【新智元导读】最近,来自NTU、KCL和同济的团队基于Meta的「分割一切」,提出了全新的模型Relate Anything Model——联系一切。
本月初,Meta推出的「分割一切」模型可谓是震撼了整个CV圈。这几天,一款名为「Relate-Anything-Model(RAM)」的机器学习模型横空出世。它赋予了Segment Anything Model(SAM)识别不同视觉概念之间的各种视觉关系的能力。据了解,该模型由南洋理工大学MMLab团队和伦敦国王学院和同济大学的VisCom实验室的同学利用闲暇时间合作开发。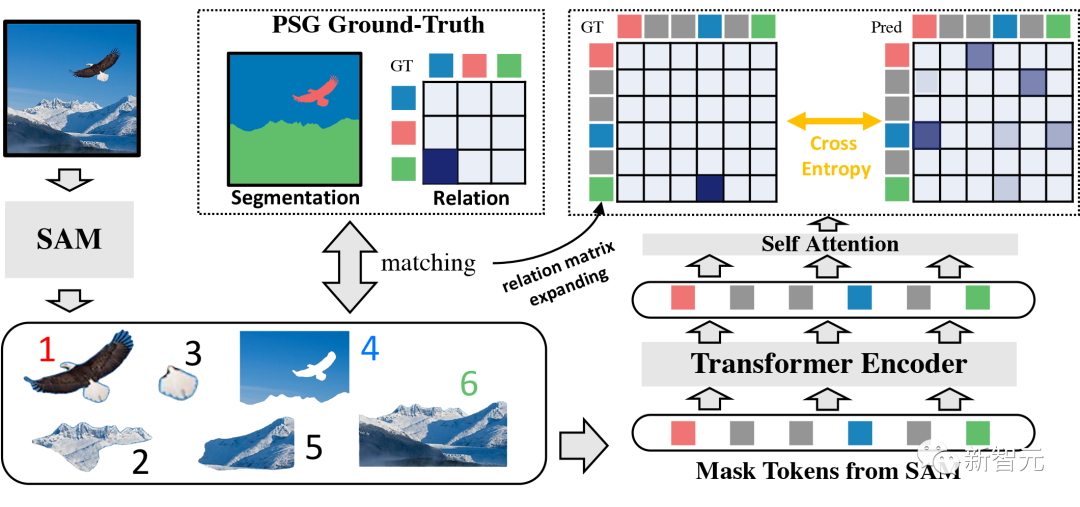
演示地址:https://huggingface.co/spaces/mmlab-ntu/relate-anything-model
代码地址:https://github.com/Luodian/RelateAnything
数据集地址:https://github.com/Jingkang50/OpenPSG
首先,让我们来看一看「Relate-Anything-Model(RAM)」的应用实例吧!比如,下面这些关于踢足球、跳舞和交朋友的RAM模型实现的图像分析结果,就让人印象非常深刻,很好地展示了模型出色的性能和多样化应用的潜力。
RAM模型基于ECCV'22 SenseHuman Workshop & 国际算法算例大赛「Panoptic Scene Graph Generation」赛道冠军方案。
论文地址:https://arxiv.org/abs/2302.02651
该PSG挑战赛奖金百万,共收到来自全球100支团队提交的各种解决方案,其中包括了使用先进的图像分割方法以及解决长尾问题等。此外,竞赛还收到了一些创新性的方法,如场景图专用的数据增强技术。经过评估,根据性能指标、解决方案的新颖性和意义等方面的考虑,小红书团队的GRNet脱颖而出,成为获胜的方法。
比赛详情:https://github.com/Jingkang50/OpenPSG在介绍解决方案之前,我们首先来介绍两个经典的PSG基线方法,其中一个是双阶段方法,另一个是单阶段方法。对于双阶段基线方法,如图a所示,在第一阶段中,使用预训练的全景分割模型Panoptic FPN从图像中提取特征、分割和分类预测。然后,将每个个体对象的特征提供给经典的场景图生成器,如IMP,以便在第二阶段进行适应PSG任务的场景图生成。该双阶段方法允许经典的SGG方法通过最小的修改适应PSG任务。如图b所示,单阶段基线方法PSGTR首先使用CNN提取图像特征,然后使用类似DETR的transformer编码器-解码器来直接学习三元组表示。匈牙利匹配器用于将预测的三元组与基本真实三元组进行比较。然后,优化目标最大化匹配器计算的成本,并使用交叉熵进行标签和分割的DICE/F-1损失计算总损失。
在RAM模型的设计过程中,作者参考了PSG冠军方案GRNet的双阶段结构范式。尽管PSG原文的研究中表明,单阶段模型目前的表现优于双阶段模型,然而,单阶段模型通常无法像双阶段模型那样达到良好的分割性能。经对不同模型结构的观察推测,单阶段模型在关系三元组预测上的优异表现可能是由于来自图像特征图的直接监督信号有利于捕捉关系。基于这一观察,RAM的设计同GRNet一样,旨在两个模式之间找到一个权衡,通过重视双阶段范式并赋予其类似于单阶段范式中获取全局上下文的能力来实现。具体地,首先利用Segment Anything Model(SAM)作为特征提取器,识别和分割图像中的物体对象,将来自SAM分割器的特定对象的中间特征映射与其对应的分割融合,得到对象级别特征。随后,把Transformer作为一种全局上下文模块,将获得的对象级别特征经过线性映射后输入其中。通过Transformer编码器中的交叉注意力机制,输出的对象特征从其他对象中收集了更多的全局信息。最后,对于Transformer输出的每个对象级别特征,通过self-attention机制进一步丰富上下文信息并使各个物体对象之间完成交互。请注意,这里还添加了一个类别嵌入以指示对象的类别,并由此得到了成对的物体及它们之间关系的预测。
在训练过程中,对于每个关系类别,需要执行关系二元分类任务以确定对象对之间是否存在关系。和GRNet相似的,对关系二元分类任务还有一些特别的考虑。例如, PSG数据集通常包含两个具有多个关系的对象,例如「人看着大象」和「人喂大象」同时存在。为了解决多标签问题,作者将关系预测从单标签分类问题转换为多标签分类问题。此外,由于PSG数据集通过要求注释者选择特定和准确的谓词(如「停在」而不是更一般的「在」)来追求精度和相关性,可能不适合学习边界关系(如「在」实际上与「停在」同时存在)。为了解决这个问题,RAM采用了一种自我训练策略,使用自我蒸馏标签进行关系分类,并使用指数移动平均来动态更新标签。
在计算关系二元分类损失时,每个预测对象必须与其对应的基础真实对象配对。匈牙利匹配算法用于此目的。然而,该算法容易出现不稳定情况,特别是在网络准确度低的早期训练阶段。这可能导致对于相同的输入,匹配产生不同的匹配结果,导致网络优化方向不一致,使训练变得更加困难。在RAM中,不同于之前方案,作者借助于强大的SAM模型,可以对几乎任何图片进行完整且细致的分割,因此,在匹配预测和GT过程中, RAM自然地设计了新的GT匹配方法:使用PSG数据集来训练模型。对于每个训练图像,SAM会分割多个物体,但只有少数与PSG的ground truth(GT)mask相匹配。作者根据它们的交集-并集(IOU)分数进行简单的匹配,以便(几乎)每个GT mask都被分配到一个SAM mask中。之后,作者根据SAM的mask重新生成关系图,自然地匹配上了模型的预测。
在RAM模型中,作者利用Segment Anything Model(SAM)来识别和分割图像中的物体,并提取每个分割物体的特征。随后使用Transformer模块来使分割物体之间产生交互作用,从而得到新的特征。最后将这些特征经过类别嵌入后,通过self-attention机制输出预测结果。在训练过程中,特别地,作者提出了新的GT匹配方法并基于该方法,计算预测和GT的配对关系并分类它们的相互关系。在关系分类的监督学习过程中,作者视之为多标签分类问题并采用了一种自我训练策略学习标签的边界关系。最后,希望RAM模型能够为你带来更多的启发和创新。如果你也想训练会找关系的机器学习模型,可以关注该团队的工作,并随时提出反馈和建议。
项目地址:https://github.com/Jingkang50/OpenPSG
https://github.com/Luodian/RelateAnything
