得邀请码~获得邀请码的读者,点击文章下方的阅读原文,就可以跳转到官网了~撰文:四大 编辑:江江 & 面线 & 结界 封面:
图片、资料来源:
天工、ChatGPT
(广告)
