扫码加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文搞科研,强烈推荐!
在CVer微信公众号后台回复:论文,即可下载论文pdf和代码链接!快学起来!
大模型涌向移动端的浪潮愈演愈烈,终于有人把多模态大模型也搬到了移动端上。近日,美团、浙大等推出了能够在移动端部署的多模态大模型,包含了 LLM 基座训练、SFT、VLM 全流程。也许不久的将来,每个人都能方便、快捷、低成本的拥有属于自己的大模型。
MobileVLM 是一款专为移动设备设计的快速、强大和开放的视觉语言助手。它结合了面向移动设备的架构设计和技术,包括从头开始训练的 1.4B 和 2.7B 参数的语言模型、以 CLIP 方式预训练的多模态视觉模型,以及通过投影实现的高效跨模态交互。在各种视觉语言基准测试中,MobileVLM 的性能可媲美大型模型。此外,它还在高通骁龙 888 CPU 和英伟达 Jeston Orin GPU 上展示了最快的推理速度。
- 论文:https://arxiv.org/pdf/2312.16886
- Code 地址:https://github.com/Meituan-AutoML/MobileVLM
简介
大型多模态模型(LMMs),尤其是视觉语言模型(VLMs)系列,由于其在感知和推理方面的能力大大增强,已成为构建通用助手的一个很有前途的研究方向。然而,如何将预训练好的大型语言模型(LLMs)和视觉模型的表征连接起来,提取跨模态特性,完成如视觉问题解答、图像字幕、视觉知识推理和对话等任务,一直是个难题。GPT-4V 和 Gemini 在这项任务上的出色表现已经被多次证明。不过,这些专有模型的技术实现细节我们还知之甚少。与此同时,研究界也提出了一系列语言调整方法。例如,Flamingo 利用视觉 token,通过门控交叉注意力层对冻结的语言模型进行调节。BLIP-2 认为这种交互是不够的,并引入了一个轻量级查询 transformer(称为 Q-Former),它能从冻结的视觉编码器中提取最有用的特征,并将其直接输入到冻结的 LLM 中。MiniGPT-4 通过一个投影层将 BLIP-2 中的冻结视觉编码器与冻结语言模型 Vicuna 配对。另外,LLaVA 应用了一个简单的可训练映射网络,将视觉特征转换为嵌入 token,其维度与语言模型要处理的单词嵌入相同。值得注意的是,训练策略也在逐渐发生转变,以适应多样性的大规模多模态数据。LLaVA 可能是将 LLM 的指令调整范式复制到多模态场景的首次尝试。为了生成多模态指令跟踪数据,LLaVA 向纯语言模型 GPT-4 输入文本信息,如图像的描述语句和图像的边界框坐标。MiniGPT-4 首先在综合性的图像描述语句数据集上进行训练,然后在【图像 - 文本】对的校准数据集上进行微调。InstructBLIP 基于预训练的 BLIP-2 模型执行视觉语言指令调整,Q-Former 是在以指令调整格式组织的各种数据集上训练的。mPLUG-Owl 引入了一种两阶段训练策略:首先对视觉部分进行预训练,然后使用 LoRA ,基于不同来源的指令数据对大语言模型 LLaMA 进行微调。尽管 VLM 取得了上述的进展,人们也存在着在计算资源有限的情况下使用跨模态功能的需求。Gemini 在一系列多模态基准上超越了 sota,并为低内存设备引入了 1.8B 和 3.25B 参数的移动级 VLM。并且 Gemini 也使用了蒸馏和量化等常用压缩技术。本文的目标是建立首个开放的移动级 VLM,利用公共数据集和可用技术进行训练,以实现视觉感知和推理,并为资源受限的平台量身定制。本文的贡献如下:- 本文提出了 MobileVLM,它是专为移动场景定制的多模态视觉语言模型的全栈级改造。据作者表示,这是首个从零开始提供详细、可复现和强大性能的视觉语言模型。通过受控和开源数据集,研究者建立了一套高性能的基础语言模型和多模态模型。
- 本文对视觉编码器的设计进行了广泛的消融实验,并系统地评估了 VLM 对各种训练范式、输入分辨率和模型大小的性能敏感性。
- 本文在视觉特征和文本特征之间设计了一种高效的映射网络,能更好地对齐多模态特征,同时减少推理消耗。
- 本文设计的模型可以在低功耗的移动设备上高效运行,在高通的移动 CPU 和 65.5 英寸处理器上的测量速度为 21.5 tokens/s。
- MobileVLM 和大量 多模态大模型在 benchmark 的表现不相上下,证明了其在众多实际任务中的应用潜力。虽然本文主要关注的是边缘场景,但 MobileVLM 优于许多最新的 VLM,而这些 VLM 只能由云端强大的 GPU 支持。
MobileVLM
考虑到为资源有限的边缘设备实现高效的视觉感知和推理的主要目标,研究者设计了 MobileVLM 的整体架构,如图 1 所示,模型包含三个组件:1) 视觉编码器,2) 定制的 LLM 边缘设备 (MobileLLaMA),以及 3) 高效的映射网络(文中称为 “轻量级下采样映射”,LDP),用于对齐视觉和文本空间。
以图像  为输入,视觉编码器 F_enc 从中提取视觉嵌入
为输入,视觉编码器 F_enc 从中提取视觉嵌入  用于图像感知,其中 N_v = HW/P^2 表示图像块数,D_v 表示视觉嵌入的隐层大小。为了缓解因处理图像 tokens 效率问题,研究者设计了一种轻量级映射网络 P,用于视觉特征压缩和视觉 - 文本模态的对齐。它将 f 转换到词嵌入空间中,并为后续的语言模型提供合适的输入维度,如下所示:
用于图像感知,其中 N_v = HW/P^2 表示图像块数,D_v 表示视觉嵌入的隐层大小。为了缓解因处理图像 tokens 效率问题,研究者设计了一种轻量级映射网络 P,用于视觉特征压缩和视觉 - 文本模态的对齐。它将 f 转换到词嵌入空间中,并为后续的语言模型提供合适的输入维度,如下所示: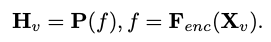
这样,就得到了图像的 tokens 和文本的 tokens
和文本的 tokens ,其中 N_t 表示文本 tokens 的数量,D_t 表示单词嵌入空间的大小。在目前的 MLLM 设计范式中,LLM 的计算量和内存消耗量最大,有鉴于此,本文为移动应用量身定制了一系列推理友好型 LLM,在速度上具有相当的优势,能够以自回归方式对多模态输入进行预测
,其中 N_t 表示文本 tokens 的数量,D_t 表示单词嵌入空间的大小。在目前的 MLLM 设计范式中,LLM 的计算量和内存消耗量最大,有鉴于此,本文为移动应用量身定制了一系列推理友好型 LLM,在速度上具有相当的优势,能够以自回归方式对多模态输入进行预测 ,其中 L 表示输出的 tokens 长度。这一过程可表述为
,其中 L 表示输出的 tokens 长度。这一过程可表述为 。根据原文第 5.1 节中的经验分析,研究者利用分辨率为 336×336 的预训练 CLIP ViT-L/14 作为视觉编码器 F_enc。视觉 Transformer(ViT)将图像分割成大小一致的图像块,并对每个图像块做一次线性嵌入。随后和位置编码整合后,将结果向量序列输入正则变换编码器。通常情况下,分类用的 token 会被添加到该序列中,用于后续的分类任务。对于语言模型,本文缩小了 LLaMA 的规模,以方便部署,也就是说,本文提出的模型可以无缝地支持几乎所有流行的推理框架。此外,研究者还评估了边缘设备上的模型延迟,来选择合适的模型架构。神经架构搜索(NAS)是比较不错的选择,但目前研究者没有将其立马应用到当前的模型上。表 2 显示了本文架构的详细设置。具体来说,本文使用 LLaMA2 中的 sentence piece tokenizer,词表大小为 32000,并从头开始训练嵌入层。这样作有利于后续进行蒸馏。由于资源有限,所有模型在预训练阶段使用的上下文长度都是 2k。不过,如《Extending context window of large language models via positional interpolation》中所述,推理时的上下文窗口可以进一步扩展到 8k。其他组件的详细设置如下。
。根据原文第 5.1 节中的经验分析,研究者利用分辨率为 336×336 的预训练 CLIP ViT-L/14 作为视觉编码器 F_enc。视觉 Transformer(ViT)将图像分割成大小一致的图像块,并对每个图像块做一次线性嵌入。随后和位置编码整合后,将结果向量序列输入正则变换编码器。通常情况下,分类用的 token 会被添加到该序列中,用于后续的分类任务。对于语言模型,本文缩小了 LLaMA 的规模,以方便部署,也就是说,本文提出的模型可以无缝地支持几乎所有流行的推理框架。此外,研究者还评估了边缘设备上的模型延迟,来选择合适的模型架构。神经架构搜索(NAS)是比较不错的选择,但目前研究者没有将其立马应用到当前的模型上。表 2 显示了本文架构的详细设置。具体来说,本文使用 LLaMA2 中的 sentence piece tokenizer,词表大小为 32000,并从头开始训练嵌入层。这样作有利于后续进行蒸馏。由于资源有限,所有模型在预训练阶段使用的上下文长度都是 2k。不过,如《Extending context window of large language models via positional interpolation》中所述,推理时的上下文窗口可以进一步扩展到 8k。其他组件的详细设置如下。- 应用预归一化来稳定训练。具体来说,本文使用 RMSNorm 代替层归一化, MLP 膨胀比使用 8/3 而不是 4。

视觉编码器和语言模型之间的映射网络对于对齐多模态特征至关重要。现有的模式有两种:Q-Former 和 MLP projection 。Q-Former 明确控制每个 query 包含的视觉 tokens 数量,以强制提取最相关的视觉信息。但是,这种方法不可避免地会丢失 tokens 的空间位置信息,而且收敛速度较慢。此外,它在边缘设备上的推理效率也不高。相比之下,MLP 保留了空间信息,但通常会包含背景等无用的 tokens。对于一幅 patch 大小为 P 的图像,有 N_v = HW/P^2 个视觉 token 需要注入到 LLM 中,这大大降低了整体推理速度。受 ViT 的条件位置编码算法 CPVT 的启发,研究者利用卷积来增强位置信息,并鼓励视觉编码器的局部交互。具体来说,研究者对基于深度卷积(PEG 的最简单形式)的移动友好操作进行了调研,这种操作既高效又能得到各种边缘设备的良好支持。为了保留空间信息并最大限度地降低计算成本,本文使用了步长为 2 的卷积,从而减少了 75% 的视觉 token 数量。这种设计大大提高了整体推理速度。然而,实验结果表明,降低 token 取样数量会严重降低下游任务(如 OCR)的性能。为了减轻这种影响,研究者设计了一个更强大的网络来代替单个 PEG。高效的映射网络(称为轻量级下采样映射(LDP))的详细架构如图 2 所示。值得注意的是,这个映射网络只包含不到 2000 万个参数,运行速度比视觉编码器快约 81 倍。
本文使用 "层归一化"(Layer Normalization)而不是 "批归一化"(Batch Normalization),以使训练不受批量大小的影响。形式上,LDP(记为 P)将视觉嵌入 作为输入,并输出有效提取和对齐的视觉标记
作为输入,并输出有效提取和对齐的视觉标记  。
。
在表 3 中,研究者在两个标准自然语言 benchmark 上对本文提出的模型进行了广泛的评估,这两个 benchmark 分别针对语言理解和常识推理。在前者的评估中,本文使用了语言模型评估工具(Language Model Evaluation Harness)。实验结果表明, MobileLLaMA 1.4B 与 TinyLLaMA 1.1B、Galactica 1.3B、OPT 1.3B 和 Pythia 1.4B 等最新开源模型不相上下。值得注意的是, MobileLLaMA 1.4B 优于 TinyLLaMA 1.1B,后者是在 2T 级别的 token 上训练的,是 MobileLLaMA 1.4B 的两倍。在 3B 级别,MobileLLaMA 2.7B 也表现出与 INCITE 3B (V1) 和 OpenLLaMA 3B (V1) 相当的性能,如表 5 所示,在骁龙 888 CPU 上,MobileLLaMA 2.7B 比 OpenLLaMA 3B 快约 40%。

本文评估了 LLaVA 在 GQA 、ScienceQA 、TextVQA 、POPE 和 MME 上的多模态性能。此外,本文还利用 MMBench 进行了综合比较。如表 4 所示,MobileVLM 尽管参数减少、训练数据有限,但性能却很有竞争力。在某些情况下,它的指标甚至优于之前最先进的多模态视觉语言模型。
Low-Rank Adaptation(LoRA)可以用较少的可训练参数实现与全微调 LLM 相同甚至更好的性能。本文对这一做法进行了实证研究,以验证其多模态性能。具体来说,在 VLM 视觉指令调整阶段,本文冻结了除 LoRA 矩阵之外的所有 LLM 参数。在 MobileLLaMA 1.4B 和 MobileLLaMA 2.7B 中,更新后的参数分别只有完整 LLM 的 8.87% 和 7.41%。对于 LoRA ,本文将 lora_r 设为 128,lora_α 设为 256。结果如表 4 所示,可以看到,在 6 个 benchmark 上,带有 LoRA 的 MobileVLM 达到了与全微调相当的性能,这与 LoRA 的结果一致。研究者在 Realme GT 手机和英伟达 Jetson AGX Orin 平台上评估了 MobileLLaMA 和 MobileVLM 的推理延迟。该手机配备了骁龙 888 SoC 和 8GB 内存,可提供 26 TOPS 的计算能力。Orin 配备 32GB 内存,可提供惊人的 275 TOPS 计算能力。它采用 CUDA 11.4 版本,支持最新的并行计算技术,可提高性能。在表 7 中,研究者比较了不同规模和不同视觉 token 数量下的多模态性能。所有实验均使用 CLIP ViT 作为视觉编码器。
由于特征交互和 token 交互都是有益的,研究者对前者采用了深度卷积,对后者采用了点卷积。表 9 显示了各种 VL 映射网络的性能。表 9 中的第 1 行是 LLaVA 中使用的模块,该模块只通过两个线性层对特征空间进行转换。第 2 行在每个 PW(pointwise)之前添加了一个 DW(depthwise)卷积,用于 token 交互,该卷积使用 2 倍下采样,步长为 2。加两个前端 PW 层会带来更多的特征级交互,从而弥补 token 减少带来的性能损失。第 4 行和第 5 行显示,增加更多参数并不能达到预期效果。第 4 和第 6 行显示,在映射网络末端对 token 进行下采样具有正面效果。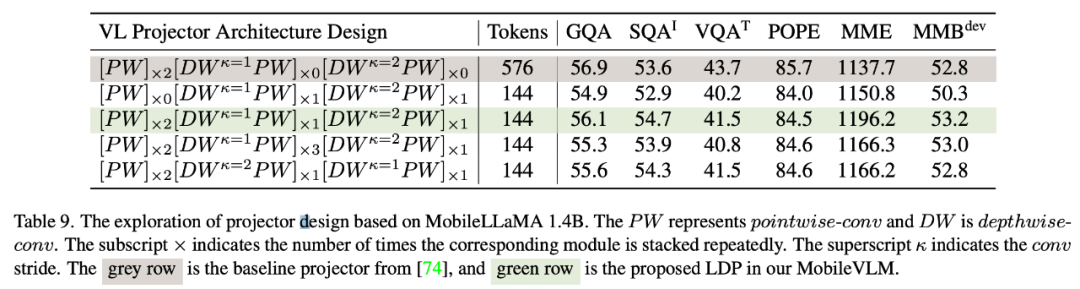
由于视觉 token 数直接影响整个多模态模型的推理速度,本文比较了两种设计方案:降低输入分辨率(RIR)和使用轻量级下采样投影器(LDP)。在 LLaMA 上进行微调的 Vicuna 被广泛用于大型多模态模型 。表 10 比较了两种常见的 SFT 范式 Alpaca 和 Vicuna 。研究者发现,SQA、VQA、MME 和 MMBench 的得分都有显著提高。这表明,在 Vicuna 对话模式下,利用 ShareGPT 的数据对大型语言模型进行微调,最终可获得最佳的性能。为了更好地将 SFT 的提示格式与下游任务的训练相结合,本文删除了 MobileVLM 上的对话模式,发现 vicunav1 的表现最佳。
简而言之,MobileVLM 是一套专为移动和物联网设备定制的高效、高能的移动版视觉语言模型。本文对语言模型和视觉映射网络进行了重置。研究者进行了广泛的实验,以选择合适的视觉骨干网络,设计高效的映射网络,并通过语言模型 SFT 等训练方案(包括预训练和指令调整的两阶段训练策略)和 LoRA 微调来增强模型能力。研究者在主流 VLM benchmark 上对 MobileVLM 的性能进行了严格评估。在典型的移动和物联网设备上,MobileVLM 也显示出前所未有的速度。研究者们认为相信,MobileVLM 将为移动设备或自动驾驶汽车上部署的多模态助手以及更广泛的人工智能机器人等广泛应用开辟新的可能性。在CVer微信公众号后台回复:论文,即可下载论文pdf和代码链接!快学起来!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态学习 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态学习+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!

▲扫码加入星球学习
整理不易,请点赞和在看
