---- 本周为您解读 ③ 个值得细品的 AI & Robotics 业内要事 ----
英伟达的 Agent 奖励设计方案了解一下?大家以前聊的 Agent 是啥意思?现在大家都是怎么理解 Agent 的?ICLR'24 的 Agent 论文了解一下?...IDC 都分析了 Salesforce 的哪些情况?Salesforce 做了什么让大跌的市值起死回生?「SaaS+AI」的业务模式可行吗?AIGC 赛道目前的市场情况如何?AIGC 玩家怎么赚钱?...LeCun 最近又说了啥?LeCun 转的两篇论文了解一下?GPT-4 在着色问题上表现如何?GPT-4 在规划任务中的表现如何?LLM 的自我批判能力到底好用吗?......本期完整版通讯含 3 项专题解读 + 31 项本周 AI & Robotics 赛道要事速递,其中技术方面 11 项,国内方面 7 项,国外方面 13 项...
本期通讯总计 22845 字,可免费试读至 11 % 消耗 99 微信豆即可兑换完整本期解读(约合人民币 9.9 元) 要事解读 ① LLM 浪潮下的 AI Agent 众生相
事件:英伟达、宾大和加州理工等机构的研究者近期提出了奖励设计算法 EUREKA,可通过用 GPT-4 来完善奖励函数,用强化学习来训练机器人控制器,让机器人学会如转笔、玩魔方等复杂的技能。1、EUREKA 全称为 Evolution-driven Universal REward Kit for Agent,其特点在于不需要特定任务提示、奖励模板或少量示例。2、EUREKA 由三个算法组件组成,包含:将环境作为上下文、进化搜索和奖励反思(reward reflection)。① 将环境作为上下文,EUREKA 可以从主干编码 LLM(GPT-4)中零样本生成可执行的奖励函数;② 进化搜索,迭代地提出奖励候选批次,并在 LLM 上下文窗口中精炼最有希望的奖励,从而大幅提高了奖励的质量;③ 奖励反思,基于策略训练统计数据的奖励质量文本总结,可实现自动和有针对性的奖励编辑,支持细粒度的奖励改进。3、该工作还提出了一项 in-context RLHF 方法,它能够将人类操作员的自然语言反馈纳入其中,以引导和对齐奖励函数。① 在 29 种不同的开源 RL 环境中,EUREKA 的奖励设计性能达到了人类水平,这些环境包括 10 种不同的机器人形态(四足机器人、四旋翼机器人、双足机器人、机械手以及几种灵巧手);② 在没有任何特定任务提示或奖励模板的情况下,EUREKA 自主生成的奖励在 83% 的任务中优于人类专家的奖励,并实现了 52% 的平均归一化改进;③ 解决了以前无法通过人工奖励工程实现的灵巧操作任务。以转笔问题为例,通过将 EUREKA 与课程学习相结合,研究者在模拟人「Shadow Hand」上演示了快速转笔的操作。5、该工作已完全开源,开源内容包含所有提示、环境和生成的奖励函数等。当我们谈论 Agent 时,常用的定义是一个可以观察其环境、做出决策并执行动作的实体。其目标通常是优化某个性能指标或满足某个任务。根据目标或任务不同,Agent 通常被分为 6 类。[1]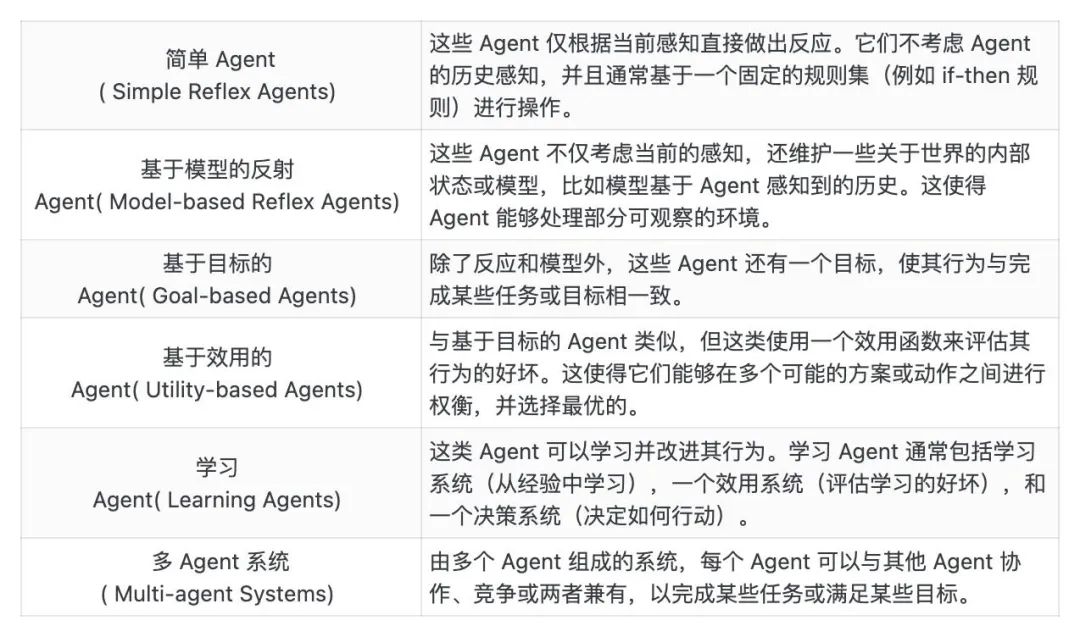
LLM 火了之后大家又是怎么理解 Agent 的?[2] [3] [4]
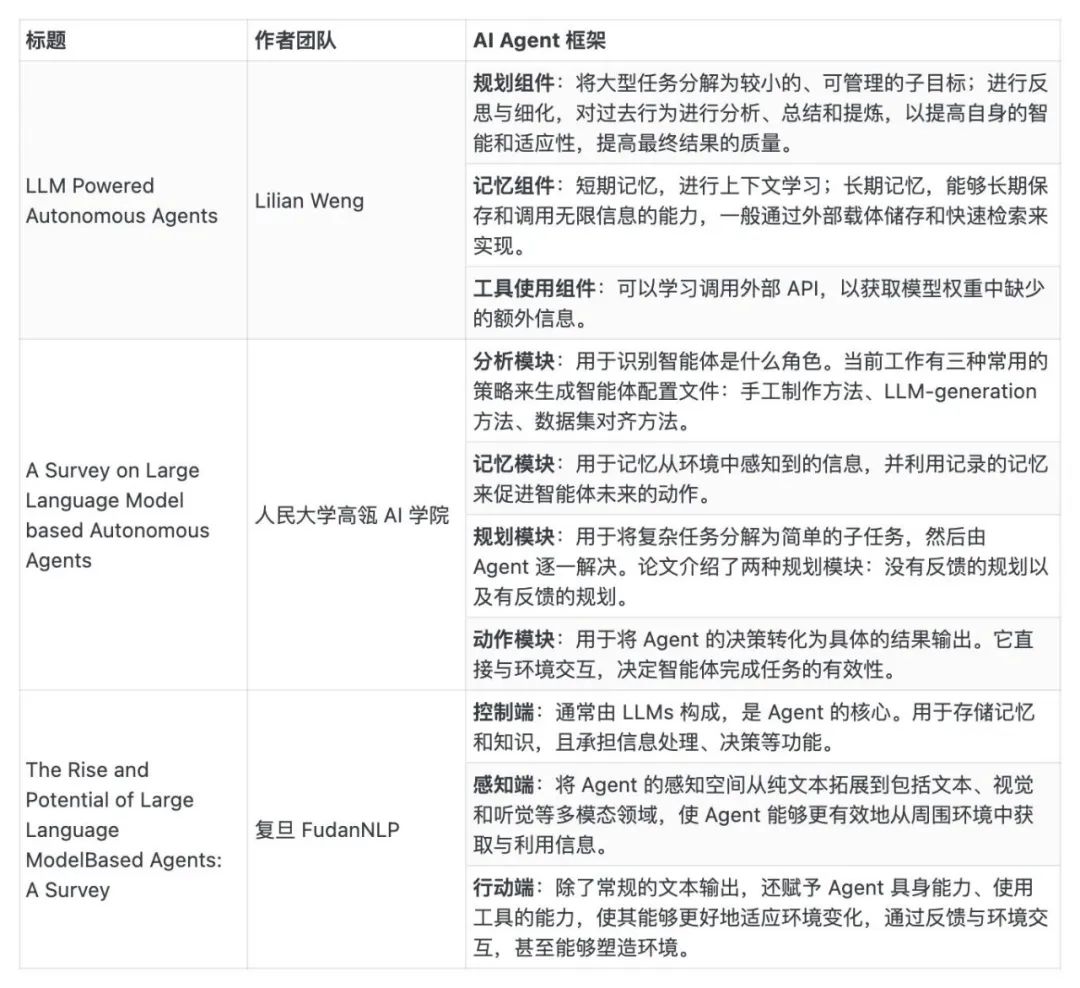
2023 年 6 月,OpenAI 的 Safety 团队负责人 Lilian Weng 发布了一篇 6000 字的博客介绍 AI Agent,并认为这将使 LLM 转为通用问题解决方案的途径之一。8 月,高瓴人工智能学院发布综述论文,探讨了基于 LLM 的自主智能体在构建、应用和评估三个方面的发展现状。9 月,FudanNLP 团队发布综述论文,梳理了基于大型语言模型的智能体技术发展现状,并探讨了智能体社会的发展机会。1、在 OpenAI Safety 团队负责人 Lilian Weng 的博客中,AI Agent 是一种智能体系统,以 LLM 作为核心控制器,其目标不仅是生成高质量的文本、故事、散文和程序,它还可以被构建成一个强大的通用问题解决器。2、Lilian Weng 表示 AI Agent 主要由规划(Planning)、记忆(Memory)、工具使用(Tool Use)三个核心组件构成,其核心概念是使用 LLM 解决问题,让 LLM 学会使用工具,可以大扩展其能力。① 规划组件:将大型任务分解为较小的、可管理的子目标;进行反思与细化,对过去行为进行分析、总结和提炼,以提高自身的智能和适应性,提高最终结果的质量。② 记忆组件:短期记忆,进行上下文学习;长期记忆,能够长期保存和调用无限信息的能力,一般通过外部载体储存和快速检索来实现。③ 工具使用组件:可以学习调用外部 API,以获取模型权重中缺少的额外信息。3、人大高瓴 AI 学院团队在 8 月发布综述论文《A Survey on Large Language Model based Autonomous Agents》,研究者基于以往研究总结了一项 Agent 设计架构,由分析模块、记忆模块、规划模块和动作模块组成。① 分析模块:用于识别智能体是什么角色。在现有的工作中,有三种常用的策略来生成智能体配置文件:手工制作方法、LLM-generation 方法、数据集对齐方法。② 记忆模块:用于记忆从环境中感知到的信息,并利用记录的记忆来促进智能体未来的动作。③ 规划模块:用于将复杂任务分解为简单的子任务,然后由智能体逐一解决。论文介绍了两种规划模块:没有反馈的规划以及有反馈的规划。④ 动作模块:用于将智能体的决策转化为具体的结果输出。它直接与环境交互,决定智能体完成任务的有效性。4、复旦 FudanNLP 团队在 9 月发布综述论文《The Rise and Potential of Large Language ModelBased Agents: A Survey》,研究者所总结的 Agent 框架则是由控制端、感知端和行动端三部分组成。① 控制端(Brain):通常由 LLMs 构成,是智能代理的核心。它不仅可以存储记忆和知识,还承担着信息处理、决策等不可或缺的功能。它可以呈现推理和计划的过程,并很好地应对未知任务,反映出智能代理的泛化性和迁移性。② 感知端(Perception):将智能代理的感知空间从纯文本拓展到包括文本、视觉和听觉等多模态领域,使代理能够更有效地从周围环境中获取与利用信息。③ 行动端(Action):除了常规的文本输出,还赋予代理具身能力、使用工具的能力,使其能够更好地适应环境变化,通过反馈与环境交互,甚至能够塑造环境。表: Lilian Weng(OpenAI)、高瓴AI学院和复旦FudanNLP分别对LLM-based Agent的架构描述[2] [3] [4]