论文标题:Cognitive Evolutionary Search to Select Feature Interactions for Click-Through Rate Prediction作者:Runlong Yu, Xiang Xu, Yuyang Ye, Qi Liu, Enhong Chen
单位:中国科学技术大学、认知智能全国重点实验室、罗格斯大学
论文链接:http://home.ustc.edu.cn/~yrunl/Files/Publications/KDD23-CELS.pdf
代码链接:https://github.com/RunlongYu/CELS or http://home.ustc.edu.cn/~yrunl/Files/code_data/CELS/code.zip
视频链接:https://youtu.be/p3kE54lIWRw
本文介绍了陈恩红、刘淇教授团队在 KDD23 会议上发表的研究成果——“认知进化搜索:基于交叉特征选择的点击率预估算法”。针对交叉特征选择问题,该团队另辟蹊径,从认知智能和进化计算角度,提出了一种认知进化搜索(Cognitive EvoLutionary Search, CELS)算法。传统处理交叉特征的方法多是采用专家设计的预定义操作来统一构造所有特征对,这种方式可能会引入不合适的交叉特征,从而产生不必要的噪声,并增加训练的复杂度。与之相比,认知进化搜索引入一种新颖的思路:通过任务驱动模型演化以构建交叉特征。认知进化搜索将交叉特征视为基因组,将模型视为生物体,将任务视为环境,借鉴基因延展性发展环境适应性的原理,通过诊断模型的适应度来模拟生物体在自然选择中的存活率。由此,认知进化搜索超越了仅依据表面层次来评估个体,转而选择在基因层面对模型进行深入诊断,并促进针对性的变异机制。实验结果表明认知进化搜索可以针对不同的任务发展为不同的模型,且在预测指标上展现最优的性能。在当今的智能营销系统中,点击率(Click-Through Rate, CTR)预估具有举足轻重的地位。其目标在于预测用户对推荐项目的点击数占总展示次数的比率。广告主努力通过提高此比率来增加投资回报,同时,流量主也试图通过此方式更高效地将网络流量转化为收入。如图1所示,在这个场景中,广告交易平台起到了枢纽的作用,它连通了广告主和流量主之间的交易需求。为了优化广告预算,精准的点击率预估显得至关重要。任何对点击率的误估可能会导致预算的浪费,或者是错失潜在的机会。
考虑到当前商业营销业务的规模,点击率预估无疑吸引了学术界和工业界的广泛关注。通过用户建模和深度学习等技术来筛选出对点击率预估有价值的特征,已经成为研究的热点。
大量的研究结果显示,特征对之间的交叉作用能带来超越单一特征的预测效果 [1]。这引出一个基础研究问题:如何有效地选择交叉特征。见图2所示。在特征选择领域,有3种主要的方法,即过滤器方法(filter)、包装器方法(wrapper)以及嵌入式方法(embeded)。过滤器方法通过使用各种度量指标来评估特征与目标的相关程度,然后依赖排序算法来挑选出与目标高度相关的特征。包装器方法以模型性能为目标函数,评估不同特征子集的表现。为了实现这个目标,需要在所有可能的特征子集上反复地训练模型。另一方面,嵌入式方法将特征选择与训练过程相融合,使得两者成为一个整体过程。在实践中,由于稳定性较差和效率较低,过滤器和包装器方法通常不适用于大规模或高维度的数据集 [2]。相对而言,嵌入式方法由于其较低的计算需求和较少的过拟合问题,越来越受到人们的青睐。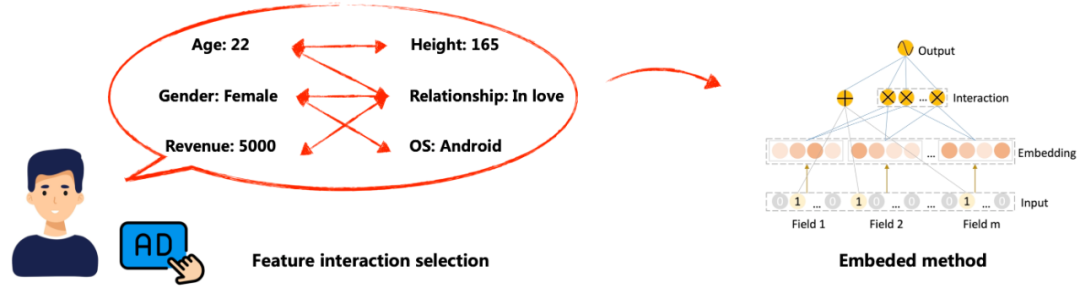
如图3所示,当前的嵌入式方法主要依赖专家设计的操作进行特征对的交叉。例如,因式分解机(Factorization Machines, FM)通过将特征投影到低维向量并利用内积来建模特征交叉 [3]。另一方面,Field-aware FM 允许特征具有多个隐向量与不同特征域的特征进行交叉 [4]。然而,由于浅层模型的表示能力有限,引起学者关注使用深度学习模型建模高阶交叉特征。例如,Attentional FM 和 Neural FM 将深度神经网络堆叠在FM的输出上以建模高阶交叉特征 [5, 6]。即便如此,这种深度学习模型捕获的低阶交叉特征仍然较少。解决这个问题的方法之一是采用像 Wide&Deep 这样的混合结构,它结合了浅层和深层组件,以实现学习模型的记忆和泛化功能 [7]。例如,DeepFM 就是使用FM层来代替了浅层部分 [8],类似地 Deep&Cross 和 xDeepFM 的浅层部分则分别采用位级和向量级特征的外积形式 [9, 10]。
尽管现有的嵌入式方法已经取得了一定的成功,但它们大都遵循一个模式,即在专家指导下,通过相同的预定义操作来建模交叉特征,并等同地枚举所有的特征和交叉特征。这其中存在着两个局限:首先,这些方法无法确保模型的学习能力,因为它们的架构对于具体的任务和数据缺乏适应性。其次,无关的特征和交叉特征可能会引入不必要的噪声,从而使训练过程变得更加复杂。举图4的例子来说,专家们可能会定义一种按位求和的操作,但是对于用户收入和手机操作系统之间的按位求和可能会产生无关的交叉特征,从而增加模型训练的复杂性。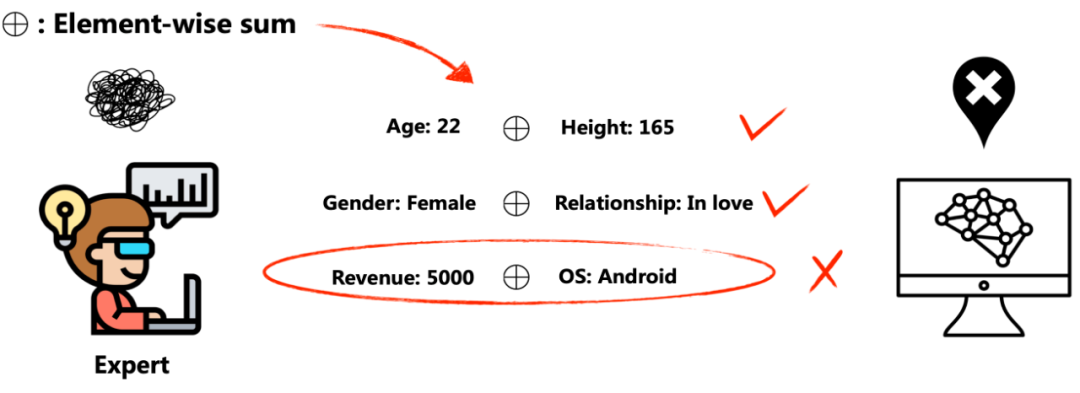
因此,我们期望理想的交叉特征选择方法应当能自适应地演化模型,以在任务指导下选择适当的操作进行特征对之间的交叉。一种可能实现模型演化的方法是进化学习,这是一种受自然启发的元启发式算法,能够解决机器学习中的复杂搜索问题。它也包括进化式自动机器学习(AutoML)方法 [11]。一般用于特征选择的进化学习算法由五个步骤组成 [11],见图5所示,包括:1)编码;2)初始化;3)搜索策略;4)特征集建模;以及5)模型适应度评估(Model Fitness Evaluation)。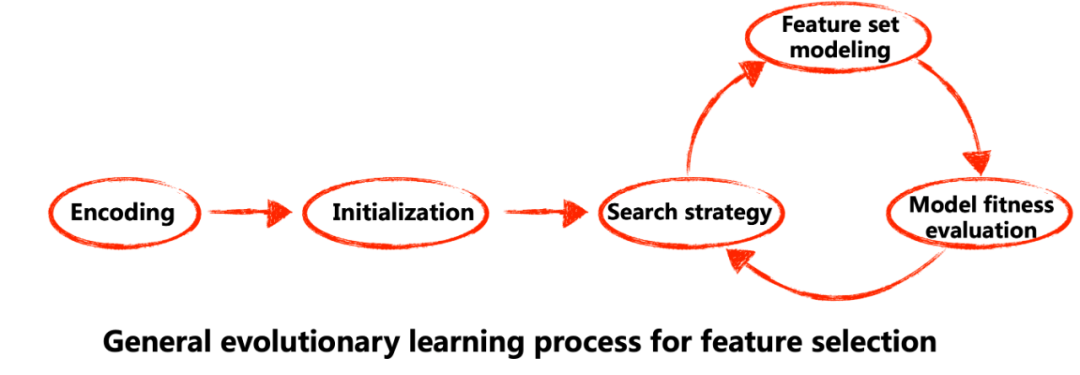
现有的研究表明,由于模型适应度评估的限制,基于进化算法的特征选择主要应用于过滤器和包装器方法 [2, 11]。具体来说,包装器方法将学习算法的性能作为其评估标准,而过滤器方法则依赖于数据的内在特征。另一方面,嵌入式方法在选择特征的同时也学习分类器。因为传统的进化算法通常将个体视为原子解决方案,依赖数值响应进行适应度评估,只提供了模型整体状况的概述,所以,对于评估嵌入式方法的适应度,传统的进化算法显得力不从心,这一观点在许多研究中已经得到了证实 [2, 11]。最近,一些嵌入式方法采用基于梯度下降的 AutoML 算法来搜索神经架构以预估点击率 [12, 13]。然而,这些方法通常依赖于一个难以满足的假设(期望搜索空间是连续、可微的凸函数)来将模块的离散选择放宽为所有模块上的连续softmax 选择 [14]。通常,它们的模块是复杂的架构级别的算法,例如多层感知机(MLP)或FM,因此,通常需要大规模的种群和大量的迭代来解决巨大的搜索空间难题 [13]。综上所述,如何设计一种元启发式进化算法,能够超越在模型的表面层次评估模型,进而深入诊断模型内部组件的学习能力,是设计自适应交叉特征选择算法的关键。
在认知科学理论的指导下,我们认识到,包括意识、知觉、记忆、学习和分析能力等在内的认知功能,是适应环境的强有力的决定因素 [15]。这些认知能力使生物体能够感知、记忆并妥当地对环境变化作出反应。从认知神经科学的视角看,这种发展认知功能的能力被定义为延展性,它赋予生物体对环境的适应性 [16, 17]。如图7所示,人类在婴儿阶段,大脑的延展性最强,因此能有效地适应环境中的各种任务,如学习一种全新的语言。这种内在的延展性对发展各种心理活动极为关键,同时也被视为一种衡量智力的标准 [17, 18]。
最新的认知人工智能(Cognitive AI)研究强调对生物体认知能力的定量分析和模拟 [19]。我们的研究团队一直致力于探索和理解人的认知能力,并且已经开展了一系列关于认知诊断的研究 [20, 21, 22]。本研究深受这些认知诊断原理的启发。在本文介绍的工作中,希望整合这些认知能力的理念,尤其是神经延展性或基因延展性(见图8),以发展出具有环境适应性的模型。因此,本文迈出了依据表面层次的“表象”评估模型,选择在更深层次的基因水平精细地诊断模型。
受自然生物体进化和性状显现机制的启发,本文提出了一种认知进化搜索(Cognitive Evolutionary Search)算法框架,缩写为CELS。在交叉特征选择的任务中,CELS 强调搜索细粒度的底层操作,而不是粗粒度的上层架构。如图9所示,CELS 将交叉特征视为基因组,将模型视为生物体,将任务视为自然环境。CELS 将交叉特征选择过程视为一个进化搜索过程,它模拟了生物体为了提高适应度而努力进化出更好的特征。可以理解为,不同的特征为模型提供了不同的生存率和适应度,模型进化过程反映了特征及交叉特征的选择过程。
为了体现基因延展性如何促进发展环境适应性,本文对模型适应度的进行了深度诊断,以模拟生物体的自然选择和生存率。如图10所示。
这种适应度诊断(Fitness Diagnosis)技术与传统的适应度评估(Fitness Evaluation)技术形成了鲜明的对比,后者主要通过数值评估来衡量模型的适应度。新的适应度诊断方法使我们能够更深入地探究模型,明确其内部组件的功能。如图11所示。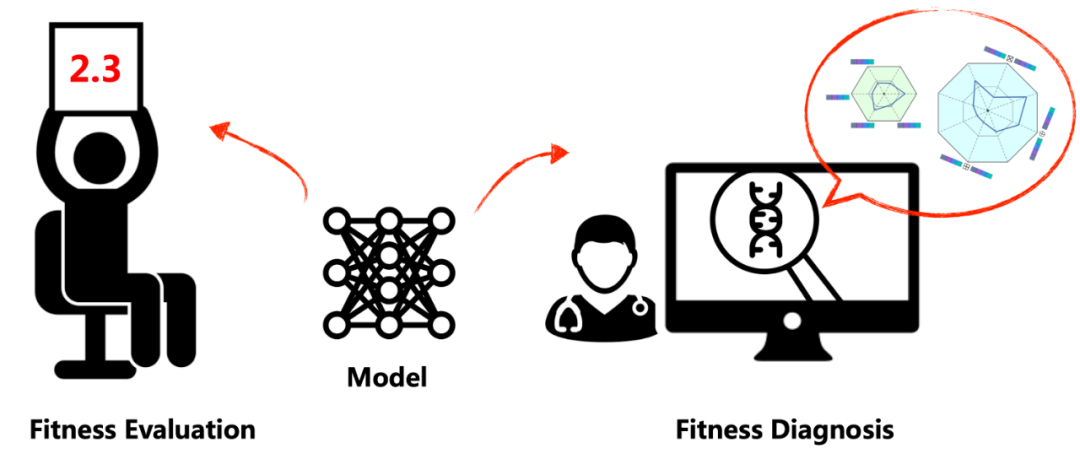
在CELS框架中,特征被视为核苷酸,操作被视为配对相连的碱基。为了发现每个特征对产生任务友好交叉特征的最适操作,搜索空间被扩大并引入了各种类型的操作,这反映了核苷酸配对原则的实施方式。简洁地,选出了四种代表性的操作作为候选操作,如图12所示,以此展示CELS的工作原理。按位求和(⊕):此操作接受两个输入向量,并输出包含它们逐位求和的向量。按位乘积(⊗):此操作接受两个输入向量,并输出包含它们逐位乘积的向量。连接与前馈层(⊠):此操作接受两个输入向量,将它们连接起来,并通过带ReLU激活函数的前馈层传递,以降低输出向量的维度。按位乘积与前馈层(⊞):此操作接受两个输入向量,并将它们的逐位乘积通过带ReLU激活函数的前馈层传递,以生成输出向量。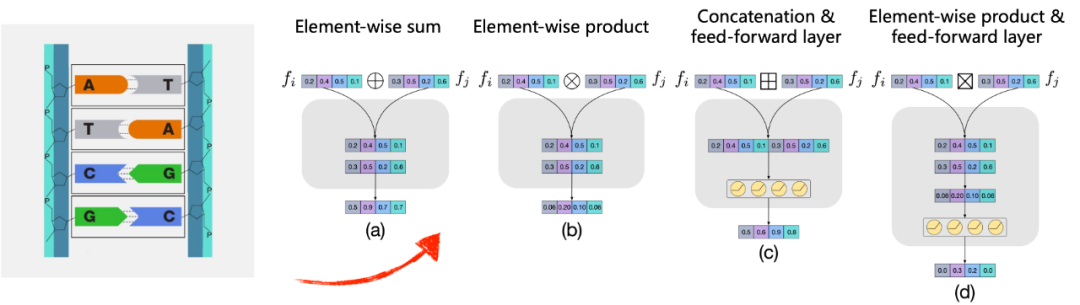
作为对比,本文提出了认知进化搜索的一般过程,如图13所示,该过程包括四个主要步骤:1)编码,2)初始化,3)模型适应度诊断,以及4)模型生成。在编码步骤完成后,通过随机为特征对分配操作来生成初始模型。CELS 迭代地诊断当前模型(也就是父代模型)中的特征及其交叉特征的相关性,并将不相关的交叉特征的操作变异为其他操作,以此创建新的模型(也就是子代模型)。如此,父代模型被下一代经过变异产生的子模型所替代。接下来的部分将重点阐述模型适应度诊断和个体变异的具体实现策略。
对于生物体来说,如果其基因组区域能解码出有助于生存的表型,那么它就会具有较高的适应性;反之,如果基因组区域解码出的表型对生存无益,那么它的适应性就会相对较差。进化策略应当有助于保留有益的遗传信息,这促使通过相关性参数来衡量特征及其交叉特征的相关性。让 𝜶 和 𝜷 分别表示特征 𝒇 和交叉特征 𝒈(𝒇) 的相关性参数。当前学习模型的预测响应可以给出:本文建议与特征嵌入向量同时优化 𝜶、𝜷,其中特征嵌入由 Adam 优化器学习,而 𝜶、𝜷 由在线学习优化器学习。传统的进化学习的适应度评估技术主要依赖预测响应来衡量当前模型的适应度,并据此指导生成后代模型的随机变异过程。这种适应度评估技术只提供了模型整体状况的概述,因此其引导的变异可能缺乏明确的方向性。相比之下,CELS 更偏向于诊断模型内部组件的学习能力,以便对特定的、低效的组件进行有针对性的变异,如图14所示。
个体变异机制如图15所示,CELS 利用在线学习优化器来区分特征和交叉特征的相关性,一旦交叉特征的相关性降低到设定的阈值,变异就有可能发生,将改变交叉特征的操作,这是遗传变异的来源。CELS 基于个体变异进行搜索的一个简单实例是 (1,1)-CELS 。首先创建一个初始模型,其中的操作被随机分配给特征对,然后通过特征嵌入同时优化相关性参数。当某个交叉特征的相关性较低(用较浅的颜色表示)时,这些交叉特征将被选为变异目标,这意味着交叉特征的操作将会变成其他的操作。与 (1,1)-CELS 会确定性地用子代模型替换父代模型不同的是,(1+1)-CELS 让子代模型与父代模型竞争。只有当子代的适应度至少与父代一样好时,才会接受并继承父代,否则,子代将会被丢弃。另外,(1+1)-CELS 引入了1/5成功原则以适应搜索范围 [23, 24]。这意味着,如果在过去的迭代过程中,搜索经常未能得到更优的模型,那么现有的模型可能已经接近局部最优。在这种情况下,应当降低变异的概率,以便更好地利用最优解周围有潜力的区域。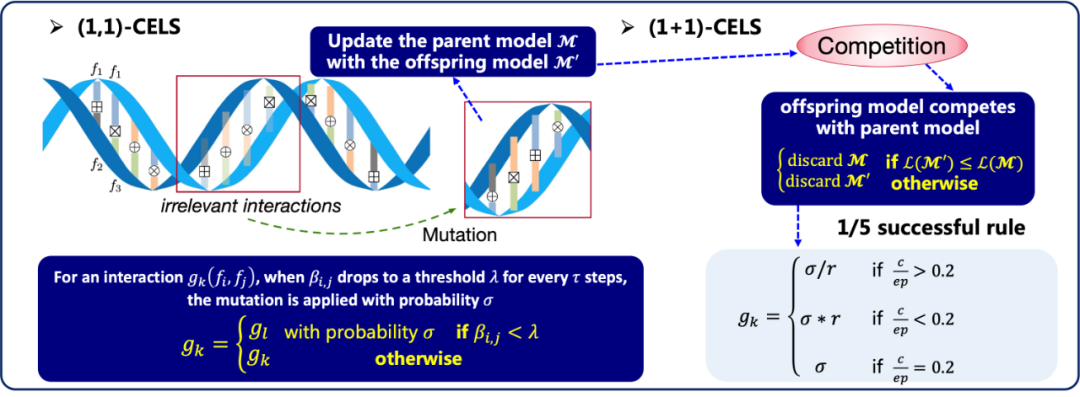
使用种群(而非单一父代模型生成子代模型)已被证实能有效防止搜索过程陷入局部最优 [25, 26, 27]。在实现基于群体搜索的 (n,1)-CELS 中,首先初始化 𝑛 个随机模型。然后,为了从种群中迭代生成子代模型,提出了一种应用于多个父代模型的杂交机制:选取种群中最适(具有最大相关性的交叉特征)的操作进行交叉,从而生成后代模型。如图16所示。随后,为了保持种群的多样性,实施变异机制。在 (n,1)-CELS 中,适应度最差的父代模型将被淘汰,而新生成的子代模型将加入新一代父代模型池。(n+1)-CELS 则结合了 (1+1)-CELS 和 (n,1)-CELS 的策略,从父代和子代模型中竞争选出新一代的父代模型。只有当子代模型的适应度达到或超过最差父代模型的适应度时,子代模型才能加入到新一代的父代模型池。1/5成功原则也被用于调整整个种群的搜索范围。
遗传信息通过连续的复制和转录过程被解码,翻译成对应的蛋白质序列。这一过程使得生物体的各种潜在功能得以显现。为了模仿这个自然过程,重新训练模型。根据相关性参数选择相关特征和交叉特征。如果 则相应的特征或交叉特征被认定为永久丢弃。为了更深入地捕捉到选定的相关特征和交叉特征的非线性交叉,在模型显现阶段,可以选择使用深度学习模型或 Wide&Deep 模型,如图17所示。其中,相关性参数被固定并被用作注意力单元。
则相应的特征或交叉特征被认定为永久丢弃。为了更深入地捕捉到选定的相关特征和交叉特征的非线性交叉,在模型显现阶段,可以选择使用深度学习模型或 Wide&Deep 模型,如图17所示。其中,相关性参数被固定并被用作注意力单元。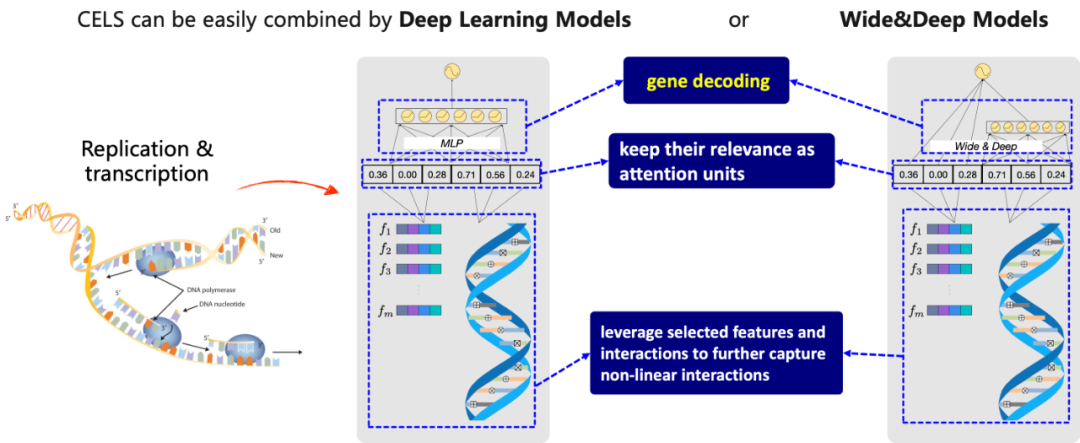
将 CELS 定位于广阔的进化计算领域,如图18所示。传统的进化算法通常将个体视为原子解决方案,通过数值响应进行适应度评估,然后舍弃竞争力较弱的个体。然而,这种方法常常忽视了模型的内在能力。CELS 引入了一种新的基于认知进化的视角。CELS 整合了认知能力的概念,尤其是神经延展性或基因延展性,以促进对环境的适应性。CELS 超越了仅依据表面层次的“表象”来评估个体,转而选择在基因层面对模型进行深入诊断。所以,提出的方法允许评估模型的内在能力,并促进针对性的变异机制。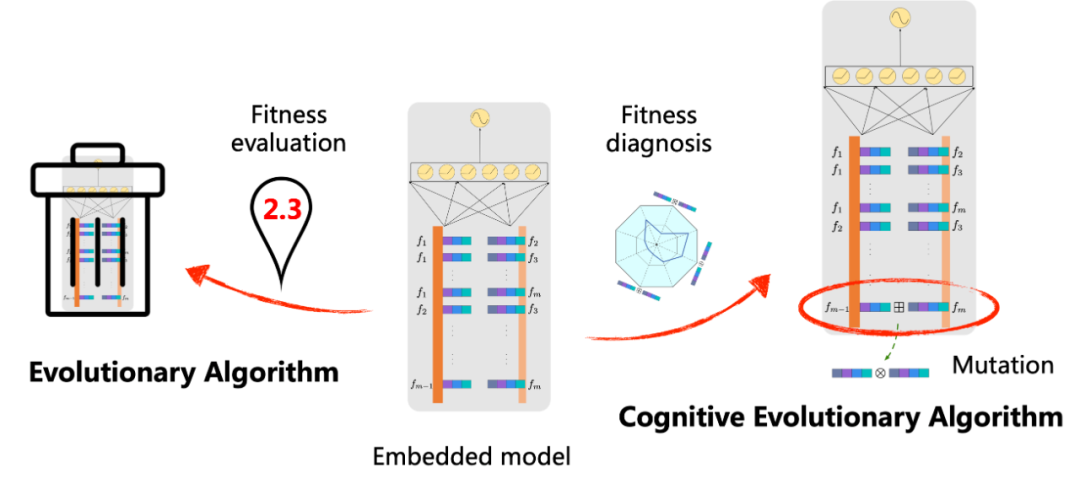
在实验部分,选择了Criteo、Avazu 和 Huawei 三个公开的广告数据集进行点击率预测,其统计数据如图19所报告。为了进行性能评估,选择了两个被广泛使用的评价指标,即AUC(曲线下面积)和 Logloss(交叉熵损失)。
图20展示了在三个数据集上,基准算法与 CELS 的性能对比结果。其中,Impr 表示相对于 AUC 的改进率。首先,OPNN、AutoGroup 和 xDeepFM,它们分别通过按位外积、内积和压缩交叉网络来建模交叉特征 [10, 28, 29],是 Criteo、Avazu 和 Huawei 数据集上的最佳基准模型。这些结果与本文的断言一致,即无法确定哪些预先设计的操作更好,因为它们对任务和数据集的适应性较差。其次,CELS 的各实例算法在所有三个数据集上的 AUC 和 Logloss 分数都显著超过了基线模型。这种性能提升可以归因于 CELS 通过自适应演化的方式来建模交叉特征,从而找到合适的操作。第三,在 CELS 的各个实例化算法的性能比较中,可以观察到 (1+1)-CELS 优于 (1,1)-CELS,(n+1)-CELS 优于 (n,1)-CELS,这表明子代模型与父代模型间的竞争是有效的,且 1/5 成功原则可以调整变异概率以更好地收敛搜索范围。同时,(n,1)-CELS 优于 (1,1)-CELS,并且 (n+1)-CELS 优于 (1+1)-CELS,这说明使用种群能够使搜索过程更加多样化,既不容易受初始模型的影响,也不容易陷入局部最优解。除了预测性能,还展示了四种 CELS 实例化算法的训练成本。所有的实验都在配备单个 NVIDIA Tesla A100 GPU 的 Linux 服务器上进行,每个数据集的整个训练过程不到一个小时。与以往需要多个 GPU 运行数天的 AutoML 方法相比 [13],表明了算法效率的显著提升。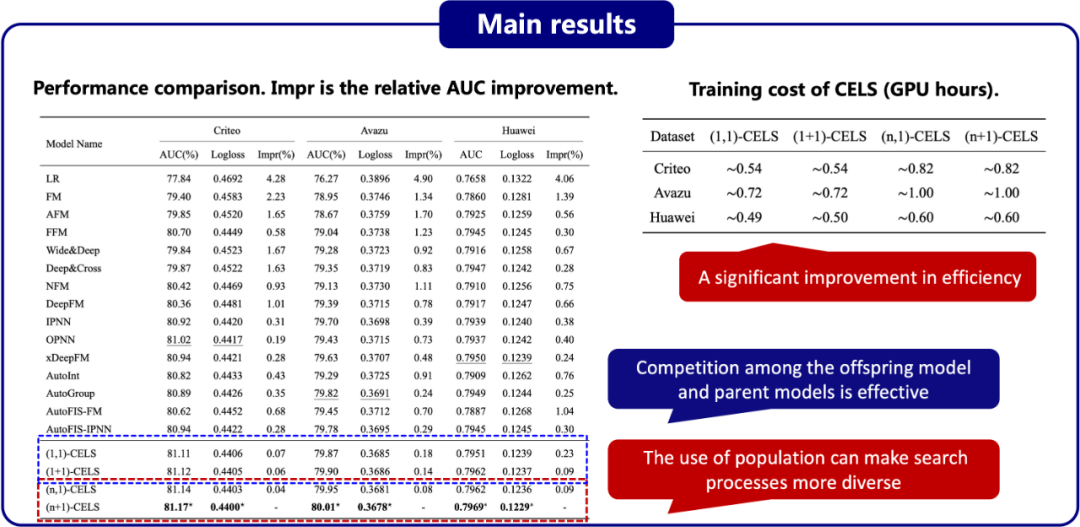
为了阐明模型如何演化以在任务指导下选择合适的操作,这里在 Criteo 数据集上可视化了 CELS 的演化路径。如果使用以下编码 ⊕ = 0,⊗ = 1,⊞ = 2,⊠ = 3,则模型的适应度可以表示为矩阵。此外,为操作分配不同的颜色以构建模型的基因图,其中每个基因表示交叉特征,即红色的“0”、绿色的“1”、黄色的“2”,和蓝色的“3”。为了表达交叉特征的相关性,根据相关性参数突出显示某些基因。较深的颜色表示被诊断为更相关的交叉特征,而较浅的颜色表示较不相关的交叉特征。如图21所示,对于基于个体的搜索 (1,1)-CELS 和 (1+1)-CELS,可以观察到,模型在开始时随机分配操作来建模所有交叉特征,并且所有交叉特征的相关性相等。随后,基因图在早期迭代中快速演化,一些交叉特征被发现成为相关的交叉特征(颜色变得更深),而大多数其他交叉特征变得不那么重要(颜色变得更浅),有些交叉特征变异成了新的交叉特征。一些交叉特征的相关性参数被降低并截断为 0。丢弃这些不相关的交叉特征,因此它们的基因变成了白色的“−1“(在图示中使用⊘来编码这些操作)。最终,搜索过程趋于收敛,模型的内部操作几乎没有再发生变化。对比 (1,1)-CELS 和 (1+1)-CELS,可以观察到 (1+1)-CELS 的收敛速度比 (1,1)-CELS 快,这得益于父模型和子模型之间的竞争。由于竞争和 1/5 成功原则,变异概率可以自适应地收敛搜索范围。基于个体的搜索最大的缺陷是它非常容易受到初始化的影响。尽管模型通过变异和演化趋向于适应任务和数据,但最终模型仍然与初始模型有许多相似之处。这在很大程度上是由于搜索空间是高维的,并且基于个体的搜索具有不足的探索能力,容易陷入局部最优解。基于种群的搜索通过增加更多的父代和引入杂交机制,成功克服了上述问题。如图22所示,在搜索开始时,四个初始模型被随机分配了各种操作。然后,杂交机制在这四个父代模型中应用,产生一个新模型,该模型经过变异生成子代。在大量的杂交和变异后,基于种群搜索演化出的最终模型几乎与任何初始模型都没有相似性。这些观察结果进一步证实了本文的提议,即使用种群能够增加模型的基因多样性,使搜索过程不容易陷入局部最优解,从而更好地探索全局区域。然而,过度的探索可能会导致搜索过程无法收敛。结果显示,(n,1)-CELS 的收敛速度相对较慢。相比较而言,(n+1)-CELS 的收敛速度更快,这得益于父代和子代之间的竞争以及 1/5 成功原则。因此,本文认为 (n+1)-CELS 在模型演化的探索和利用之间达到了理想的平衡。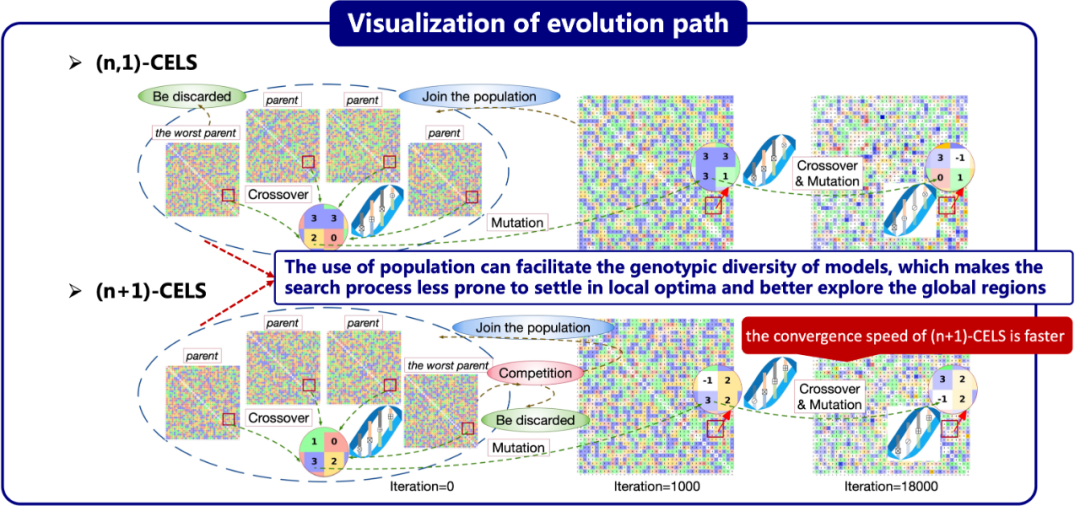
从应用的角度来看,CELS 提供了一种新的智能营销和交叉特征选择的方法。它能够自适应地演化模型,在任务指导下选择合适的操作建模交叉特征,如图23所示。CELS 突破了传统的交叉特征选择方法所需的专业知识壁垒,从而成为一种适应多种场景的通用算法。
从算法的视角出发,CELS 侧重于模型的认知能力,引入了基因延展性的概念,从而使模型具备了对多种环境的适应性。从进化计算的角度看,适应度诊断技术有助于评估模型的内在潜力,并促进有针对性的变异机制。这使得模型演化路径的可视化成为现实。本文展示了通过个体变异和种群杂交,CELS 如何演化成适应各种任务和数据集的各种模型,提供了即用(ready-to-use)的模型。根据进化策略的标准命名法 [23],从业者可以轻松地扩展 CELS 到其衍生版本,如 (n,𝜅)-CELS 和 (n+𝜅)-CELS。总之,利用个体变异和种群杂交的 CELS 框架代表了一种新的思维方式,它能够帮助从业者在任务的指导下构建模型,而不仅限于本文中的实例。在未来的研究中,作者将更深入地探讨模型演化的内在规律,并尝试为其演化行为建立理论框架。同时,作者鼓励基于本文的研究,提出更多面向特定任务的算法实例。
参考文献
[1] Runlong Yu, Yuyang Ye, Qi Liu, Zihan Wang, Chunfeng Yang, Yucheng Hu, and Enhong Chen. 2021. Xcrossnet: Feature structure-oriented learning for click- through rate prediction. In Advances in Knowledge Discovery and Data Mining: 25th Pacific-Asia Conference (PAKDD). Springer, 436–447.[2] Bing Xue, Mengjie Zhang, Will N Browne, and Xin Yao. 2015. A survey on evolutionary computation approaches to feature selection. IEEE Transactions on Evolutionary Computation 20, 4 (2015), 606–626.[3] Steffen Rendle. 2010. Factorization machines. In 2010 IEEE International Conference on Data Mining (ICDM). IEEE, 995–1000.[4] Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Field-aware factorization machines for CTR prediction. In Proceedings of the 10th ACM Conference on Recommender Systems (RecSys). 43–50.[5] Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and Tat-Seng Chua. 2017. Attentional factorization machines: learning the weight of feature interactions via attention networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI). 3119–3125.[6] Xiangnan He and Tat-Seng Chua. 2017. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval (SIGIR). 355–364.[7] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. 7–10.[8] Huifeng Guo, Ruiming Tang, et al. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI). 1725–1731.[9] Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17. 1–7.[10] Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature in- teractions for recommender systems. In Proceedings of the 24th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (KDD). 1754–1763.[11] Akbar Telikani, Amirhessam Tahmassebi, et al. 2021. Evolutionary machine learning: A survey. Comput. Surveys 54, 8 (2021), 1–35.[12] Farhan Khawar Xu Hang, Ruiming Tang, Bin Liu, Zhenguo Li, and Xiuqiang He. 2020. Autofeature: Searching for feature interactions and their architectures for click-through rate prediction. In ACM International Conference on Information and Knowledge Management (CIKM). 625–634.[13] Qingquan Song, Dehua Cheng, Hanning Zhou, Jiyan Yang, Yuandong Tian, and Xia Hu. 2020. Towards automated neural interaction discovery for click-through rate prediction. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD). 945–955.[14] Hanxiao Liu, Karen Simonyan, and Yiming Yang. 2019. DARTS: Differentiable architecture search. In International Conference on Learning Representations.[15] Lukasz Stasielowicz. 2020. How important is cognitive ability when adapting to changes? A meta-analysis of the performance adaptation literature. Personality and Individual Differences 166 (2020), 110178.[16] Angela Gutchess. 2014. Plasticity of the aging brain: new directions in cognitive neuroscience. Science 346, 6209 (2014), 579–582.[17] Kenneth S Kendler, Eric Turkheimer, Henrik Ohlsson, Jan Sundquist, and Kristina Sundquist. 2015. Family environment and the malleability of cognitive ability: A Swedish national home-reared and adopted-away cosibling control study. Proceedings of the National Academy of Sciences (PNAS) 112, 15 (2015), 4612–4617.[18] William E Hyland et al. 2022. Interest–ability profiles: An integrative approach to knowledge acquisition. Journal of Intelligence 10, 3 (2022), 43.[19] Yanyan Dong, Jie Hou, Ning Zhang, and Maocong Zhang. 2020. Research on how human intelligence, consciousness, and cognitive computing affect the development of artificial intelligence. Complexity 2020 (2020), 1–10.[20] Fei Wang, Qi Liu, Enhong Chen, Zhenya Huang, et al. 2020. Neural cognitive diagnosis for intelligent education systems. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Vol. 34. 6153–6161.[21] Qi Liu, Runze Wu, Enhong Chen, Guandong Xu, Yu Su, Zhigang Chen, and Guoping Hu. 2018. Fuzzy cognitive diagnosis for modelling examinee performance. ACM Transactions on Intelligent Systems and Technology 9, 4 (2018), 1–26.[22] Shiwei Tong, Qi Liu, Runlong Yu, Wei Huang, Zhenya Huang, Zachary A Pardos, Weijie Jiang. 2021. Item Response Ranking for Cognitive Diagnosis. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI). 1750-1756.[23] Hans-Georg Beyer and Hans-Paul Schwefel. 2002. Evolution strategies–a comprehensive introduction. Natural Computing 1 (2002), 3–52.[24] Runlong Yu, Hongke Zhao, Zhong Wang, Yuyang Ye, Peining Zhang, Qi Liu, and Enhong Chen. 2019. Negatively correlated search with asymmetry for real- parameter optimization problems. Jisuanji Yanjiu yu Fazhan/Computer Research and Development 56, 8 (2019), 1746 – 1757.[25] Jun He and Xin Yao.2002. From an individual to a population: An analysis of the first hitting time of population-based evolutionary algorithms. IEEE Transactions on Evolutionary Computation 6, 5 (2002), 495–511.[26] Rammohan Mallipeddi and Ponnuthurai N Suganthan. 2008. Empirical study on the effect of population size on differential evolution algorithm. In 2008 IEEE Congress on Evolutionary Computation. IEEE, 3663–3670.[27] Ke Tang, Peng Yang, and Xin Yao. 2016. Negatively correlated search. IEEE Journal on Selected Areas in Communications 34, 3 (2016), 542–550.[28] Yanru Qu, Han Cai, Kan Ren, Weinan Zhang, et al. 2016. Product-based neural networks for user response prediction. In 2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 1149–1154.[29] Bin Liu, Niannan Xue, Huifeng Guo, Ruiming Tang, Stefanos Zafeiriou, Xiuqiang He, and Zhenguo Li. 2020. AutoGroup: Automatic feature grouping for modelling explicit high-order feature interactions in CTR prediction. In Proceedings of the 43rd international ACM SIGIR conference on Research and Development in Information Retrieval (SIGIR). 199–208.

更多内容,点击下方关注: