
©PaperWeekly 原创 · 作者 | Hongru WANG
单位 | 香港中文大学
内功和外功,作为诸多武侠小说的两大流派,有着诸多区别。内功主要是内力,外功主要是拳脚功夫,如熟知的降龙十八掌就是外家的顶峰功夫,任何武功若想发挥最大的威力都离不开内功的精深。内功是道,外功是术,道术结合,东方不败。作为一个业余的武侠小说爱好者和刚入门的科研爱好者,这次从内功和外功的两个角度出发,介绍我们我们组在 EMNLP 2023 中的两个工作,如有不当之处,敬请原谅:论文标题:
Cue-CoT: Chain-of-thought Prompting for Responding to In-depth Dialogue Questions with LLMs
https://arxiv.org/abs/2305.11792
https://github.com/ruleGreen/Cue-CoT
Large Language Models as Source Planner for Personalized Knowledge-grounded Dialogueshttps://arxiv.org/pdf/2310.08840.pdf代码链接:
https://github.com/ruleGreen/SAFARI

何为内功?
何为内功?按我的理解,要有功法,要运转多少个小周天,大周天,要有真气,真气运转之后要不变的更多,要不变的质量更好。何为功法?唯有 LLM 是也。何为小周天,大周天?唯有不同的 prompt engieering 或者说不同 path 的 chain-of-thoughts。何为真气?即为对话历史,也就是当前的输入。对话历史里面蕴藏着很多语义学线索,Mairesse 就研究过从对话历史中识别出来人物性格特点等,比如性子急的讲话就比较急躁,除此之外,其他工作也探索了类似情绪,心理状态等等不同方面的语义学线索,这些语义学线索在生成个性化回复的时候尤为重要。正如我们人类在进行对话的时候,不可避免的会考虑对方的性格习惯,当下的情绪和心理状态等,LLM 在进行对话的时候也需要考虑到这些因素,从而生成更有帮助,更容易被用户接受的回复。而相较于传统的 standard prompting 而言,LLM 直接依赖对话历史进行回复,没有显示的建模刚刚提到的隐藏在对话历史中丰富的用户信息,我们提出一种新的 CoT 方法,Cue-CoT,把用户回复生成建模成多阶段的推理过程:O-Cue:One-step inference, 类似于传统的 CoT,一步直接生成中间推理过程和最终回复。首先我们要求 LLM 推理出来当前对话历史里面蕴含的不同维度的用户信息(使用不同的 prompts),然后我们让 LLM 接着生成最终的回复。(相对复杂的指令和内容臃肿的输出)M-Cue:Multi-step inference,我们逐步的生成我们想要 LLM 输出的内容。和 O-Cue 一样,这里第一步我们要求 LLM 推理出来当前对话历史里面蕴含的不同维度的用户信息,然后给定对话上下文和第一步生成的中间结果,我们第二步让 LLM 接着生成最终的回复。(相对简单的指令和内容清晰的输出)
这两种 prompting 的处理方式不同,带来了 Zero-shot setting 和 One-shot setting(受限于 LLM input limit 和对话长度)的差别。Zero-shot Setting:在 O-Cue 中,由于单步指令较复杂(不要要进行推理还要进行回复生成,以及生成的格式要求),单步生成内容过多,导致 LLM 无法很好的理解指令;生成内容较短,无论是中间推理结果还是最后回复的长度相对于 M-Cue 都短一点,另外还有一个严重的问题是生成内容无法很好的切分,因为一部分 LLM 无法按照要求的格式进行输出。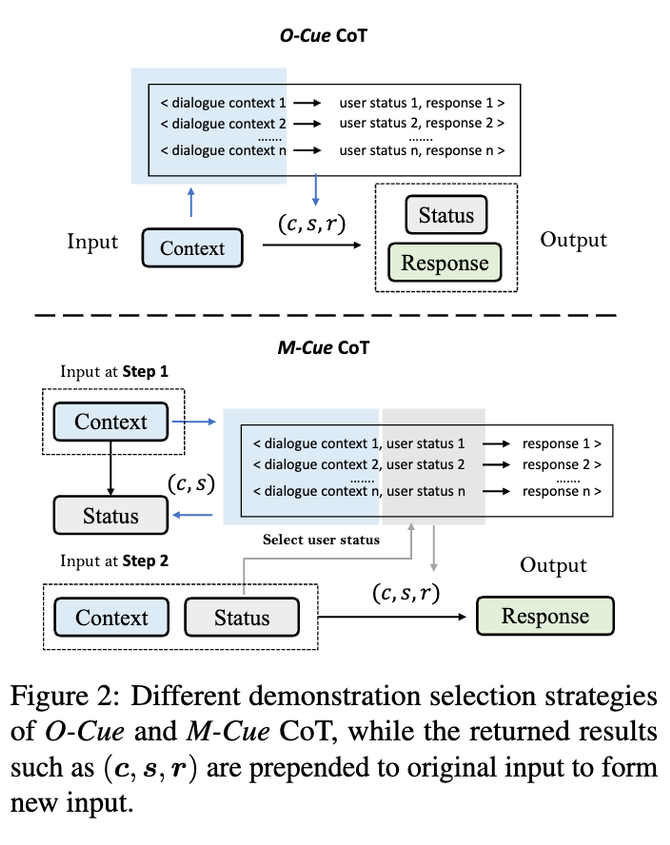
One-shot Setting:在进行 demostration selection 的过程中,也有着很大的区别。O-Cue 只能依赖单一的 input 即当前的对话上下文来作为 query 去 demostration pool 里面进行选择,而 M-Cue 在每一步都可以根据不同的 input 去作为 query 进行选择。总的来说,M-Cue 这种处理方式可以增强整个系统的解释性和控制性,我们对于中间结果可以进行编辑,比如增加对于当前用户的其他渠道的数据,或者过滤掉不好或者不正确的推理结果,其次这种中间结果可以作为 demostration selection 的一个标准,从而帮助我们更好的选择 demostration。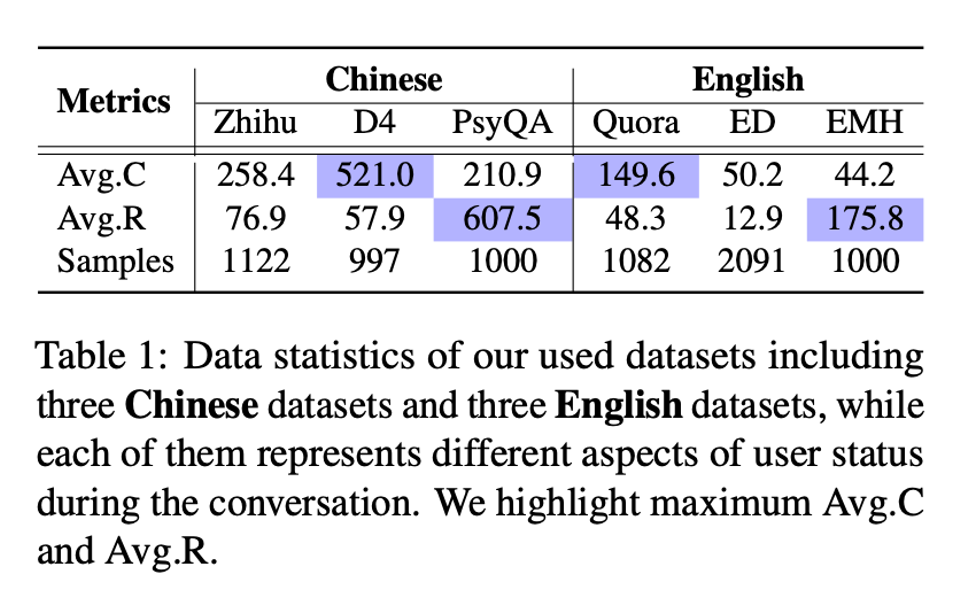
我们在 5 个中英文 LLM,6 个数据集(中文:Zhihu,D4,PsyQA;英文:Quora,ED,EMH)上将我们提出的 O-Cue 和 M-Cue 与传统的 standard prompting 进行了对比,这里具体的分析可以参考原文,总体来说我们发现: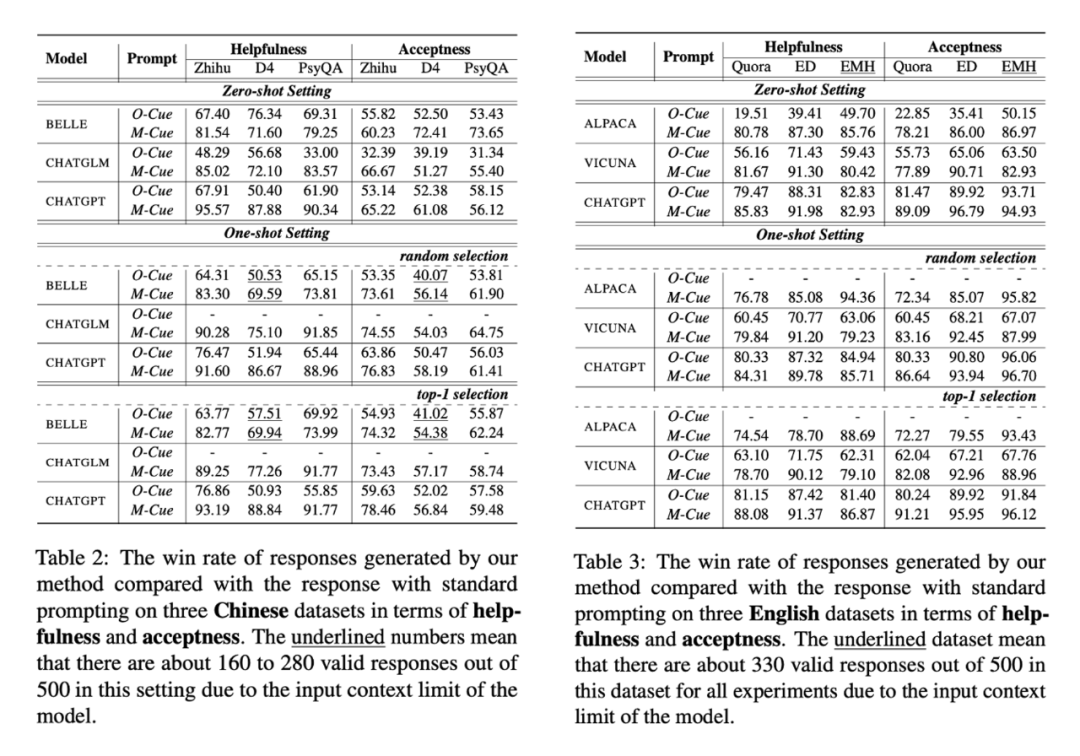
整体来说:大部分情况下 Cue-Cot 都能够取得比 standard prompting 更好的效果(win rates 超过 50%),其中受益于相对简单的指令和多步推理的输出,M-Cue 比 O-Cue 能够实现更高的 win rate。此外我们发现中文大模型上 acceptability 的 win rates 比 helpfulness 低,而英文大模型上刚好相反,我们猜测可能是由于中文大模型在根据当前用户的情感,性格等因素生成更容易被用户接受的回复的能力略弱,而仅仅考虑了 helpfulness 这个维度。
中文大模型:我们发现 ChatGLM 在 O-Cue 的情况下是三个模型当中最差的,然后我们检查了对应的输出,我们发现 ChatGLM 基本上忽视了给定的指令而直接进行对话;或者没有按照指令要求输出对应的格式,这可能归结为其不同的训练方式。但是在 M-Cue 的情况下所有的大模型都能很好的跟随指令,这种情况下由于 D4 的对话上下文是最长的,导致其效果是三个数据集中最差的。
- 英文大模型:在 O-Cue 的情况下 Alpaca 也出现了类似 ChatGLM 的问题,即不能很好的跟随指令,此外英文大模型在较长的对话输入等场景下也表现不佳。整体来说 ChatGPT 和 Vicuna 的指令跟随能力更强,相较于 Alpaca 而言都倾向于生成较长的回复。
注:以上实验结果均基于 2023 年 5 月左右的模型表现。以上均是方法层面的直接对比,我们额外进行了模型层面的对比。将 ChatGPT 作为锚点,我们评估了现有模型的相对表现。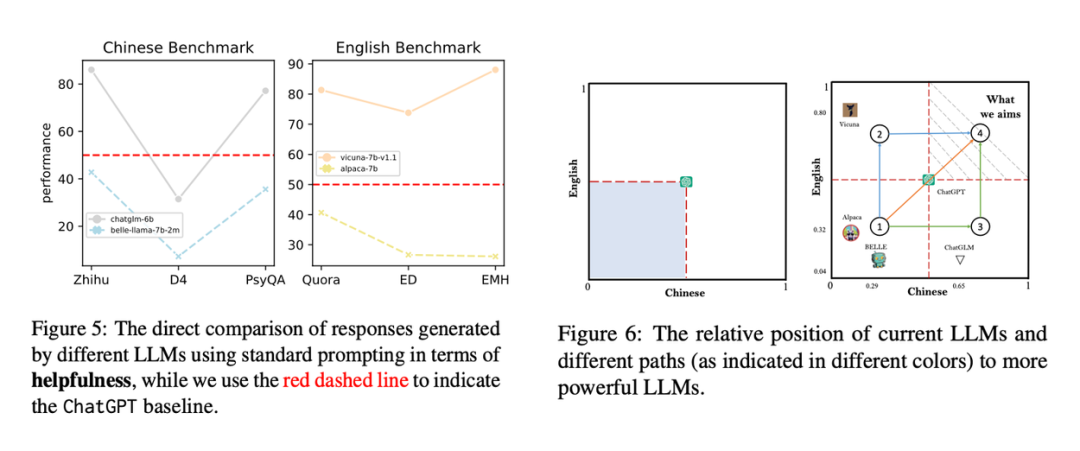
我们将中文和英文分别作为两个坐标轴,以 ChatGPT 为中间点将第一象限分为四个不同的区域,区域一代表中英文均比 ChatGPT 差;区域二代表英文比 ChatGPT 好,但是中文较差;区域三代表中文比 ChatGPT 好,但是英文较差;区域四代表中英文均比 ChatGPT 好。我们发现目前在区域四还是没有出现任何一个模型,我们设想了三种不同的路径来帮助我们得到区域四的模型。路径一:直接不断外推现有的 ChatGPT 的能力,如图中橙色所示,OpenAI 可能是这条路线。路径二:由当前中文模型进一步的在英文语料上进行训练,如 ChatGLM 或者其他中文模型。路径三:由当前英文模型进一步的在中文语料上进行训练,如 LLaMA 系列的中文版本,Vicuna 和 Alpaca 的中文版本。我们看到其实目前来说路径三里面的模型是最多的,路径一可能是最难的,路径二一方面是现有的中文模型的基座能力还没有达到上限;另一方面其英文能力可能也不是主流大模型玩家在乎的;还有一种可能是英文能力即使拉上去,可能也干不过 SOTA :)很多只需要当前的对话历史作为输入,从而得到最终的答案的对话任务,如回复多样性,回复选择,对话信息抽取,对话摘要等等,都属于内功。内功练得好,外功就用的越溜,因为在这个过程中,真气没有流失,要不压缩之后进一步提纯,质量变得更好了,比如从非结构化数据变成结构化数据;要不信息量得到增强,如情感分析等。这两种不同的处理导致的结果都是变的更加适配下游任务了。
何为外功?
那何为外功?外功由内力驱使,借助外力,如刀枪剑戟,即为不同的工具。功法,运转路径,真气,也是缺一不可。唯一不同的是这时候需要使用不同的刀法,剑法,即为不同工具的使用方法。那何时,何地使用工具,使用哪一个工具呢?这就是我们另外一个工作 SAFARI 所要探索的问题。开放域对话系统往往需要很多的外部知识,比如用户的 persona,和 wikipedia 上的 document,以及其他的一些我们设计出来的一些帮助我们生成更好回复的数据库等等。这些不同的外部知识,比如 persona 和 document,其实就是不同的 conceptual tool [1]。很多时候,不是每一轮对话都需要这些外部知识,也不是一下子就需要使用所有的外部知识,更复杂的是有时候这些知识库之间存在依赖,比如我们倾向于见人说人话,见鬼说鬼话,这就是根据不同人的 persona 使用了不同的 document 的结果,所以这里的 document 就是依赖于对话者的 persona 的。而之前的开放域对话系统大部分都是针对单一知识来源,要不是 persona 要不是 document 要不是其他的,也有一部分工作是考虑了多个外部知识的复合作用,但是不加区分的对于对话中的每一轮都使用所有知识,这无疑会带来额外的消耗和不必要的浪费。在本篇工作中,我们首先构造了一个数据集,建模了 persona 和 document 之间的依赖关系,其中 persona 的维度包括了年龄,性别,民族,爱好等 12 个维度,基本涵盖了当下个性化对话的大部分需求,然后我们按照不同的 persona description 提供了对应的 document,包括 5 个不同的 knowledge sentences。举个例子,persona description 包括有:我今年 16 岁,那对应的 document 里面包括的知识可能是 16 岁是未成年人,16 岁无法喝酒 等等。一条简单的 persona 描述背后可能隐藏着非常多的常识知识和世界知识,退一步说,即使 persona 和 document 之间没有直接的联系,我们在做 document selection 的时候其实还是受到 persona 或者 memory 等因素隐性的影响,参考《There Are a Thousand Hamlets in a Thousand People’s Eyes: Enhancing Knowledge-grounded Dialogue with Personal Memory》[2]。
总的来说,我们首先构建了将近 3k 多条多轮对话,在一个多轮对话包括三个不同的场景:1)不使用任何外部知识;2)仅使用 persona knowledge source;3)既使用 persona 又使用 documents(这里 persona 和 document 存在依赖关系)。为了同时建模这三种场景,我们提出一个框架 SAFARI,将外部知识选择和回复生成进行解耦。具体来说我们将整个对话回复生成解耦成三个任务,1)Planning:规划是否需要使用知识,何时使用知识,以及多种知识库之间的调用顺序;2)Retrieval:使用外部的 retriever 对上一步规划使用的知识库按顺序抽取对应的 Top-n 的辅助文档;3)Assembling:将对话上下文和中间抽取到的辅助文档拼接在一起进行最终的回复生成。我们同时研究了在 supervised 和 unsupervised 两种设定下 SAFARI 的实现方式,并且评估了三种不同 LLM 的表现(BELLE,ChatGLM 和 ChatGPT)。
Supervised SAFARI:我们将整个过程建模成一个序列生成任务,整体思想类似于 ReWOO+ToolkenGPT 的结合体,但是限于匿名期,我们没有及时的披露。具体来说,我们将不同的 source(不使用任何 source 视为 NULL)作为 special tokens 加入到大模型的词表里面,然后要求大模型输出一个 source 序列,代表不同 source 一个调用顺序,如下图所示,然后我们将对应 source 的 ground-truth 辅助文档和对话上下文,输出的 source 作为输入,要求大模型输出最终的模型,以这种形式,我们只需要将 loss 加在 source 训练和最终的回复上即可进行端到端的训练。推理的时候需要进行两步推理,和以上介绍的类似,不再赘述。Unsupervised SAFARI:给定一些 demostrations,我们直接使用 prompt 来要求大模型输出我们需要的内容,比如第一步要求大模型直接输出 source 序列,第二步根据对话上下文和中间辅助文档生成对应的回复。prompt 如图所示: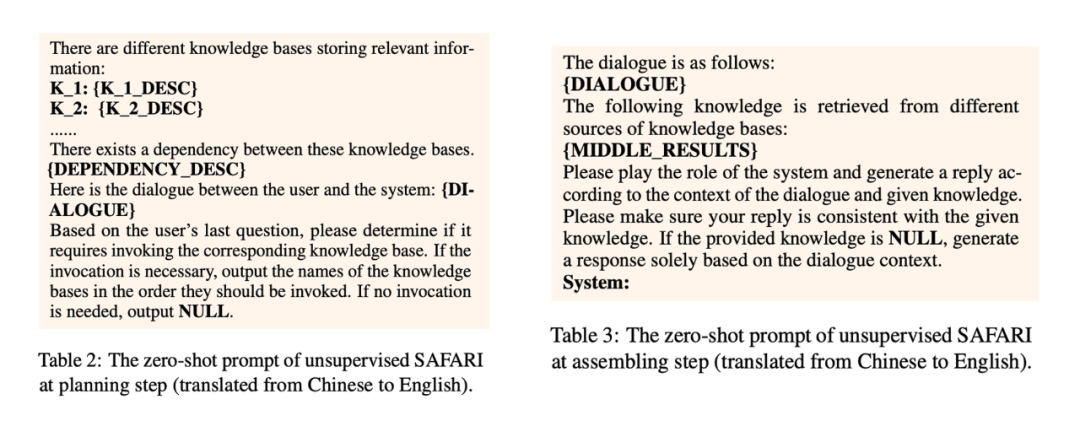
我们详细对比了不同的大模型在两种设定下的表现,首先我们看 planning 的表现,如下图所示,整体而言经过训练的大模型能够取得比 unsupervised 更好的效果(LoRA 微调),但是在 NULL 和 Persona 的效果仍然不是很理想,这可能和我们的数据分布比较相关。在 unsupervised 的设定下,我们发现 zero-shot 情况下 BELLE 和 ChatGLM 通常表现出过度自信(大部分都选择不使用任何知识),而 ChatGPT 就好很多,但是也仍然无法理解多个 source 之间存在 dependency 的情况,很多 cases 下仅仅选择使用 Documents,In-context learning 无法带来明显的增益,这一方面是由于我们使用的是随机选择的 3 个案例作为 demostrations,另一方面 in-context learning 在解决大模型的 uncertainy 上似乎也不是一个有效方案 [3]。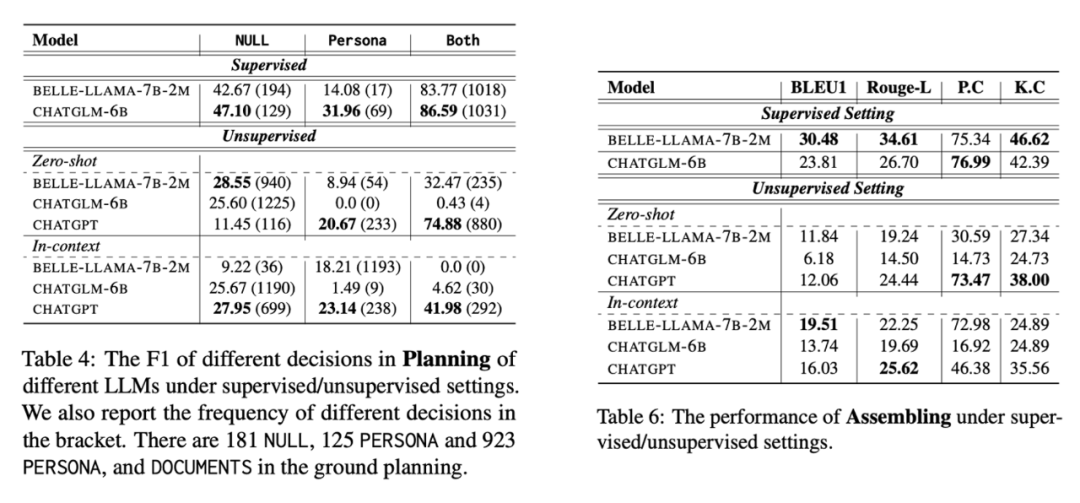
然后我们看 Assmbling 的表现,由于这里的 Assemling 非常依赖上面的 planning 的结果,所以需要结合起来进行分析。经过训练的模型往往能取得更好的效果,尤其是在 BLEU1 和 RougeL上,然后在 unsupervised 下,Zero-shot ChatGPT 的效果都是最好的,而 In-context learning 的时候 BELLE 是最好的,这是由于 In-context learning 的 BELLE 在进行 planning 的时候选择了大量的 Persona,所以导致会使用更多的辅助文档,相较于 In-context ChatGPT 而言,从而取得更好的效果。其他消融分析和实验结果可以参考原文,我们还对比了不同的 source 策略的效果,比如无脑选择使用所有 source,无脑使用 Persona 等等。我们相信 SAFARI 框架还有这巨大的潜力等待挖掘,也可以用来处理现实生活中更加复杂的场景,但受限于时间和 benchmark 的缺乏,我们没有做更进一步的验证,我们也欢迎感兴趣的同学或者老师一起合作交流。
写在最后
本文探讨了一种以内外的视角去看待大模型时代下的对话系统,我们也关注内外合并,并做了简单的初步探索,欢迎大家关注我们的下一篇文章。总的来说,我们认为对话上下文中蕴含的丰富的内部信息 + 外部知识调用将会是未来 LLM-based 对话系统的重要研究方向,尤其是在与不同的 Source,不同的 Task 上的交互从而带来的不同应用场景和设计。Stay Tuned!!
[1] https://arxiv.org/abs/2309.16090.pdf
[2] https://aclanthology.org/2022.acl-long.270.pdf
[3] https://arxiv.org/abs/2305.13712.pdf


如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
