
©作者 | LRS 好困
来源 | 新智元
C-MCR利用现有多模态对比表征间可能存在的重叠模态,来连接不同的对比表征,从而学到更多模态间的对齐关系,实现了在缺乏配对数据的多模态间进行训练。
多模态对比表示(multi-modal contrastive representation, MCR)的目标是将不同模态的输入编码到一个语义对齐的共享空间中。
随着视觉-语言领域中CLIP模型的巨大成功,更多模态上的对比表征开始涌现出来,并在诸多下游任务上得到了明显的提升,但是这些方法严重依赖于大规模高质量的配对数据。
为了解决这个问题,来自浙江大学等机构的研究人员提出了连接多模态对比表示(C-MCR),一种无需配对数据且训练极为高效的多模态对比表征学习方法。

论文题目:
Connecting Multi-modal Contrastive Representations
https://arxiv.org/abs/2305.14381
https://c-mcr.github.io/C-MCR/
https://github.com/MCR-PEFT/C-MCR
该方法在不使用任何配对数据的情况下,通过枢纽模态连接不同的预训练对比表征,我们学习到了强大的音频-视觉和3D点云-文本表征,并在音频-视觉检索、声源定位、3D物体分类等多个任务上取得了SOTA效果。
介绍
多模态对比表示(MCR)旨在将不同模态的数据映射到统一的语义空间中。随着CLIP在视觉-语言领域的巨大成功,学习更多模态组合之间的对比表示已成为一个热门研究课题,吸引了越来越多的关注。然而,现有多模态对比表示的泛化能力主要受益于大量高质量数据对。这严重限制了对比表征在缺乏大规模高质量数据的模态上的发展。例如,音频和视觉数据对之间的语义相关性往往是模糊的,3D点云和文本之间的配对数据稀缺且难以获得。不过,我们观察到,这些缺乏配对数据的模态组合,往往和同一个中间模态具有大量高质量配对数据。比如,在音频-视觉领域,尽管视听数据质量不可靠,但音频-文本和文本-视觉之间存在大量高质量的配对数据。同样,虽然3D点云-文本配对数据的可用性有限,但3D点云-图像和图像-文本数据却非常丰富。这些枢纽模态可以为模式之间建立进一步关联的纽带。考虑到具有大量配对数据的模态间往往已经拥有预训练的对比表示,本文直接尝试通过枢纽模态来将不同模态间的对比表征连接起来,从而为缺乏配对数据的模态组合构建新的对比表征空间。连接多模态对比表示(C-MCR)可以通过重叠模态为现有大量多模态对比表示构建连接,从而学习更广泛的模态之间的对齐关系。其中,学习过程不需要任何配对数据且极为高效。C-MCR能够为缺乏直接配对配对的模态学习对比表征。从另一个视角来看,C-MCR将每个已有的多模态对比表示空间视为一个节点,并将不同表示空间的重叠模态视为枢纽模态。通过连接各个孤立的多模态对比表征,我们可以灵活地扩展了获得的多模态对齐知识,并挖掘出更广泛模态间的对比表示。由于C-MCR仅需为已有的表征空间构建连接,因此只用学习两个简单的映射器,其训练参数和训练成本都是极低的。实验利用文本作为枢纽连接视觉-文本(CLIP)和文本-音频(CLAP)对比表示空间,获得了高质量的视觉-音频表示。 类似地,通过使用图像连接文本-视觉(CLIP)和视觉-3D点云(ULIP)对比表示空间,也可以获得一组3D点云-文本对比表示。
方法
图1 (a) 介绍了C-MCR的算法流程(以使用文本连接CLIP和CLAP为例)。
文本(重叠模态)的数据分别被CLIP和CLAP的文本编码器编码为文本特征:、。同时,大量非配对单模态数据也分别被编码到CLIP和CLAP空间,构成image memory 和 audio memory我们首先提出从语义一致性和语义完整性两个角度来增强表征中的语义信息,从而实现更鲁棒更全面的空间连接。CLIP和CLAP分别已经学到了可靠的对齐的图像-文本和文本-音频表征。我们利用CLIP和CLAP中这种内在的模态对齐性来生成与第i个文本语义一致的图像和音频特征,从而更好地量化对比表征空间中的modality gap以及更直接的挖掘非重叠模态间的关联性:
不同表征空间对于数据的语义表达会有不同的倾向性,因此不同空间下的同一个文本也会不可避免的存在语义偏差和丢失。在连接表示空间时,这种语义偏差会被累积并且放大。为了增强每个表征的语义完整性,我们提出将零均值高斯噪声添加到表征中,并将它们重新归一化为单位超球面上:

如图1 (c) 中所示,在对比表征空间中,每个表征可以看代表是在单位超球面上的一个点。添加高斯噪声并重新归一化则使表征能够代表了单位球面上的一个圆。因为两个特征的空间距离越接近,其语义相似度也越高。所以圆内的特征都具有相似语义,圆所能表示的语义更加完整。完成表征语义增强后,我们学习两个映射器 和 来分别将CLIP和CLAP表征重新映射到一个新的共享空间: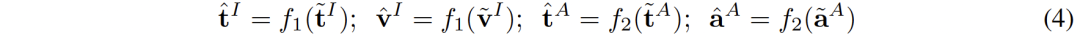
新空间需要确保来自不同空间的语义相似的表征彼此接近。来源于同一文本的 (,) 是天然语义一致的,可以被看做真实标签对,而源自于 (,) 的 (,) 可以被视为伪标签对。 (,) 之间的语义高度一致,但从它们中学习到的连接对于音频-视觉来说是间接的。 而(,)对的语义一致性虽然不太可靠,但其更直接地有利于音频-视觉表征。为了更全面地连接两个对比表征空间,我们同时对齐 (,) 和 (,):
除了空间之间的连接,对比表征空间内部还存在着modality gap的现象。即在对比表征空间中,不同模态的表征虽然语义对齐,但它们分布在完全不同的子空间中。这意味着从 (,) 学习到的更稳定的连接可能不能很好的被音频-视觉继承。为了解决这个问题,我们提出重新对齐各个对比表征空间的不同模态表征。具体来说,我们去除对比损失函数中的负例排斥结构,来推导出用于减小modality gap的损失函数。典型的对比损失函数可以表述为:
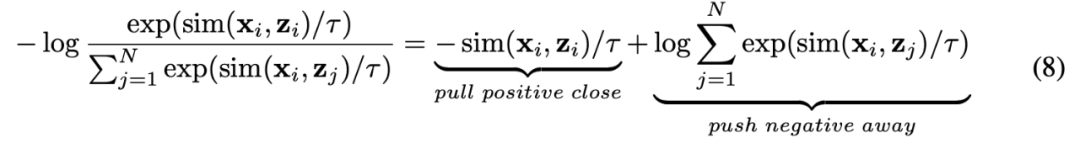

实验
实验上,我们通过使用文本连接音频-文本空间(CLAP)和文本-视觉空间(CLIP)来获得音频-视觉表征,使用图像连接3D点云-图像空间(ULIP)和图像-文本空间(CLIP)来获得3D点云-文本表征。
在AVE和Flickr-SoundNet上的zero-shot 音频图像检索结果如下:
在MUSIC-Solo和VGGSS上的zero-shot 声源定位结果如下:
在Ex-VGGSS和Ex-FlickrNet上的zero-shot反事实音频图像识别结果如下:在ModelNet40上的zero-shot 3D点云分类结果如下:
ttps://c-mcr.github.io/C-MCR/
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
