据Global Market Insights 数据,全球 GPU 市场预计将以 CAGR 25.9%持续增长,至 2030 年达到 4000 亿美元规模。其中 AI 领域大语言模型的持续推出以及参数量的不断增长有望驱动模型训练端、推理端 GPU 需求快速增长。近年来,国产 GPU 厂商在图形渲染 GPU 和高性能计算 GPGPU 领域上均推出了较为成熟的产品,在性能上不断追赶行业主流产品,在特定领域达到业界一流水平。生态方面国产厂商大多兼容英伟达 CUDA,融入大生态进而实现客户端不断导入。在高端GPU 芯片进口受限的背景下,国产 GPU 厂商预计将乘政策东风,抓住国产替代契机快速成长。GPU(图形处理器)最初是为了解决 CPU 在图形处理领域性能不足的问题而诞生。CPU 作为核心控制计算单元,高速缓冲存储器(Cache)、控制单元(Control)在 CPU 硬件架构设计中所占比例较大,主要为实现低延迟和处理单位内核性能要求较高的工作而存在,而计算单元(ALU)所占比例较小,这使得 CPU 的大规模并行计算表现不佳。GPU 架构内主要为计算单元,采用极简的流水线进行设计,适合处理高度线程化、相对简单的并行计算,在图像渲染等涉及大量重复运算的领域拥有更强运算能力。常见的AI 加速芯片主要为GPU、FPGA 和 ASICGPU 的微架构是用以实现指令执行的硬件电路结构设计以 Nvidia 第一个实现统一着色器模型的 Tesla 微架构为例,从顶层 Host Interface 接受来自 CPU 的数据,藉由 Vertex(顶点)、Pixel(片元)、Compute(计算着色器)分发给各 TPC(Texture Processing Clusters 纹理处理集群)进行处理。在单个 TPC 中主要的运算结构为SM(Streaming Multiprocessor 流式多处理器),其内在蕴含 I Cache(指令缓存)、C Cache(常量缓存)以及核心的计算单元 SP(Streaming Processor 流处理器)和 SFU(Special Function Unit 特殊函数计算单元),外加 Texture Unit(纹理单元)。由于图形渲染流管线相对固定,Nvidia 在 Tesla构中将部分重要环节剥离并实现可编程,解耦出 SM 计算单元用于通用计算,即可实现根据具体任务需要分配相应线程实现通用计算处理。计算核心、纹理单元增加, GPC 功能更加完整,Nvidia Fermi 架构奠定完整GPU 计算架构基础。在Tesla 之后,Nvidia 第一个完整的 GPU 计算架构 Fermi通过制程微缩增加更多计算核心、纹理单元,并且通过增加 PolyMorph Engine(多形体引擎)和 Raster Engine(光栅引擎)使得原来 TPC 升级成为拥有更加完整功能的 GPC(Graphics Processing Clusters 图形处理器集群)。Fermi 架构共包含 4 个 GPC,16 个 SM,512 个CUDA Core。英伟达GPU从最初 Fermi 架构到最新的 Ampere 架构和 Hopper 架构
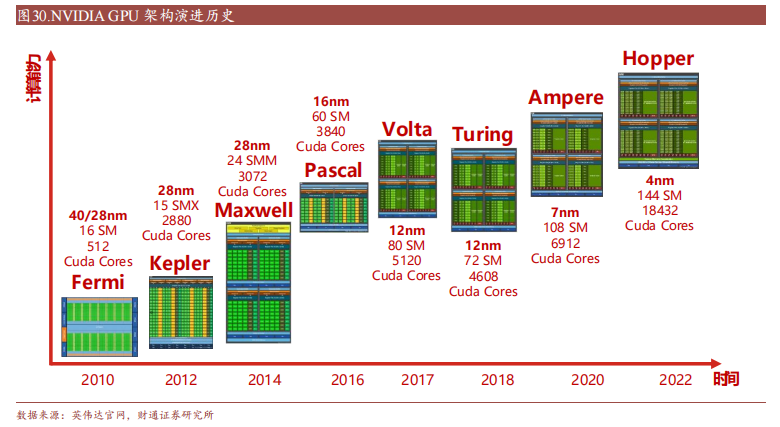
每一阶段都在性能和能效比方面得到提升,引入了新技术,如 CUDA、GPUBoost、RT 核心和 Tensor 核心等,在图形渲染、科学计算和深度学习等领域发挥重要作用。最新一代 Hopper 架构在 2022 年 3 月推出,旨在加速 AI 模型训练,使用 Hopper Tensor Core 进行 FP8 和 FP16 的混合精度计算,以大幅加速Transformer 模型的 AI 计算。与上一代相比,Hopper 还将 TF32、FP64、FP16 和INT8 精度的每秒浮点运算(FLOPS)提高了 3 倍。
AMD 作为全球第二大GPU厂商,亦通过持续的架构演进保持其市场领先地位

从2010年以来,AMD 相继推出:GCN 架构、RDNA 架构、RDNA 2 架构、RDNA 3 架构、CDNA 架构和 CDNA 2 架构。最新一代面向高性能计算和人工智能 CDNA 2 架构于架构采用增强型 Matrix Core 技术,支持更广泛的数据型和应用,针对高性能计算工作负载带来全速率双精度和全新 FP64 矩阵运算。基于 CDNA2 架构的 AMD Instinct MI250X GPU FP64 双精度运算算力最高可达 95.7 TFLOPs。
或者获取全店资料打包,后续免费获取全店所有新增和更新。
全店铺技术资料打包(全)
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店资料打包汇总(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。