
©作者 | 蚂蚁安全天鉴实验室
来源 | 蚂蚁技术AntTech
近日,蚂蚁安全天鉴实验室与复旦大学合作,针对视觉富文档的实际应用场景,指出了应用场景下常见的阅读顺序错乱问题,并强调该问题会严重影响当前模型的效果。针对上述问题,天鉴实验室在《Reading Order Matters: Information Extraction from Visually-rich Documents by Token Path Prediction》论文中重新提出视觉富文档场景下基于词序预测的 NER 任务形式和适用于该场景的数据集,并进一步提出 Token Path Prediction 模型以统一形式解决多项视觉富文档任务。模型在提出的数据集和多个公开测试集上取得 SOTA 效果,并在蚂蚁集团的多个业务场景得到了落地应用。论文工作已经被自然语言处理领域顶会 EMNLP 2023 录用为主会长文(main conference,oral)。
论文标题:
Reading Order Matters: Information Extraction from Visually-rich Documents by Token Path Prediction
https://arxiv.org/abs/2310.11016
复旦大学计算机科学技术学院教授、博士生导师张奇老师表示,文档信息抽取是视觉富文档上的重要应用任务,近年来,面向文档理解的多模态预训练模型极大地推进了这一领域的发展。这篇论文是对真实应用场景下文档模型阅读顺序错乱问题的深入探讨,指出了该问题对现有文档信息抽取模型带来的影响,并通过重新定义任务形式、设计通用模型来解决这一问题。论文通过提出 Token Path Prediction 模型解决了这一问题,并能用于命名实体识别、实体链接、阅读顺序预测等多项任务上,显著改善了真实情况下模型在这些任务上的效果。这项研究对视觉富文档的信息抽取具有重要的科研意义和现实应用价值。问题背景
文档智能(Document Intelligence)是一项因实际的工业界需求而生的研究课题,主要是指对包含网页、数字文档、扫描文档等在内的视觉富文档(Visually-rich Document)进行内容理解和信息归纳的处理过程。在数字化时代,视觉富文档是最常见的信息载体,用来收集、保存和展示各种模态信息,包括图像(插图、指标图、背景图、视觉 UI 等)、文本(标题、段落内容等)、排版(文本字号颜色等版式、文本缩进结构等空间、UI 布局、分割线、格线格点等)等多模态信息,在多种应用领域得到广泛应用。因此,对视觉富文档的结构化分析和信息抽取是企业生产中的必要一环,自动化地从视觉富文档中提取关键信息,是企业数字化服务的一项关键性技术。本文主要涉及视觉富文档上的命名实体识别(Named Entity Recognition,NER)、实体链接(Entity Linking,EL)和阅读顺序预测(Reading Order Prediction,ROP)任务。NER 任务旨在从文档内容中识别出特定类型的实体,如人名、地名、组织机构名等。通过 NER 可以帮助识别文档中的重要信息,包括人物、位置、组织机构、日期和时间等,并用于后续任务。EL 任务旨在基于某种预定义的实体关系,在文档中找到所有符合条件的实体对。通过 EL 识别出的实体对具有显式语义,可用于构建结构化知识图谱,用于增强对文档内容的语义理解。这两项任务是最基础的信息抽取任务,不但定义了最基础的信息抽取任务范式,也是其他信息抽取任务的基础。ROP 任务旨在按照人类阅读顺序排列文档标注中的文字内容,是重要的文档理解任务。
任务定义与挑战
文档信息抽取场景中的阅读顺序问题,主要来自我们对 NER 任务的实践与思考。在 NLP 中,NER 任务可以用序列标注的范式解决。如图 1 所示,对于一条文本数据"NAME OF
ACCOUNT # OF STORES SUPPLIED",序列标注范式采取 BIO 标注方案,将"NAME
OF ACCOUNT"和"# OF STORES SUPPLIED"标注为类型为 Header 和 Question 的实体,随后通过分类模型学习每个词对应的标签。在视觉富文档的先前工作中,也采用类似的范式,先通过基于 Transformer
encoder 的文档编码器(如 LayoutLM 等)对文档输入进行编码,然后通过一个词元预测(token classification)头来进行序列标注任务的建模,优化分类 loss 实现对 NER 任务的学习。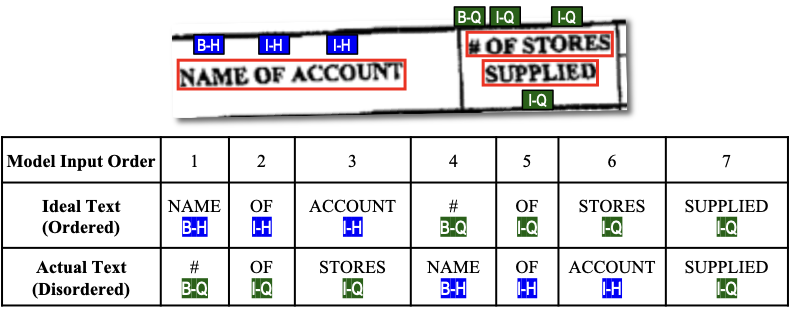
▲ 图1: 扫描文档上存在阅读顺序问题,不能用序列标注范式解决NER任务然而,在实际生产应用中,扫描文档的布局信息通常是通过一个前置的 OCR 系统获得的。词语的顺序按照布局坐标框从上到下、从左到右的顺序排列,因而会产生阅读顺序问题,即词语排列顺序和人类阅读顺序不符的问题。如图 1 所示,OCR 系统将跨行的实体"# OF STORES SUPPLIED"识别为两个不同的片段(segment),实体在输入中被分为不连续的两段,因此不能用 BIO 标签来合理地表示。因此,序列标注的范式不适用于该场景下的 NER 任务。图 2 展示了更多真实场景下具有阅读顺序问题的扫描文档,以体现该问题的严重性。

▲ 图2: 真实场景下扫描文档的阅读顺序问题。最右侧是根据OCR结果自动排列的伪阅读顺序,和人类阅读顺序相冲突。针对上述问题,我们重新定义了视觉富文档上 NER 任务的形式,把该任务建模成无向图上的一个路径预测问题。我们指出,视觉富文档上的命名实体应该由词序列表示。具体而言,我们将文档输入视为一个词与词之间双向连结的完全有向图,每个命名实体表示为图中词与词之间首尾相连的一条路径,在文中称为词元路径(Token Path),从而把文档 NER 任务建模成文档完全图上的路径预测问题。如图 3 所示,无论文字是否受到离散、颠倒等词语乱序的情况影响,这种方案都能恰当地标出文档中的每个实体。在此基础上,如何设计一个模型,使其能预测预测文档中乱序且彼此交错的词序列,是这项任务聚焦的核心问题。

▲ 图3: 使用词序列标注文档中的实体,不受阅读顺序问题影响
模型设计
模型结构
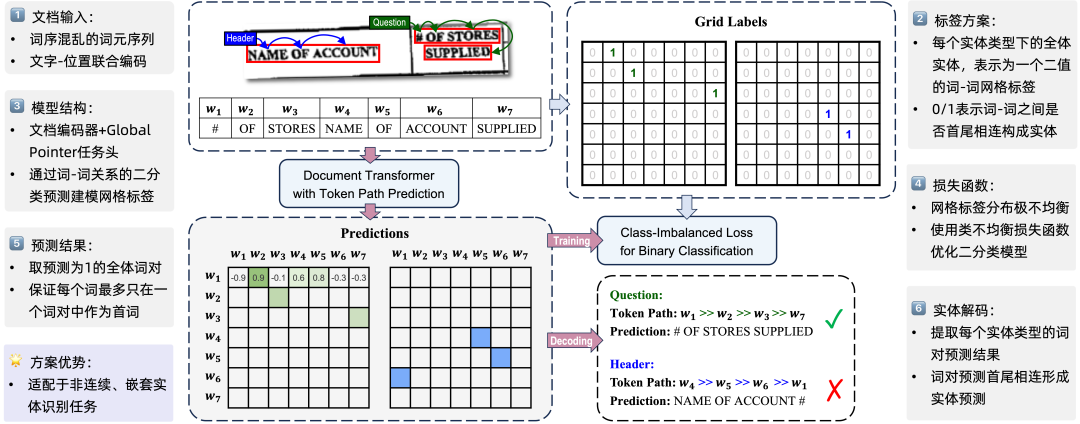
▲ 图4: Token Path Prediction流程图针对上节提出的模型设计问题,我们提出基于网格标签预测的解决框架,将以上问题转化为一个分类问题。如图 4 所示,对于包含 N 个词的文档输入,我们建立 E 个 N*N 的网格标签,其中 E 是实体类型数。每个网格标签表示文档中一种实体类型的全部实体。以图 4 中全体 Header 类型的实体为例,实体"HEAD OF ACCOUNT"表示为对应网格标签中("HEAD", "OF")和("OF", "ACCOUNT")位置的"1"标注,而网格中其他位置标注为"0". 以此法,我们将每条文档样本的实体标注表示为 E*N*N 的二值网格标签。随后,我们建立模型进行网格标签的预测。我们提出 Token Path Prediction(简称为 TPP)预测头,可以和任意一个结构类似 LayoutLM 的文档布局编码器搭配,来进行网格标签的预测。如果把网格标签视为以全体词元(token)作为结点的一个有向完全图,实体标注可以视为图上的若干条路径,因此 TPP 将 NER 任务视为一种在图中预测路径的方法,并以 Token Path Prediction(“词元路径预测”)命名。TPP 预测头的输入是文档编码器的输出,即 N 个文本+布局信息的 token 的表示序列;输出是 N*N 的二值预测,表示对网格标签的预测,其中下标为 (i, j) 的预测值表示对第 i 个、第 j 个词元之间关系的预测。基于此,Token Path Prediction 中使用 Global Pointer 来实现上述的网格标签预测,并使用配套的 Class-Imbalanced Loss 作为优化目标,对全体模型参数进行优化。多任务适配
基于上述模型结构,TPP 不但适用于文档上的 NER 任务,通过修改网格标签的标注方案,还能用来建模实体链接(EL)、阅读顺序预测(ROP)等任务。如图 5 所示,在 EL 任务中,如果两个实体之间存在链接关系,则将分别来自两个实体的每个词元对标注为 1,其他不相关词元对标注为 0;在 ROP 任务中,将全部词元从前到后的阅读顺序序列视为一条全局路径,并使用如上所述的路径标注的方法标识这条路径。通过上述方式,EL 和 ROP 任务均可转化为网格标签预测的任务范式,从而能使用 TPP 进行解决。
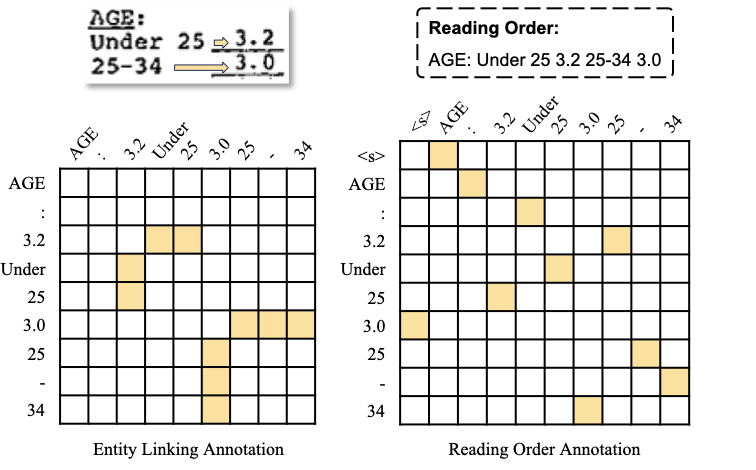
▲ 图5: TPP对实体链接、阅读顺序预测任务的适配整体而言,TPP 是一个简单易懂、易于代码实现的方案,它能应用于多种视觉富文档的信息抽取任务,解决该任务在实际应用中面临的阅读顺序问题。值得一提的是,TPP 既能直接作为文档 NER 任务的模型,又能作为文档阅读顺序预测模型,充当前置机制来重新排列文档词元的输入,以修正之前基于序列标注的 NER 方法。
实验效果
数据集
为了展开对视觉富文档信息抽取中阅读顺序问题的研究,我们重新标注了常用文档 NER 数据集 FUNSD 和 CORD 的布局和实体标注。先前的两个评测基准中,布局标注和现实应用场景存在不一致,不适合用于评价现实场景中的文档信息抽取。因此,我们和现实情况对齐,采用基于 PPOCR 的 OCR 系统重新标注布局信息,并人工在新的布局标注基础上标注实体信息,从而构建新的 FUNSD-r 和 CORD-r 数据集。这两个数据集在高质量的扫描文档图像上标注了符合现实情景的布局信息,因而更加适合于衡量视觉富文档 NER 模型在现实场景中的效果。图 6 展示了重标数据集和原始数据集在 OCR 标注上的区别,以 FUNSD 的一条样本为例,细粒度位置框由 OCR 系统提供,所以以字符位置给出;片段标注同样遵从 OCR 系统的现实情况,把跨行实体的每一行标记为一个片段,并保留了 OCR 系统的误识情况,包括将空间位置相近的单词识别为同一个片段,以及遗漏识别的情况。

▲ 图6: (左)FUNSD数据集的原始标注;(右)我们的重新标注,更符合现实应用场景。
NER实验效果
在文档编码器上,我们分别采用“图+文+布局”模态和“文+布局”模态表现最好的基座模型用于验证,即 LayoutLMv3 和蚂蚁自研的 LayoutMask.▲ 表1: TPP在NER任务上的效果。Pre.即前置的输入排序机制,其中None表示不对输入进行排序,LR/LR_C表示使用预先在ReadingBank/CORD上训练的LayoutReader阅读顺序模型对输入进行排序,TPP_R/TPP_C表示使用预先在ReadingBank/CORD上训练的TPP阅读顺序模型进行排序。Cont.指的是实体在模型输入中有序且连续排列的比例,越高则文档输入越有序,即前置机制越好。F1得分为方案在数据集上的实体级别F1得分,得分越高则“前置机制+模型”的解决方案越有效。
如表 1 所示,无论作为 NER 模型,还是作为一项前置的输入顺序重排机制,TPP 在全部的 4 组设定上的表现均达到 SOTA,超过了先前的序列标注模型。作为 NER 模型,TPP 在全部的 4 组设定上超过基线模型,尤其是在阅读顺序问题较为严重的 CORD-r 数据集上,TPP 相对基线模型分别有 +9.13 和 +7.50 的性能增益。注意到,在 NER 任务上,序列标注方法只需要预测实体的边界,而 TPP 还需要对实体内的词元进行排序,任务更难;因此,TPP 的实际效果可能比实验结果展示出来的更好。作为前置机制,我们采用 LayoutMask+TPP 的阅读顺序预测模型,其比较对象为微软在 21 年提出的 LayoutReader(LR)阅读顺序预测模型,以及空白对照组。如表 1 所示,作为前置机制,TPP 的效果好于 LayoutReader,后者几乎不能作为一个合格的前置机制,而我们的模型在两个数据集上均起到输入重排的效果,对实体有序率有 +1.55 和 +0.33 的提升。经 TPP 改善输入的序列标注模型在 FUNSD-r 数据集上、采用 LayoutMask 底座的场景下,获得 +3.60 的性能增益,成为 SOTA 结果。综上所述,TPP 很好地解决了文档信息抽取中的阅读顺序问题,而且可以低成本地适配于不同的文档编码器。可视化分析
为了更清晰地展示 TPP 的优点和缺点,我们选取了在实际应用中的若干疑难情况,并可视化不同模型的预测结果作为对照,如图 7 所示:

▲ 图7: 不同模型预测可视化结果
如图所示,TPP 的优点在于精确识别复杂布局中的实体边界,而不受片段标注的偏差影响。例如“跨行实体”情形,TPP 可以完美识别横跨两行的日期信息;在“跨列实体”情形,“TOTAL”和“(2 item)”是两个不同的实体,但是被识别为同一片段,TPP 可以完美地识别两者边界,并把“TOTAL”和另一个片段的“120,000”关联,从而正确识别实体。针对“长实体”情形,TPP 可以正确识别整段文字作为同一实体,而序列标注模型的预测中存在中断,导致预测结果被解码为两个单独的实体;这种预测错误在序列标注模型中很难避免,因为单个词的预测错误在目标函数中的影响会被其他正确预测结果平摊削弱,但实体的完整、正确识别依赖于全部词的预测正确。我们也观测到 TPP 在特定情形下存在捕获实体类型语义的不足,如“实体类别识别”情形,TPP 正确地预测出“SEPT 21”和“NOV 9”实体,却错误地预测两者为“Answer”实体类型,这可能是因为 TPP 在预测中过度关注“Question-Answe的左-右排布”布局信息,而忽略了实体本身的文本信息。这也指出了 TPP 的一大改进方向,即侧重建模实体类型语义和实体类型之间的关系。其他任务实验效果
TPP 在 EL 和 ROP 任务上也取得了当前基准上的 SOTA. 表 2 展示了 TPP 在 EL 任务上的效果,相比于之前的 SOTA 方案,基于 LayoutMask+TPP 的模型在 FUNSD 数据集上取得 +4.23 的性能优势。对于 ROP 任务,注意到我们的模型结构无关于词序,所以我们在这 6 组设定上做的实验不存在除随机性外的差异,基本视同为同一组实验的 6 次重复运行。我们的 TPP 在 ARD 指标上大幅度超过了 LayoutReader,在 BLEU 指标上也基本全面超过了 LayoutReader,仅在(0-否)这组 setting 上与 LayoutReader 有微弱差别。我们认为在(0-否)这组 setting 上,训练/验证/测试集的阅读顺序几乎和输入词序一致,因此 LayoutReader 的 LayoutLM 编码器通过全局 1D 信息编码了输入词序信息,并简单地基于过拟合该特征进行预测。由于测试集上同样存在这种系统性偏差,所以未体现为性能下降。相反地,我们的模型结构无关于词顺序,所以规避了可能的过拟合问题。

▲ 表3: TPP在ROP任务上的效果。Order一栏表示在测试时文档输入的排列顺序,其中OCR表示词语按照从上到下、从左到右的顺序排列,Shfl.表示词语乱序排序。r表示在测试时文档输入打乱的样本比例,r越大模型对乱序输入的鲁棒性越强,但也可能因输入顺序噪声而损失一部分性能。
如前文所述,阅读顺序预测模型可以作为信息抽取任务中模型输入的前置机制,来改善阅读顺序问题。但是 LayoutReader 并没有实现这一效果。结合本节展示的实验结果,我们进一步分析实验现象,来说明为何 TPP 相对 LayoutReader 在这一场景下具有优势:首先,我们的 TPP 模型保证输出为词下标的一种排列,从而规避了词的漏预测,体现为 ARD 指标上的大幅度降低。因此,在作为前置机制对输入词序列进行重排等场景下,我们的模型有助于防止信息丢失。另外,我们的 TPP 对输入词元序列中词元的先后顺序不敏感,因此训练集、测试集是否打乱对我们的模型效果没有影响。因此,在作为前置机制对输入词序列进行重排等场景下,在输入混乱程度较为严重时,TPP 的性能不会受到巨大影响。综上所述,相比于先前的排序模型,TPP 能通用地解决信息抽取任务的阅读顺序问题。
展望和总结
1. 指出了文档信息抽取中的阅读顺序问题,指出当前的 NER 模型不适合应用于具有阅读顺序问题的真实场景,并针对真实场景重新提出文档 NER 的任务范式;2. 提出一种简单、易实现、可广泛适配的 Token Path Prediction 方案,用来解决文档 NER 上的阅读顺序问题;3. 积极探索 TPP 方案对多种文档任务的适配,在 NER、EL、ROP 任务上取得 SOTA,证明了 TPP 方案可以作为文档信息抽取的一项通用解决方案。TPP 模型已经应用在集团内多个涉及文档理解、信息抽取的业务场景,比如统一解限凭证解析、商家数字化云雁、外卡审核、医保亲情账户审核、小程序页面理解等。面向智能凭证产品项目多类场景属性的凭证识别解析需求,TPP 模型在 30 余项智能凭证识别解析标准能力建设上得到应用,覆盖个人卡证、企业资质、经营场景、交易凭证、行业文档、通用类别等文档类别。[1] Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., & Zhou, M. (2020, August). Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 1192-1200).
[2] Su, J., Murtadha, A., Pan, S., Hou, J., Sun, J., Huang, W., ... & Liu, Y. (2022). Global pointer: Novel efficient span-based approach for named entity recognition. arXiv preprint arXiv:2208.03054.[3] Li, C., Liu, W., Guo, R., Yin, X., Jiang, K., Du, Y., ... & Ma, Y. (2022). PP-OCRv3: More attempts for the improvement of ultra lightweight OCR system. arXiv preprint arXiv:2206.03001.[4] Huang, Y., Lv, T., Cui, L., Lu, Y., & Wei, F. (2022, October). Layoutlmv3: Pre-training for document ai with unified text and image masking. In Proceedings of the 30th ACM International Conference on Multimedia (pp. 4083-4091).[5] Tu, Y., Guo, Y., Chen, H., & Tang, J. (2023). LayoutMask: Enhance Text-Layout Interaction in Multi-modal Pre-training for Document Understanding. arXiv preprint arXiv:2305.18721.[6] Wang, Z., Xu, Y., Cui, L., Shang, J., & Wei, F. (2021). Layoutreader: Pre-training of text and layout for reading order detection. arXiv preprint arXiv:2108.11591.

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
