机器之心 & ArXiv Weekly
参与:楚航、罗若天、梅洪源
本周重要论文包括威斯康星大学麦迪逊分校、微软、港科大华人研究者提出的基于 prompt 的新型交互模型 SEEM,以及 40 多位学者联合发布的基础模型工具学习综述和开源 BMTools 平台。
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- A Cookbook of Self-Supervised Learning
- Tool Learning with Foundation Models
- Scaling Transformer to 1M tokens and beyond with RMT
- Segment Everything Everywhere All at Once
- Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
- Collaboration Helps Camera Overtake LiDAR in 3D Detection
- ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness- 作者:Tri Dao、Daniel Y. Fu 等
- 论文地址:https://arxiv.org/abs/2205.14135
摘要:过去两年,斯坦福大学 Hazy Research 实验室一直在从事一项重要的工作:增加序列长度。他们有一种观点:更长的序列将开启机器学习基础模型的新时代 —— 模型可以从更长的上下文、多种媒体源、复杂的演示等中学习。目前,这项研究已经取得了新进展。Hazy Research 实验室的 Tri Dao 和 Dan Fu 主导了 FlashAttention 算法的研究和推广,他们证明了 32k 的序列长度是可能的,且在当前这个基础模型时代将得到广泛应用(OpenAI、Microsoft、NVIDIA 和其他公司的模型都在使用 FlashAttention 算法)。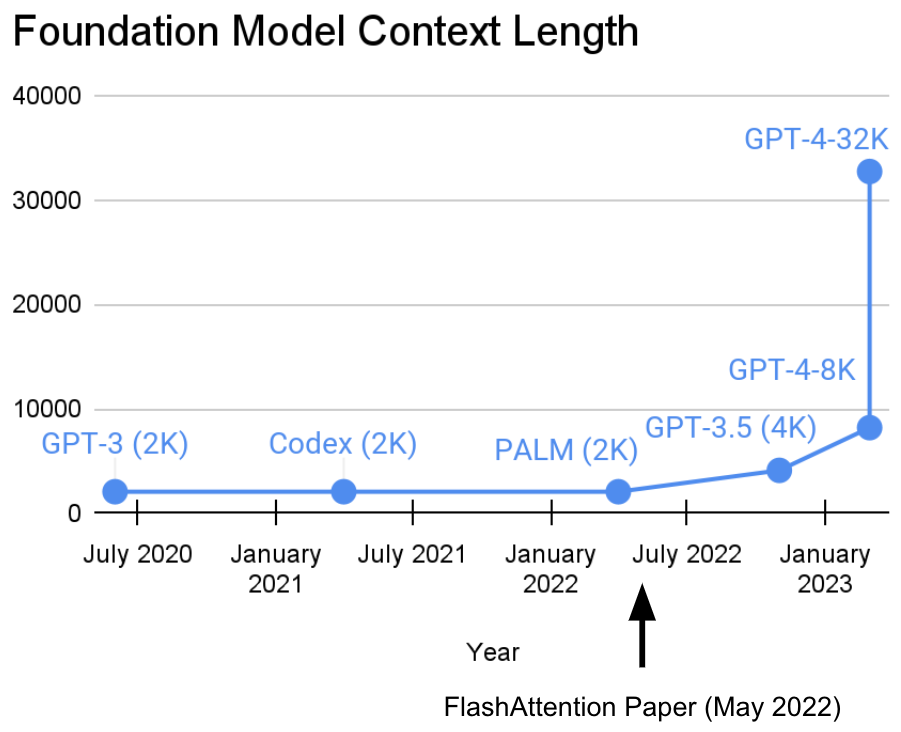
推荐:想把半本《红楼梦》搬进 ChatGPT 输入框?先把这个问题解决掉。论文 2:A Cookbook of Self-Supervised Learning- 作者:Randall Balestriero、 Mark Ibrahim 等
- 论文地址:https://arxiv.org/pdf/2304.12210v1.pdf
摘要:近日,LeCun 介绍了他和 Meta 人工智能研究院研究员、研究经理田渊栋等人共同撰写的一份「Cookbook」(非常实用、可操作性强、就像一本菜谱一样的论文)。这本 Cookbook 总共 70 页,涵盖了自监督学习的定义、重要性、起源、家族、训练部署方法、扩展方法等方面知识,是一份不可多得的学习材料。「如果你想研究自监督学习,那最好看看这本书。」田渊栋补充说。
推荐:LeCun、田渊栋参与撰写,70 页「自监督学习」大全来了。论文 3:Tool Learning with Foundation Models- 作者:Yujia Qin、Shengding Hu 等
- 论文地址:https://arxiv.org/abs/2304.08354
摘要:近期,来自清华大学、中国人民大学、北京邮电大学、UIUC、NYU、CMU 等高校的研究人员联合知乎、面壁智能公司探索基础模型调用外部工具的课题,联合发表了一篇 74 页的基础模型工具学习综述论文,发布开源工具学习平台。该团队提出了基础模型工具学习的概念,系统性地整理和阐述了其技术框架,同时展示了未来可能面临的机遇和挑战。这项研究对于了解基础模型工具学习的最新进展及其未来发展趋势具有重要价值。工具学习整体框架呈现了人类用户和四个核心成分:工具集、控制器、感知器、环境。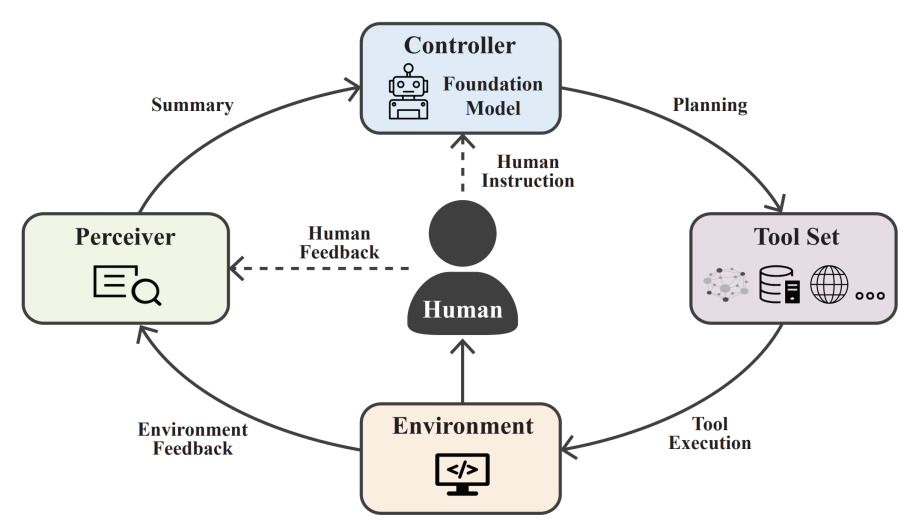
推荐:40 多位学者联合发布基础模型工具学习综述,开源 BMTools 平台。论文 4:Scaling Transformer to 1M tokens and beyond with RMT- 作者:Aydar Bulatov、 Yuri Kuratov 等
- 论文地址:https://arxiv.org/pdf/2304.11062.pdf
摘要:前几天,一篇来自开源对话 AI 技术栈 DeepPavlov 等机构的研究表明:通过采用一种名为 Recurrent Memory Transformer(RMT)的架构,他们可以将 BERT 模型的有效上下文长度增加到 200 万个 token(按照 OpenAI 的计算方式,大约相当于 3200 页文本),同时保持了较高的记忆检索准确性(注:Recurrent Memory Transformer 是 Aydar Bulatov 等人在 NeurIPS 2022 的一篇论文中提出的方法)。新方法允许存储和处理局部和全局信息,并通过使用 recurrence 使信息在输入序列的各 segment 之间流动。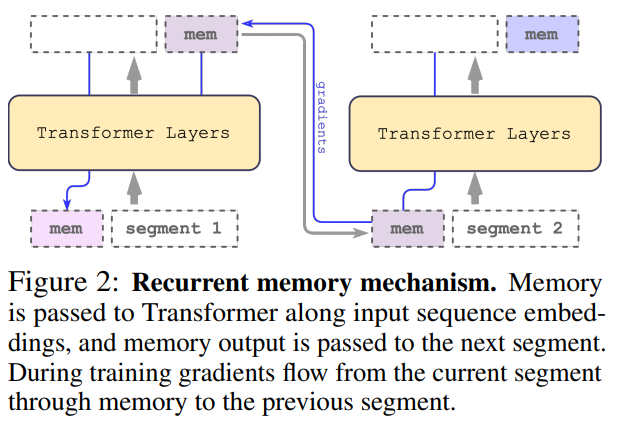
推荐:真・量子速读:突破 GPT-4 一次只能理解 50 页文本限制,新研究扩展到百万 token。论文 5:Segment Everything Everywhere All at Once- 作者:Xueyan Zou、 Jianwei Yang 等
- 论文地址:https://arxiv.org/pdf/2304.06718.pdf
摘要:最近,一篇「一次性分割一切」的新论文再次引起关注。在该论文中,来自威斯康星大学麦迪逊分校、微软、香港科技大学的几位华人研究者提出了一种基于 prompt 的新型交互模型 SEEM。SEEM 能够根据用户给出的各种模态的输入(包括文本、图像、涂鸦等等),一次性分割图像或视频中的所有内容,并识别出物体类别。该项目已经开源,并提供了试玩地址供大家体验。下图中展示了轻松分割出视频中移动的物体。
推荐:一次性分割一切,比 SAM 更强,华人团队的通用分割模型 SEEM 来了论文 6:Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators- 作者:Alexander Herzog、 Kanishka Rao 等
- 论文地址:https://rl-at-scale.github.io/assets/rl_at_scale.pdf
摘要:在谷歌这篇论文中,研究人员探讨了如何通过最新的大规模实验解决这个问题,他们在两年内部署了一支由 23 个支持 RL 的机器人组成的群组,用于在谷歌办公楼中进行垃圾分类和回收。使用的机器人系统将来自真实世界数据的可扩展深度强化学习与来自模拟训练的引导和辅助对象感知输入相结合,以提高泛化能力,同时保留端到端训练优势,通过对 240 个垃圾站进行 4800 次评估试验来验证。在现实世界中,机器人会遇到各种独特的情况,比如以下真实办公楼的例子:
推荐:耗时两年,谷歌用强化学习打造 23 个机器人帮助垃圾分类。论文 7:Collaboration Helps Camera Overtake LiDAR in 3D Detection- 论文地址:https://arxiv.org/abs/2303.13560
摘要:摄像头能否实现激光雷达的检测效果,以更低成本实现自动驾驶感知?在最新的 CVPR2023 论文中,来自上海交通大学、加州大学洛杉矶分校、以及上海人工智能实验室的研究者提出了纯视觉协作探测方法(CoCa3D),通过让多个基于纯视觉的智能车高效协作,在 3D 目标探测效果上,接近甚至超越基于激光雷达的智能车。下图为数据集 CoPerception-UAVs + 和 OPV2V + 仿真环境。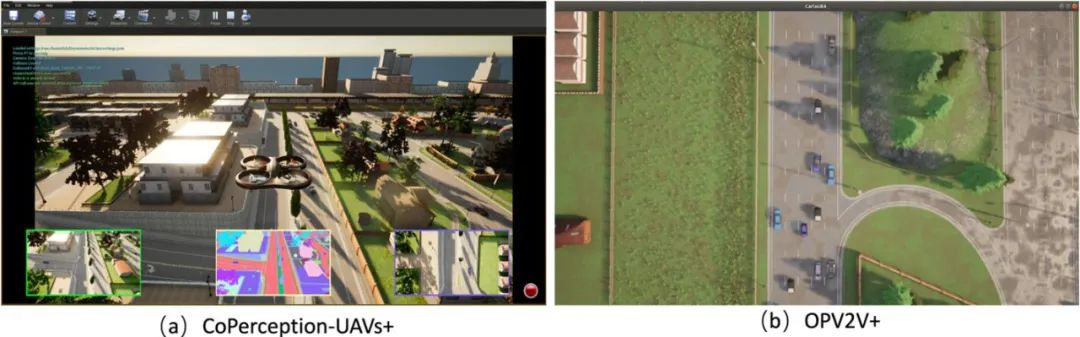
推荐:多车协作让纯视觉 3D 目标探测媲美激光雷达。ArXiv Weekly Radiostation机器之心联合由楚航、罗若天、梅洪源发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Multi-Party Chat: Conversational Agents in Group Settings with Humans and Models. (from Jason Weston)
2. The Internal State of an LLM Knows When its Lying. (from Tom Mitchell)
3. string2string: A Modern Python Library for String-to-String Algorithms. (from Stuart M. Shieber, Dan Jurafsky)
4. Pretrain on just structure: Understanding linguistic inductive biases using transfer learning. (from Dan Jurafsky)
5. A Comparison of Semi-Supervised Learning Techniques for Streaming ASR at Scale. (from Kyunghyun Cho)
6. ChatABL: Abductive Learning via Natural Language Interaction with ChatGPT. (from Dinggang Shen)
7. Studying the Impact of Semi-Cooperative Drivers on Overall Highway Flow. (from Daniela Rus)
8. Shades of meaning: Uncovering the geometry of ambiguous word representations through contextualised language models. (from Chris Watkins, Yang Gao)
9. IXA/Cogcomp at SemEval-2023 Task 2: Context-enriched Multilingual Named Entity Recognition using Knowledge Bases. (from Dan Roth)
10. We're Afraid Language Models Aren't Modeling Ambiguity. (from Noah A. Smith)
本周 10 篇 CV 精选论文是:
1. Latent Fingerprint Recognition: Fusion of Local and Global Embeddings. (from Anil K. Jain)2. 3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes. (from Antonio Torralba, Joshua B. Tenenbaum)3. Self-supervised Learning by View Synthesis. (from Xiangyu Zhang, Jiaya Jia)4. A Review of Deep Learning for Video Captioning. (from Shuicheng Yan, Erik Cambria, Fatih Porikli)5. Motion-Conditioned Diffusion Model for Controllable Video Synthesis. (from Tsung-Yi Lin, Ming-Hsuan Yang)6. SwinFSR: Stereo Image Super-Resolution using SwinIR and Frequency Domain Knowledge. (from Huan Liu)7. Med-Tuning: Exploring Parameter-Efficient Transfer Learning for Medical Volumetric Segmentation. (from Yan Zhang)8. A marker-less human motion analysis system for motion-based biomarker discovery in knee disorders. (from Lei Zhang)9. A Strong and Reproducible Object Detector with Only Public Datasets. (from Lei Zhang)10. Compositional 3D Human-Object Neural Animation. (from Dacheng Tao)
1. Conditional Denoising Diffusion for Sequential Recommendation. (from Philip S. Yu)2. Bayesian Federated Learning: A Survey. (from Joao Gama, Yew-Soon Ong, Vipin Kumar)3. Learning Neural Constitutive Laws From Motion Observations for Generalizable PDE Dynamics. (from Joshua B. Tenenbaum, Wojciech Matusik)4. TR0N: Translator Networks for 0-Shot Plug-and-Play Conditional Generation. (from Jimmy Ba)5. Physics-informed neural networks for predicting gas flow dynamics and unknown parameters in diesel engines. (from George Em Karniadakis)6. Certifying Ensembles: A General Certification Theory with S-Lipschitzness. (from Philip H.S. Torr)7. AdaNPC: Exploring Non-Parametric Classifier for Test-Time Adaptation. (from Liang Wang, Rong Jin, Tieniu Tan)8. Prediction, Learning, Uniform Convergence, and Scale-sensitive Dimensions. (from Peter L. Bartlett)9. Latent Traversals in Generative Models as Potential Flows. (from Nicu Sebe, Max Welling)10. Discovering Graph Generation Algorithms. (from Roger Wattenhofer)© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]