©作者 | 杨林易
来源 | 王晋东不在家
机器学习的许多领域都面临着一个共同的难题:评估。近些年来,虽然机器学习取得了很多进展,但随着研究的深入,研究人员发现这些进展的泛化性并不如预期的优秀。传统语言模型的评估大多依赖于 GLUE 排行榜。截止至 2022 年,已经有超过 20 个单模型的结果在 GLUE 的测评上优于人工测评的表现。过去的工作证明了模型的表现并不是真正超过了人类,而是依靠伪特征(spurious features)和捷径学习(shortcut learning)取得了虚高的成绩。
因此在模型拟合能力大大提升的今天,依靠传统 in-domain test 的 GLUE 榜单在实践中作为评估指标的实际价值较低。所以需要靠分布外泛化(Out of Distribution, OOD)来测试模型真正的泛化能力。以往的泛化评估通常是研究者自行选择数据集在 1-2 个任务上进行测试,缺乏 GLUE-X 这样全面评估模型泛化能力的基准。不同于 GLUE,当前最好的模型在 GLUE-X 表现仍明显逊于人类 (74.6% vs. 80.4%)。

GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-distribution Generalization Perspective论文链接:
https://arxiv.org/abs/2211.08073代码链接:
https://github.com/YangLinyi/GLUE-X
在人工智能得以广泛运用的今天,构建负责任的人工智能需要模型具备足够的鲁棒性。但在 NLP 的过往研究中,OOD 并没有得到足够的关注且缺乏统一的评估基准,这限制了 NLP 系统在真实世界中的应用。
为了构建针对模型泛化能力的统一基准,我们创建一个名为 GLUE-X 的评测榜单。首先,研究员们以 GLUE 上囊括的数据集作为领域内训练集,在 8 个文本分类任务上,构建了 14 个用于 OOD 测试的文本数据集。然后,又在 21 个常用的预训练模型(包括 InstructGPT 和 GPT 3.5)上利用领域内的训练集进行调参,得到领域内最佳性能的模型后,再在 OOD 文本数据集进行测试,以 OOD 数据上的表现作为模型泛化能力的指标,同时提供人类测评的结果作为参照。
此外,研究员们还比较了不同的微调方式对模型泛化性能的影响,并利用 Rationale “事后分析”了模型在 OOD 数据上作出判断的理性依据,并与人工标注的数据进行比对分析,以帮助研究人员理解模型泛化能力的来源。

任务、数据集和模型选取
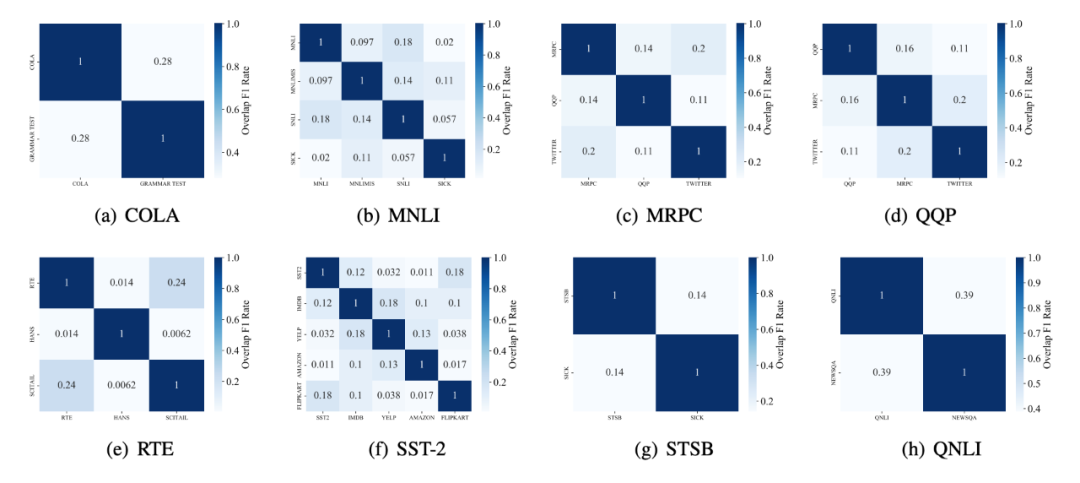
如上图所示,我们对每一个 GLUE 中出现的任务构建对应的 OOD 数据。例如,对情感分析 SST-2 数据,我们选取了 IMDB, Yelp, Amazon, 和 Flipkart 作为测试数据。对语法判断 COLA 数据,我们选取了自行收集的 Grammar Test(考题)作为测试数据。GLUE-X 总共包含十五组,超过 600 万条的泛化测试数据。此基础上,研究员们对常见的 PLM 进行了全数据测试。亦对 InstructGPT 和 ChatGPT 进行了采样测试。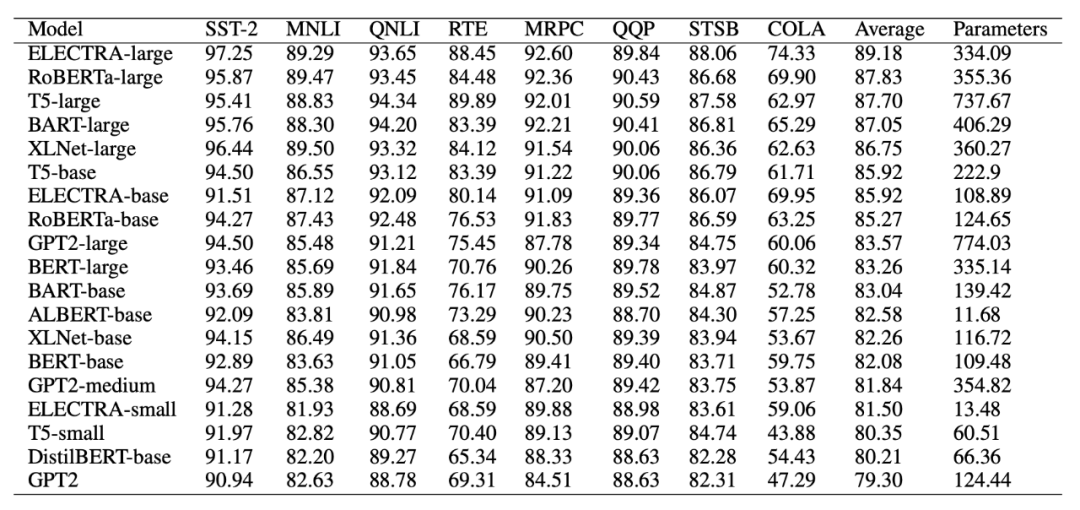
结果
我们的结论如下:
无论是最佳的有监督学习模型,还是 ChatGPT 大模型,在 GLUE-X 上的表现都远远低于人类。值得注意的是,人工测评也是在 OOD 条件下进行的(仅给人类 in-domain 的数据作为培训范例)。
没有一种模型能领跑所有任务,这与计算机视觉领域的研究结论一致。模型架构 OOD 鲁棒性的影响比模型参数大小更为重要。模型的结构对于处理未预料到的输入更具有影响力。
对于文本分类任务来说,ID 和 OOD 的性能在大多数情况下呈线性相关,即如果在已知的数据分布上表现良好,那么在未知的数据分布上也可能会有较好的表现。[1] Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In ICLR, 2017.[2] Liu, W., Wang, X., Owens, J. D., and Li, Y. Energy-based out-of-distribution detection. In NeurIPS, 2020.[3] Hendrycks, D., Mazeika, M., and Dietterich, T. Deep anomaly detection with outlier exposure. In ICLR, 2019.[4] Yang, J., Zhou, K., Li, Y., and Liu, Z. Generalized out-ofdistribution detection: A survey. In arXiv, 2021.[5] Yang, J., Wang, P., Zou, D., Zhou, Z., Ding, K., PENG, W., Wang, H., Chen, G., Li, B., Sun, Y., et al. Openood: Benchmarking generalized out-of-distribution detection. In NeurIPS Datasets and Benchmarks Track, 2022.[6] Vaze, S., Han, K., Vedaldi, A., and Zisserman, A. Open-set recognition: A good closed-set classifier is all you need. In ICLR, 2022.[7] Arpit, D., Jastrzebski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M. S., Maharaj, T., Fischer, A., Courville, A. C., Bengio, Y., and Lacoste-Julien, S. A closer look at memorization in deep networks. In ICML, 2017.[8] Sorg, J., Lewis, R. L., and Singh, S. Reward design via online gradient ascent. In NeurIPS, 2010.[9] Ishida, T., Yamane, I., Sakai, T., Niu, G., and Sugiyama, M. Do we need zero training loss after achieving zero training error? In ICML, 2020.[10] Ramanujan, V., Wortsman, M., Kembhavi, A., Farhadi, A., and Rastegari, M. What’s hidden in a randomly weighted neural network? In CVPR, 2020.[11] Ming, Y., Fan, Y., and Li, Y. Poem: Out-of-distribution detection with posterior sampling. In ICML, 2022.

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
