我们知道,ChatGPT 的成功离不开 RLHF 这个「秘密武器」。不过 RLHF 并不是完美无缺的,存在难以处理的优化难题。本文中,斯坦福大学等研究机构的团队探索用「对比偏好学习」替换掉「强化学习」,在速度和性能上都有不俗的表现。
在模型与人类意图对齐方面,根据人类反馈的强化学习(RLHF)已经成为一大流行范式。通常来说,RLHF 算法的工作过程分为两个阶段:一、使用人类偏好学习一个奖励函数;二、通过使用强化学习优化所学习的奖励来对齐模型。RLHF 范式假定人类偏好的分布遵照奖励,但近期有研究认为情况并非如此,人类偏好其实遵循用户最优策略下的后悔值(regret)。因此,根据反馈学习奖励函数不仅基于一个有漏洞的对于人类偏好的假设,而且还会导致出现难以处理的优化难题 —— 这些难题来自强化学习阶段的策略梯度或 bootstrapping。由于存在这些优化难题,当今的 RLHF 方法都会将自身限定在基于上下文的 bandit 设置中(比如在大型语言模型中)或会限制自己的观察维度(比如基于状态的机器人技术)。为了克服这些难题,斯坦福等多所大学的一个研究团队提出了一系列新算法,可使用基于后悔的人类偏好模型来优化采用人类反馈时的行为,而没有采用社区广泛接受的仅考虑奖励总和的部分回报模型。不同于部分回报模型,基于后悔的模型可直接提供有关最优策略的信息。这样一种机制带来了一个幸运的结果:完全不需要强化学习了!这样一来,就能在具有高维状态和动作空间的通用型 MDP 框架中来解决 RLHF 问题了。研究者提出,他们这项研究成果的核心见解是:将基于后悔的偏好框架与最大熵(MaxEnt)原理结合起来,可得到优势函数与策略之间的双射。通过将对优势的优化换成对策略的优化,可以推导出一个纯监督学习的目标,其最优值为专家奖励下的最优策略。该团队将这种方法命名为对比偏好学习(Contrastive Preference Learning/CPL),因为其类似于人们广为接受的对比学习目标。
一、CPL 能像监督学习一样扩展,因为它只使用监督式目标来匹配最优优势,而无需使用任何策略梯度或动态规划。
二、CPL 是完全离策略的方法,因此其可有效使用任何离线的次优数据源。
三、CPL 可应用于任意马尔可夫决策过程(MDP),使其可以从序列数据上的偏好查询中学习。
该团队表示,之前的 RLHF 方法都无法同时满足以上三点。为了表明 CPL 方法符合以上三点描述,研究者进行了实验,结果表明该方法确实能有效应对带有次优和高维离策略数据的序列决策问题。值得注意的是,他们在实验中发现:在 MetaWorld 基准上,CPL 竟能有效地使用与对话模型一样的 RLHF 微调流程来学习在时间上扩展的操作策略。具体来说,他们使用监督学习方法,在高维图像观察上对策略进行预训练,然后使用偏好来对其进行微调。无需动态规划或策略梯度,CPL 就能达到与基于先验式强化学习的方法一样的性能表现。与此同时,CPL 方法要快 1.6 倍,参数效率也提高了四倍。当使用更密集的偏好数据时,CPL 的性能表现在 6 项任务的 5 项上超越了强化学习。这种方法的核心思想很简单:研究者发现,当使用最大熵强化学习框架时,后悔偏好模型中使用的优势函数可被轻松替换成策略的对数概率。但是,这种简单的替换能带来巨大的好处。如果使用策略的对数概率,就不需要学习优势函数或应付与类强化学习算法相关的优化难题了。研究者表示,这不仅能造就对齐更紧密的后悔偏好模型,还能完全依靠监督学习来学习人类反馈。下面首先将推导 CPL 目标,并表明对于带有无界数据的专家用户奖励函数 r_E,该方法可以收敛到最优策略。然后将说明 CPL 与其它监督学习方法的联系。最后,研究者将说明如何在实践中使用 CPL。他们表示,这些算法属于一个用于解决序列决策问题的新方法类别,这类方法非常高效,因为它能直接从基于后悔的偏好中学习出策略,而无需强化学习。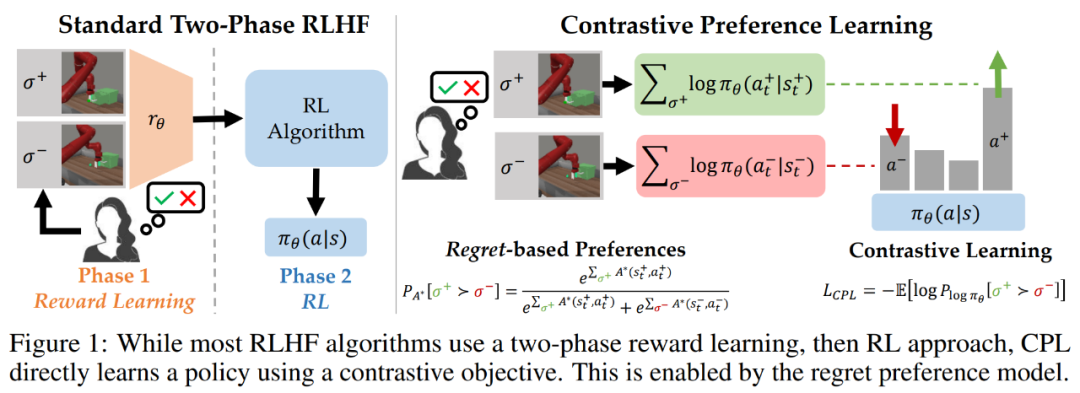
在使用后悔偏好模型时,偏好数据集 D_pref 包含有关最优优势函数 A^∗ (s, a) 的信息。我们可以直观地认为,该函数度量的是一个给定动作 a 比最优策略在状态 s 时生成的动作的糟糕程度。因此根据定义,最大化最优优势的动作就是最优动作,并且从偏好学习最优优势函数应该让人能直观地提取出最优策略。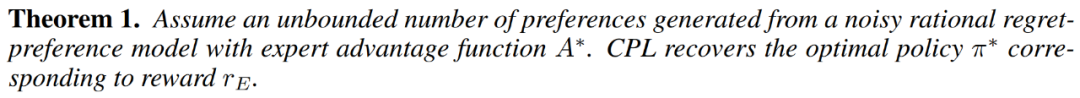
直接学习策略的好处。以这种方式直接学习 π 有诸多实践和理论上的好处。其中最明显的可能是:直接学习策略的话,就无需学习其它任何函数了,比如奖励函数或价值函数。这使得 CPL 比之前的方法简单很多。与对比学习的联系。CPL 方法直接使用一个对比目标来进行策略学习。研究者表示,鉴于对比学习目标已经在大型数据集和神经网络方面取得了有目共睹的成功,因此他们预计 CPL 能比使用传统强化学习算法的强化学习方法进行更好的扩展。对比偏好学习框架提供了一个通用的损失函数,可用于从基于优势的偏好中学习策略,基于此可以派生出许多算法。下面将基于一个实践效果很好的特定 CPL 框架实例介绍实践方面需要考虑的问题。使用有限离线数据的 CPL。尽管 CPL 可通过无界偏好数据收敛到最优策略,但实际上我们通常关心的是学习有限离线数据集。在这种设置下,外推到数据集支持之外太远的策略表现很差,因为它们采取的动作会导致出现分布之外的状态。正则化。在有限设置中,我们希望选择能最小化 CPL 损失函数的策略,同时为该数据集中的动作赋予更高的可能性。为了做到这一点,研究者使用一个保守的正则化器得到了以下损失函数:当策略在 D_pref 中的动作上有更高的可能性时,就分配更低的损失,从而保证其在分布内。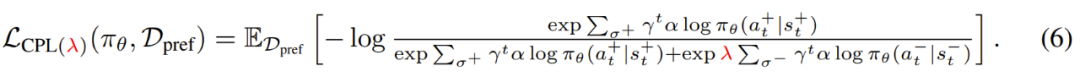
预训练。该团队发现,如果使用行为克隆(BC)方法对策略 π_θ 进行预训练,往往能得到更优的结果。因此,在通过 CPL 损失使用偏好来进行微调之前,该团队使用了标准的最大似然行为克隆目标来训练策略,即: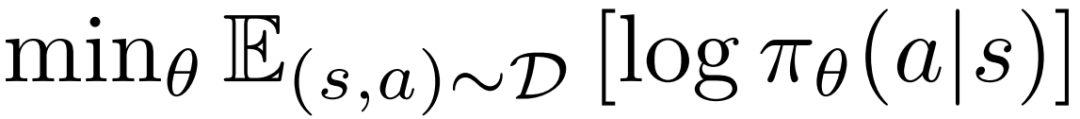
这一节将解答以下有关 CPL 的问题:一、CPL 能否有效地根据基于后悔的偏好来微调策略?二、CPL 能否扩展用于高维控制问题和更大的网络?三、CPL 的哪些组件对于获得高性能很重要?偏好数据。使用次优的离策略 rollout 数据和偏好,研究者评估了 CPL 为一般性 MDP 学习策略的能力。基准方法。实验中考虑了三种基准方法:监督式微调(SFT)、偏好隐式 Q 学习(P-IQL)、% BC(通过对 rollout 的 top X% 进行行为克隆来训练策略)。使用基于状态的观察数据时,CPL 表现如何?对于基于状态的实验结果,主要可见表 1 的第 1 和 3 行。当使用更稀疏的比较数据时(第 3 行),CPL 在 6 个环境中的 5 个上都优于之前的方法,并且相比于 P-IQL 的优势大都很明显,尤其是 Button Press、Bin Picking 和 Sweep Into 环境。当应用于具有更密集比较的数据集时,CPL 比 P-IQL 的优势还要更大(第 1 行),并且在所有环境上都很显著。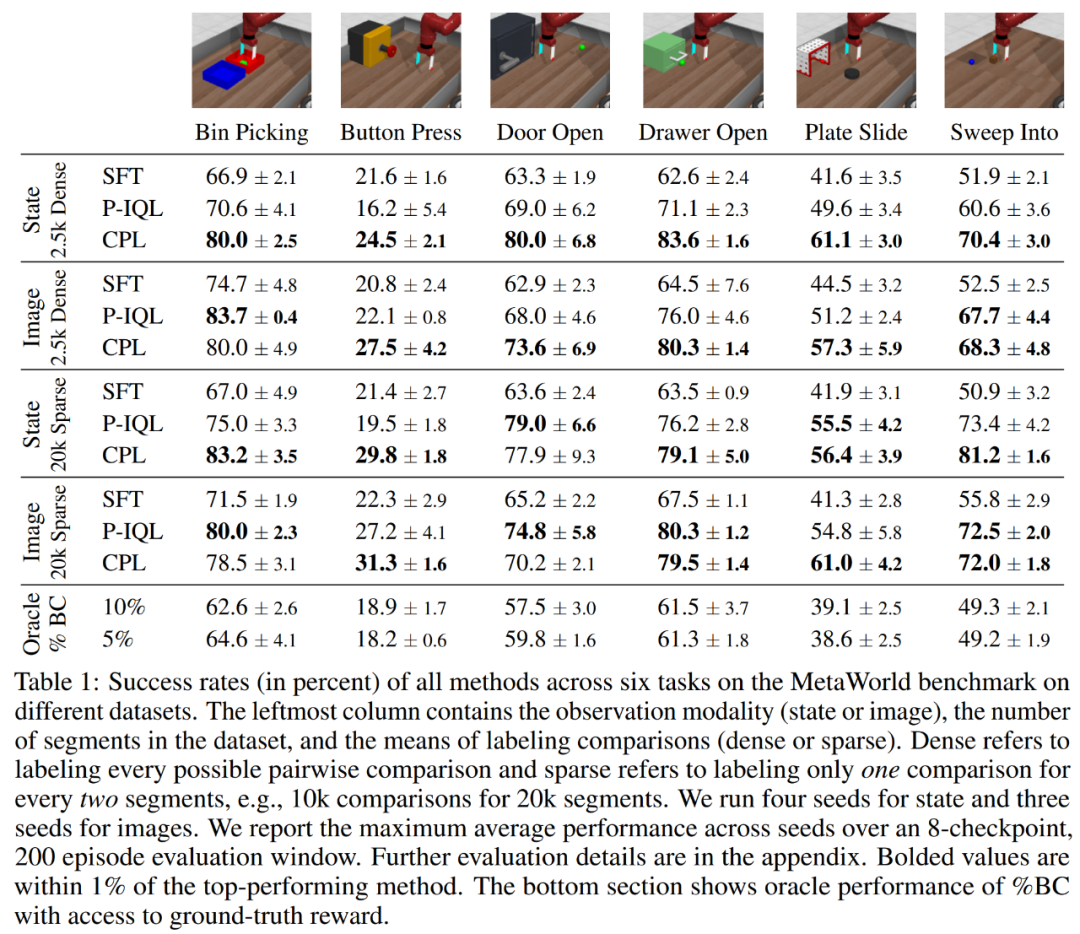
CPL 如何扩展用于高维观察数据?为了测试 CPL 的监督目标能否扩展用于高维连续控制问题,该团队将 MetaWorld 数据集渲染成了 64 × 64 的图像。表 1 的第 2 和 4 行给出了基于图像的实验结果。他们得到了有趣的发现:对 SFT 来说,性能表现略有提升,但 P-IQL 的提升却很明显。当学习更密集的偏好数据时(第 2 行),CPL 仍旧在 6 个环境中的 4 个上优于 P-IQL,在 Sweep Into 上两者相当。当学习更稀疏的比较数据时(第 4 行),CPL 和 P-IQL 在大多数任务上都表现相当。考虑到 CPL 有明显更低的复杂性,这样的结果就更惊人了!P-IQL 必须学习一个奖励函数、一个 Q 函数、一个价值函数和一个策略。CPL 则都不需要,它只需学习一个策略,这能极大减少训练时间和参数数量。正如下表 2 所示,在图像任务上,CPL 的运行速度比 P-IQL 快 1.62 倍,并且参数数量还不到 P-IQL 的四分之一。随着网络越来越大,使用 CPL 所带来的性能增益只会有增无减。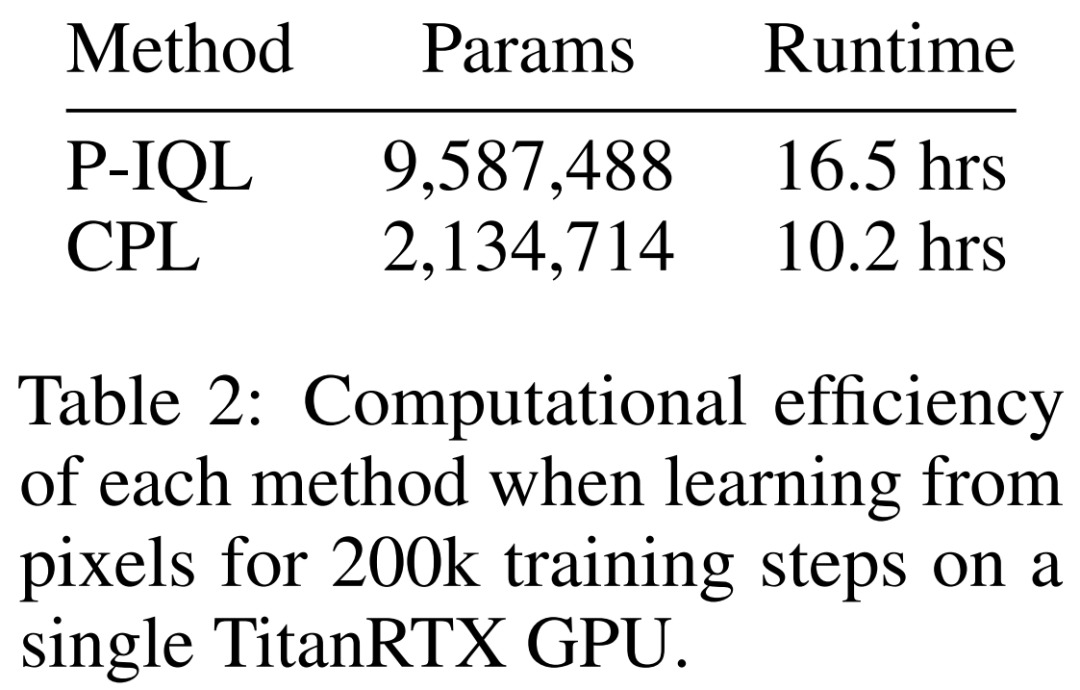
从实验结果可以看到,当使用有更密集比较的数据集时,CPL 和基准方法之间的差距会更大。这与之前在对比学习方面的研究成果一致。为了研究这种效果,研究者基于一个包含 5000 个片段的固定大小的数据集,通过增加每个片段采样的比较数量,对 CPL 的性能进行了评估。下图 2 给出了在基于状态的观察数据的开抽屉(Drawer Open)任务上的结果。整体上看,当每片段采样的比较数量增加时,CPL 都能从中受益,仅有 Plate Slide 任务例外。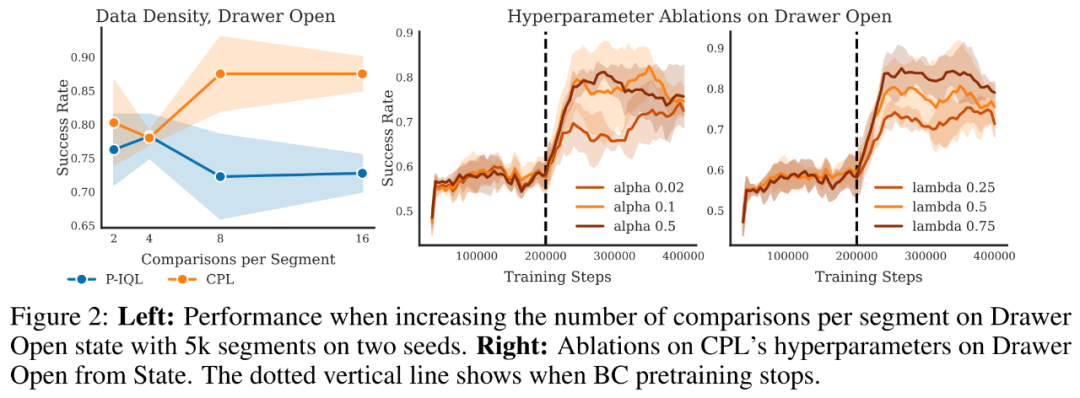
最后,该团队也对 CPL 的超参数(温度值 α 和偏差正则化器 λ)进行了消融研究;该研究也基于开抽屉任务,结果见图 2 右侧。尽管 CPL 使用这些值的表现已经很好了,但实验发现通过适当调整超参数(尤其是 λ),其表现还能更好。© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]