回想两个月前,LLaMA2 的开源,曾以一己之力改变了大模型领域的竞争格局。相比于今年 2 月推出的第一代 LLaMA,LLaMA2 在推理、编码、精通性和知识测试等任务中都实现了性能的大幅提升,甚至可以在某些数据集上接近 GPT-3.5。由于其强大的性能和开源的特质,LLaMA2 在发布后的一周内就接收到了超过 15 万次的下载请求,并吸引了大量开发者进行「二创」。但大模型技术的进化速度经常超乎预期。一觉醒来,发现大模型的性能上限被再次刷新,这在最近是经常发生的事情。近期就有一位「选手」,在开源大模型社区的关注度不断攀升,逐渐超越 LLaMA2 成为了新晋顶流。在 Huggingface 社区,「Baichuan」系列是过去一个月下载量全球最高的开源大模型,它来自一家成立仅五个月的中国公司 —— 百川智能。在 ChatGPT 爆火之初,王小川即宣布入局大模型,并迅速组建起大模型技术团队。自成立以来,这家公司保持了平均每月更新一款大模型的惊人节奏:6 月 15 日,发布 Baichuan-7B;7 月 11 日,发布 Baichuan-13B;这两款免费可商用的中文开源大模型之后,8 月 8 日,搜索增强大模型 Baichuan-53B 面世。9 月 6 日,百川智能又一次宣布了重量级更新:Baichuan2-7B、Baichuan2-13B 的 Base 和 Chat 版本同时开源,并提供了 Chat 版本的 4bits 量化,且均为免费可商用。平均 28 天发布一款大模型,这是国产开源大模型的迭代速度,也代表了中国开源力量迎头赶上的决心。迄今,Baichuan-7B 和 Baichuan-13B 这两款开源大模型目前的下载量已经突破 500 万,其中近一个月的下载量就有 300 多万。除开发者之外,也有 200 多家企业申请部署开源大模型。
未来的大模型竞争格局中,谁能占据核心地位仍是未知。但不难想象的是,既已实现对 LLaMA2 的超越,再加上惊人的迭代速度,国产开源大模型的黄金时代应该不远了。Baichuan 2 下载地址:https://github.com/baichuan-inc/Baichuan2让整个领域感到惊讶的不只是「Baichuan」系列的更新速度,还有其迭代后的模型能力。曾曝光 GPT-4 技术细节的软件开发者、Kaggle大神、 Deep trading 创始人 Yam Peleg 通读了 Baichuan 2 的技术报告,直言这是一次相当重大的改进。
他特别提到一点:「就像 GPT-4 的报告一样,团队在训练开始前就预测了最终损失。为此,他们训练了从 1 千万到 3 亿的小模型,并根据这些模型的损失预测了大模型的最终损失。据我所知,这是首个能够复制这一程序的开源模型。」
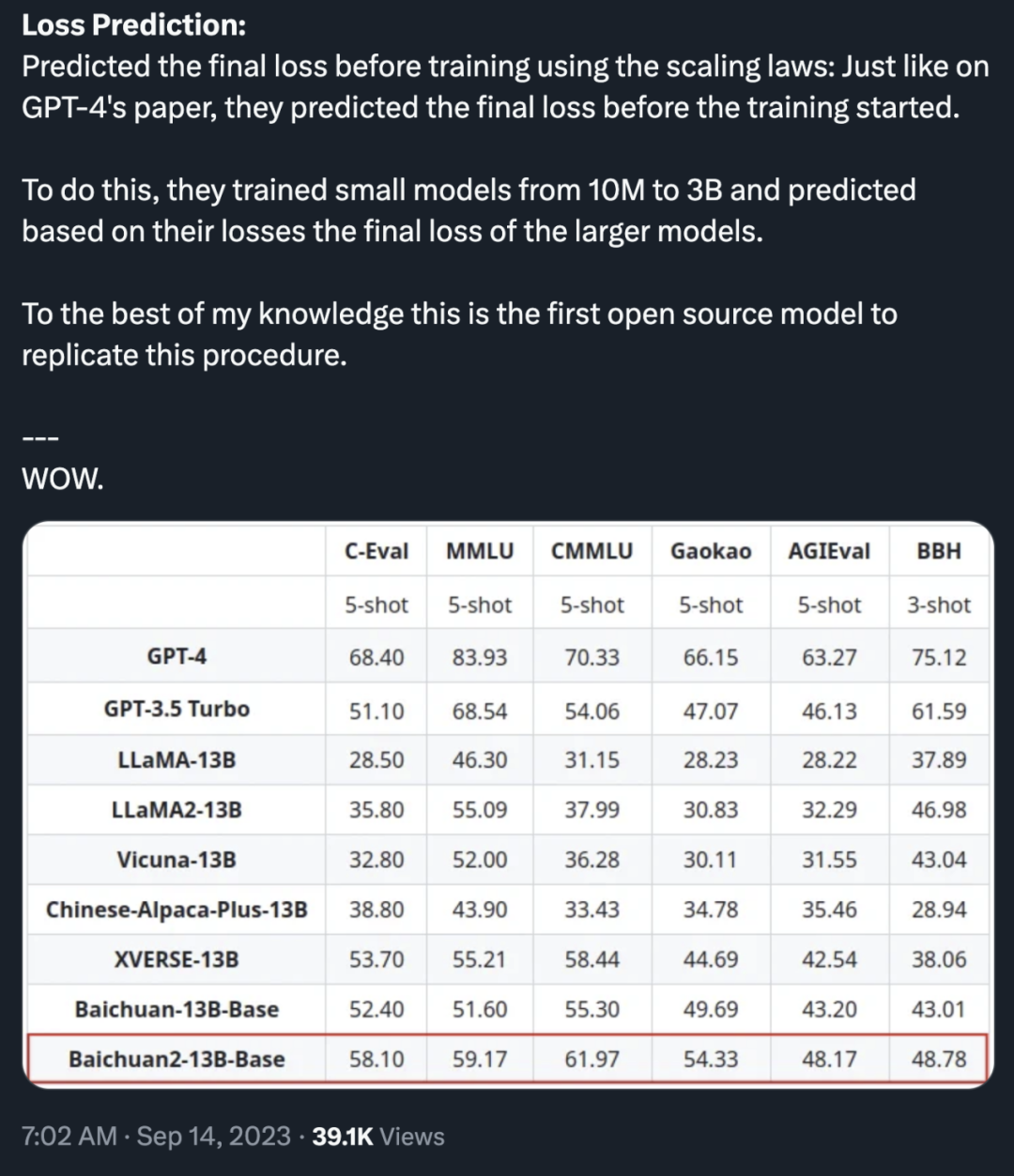
图片来源:https://twitter.com/Yampeleg/status/1702095404802637874?s=19
基于上一代 Baichuan 大模型,Baichuan 2 保留了良好的生成与创作能力、流畅的多轮对话能力以及部署门槛较低等众多特性,同时实现了数学、代码、安全、逻辑推理、语义理解等能力的大幅提升。根据公开的 Baichuan 2 技术报告,Baichuan2-7B-Base 和 Baichuan2-13B-Base 均基于 2.6 万亿高质量多语言数据进行训练,数据来源十分广泛: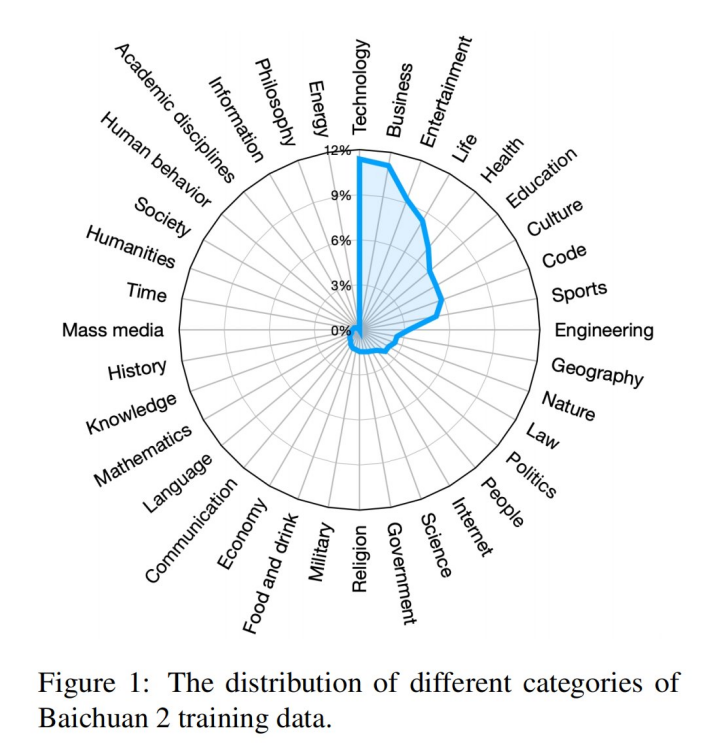
同时,Baichuan 2 建立了一个可在数小时内对万亿规模的数据进行聚类和重复数据删除的系统,提升了预训练中数据采样的质量。此外,Tokenizer 需要平衡提高推理效率的高压缩率以及适当大小的词汇量,以确保每个词嵌入的充分训练。在 Baichuan 2 的训练中,词汇量从 Baichuan1 的 64,000 个扩大到了 125,696 个。这些方法,最终使得 Baichuan 2 在计算效率和模型性能之间取得了更好的平衡。在 MMLU、CMMLU、GSM8K 等多项权威基准上,Baichuan 2 均以绝对优势领先 LLaMA2。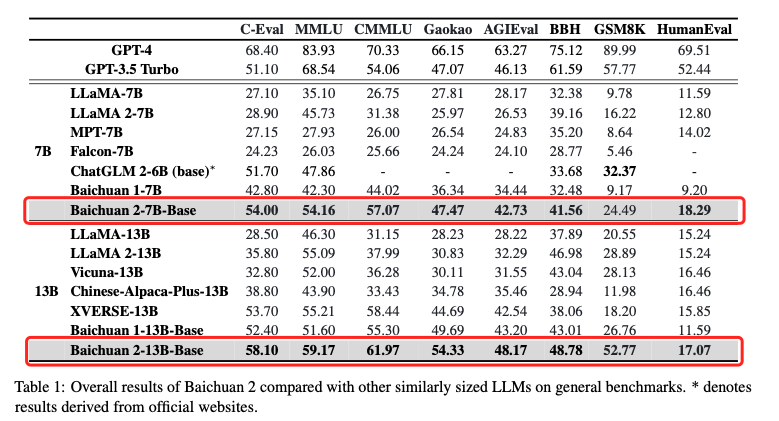
Baichuan 2 性能大幅度优于 LLaMA2 等同尺寸模型竞品。如表 5 所示,在法律领域,Baichuan 2-7B-Base 超越了 GPT-3.5 Turbo、ChatGLM 2-6B 和 LLaMA 2-7B 等模型,仅次于 GPT-4,与 Baichuan1-7B 相比提高了近 30%;在医疗领域,Baichuan2-7B-Base 的表现明显优于 ChatGLM 2-6B 和 LLaMA 2-7B,与 Baichuan1-7B 相比也有显著提高。同样,在这两个领域,Baichuan2-13B-Base 则超越了同尺寸所有模型。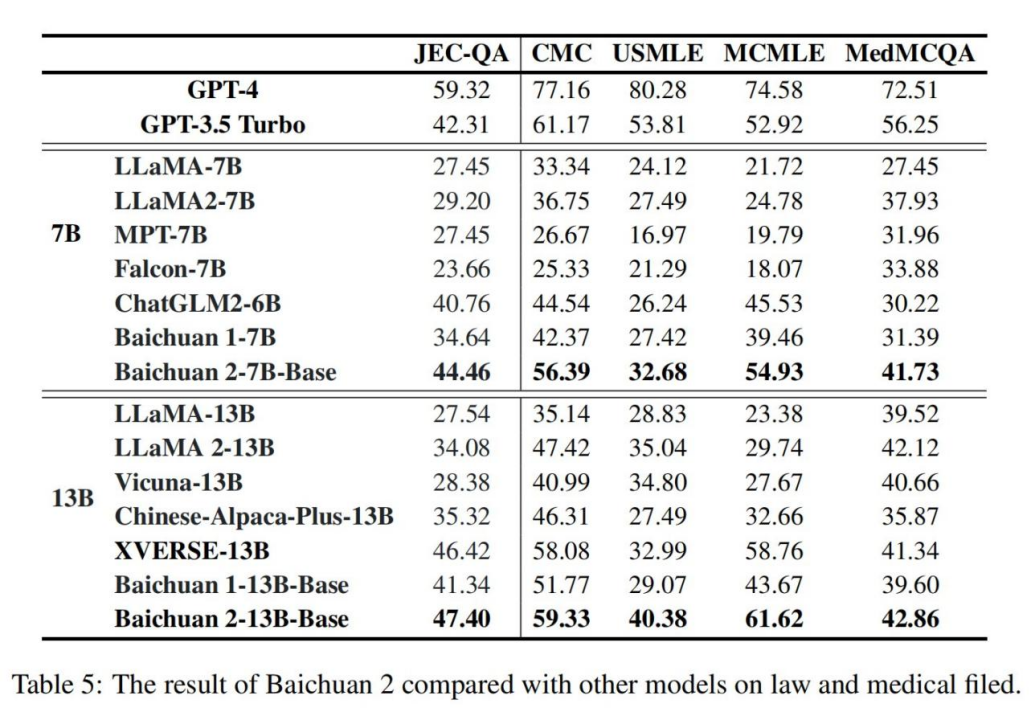
如表 6 所示,在数学领域,Baichuan2-7B Base 超越了 LLaMA 2-7B 等模型,Baichuan2-13B-Base 超越了所有相同规模的模型,接近 GPT-3.5 Turbo 的水平;在代码领域,Baichuan2-7B Base 超越了同等规模的 ChatGLM 2-6B 等模型,Baichuan2-13B-Base 优于 LLaMA 2- 13B 和 XVERSE-13B 等模型。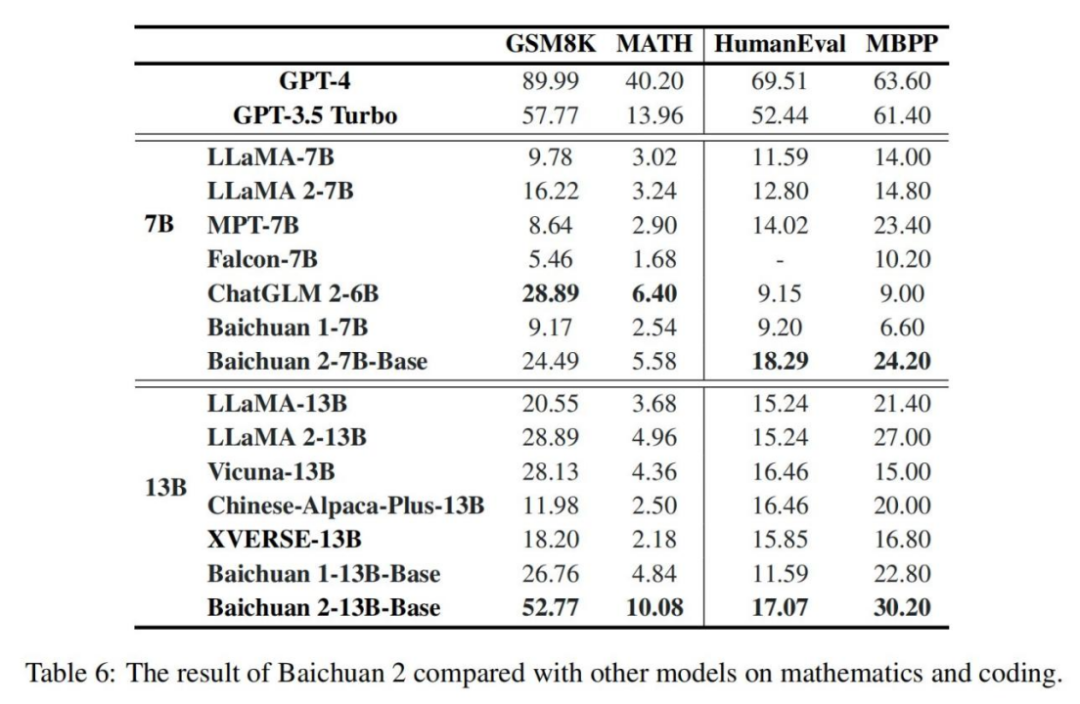
尽管 GPT-4 在多语言领域仍占主导地位,但开源模型正紧追不舍。如表 7 所示,在多语言场景的任务评估中,Baichuan2-7B-Base 在所有七项任务中都超过了所有同等规模的模型;Baichuan 2-13B 在四项任务中的表现优于相同规模的模型,其中在 zh-en 和 zh-ja 任务上超过了 GPT3.5 Turbo,达到了 GPT-4 的水平。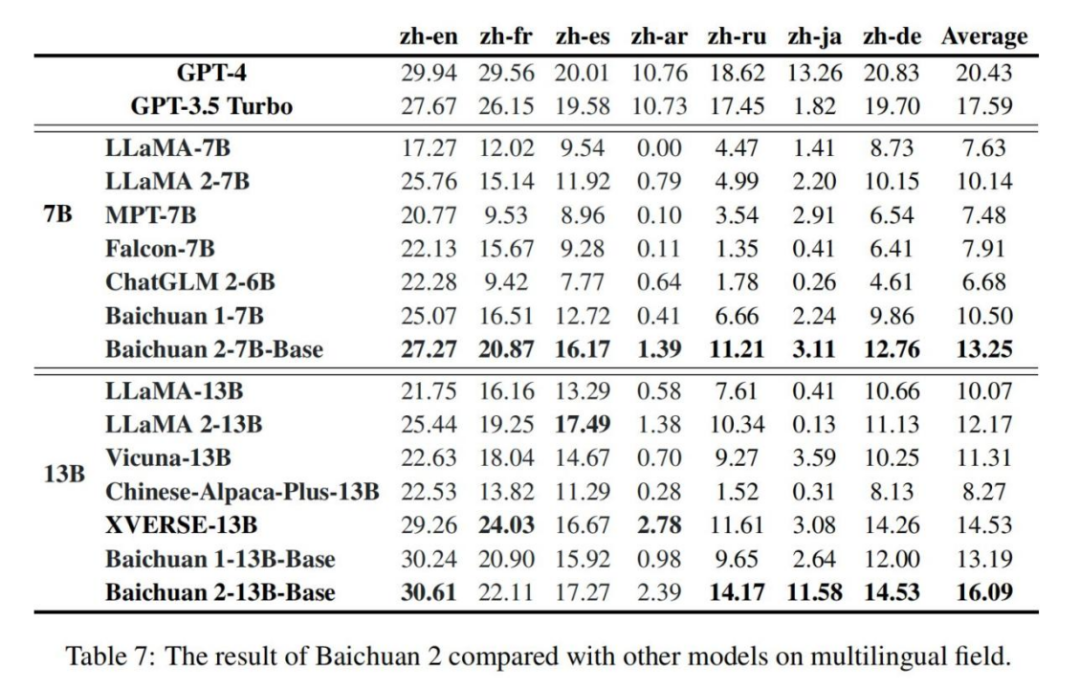
对于中国的众多开发者来说,Baichuan 2 的开源是一个令人振奋的好消息。这就要提到 LLaMA2 的「开源争议」。Meta 官宣的第二天,便有开发者抛出质疑:LLaMA2 不属于真正的「开源」,所谓的「可商用协议」本质上附加了许多限制。首先,Llama 2 的语料库以英文(89.7%)为主,中文仅占据其中 0.13%,因此在中文场景任务中并不占优势。其次,Llama 2 在协议中明确禁止非英文场景的商用。Baichuan 2 的能力完全可以与 LLaMA2 相媲美,甚至超越。而且在「免费商用」这件事上,Baichuan 2 实践得更加彻底,弥补了中国开源生态的短板,让中国开发者用上了对中文场景更友好的开源大模型。Baichuan2-7B 和 Baichuan2-13B 不仅对学术研究完全开放,企业也仅需邮件申请获得官方商用许可后,即可免费商用。更具备长期价值的一点是,这次彻底的、完全的开源,能够帮助大模型学术机构、开发者和企业用户更深入的了解 Baichuan 2 的训练过程,推动社区对大模型学术层面的深入研究。从理论研究的角度,大模型训练包含海量高质量数据获取、大规模训练集群稳定训练、模型算法调优等多个环节。每个环节都需要大量人才、算力等资源的投入。由于大部分开源模型只能做到对外公开自身模型权重,却很少提及训练细节,所以企业、研究机构、开发者们只能自己摸索着训练模型,或是在开源模型的基础上做有限的微调,很难深入。LLaMA2 也是一样,最受关注的「数据处理」层面恰恰没有开源,因此参考意义有限。但在总共 28 页的 Baichuan 2 技术报告中,团队详细介绍了 Baichuan 2 训练的全过程,包括数据处理、模型结构优化、Scaling law、过程指标等关键细节。本着协作和持续改进的精神,百川智能还公布了 3000 亿到 2.6 万亿 Token 模型训练的 checkponits,供社区研究使用: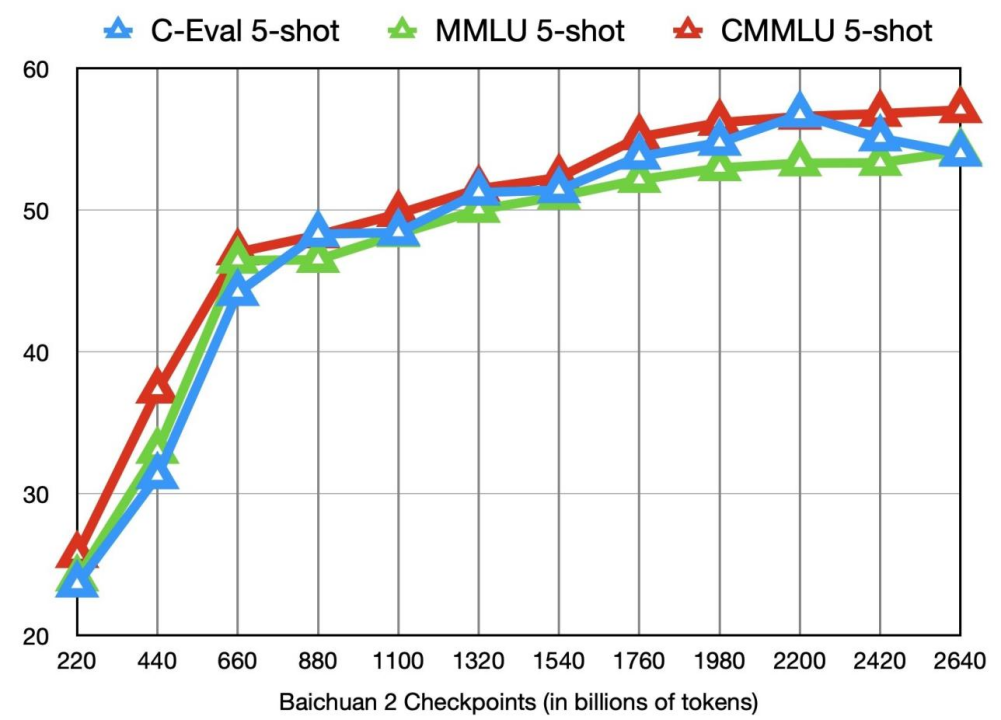
就当前的开源生态来说,这种公布训练模型过程的方式称得上「首次」。这些技术细节的开放,对于科研机构研究大模型训练过程、模型继续训练和模型的价值观对齐等极具价值,将极大推动国内大模型的科研进展。在这场由 ChatGPT 打响的大模型竞赛中,「开源」与「闭源」之争已经上演。正如今年 5 月的一篇「谷歌内部文章」所说,「谷歌、OpenAI 没有护城河」,由一两家科技公司构建和维护的技术高墙总会被打破,开源的力量将使得大模型技术真正易用和可用。而且这种竞争态势将长期存在:今后的大模型格局中,「开源」与「闭源」最终会并驾齐驱,如同手机操作系统领域的 iOS 和 Android。不断刷新的模型性能、率先实现「免费商用」、更加全面的社区生态,都是开源大模型能获得更多开发者支持的优势所在。纵观当前的开源大模型,达到 GPT3.5 的水平已经不再是难题,大家正在探索的重点已经变为如何实现 GPT-4 的水准。比如,前段时间 1800 亿参数的阿联酋大模型 Falcon 发布,迅速在 Hugging Face 开源大模型榜单上以 68.74 分超过 LLaMA 2 位列第一;传闻中,Meta 也在加快开发新的大语言模型,各项能力对标 GPT-4,预计明年就会推出。开源大模型的不断进步、相互促进,对整个行业的影响是积极的。未来,开发者和中小企业可以以低成本调用先进的大模型,而不必被高昂的研发、采购成本拒之门外。百川智能自成立之初,就将通过开源方式助力中国大模型生态繁荣作为公司的重要发展方向,并在激烈的竞争态势中确立了自己的目标:2023 年内还将发布千亿参数大模型,并在明年一季度推出 「超级应用」。
同行投来羡慕的眼光:「嫉妒Falcon和Baichuan背后的团队……不是因为资金或算力,就只因为团队本身……」
基于行业领先的基础大模型研发和创新能力,百川智能收获了行业的高度认可:最新开源的两款 Baichuan 2 大模型已经得到了上下游企业的积极响应,腾讯云、阿里云、火山方舟、华为、联发科等众多知名企业均与百川智能达成了合作。前段时间,首批大模型公众服务牌照正式落地。在今年创立的大模型公司中,百川智能也是唯一一家通过《生成式人工智能服务管理暂行办法》备案,可以正式面向公众提供服务的企业。而 Baichuan 系列大模型的开源,将汇聚社区中更多的创新力量,加速技术的迭代与应用的拓展。技术的进步只是第一阶段,未来,大模型还需要走到产业中去,与各行各业的业务实践相结合。如何让大模型的能力与业务场景更好结合,同样是当下每一家大模型提供商的重点课题,也需要科技公司、学术机构和开发者共同创造。© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]