

智源推最强开源中英双语大模型!340亿参数超越Llama 2-70B。智东西10月12日报道,今日,智源研究院宣布悟道·天鹰Aquila大语言模型系列全面升级到Aquila2,并再添340亿参数(34B)重量级新成员。Aquila2-34B取得了22个评测基准的领先综合排名,智源研究院称其是当前最强的开源中英双语大模型。一举刷新大模型榜单成绩之外,智源研究院更加注重对推理、泛化等重要模型实际能力的潜心提升,在支撑智能体(AI agent)、代码生成、文献检索等场景方面取得一系列成绩。值得一提的是,智源研究院一口气带来开源全家桶,将创新训练算法与实践同步开放,包括:1、全面升级Aquila2模型系列:Aquila2-34B/7B基础模型、AquilaChat2-34B/7B对话模型、AquilaSQL“文本-SQL语言”模型。2、语义向量模型BGE新版本升级,4大检索诉求全覆盖。3、FlagScale高效并行训练框架,训练吞吐量、GPU利用率业界领先。4、FlagAttention高性能Attention算子集,创新支撑长文本训练、Triton语言。https://github.com/FlagAI-Open/Aquila2https://model.baai.ac.cn/https://huggingface.co/BAAI
通过架构升级、算法创新、数据迭代,新一代悟道·天鹰模型Aquila2在中英文综合能力方面进一步突破:Aquila2-34B基座模型取得了22个评测基准的领先综合排名,包括语言、理解、推理、代码、考试等多个维度。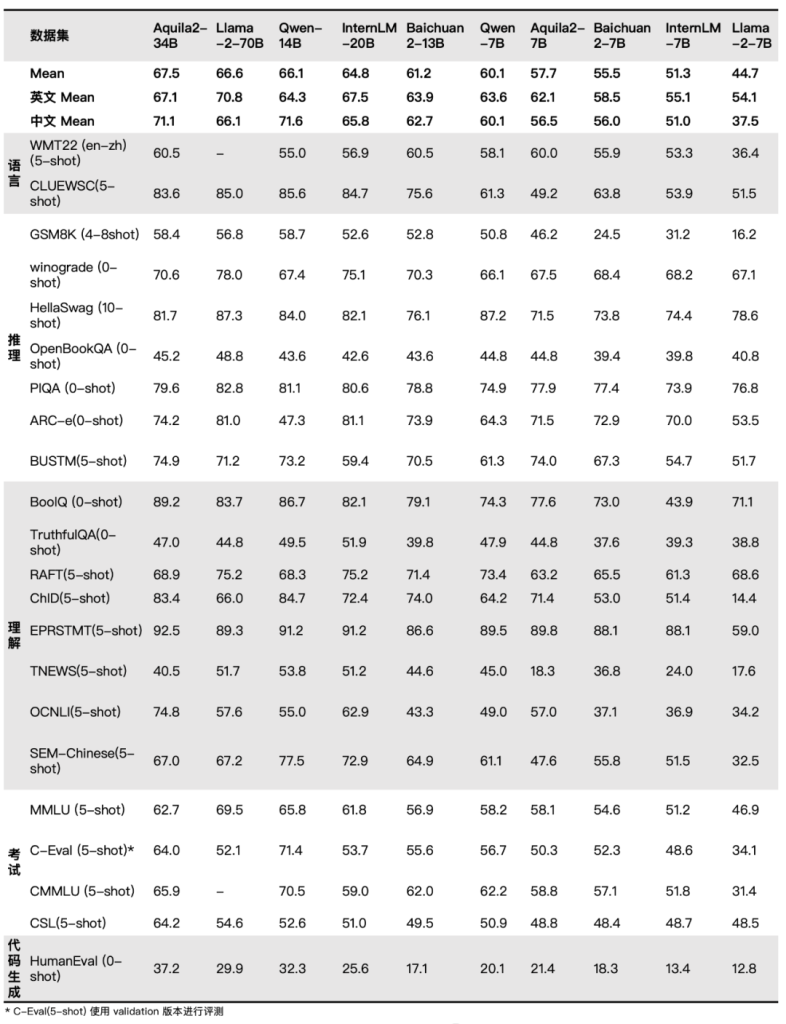
▲Base模型评测结果(详细数据集评测结果见官方开源仓库介绍)
同时,Aquila2基础模型以开源基座模型综合性能,为下游模型提供强大支撑,经指令微调得到了AquilaChat2对话模型系列。AquilaChat2-34B在主观+客观综合评测中全面领先,AquilaChat2-7B也取得同量级中英对话模型中综合性能最佳成绩。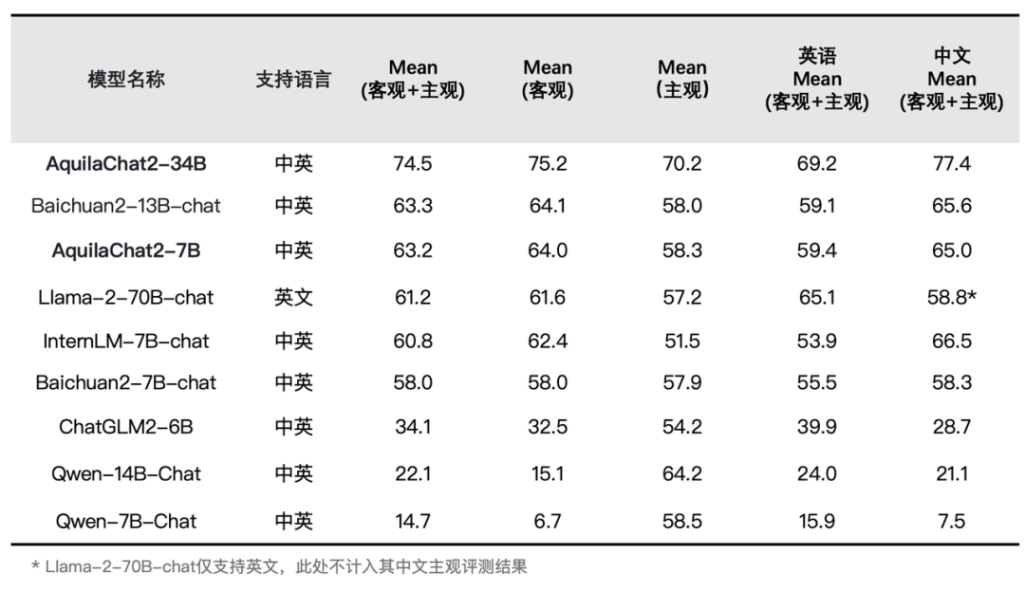
▲SFT模型评测结果(详细数据集评测结果见官方开源仓库介绍)
大模型的推理(Reasoning)能力是实现通用人工智能(AGI)的关键能力,AquilaChat2-34B在IRD评测基准中排名第一,超越Llama 2-70B、GPT-3.5等模型,仅次于GPT-4。智源团队整理了评测基准Integrated Reasoning Dataset(IRD)考察模型在归纳推理、演绎推理、溯因推理和因果推理维度上的推理结果和过程的准确性,并对主流对话模型进行了全面评测。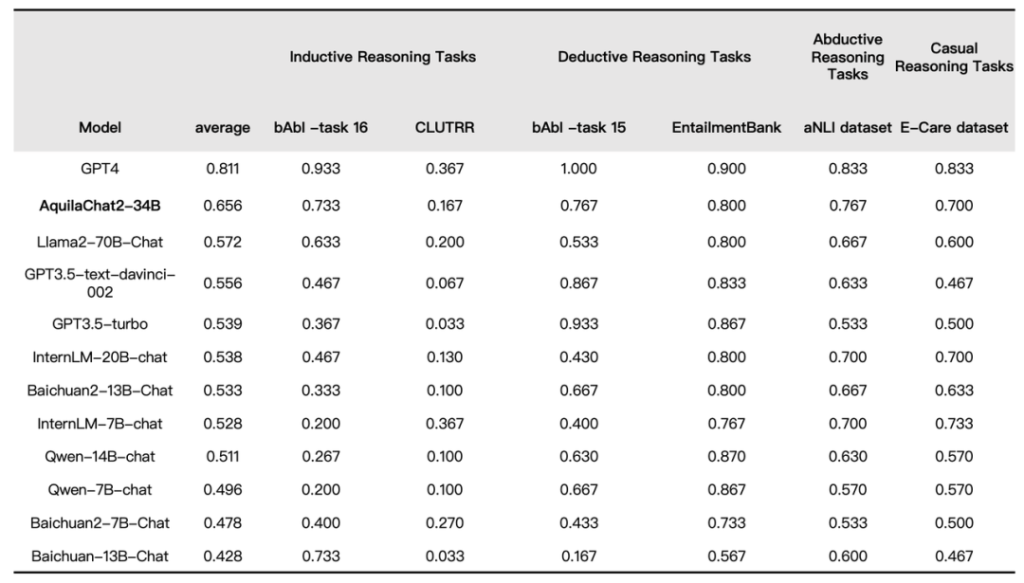
▲SFT模型在IRD数据集上的评测结果
AquilaChat2-34B-16K以Aquila2-34B为基座,经过位置编码内插法处理,并在20W条优质长文本对话数据集上做了SFT,将模型的有效上下文窗口长度扩展至16K。在LongBench的四项中英文长文本问答、长文本总结任务的评测效果显示,AquilaChat2-34B-16K处于开源长文本模型的领先水平,接近GPT-3.5长文本模型。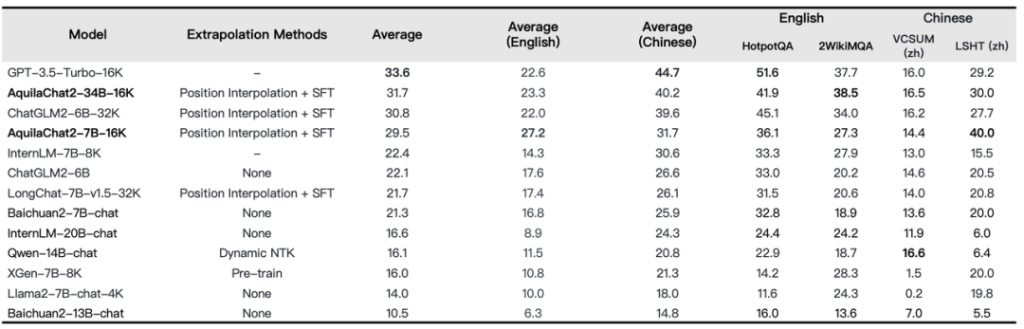
▲长文本理解任务评测
长度外延能力不足是制约大模型成文本能力的普遍问题。智源团队对多个语言模型处理超长文本的注意力分布做了可视化分析,发现所有的语言模型均存在固定的相对位置瓶颈,显著小于上下文窗口长度。为此,智源团队创新提出NLPE(Non-Linearized Position Embedding,非线性位置编码)方法,在RoPE方法的基础上,通过调整相对位置编码、约束最大相对长度来提升模型外延能力。在代码、中英文Few-Shot Leaning、电子书等多个领域上的文本续写实验显示,NLPE可以将4K的Aquila2-34B模型外延到32K长度,且续写文本的连贯性远好于Dynamic-NTK、位置插值等方法。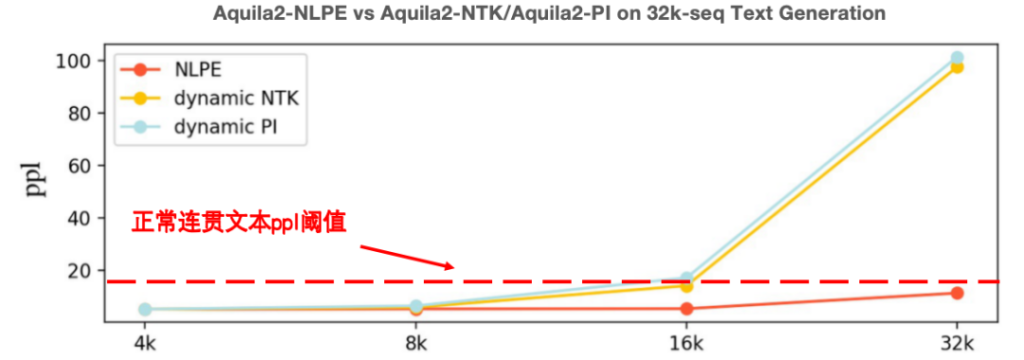
图:NLPE与主流Dynamic-NTK外延方法在Base模型上的能力对比(ppl值越低越好)此外,在长度为5K~15K的HotpotQA、2WikiMultihopQA等数据集上的指令跟随能力测试显示,经过NLPE外延的AquilaChat2-7B(2K)准确率为17.2%,而Dynamic-NTK外延的AquilaChat2-7B准确率仅为0.4%。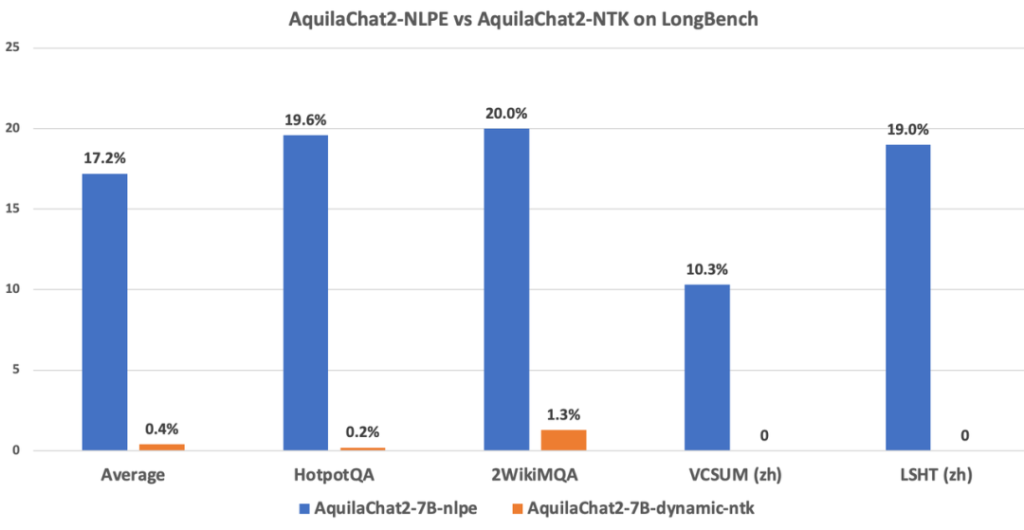
▲NLPE与主流Dynamic-NTK外延方法在SFT模型上的能力对比
同时,智源团队开发了适配长文本推理的分段式Attention算子PiecewiseAttention,高效地支持NLPE等面向Attention Map的优化算法,进一步减少显存占用、提升运算速度。
强大的泛化能力对于大语言模型至关重要,它意味着模型能够有效地应对未见过的数据与新任务,而不仅仅仅在标准测试中表现出色、但在实际应用中表现不佳,陷入“高分低能”的陷阱。悟道·天鹰团队通过三个真实应用场景验证了Aquila2模型的泛化能力。1、利用AquilaChat2推理能力打造智能体(AI agent)在开放式的环境中学习多种任务是通用智能体的重要能力。《我的世界》(Minecraft)作为一款受欢迎的开放世界游戏,具有无限生成的复杂世界和大量开放的任务,为智能体提供了丰富的交互接口,进而成为近几年开放式学习研究的重要测试环境。智源研究院与北京大学团队提出了在无专家数据的情况下高效解决Minecraft多任务的方法——Plan4MC。Plan4MC可以使用内在奖励的强化学习训练智能体的基本技能,使得智能体可以利用大语言模型AquilaChat2的推理能力进行任务规划。以下视频展示了智能体利用AquilaChat2进行自动完成多轮对话交互,将游戏“当前环境状态”、“需要完成的任务”等信息输入AquilaChat2模型,AquilaChat2反馈给角色“下一步使用什么技能”等决策信息,最终完成了Minecraft游戏中设定的任务“伐木并制作工作台放在附近”的任务。基于传统向量库的检索方式在一些简单问题场景下表现良好,但面对复杂的、需要深度理解的问题时,其效果有限。Aqiula2+BGE2的引入改变了这一局面(BGE是智源团队开源的语义向量模型),彻底解锁了一些仅基于传统向量库的检索方法不能解决的复杂检索任务,例如检索某个作者关于某个主题的论文,或针对一个主题的多篇论文的生成总结文本。▲Aquila2+BGE 文献检索场景复杂查询示例 “Give me some papers about summarization written by Mirella Lapata”
3、AquilaSQL:“文本-SQL语言”生成模型AquilaSQL可以充当“翻译员”,将用户发出的自然语言指令准确翻译为合格的SQL查询语句,极大地降低数据查询分析的门槛。在实际应用场景中,用户还可以基于AquilaSQL进行二次开发,将其嫁接至本地知识库、生成本地查询SQL,或进一步提升模型的数据分析性能,让模型不仅返回查询结果,更能进一步生成分析结论、图表等。基于Aquila基座模型优秀的代码生成能力,AquilaSQL经过SQL语料的继续预训练和SFT两阶段训练,最终以67.3%准确率超过“文本-SQL语言生成模型”排行榜Cspider上的SOTA模型,而未经过SQL语料微调的GPT-4模型准确率仅为30.8%。https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila/Aquila-sql下面是一个复杂查询任务示例:“从包含汽车销量(car_sales)、汽车颜色(car_color)的两个数据表中筛选销量大于100并且颜色为红色的汽车”。
▲AquilaSQL生成多表查询语句
持续全家桶级开源,Aquila2系列创新训练算法同步开放
作为中国大模型开源生态的代表机构,智源早在2022年即开始打造FlagOpen飞智大模型技术开源体系。不止于明星模型,智源持续贡献大模型全栈技术开源开放,带来一系列包括算法、数据、工具、评测方面的明星开源项目。秉承开源传统,智源不仅带来了强大的Aquila2系列模型,全面采用商用许可协议,允许公众广泛应用于学术研究和商业应用;还将相关创新训练算法、实践全面彻底开放。FlagScale是Aquila2-34B使用的高效并行训练框架。提供一站式语言大模型的训练功能。智源团队将Aquila2模型的训练配置、优化方案和超参数通过FlagScale项目分享给大模型开发者,在国内首次完整开源训练代码和超参数。FlagScale基于Megatron-LM扩展而来,提供了一系列功能增强,包括分布式优化器状态重切分、精确定位训练问题数据以及参数到Huggingface转换等。经过实测,Aquila2训练吞吐量和GPU利用率均达到业界领先水平[1][2]。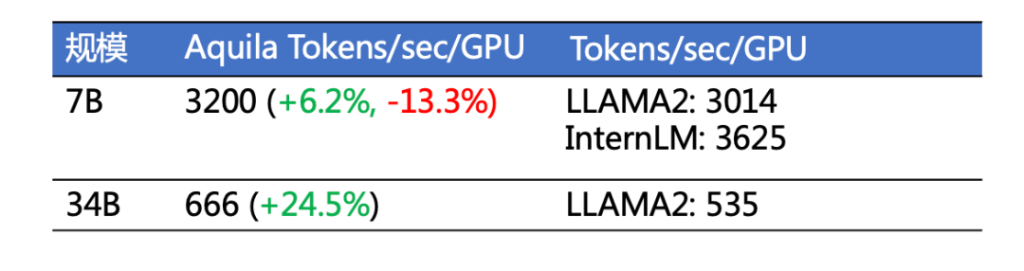
▲FlagScale训练吞吐量与GPU利用率(数据来源和计算公式见文末)
https://github.com/FlagOpen/FlagScale此外,FlagScale采用了多种并行技术如数据并行、张量并行和1F1B流水线并行等,加速训练过程,并使用BF16进行混合精度进行训练。在性能优化方面,FlagScale采用了FlashAttnV2、计算与通信重叠、梯度累积等技术,显著提升了计算效率。未来,FlagScale将继续保持与上游项目Megatron-LM最新代码同步,引入更多定制功能,融合最新的分布式训练与推理技术以及主流大模型、支持异构AI硬件,力图构建一个通用、便捷、高效的分布式大模型训练推理框架,满足不同规模和需求的模型训练任务。2、FlagAttention高性能Attention开源算子集FlagAttention是首个支持长文本大模型训练、使用Triton语言开发的高性能Attention开源算子集,针对大模型训练的需求,对Flash Attention系列的Memory Efficient Attention算子进行扩展。目前已实现分段式Attention算子——PiecewiseAttention。https://github.com/FlagOpen/FlagAttentionPiecewiseAttention主要解决了带旋转位置编码Transformer模型(Roformer)的外推问题。大模型推理时的序列长度超出训练时最大序列长度时,距离较远的token之间attention weight异常增高。而Flash Attention对Attention Score的计算采用分段式的处理时无法做到高效实现,因此智源团队自研了分段式PiecewiseAttention算子,大模型开发者可利用该开源算子实现更加灵活的Attention计算方式。PiecewiseAttention主要解决了带旋转位置编码Transformer模型(Roformer)的外推问题。大模型推理时的序列长度超出训练时最大序列长度时,距离较远的token之间attention weight异常增高。而Flash Attention对Attention Score的计算采用分段式的处理时无法做到高效实现,因此智源团队自研了分段式PiecewiseAttention算子,大模型开发者可利用该开源算子实现更灵活的。简单来说,PiecewiseAttention具备如下特性:
(注:Triton是OpenAI开源的编程语言,方便开发者编写高效的GPU代码。)
基于Triton开发的FlagAttention具备更好的开源开放能力,轻松适配各种AI硬件,目前已在英伟达及天数智芯硬件上完成支持[3]。未来,FlagAttention项目将继续针对大模型研究需求,支持其他功能扩展的Attention算子,进一步优化算子性能,并适配更多异构AI硬件。新一代BGE语义向量模型将随Aquila2同步开源。BGE2中的BGE-LLM Embedder模型集成了“知识检索”、“记忆检索”、“示例检索”、“工具检索”四大能力,首次实现了单一语义向量模型对大语言模型主要检索诉求的全面覆盖。结合具体的使用场景,BGE-LLM Embedder将显著提升大语言模型在处理知识密集型任务、长期记忆、指令跟随、工具使用等重要领域的表现。https://arxiv.org/pdf/2310.07554.pdfhttps://huggingface.co/BAAI/llm-embedderrepo:https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder[1]Llama 2吞吐量估算公式:total tokens/(total GPU hours * 3600),根据Llama 2:Open Foundation and Fine-Tuned Chat Models论文:1)7B的total tokens为2.0T,total GPU hours为184320,代入公式得3014Tokens/sec/GPU;2)34B的total tokens为2.0T,total GPU hours为1038336,代入公式得535Tokens/sec/GPU。https://github.com/InternLM/InternLM#training-performance可知InternLM 7B的1024卡能达到3625Tokens/sec/GPU。[3]当前仅在英伟达RTX3090和A100以及天数的MR-V100上进行验证。
