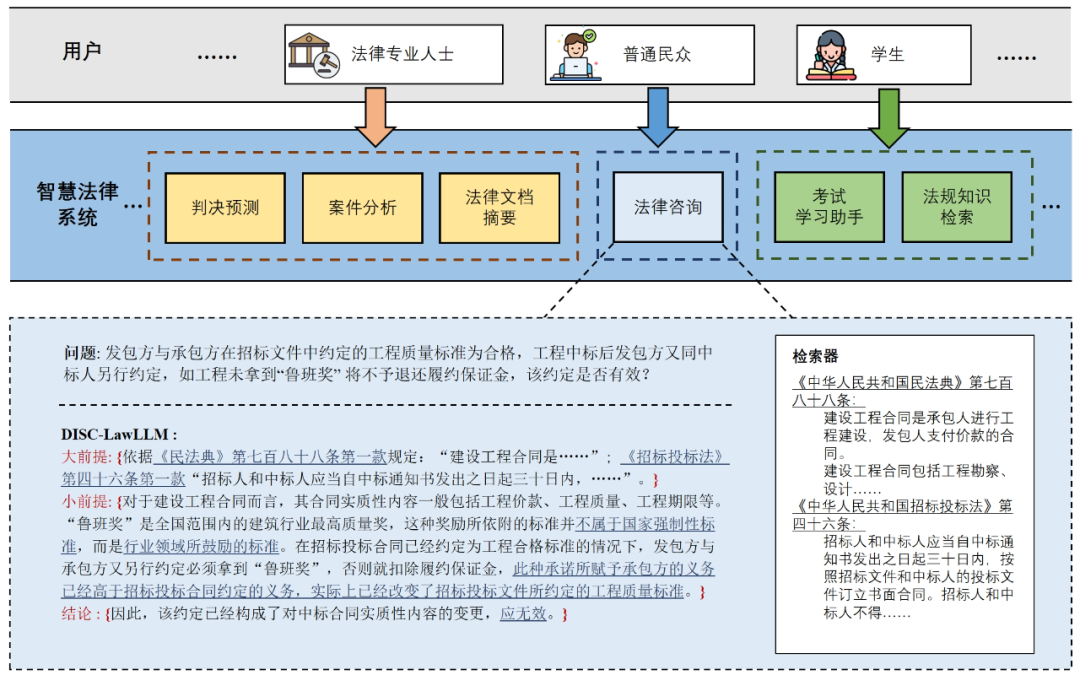
随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中文智慧法律系统 ——DISC-LawLLM。该系统可以面向不同用户群体,提供多样的法律服务。此外,实验室还构建了评测基准 DISC-Law-Eval,从客观和主观两个方面来评测法律大语言模型,模型在评测中的表现相较现有的法律大模型有明显优势。课题组同时公开包含 30 万高质量的监督微调(SFT)数据集 ——DISC-Law-SFT,模型参数和技术报告也一并开源。
- 主页地址:https://law.fudan-disc.com
- Github 地址:https://github.com/FudanDISC/DISC-LawLLM
- 技术报告:https://arxiv.org/abs/2309.11325
用户有法律方面的疑问时,可以向模型咨询,描述疑问,模型会给出相关的法律规定和解释、推荐的解决方案等。
专业法律者和司法机关,可以利用模型完成法律文本摘要、司法事件检测、实体和关系抽取等,减轻文书工作,提高工作效率。
法律专业的学生在准备司法考试过程中,可以向模型提出问题,帮助巩固法律知识,解答法律考试题。
在需要外部法条做支撑时,模型会根据问题在知识库中检索相关内容,给出回复。
DISC-LawLLM 是基于我们构建的高质量数据集 DISC-Law-SFT 在通用领域中文大模型 Baichuan-13B 上进行全参指令微调得到的法律大模型。值得注意的是,我们的训练数据和训练方法可以被适配到任何基座大模型之上。1. 基础的法律文本处理能力。针对法律文本理解与生成的不同基础能力,包括信息抽取、文本摘要等,我们基于现有的 NLP 司法任务公开数据和真实世界的法律相关文本进行了微调数据的构建。
2. 法律推理思维能力。针对智慧司法领域任务的需求,我们使用法律三段论这一法官的基本法律推理过程重构了指令数据,有效地提高了模型的法律推理能力。
3. 司法领域知识检索遵循能力。智慧司法领域的问题解决,往往需要依循与问题相关的背景法条或者案例,我们为智能法律处理系统配备了检索增强的模块,加强了系统对于背景知识的检索和遵循能力。
03 方法:数据集 DISC-Law-SFT 的构造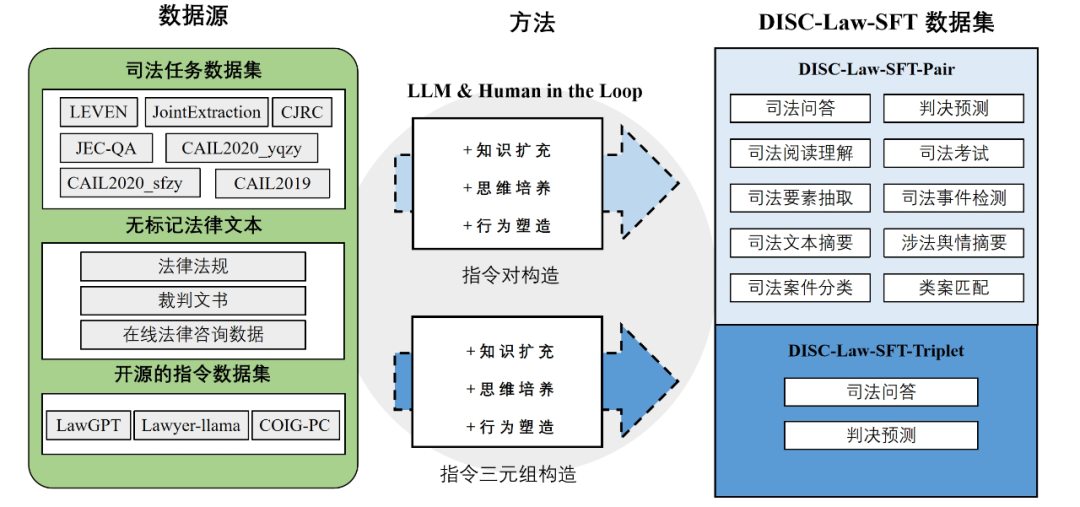
DISC-Law-SFT 分为两个子数据集,分别是 DISC-Law-SFT-Pair 和 DISC-Law-SFT-Triplet,前者向 LLM 中引入了法律推理能力,而后者则有助于提高模型利用外部知识的能力。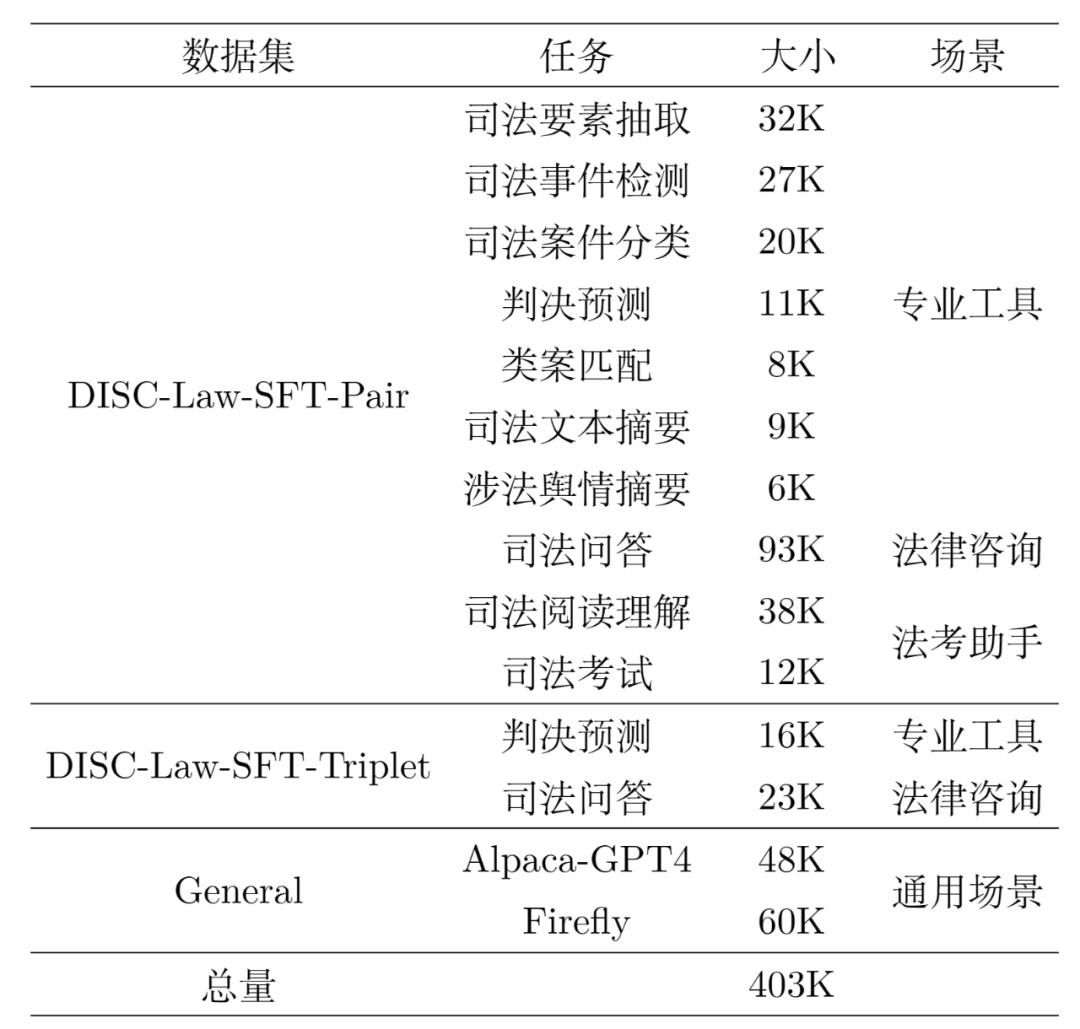
DISC-Law-SFT 数据集的数据来源于三部分,一是与中国法律相关的 NLP 司法任务公开数据集,包括法律信息抽取、实体与关系抽取、司法文本摘要、司法考试问答、司法阅读理解、罪名 / 刑期预测等;二是收集了来自真实世界的法律相关的原始文本,如法律法规、司法案件、裁判文书、司法相关的考试等;三是通用的开源数据集,我们使用了 alpaca_gpt4_data_zh 和 Firefly,这样可以丰富训练集的多样性,减轻模型在 SFT 训练阶段出现基础能力降级的风险。对上述一、二来源的数据转换为 “输入 - 输出” 指令对后,我们采用以下三种方式对指令数据重构,以提高数据质量。在法律三段论中,大前提为适用的法律规则,小前提为案件事实,结论为法律判断。这构成了法官的一个基本的法律推理过程。每一个案例都可以通过三段论得出一个明确的结论,如下所述:
我们利用 GPT-3.5-turbo 来完成行为塑造的重构,细化输出,确保每个结论都从一个法律条款和一个案例事实中得出。对于行为塑造不适用的多项选择题,我们直接使用法律知识扩展输出,以提供更多的推理细节。许多与法律相关的考试和知识竞赛只提供答案选项,我们使用 LLM 来扩展所涉及的法律知识,给出正确的答案,并重建指令对。思维链(CoT)已被证明能有效地提高模型的推理能力。为了进一步赋予模型法律推理能力,我们设计了具有特定法律意义的思维链,称为 LCoT,要求模型用法律三段论来推导答案。LCoT 将输入 X 转换为如下的提示:在法律三段论中,大前提是适用的法律规则,小前提是案件事实,结论是对案件的法律判断。
为了训练检索增强后的模型,我们构造了 DISC-Law-SFT-Triplet 子数据集,数据为 < 输入、输出、参考 > 形式的三元组,我们使用指令对构造中列出的三种策略对原始数据进行处理,获得输入和输出,并设计启发式规则来从原始数据中提取参考信息。DISC-LawLLM 的训练过程分为 SFT 和检索增强两个阶段。虽然我们使用了高质量的指令数据对 LLM 进行微调,但它可能会由于幻觉或过时的知识而产生不准确的反应。为了解决这个问题,我们设计了一个检索模块来增强 DISC-LawLLM。给定一个用户输入,检索器通过计算它们与输入的相似性,从知识库返回最相关的 Top-K 文档。这些候选文档,连同用户输入,用我们设计的模板构造后输入到 DISC-LawLLM 中。通过查询知识库,模型可以更好地理解主要前提,从而得到更准确可靠的答案。
我们构建了一个公平的智能法律系统评估基准 DISC-Law-Eval,从客观和主观的角度来评估,填补了目前还没有基准来对智能法律体系全面评估这一空白。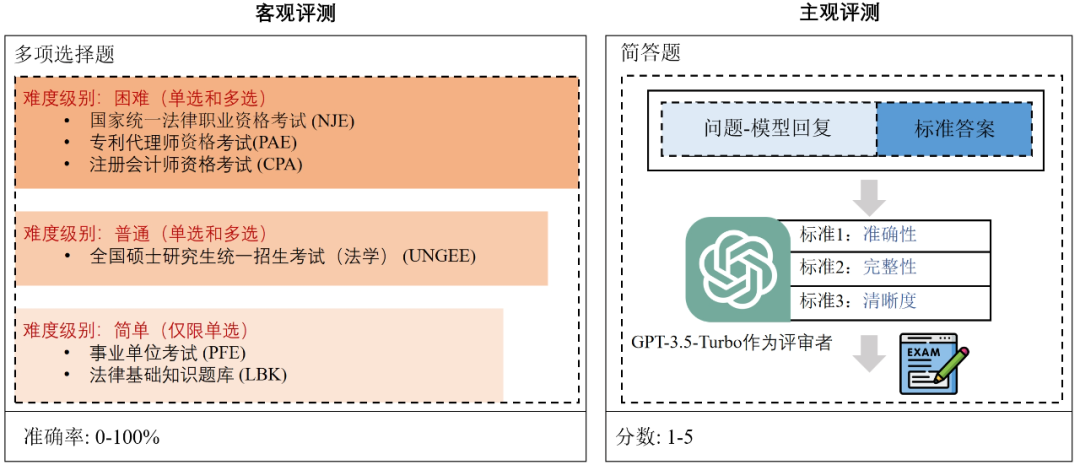
为了客观、定量地评估智能法律系统的法律知识和推理能力,我们设计了一个客观的评价数据集,由一系列中国法律标准化考试和知识竞赛的单项和多项选择题组成,并根据内容复杂性和演绎难度,将问题分为困难、正常和容易三个层次。它可以提供一个更具挑战性和可靠的方法来衡量模型是否可以利用其知识来推理正确的答案。我们通过计算精度来表明性能。主观评测部分,我们采用问答的范式进行评估,模拟主观考试问题的过程。我们从法律咨询、在线论坛、与司法相关的出版物和法律文件中手工构建了一个高质量的测试集。我们用 GPT- 3.5-turbo 作为裁判模型来评估模型的输出,并用准确性、完整性和清晰度这三个标准提供 1 到 5 的评分。将我们的模型 DISC-LawLLM (不外接知识库) 与 4 个通用 LLM 和 4 个中文法律 LLM 进行比较,包括 GPT-3.5-turbo、ChatGLM-6B 、Baichuan-13B-Chat 、Chinese-Alpaca2-13B ;LexiLaw 、LawGPT、Lawyer LLaMA、ChatLaw 。DISC-LawLLM 在所有不同难度水平的测试中超过所有比较的同等参数量的大模型。即使与具有 175B 参数的 GPT- 3.5-turbo 相比,DISC-LawLLM 在部分测试上也表现出了更优越的性能。表 2 是客观评测结果,其中加粗表示最佳结果,下划线表示次佳结果。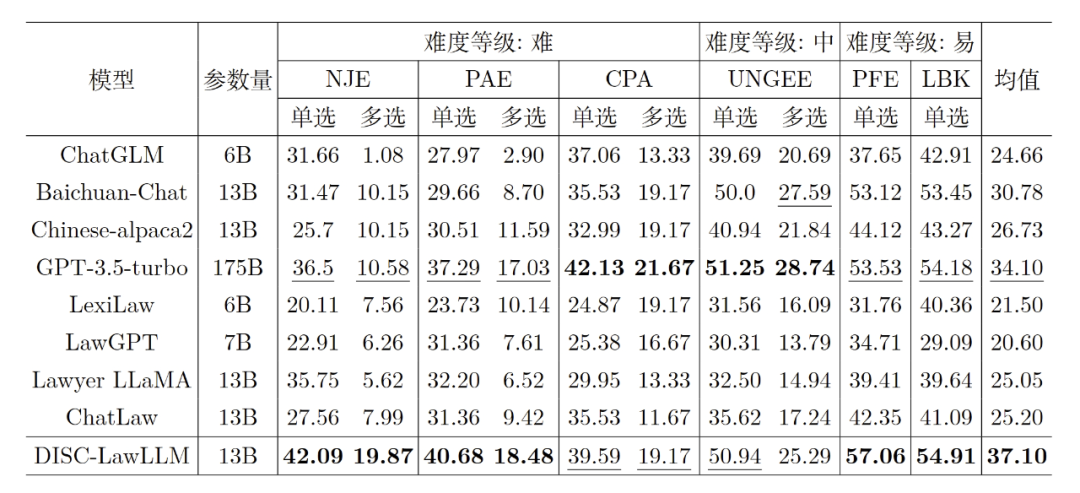
在客观评测中,DISC-LawLLM 获得了最高的综合得分,并在准确性和清晰度这两项标准中得分最高。表 3 是主观评测结果,其中加粗表示最佳结果。
我们发布了 DISC-LawLLM,一个提供多应用场景下法律服务的智能法律系统。基于公开的法律领域 NLP 任务数据集、法律原始文本和开源通用指令数据集,按照法律三段论重构了法律指令进行监督微调。为了提高输出的可靠性,我们加入了一个外部检索模块。通过提高法律推理和知识检索能力,DISC-LawLLM 在我们构建的法律基准评测集上优于现有的法律 LLM。该领域的研究将为实现法律资源平衡等带来更多前景和可能性,我们发布了所构建的数据集和模型权重,以促进进一步的研究。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]