PCIe是一种高速串行计算机扩展总线标准,与SATA相比,具有很多改进的地方,比如更高的最大系统总线吞吐量,较少的IO引脚数,更小的物理占位面积和更好的总线设备性能扩展。PCIe总线是高速差分总线,采用端对端的数据传输方式。随着PCIe技术不断发展与进步,目前市场上应用最多的还是2015年发布的PCIe Gen3。在2017年6月份的时候,PCIe Gen4已经发布,市场上目前也可以买到Gen4的固态硬盘了。在2019年的时候,Gen5也正是发布,速度更是达到128GB/s, 性能越来越强劲。不过,目前Gen5 SSD还没规模上市,大家还需要在耐心等待下。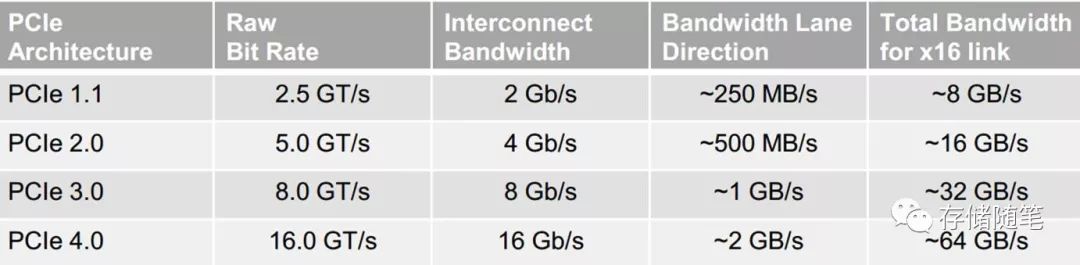
在上图中有一个栏位,名称叫做Raw Bit Rate,翻译过来就是原始比特率。那么,这个原始比特率(RBR)与真实的数据传输速度之间是什么关系呢?有什么区别?这就是我们本篇文章想要思索的问题。一、数据传输速率定义
在PCIe总线中,事务传输类型有四种,Memory,IO,Configuration,Message,如下图。
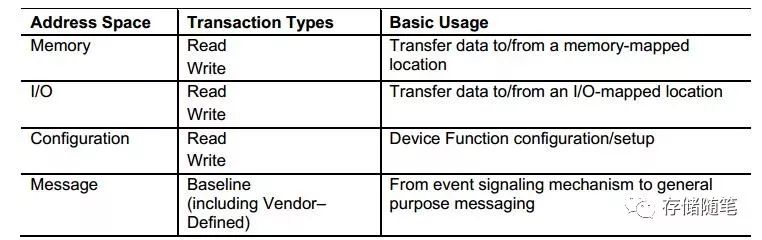
不过,PCIe系统针对传输速率的优化都主要集中提高Memory类型事务的传输速率,所以,我们在这里提到的传输速率,主要是Memory data的传输速率。本文主要以理论分析为主,内容仍然以主流的Gen3为主,Gen4/5可以作为参考。PCIe Spec定义Gen1的最大传输速率是2.5Gb/s, Gen2的最大传输速率是5.0Gb/s, Gen3的最大传输速率是8.0Gb/s. 在这里的最大传输速率指的是单lane单向的原始比特传输速率(Raw bit rate), 并不是PCIe系统中真正的数据传输速率。因为在PCIe系统存在一定的数据传输开销和设计取舍。二、数据传输开销
任何数据在PCIe系统传输,都会产生一定的开销。我们从以下五个方面探究一下:
(1) 数据编码: Gen1/2 8b/10b & Gen3 128b/130bGen1/Gen2采用8b/10b编码,直观的理解,就是把8bit数据转换为10bit数据传输,目的就是维持"直流平衡(DC Balance)",让1和0传输数目相等。因为高速串行传输过程中,如果有连续多位1或者0没有变化,那么,信号传输就会由于电压位阶的关系而发生错误。Gen1/Gen2采用8b/10b编码进行数据传输,就相当于多了20%左右的传输开销。同理,Gen3采用了128b/130b编码传输,就等于多了2%左右的开销。PCIe属于封装分层协议,数据报文在Device Core产生之后,在分别经过事务层(Transaction Layer)、数据链路层(Data Link Layer)、物理层(Physical Layer)之后会依次被增加ECRC,Sequence Number,LCRC,Start,END等数据块。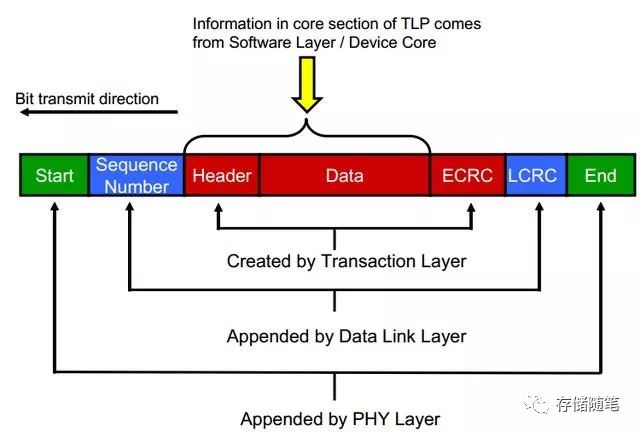
不过,需要注意的是,Gen1和Gen2有End标识符,Gen3则没有End标识符。

TLP header有两种选择12 bytes或者16bytes,主要与Memory Read/Write TLP中采用32位地址或者64位地址有关。如果采用32位地址,那么TLP Header的长度是12bytes: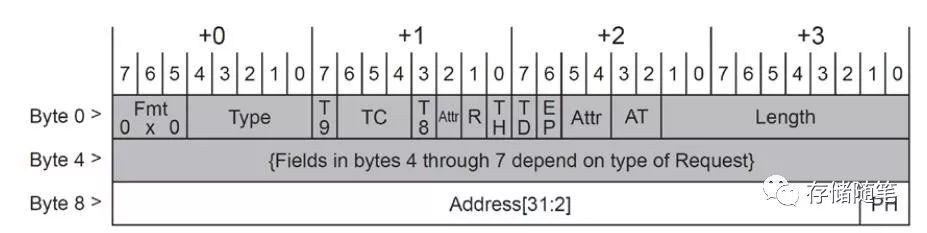
如果采用64位地址,那么TLP Header的长度是16bytes: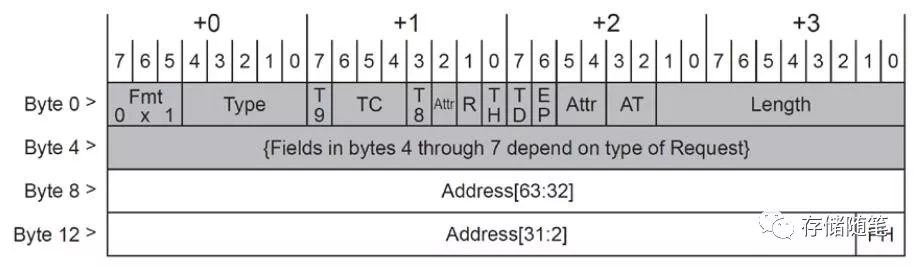
所以,在TLP传输过程中,就增加了20~30 Bytes的开销。(3) 流量开销(Traffic Overhead)在数据链路层(Data link layer)和物理层(Physical Layer)都会引入流量开销(Traffic Overhead). 数据链路层在PCIe总线中的作用就是保证来自事务层TLPs的正确传输。为了实现这一目的,数据链路层又定义了DLLP(Data Link Layer Packets)。DLLP产生于数据链路层,终止于数据链路层。定义的DLLP数据类型主要有Ack, Nak, PM,FC等,如下图。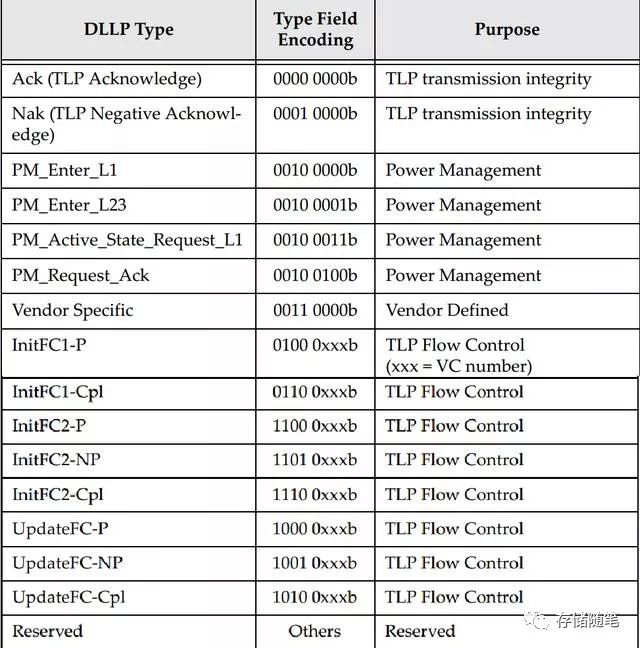
在PCIe Link达到正常的工作状态(L0)之后,如果两个交互port口之间存在延时,那么这个时候就需要物理层插入SKP Order sets来补偿PCIe链路中的延时。对于Gen1/Gen2, SKP OS的大小为4 Bytes;对于Gen3, SKP OS的大小一般为16 Bytes. PCIe Spec规定,在TLP传输过程中,不允许插入Order Sets,SKP OS只能在TLP传输间隙进行。所以,Ack/Nak/PM/FC等DLLP和Order Sets也都会影响到数据传输的速率。PCIe Spec规定,发送端发送TLP之后,需要接受端回应Ack或者Nak, 以得知发送的TLP是否被成功接收。发送端需要将TLP保存在TLP retry buffer中,直到收到Ack成功接收的回应。如果不幸的收到了Nak未成功接收的回应,那也不怕,只要将放在TLP retry buffer中的TLP再次发送,直到被正确接收。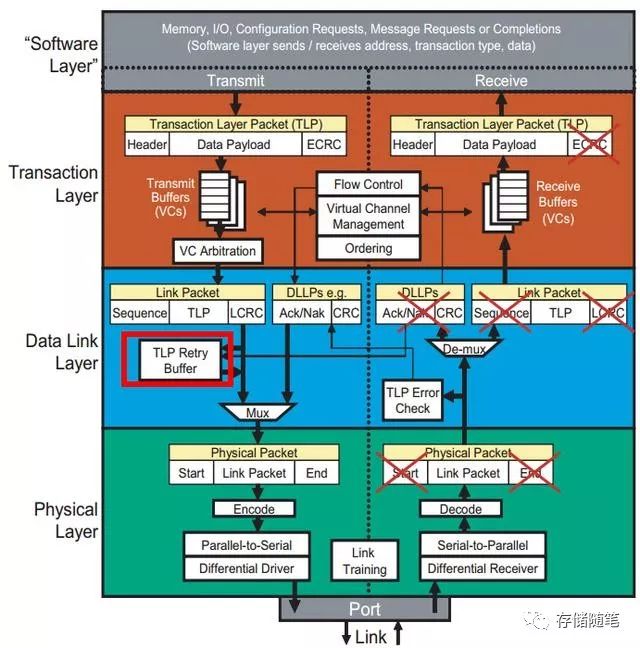
如果发送每个TLP之后,都要求对应一个Ack回应,那么,当发送多个TLP时,就需要对应多个Ack回应,这样的话,会严重的增加PCIe链路中的数据传输开销。为了减少这方面的开销,PCIe Spec允许发送多个TLP后,有一个Ack回应就可以。如下图,发送5个TLP,收到一个Ack回应。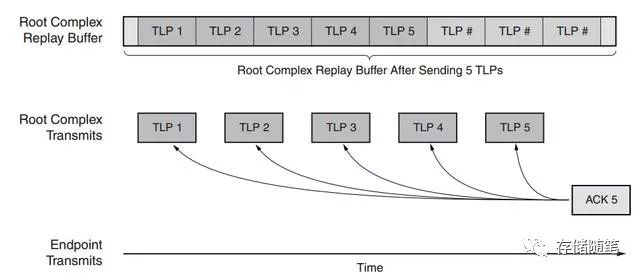
此外,之前PCIe专题的介绍中,我们提到过PCIe中总线事务有两大类:Non-Posted和Posted:- Non-Posted: 需要completion返回响应包;
- Posted: 不需要completion返回响应包.
当我们发送一个Non-Posted Memory Read TLP之后,就需要等待Completion TLP回应。这个过程也会增加数据传输的延时。(5) 流量控制(Flow Control)机制的开销在PCIe链路中,我们不能一直发送TLP,而是需要接受端有足够的接受空间之后,才能继续发送TLP,这个过程就是PCIe协议中的流量控制(Flow Control)机制。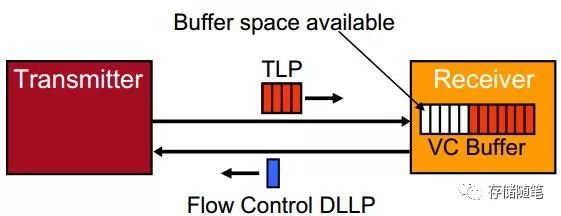
接收端会通过不断地发送FC DLLP来告知发送端,此时接收端可用Buffer的大小。如果接收端的Buffer快满时,发送端就会停止发送TLP,这样做的目的就是防止Buffer空间不足而造成TLP被丢弃。所以,接收端可用Buffer的大小很大程度上也会影响着数据传输速率。三、系统参数对传输速率的影响
除了上面提到的协议和流量开销外,对传输速率也有一定影响的因素就是系统参数,比如MPS(Maximum Payload Size), MRRS(Maximum Read Request Szie), RCB(Read Completion Boundary)等。(1) MPS(Maximum Payload Size)PCIe协议对MPS支持的大小有6种: 128B,256B,512B,1024B,2048B,4096B.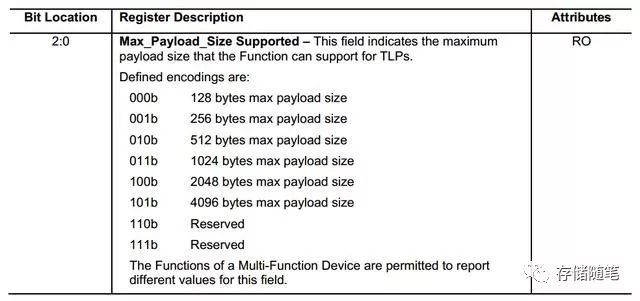
PCIe系统中的最大负载MPS是在上电枚举和配置阶段定义的,以PCIe系统中最小MPS为准。比如,下图,RC,Switch,Endpoint都有不同的MPS设置,那么,就取最小MPS 128 Bytes为准。这个过程,类似水桶原理。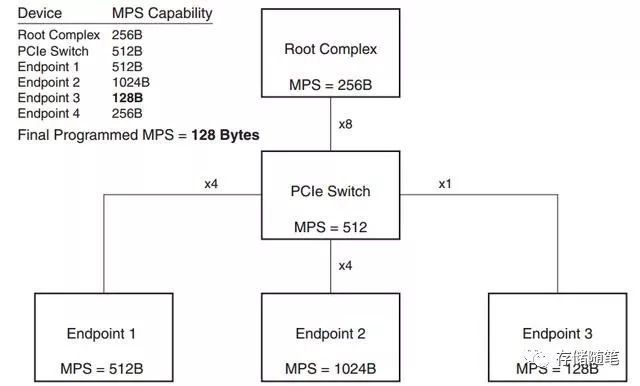
MPS的大小影响着数据传输的效率。数据包传输效率计算公式: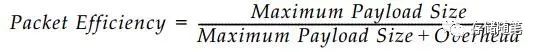
我们假设TLP中的Header大小为12 Bytes, 同时没有ECRC,这样的话,TLP传输就有20bytes的额外开销。那么,不同MPS大小对应的数据包传输效率计算结果如下: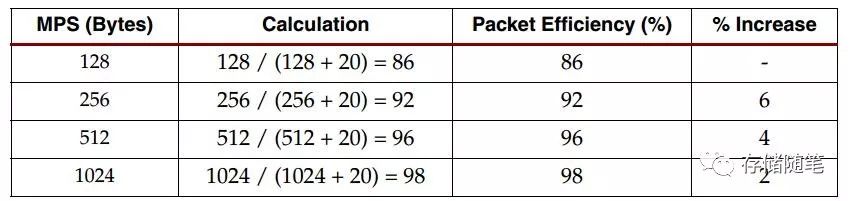
从计算结果来看,随着MPS的增加,数据包的传输效率在增加,但是增幅在变小,作个曲线表示如下: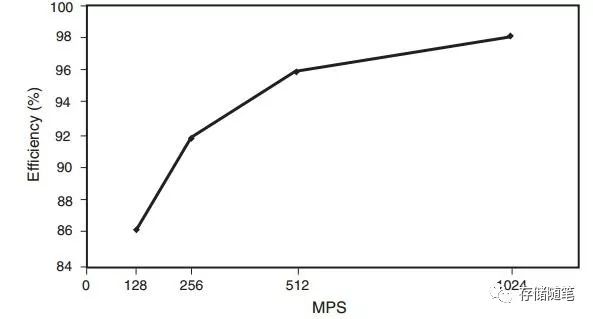
(2) MRRS(Maximum Read Request Size)PCIe协议中,MRRS代表着读请求最大Size,对于MRRS选择,同样有6种:128B,256B,512B,1024B,2048B,4096B. 这个参数也是在Configuration阶段,写入到设备的control寄存器。
由于不携带任何数据,所以每次的读请求都是一笔额外的开销。如果我们设定MRRS为128B,我们读64KB数据时,就需要发送512(64KB/128B=512)次读请求,这样的话,就增加了很多额外的开销,对数据传输速率也是一种伤害。(3) RCB(Read Completion Boundary)在发送一个Non-Posted Memory Read TLP之后,接收端就会通过回应Completion TLP,并返回目标数据。在这个过程汇中,一个Memory Read TLP请求,可能会收到多个Completion TLP。这主要取决一个参数,叫做RCB。RCB是一个限定Read Completion边界的参数,要求64Bytes或者128BBytes地址对齐, 如下图。不过,大多数情况下,RC/Endpoint都是采用64Bytes对齐。
RCB这个参数在哪里设定呢? 众里寻他千百度,蓦然回首,它就在Link Control Register Bit[3],如下图.举个RCB=64 Bytes的例子: 从地址0x10028开始读取256B数据。由于Root Complex要求以64Bytes对齐,第一笔数据读取的时候只读到24Bytes, 之后三笔数据大小为64Bytes, 最后一笔数据读到40Bytes. 在这里,用5笔Completion TLP完成了Memory Read TLP 256B数据的请求。单笔64B数据包的传输效率=64B/(64B+20B)=76%. 所以,多笔Completion TLP会造成数据传输效率降低。
四、写入吞吐量(Write Throughput)计算方式
假设Write TLP的数量是50, MPS=512B,PCIe系统是Gen1 x8.我们知道是Gen1,传输速率是2.5Gb/s. 那么,Symbol Time(由于8b/10b编码, 在这里指传输10bit的时间)=10b/2.5Gb/s=4ns.因为是8 lane,那么,每4ns可以发送8Byte数据。在MPS=512B,32bit地址的情况下,Memory Write TLP的传输时间就等于:
[(512B payload+ 20B overhead)/8B/Clock]*4ns/Clock=266 ns.
DLLP的传输时间就等于:
[8B / 8B/Clock] * [4ns/Clock] = 4 ns.
另外,我们在这里假设,每传输5个TLPs, 对应一个Ack DLLP。每传输4个TLPs,有一个FC update DLLP。
传输数据总量(Bytes)=50 posted writes × 512 bytes/posted write = 25,600 bytes.
传输时间=(50 × 266 ns) + (10 × 4 ns) + (13 × 4 ns) = 13,392 ns.
传输带宽=[25,600 bytes / 13,392 ns] = 1.912 GB/s.五、读取吞吐量(Read Throughput)计算方式
假设读取数据量=4096B, MRRS=256B,PCIe系统是Gen1 x8.我们知道是Gen1,传输速率是2.5Gb/s. 那么,
Symbol Time(由于8b/10b编码, 在这里指传输10bit的时间)=10b/2.5Gb/s=4ns.
因为是8 lane,那么,每4ns可以发送8Byte数据。在32bit地址的情况下,Memory Read TLP的传输时间等于:
[20B overhead/8B/Clock]*4ns/Clock=10 ns.
DLLP的传输时间就等于:
[8B / 8B/Clock] * [4ns/Clock] = 4 ns.
假设RCB(Read Completion Boundary)=64 Bytes,所以,多数的Completion TLP都是64B大小。
Memory Read Completion TLP传输时间等于:
[(64 bytes payload + 20 bytes overhead) / 8 bytes/clock] × [4 ns/clock] = 42 ns.
另外,我们在这里假设,每传输5个TLPs, 对应一个Ack DLLP。每传输4个TLPs,有一个FC update DLLP. 从发送Read请求,到Completion产生的时间为300ns.传输数据总量(Bytes)=4096 bytes.
传输时间=(16 × 10 ns) + (16 × 300 ns) + (64 × 42 ns) + (16 × 4 ns) + (20 × 4 ns) = 7,792 ns.
传输带宽=[4096 bytes / 7,792 ns] = 523 MB/s.
声明: 本文内容参考PCIe Spec, MindShare以及Xilinx White Paper. 非常感谢!
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店资料打包汇总(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击小程序链接获取“架构师技术联盟书店”电子书资料详情。