
Debiasing Graph Neural Networks via Learning Disentangled Causal Substructure论文链接:
http://shichuan.org/doc/140.pdf代码和数据:
https://github.com/BUPT-GAMMA/DisC近日,北邮GAMMA Lab和Mila合作的论文“Debiasing Graph Neural Networks via Learning Disentangled Causal Substructure”被NeurIPS 2022接收。该论文主要试图回答,在偏差信息和因果信息同时存在时图神经网络更倾向于学习哪方面信息?如何从具有严重偏差的图数据中解耦并且利用因果子结构做预测?并且如何有效地从定量以及定性两方面评测因果图神经网络方法?带着这几个问题,我们详细介绍该论文的核心思想与对应技术细节。大多图神经网络 (GNNs) 通过学习输入图和标签之间的相关性来预测不可见图的标签。然而,通过一个在有严重偏差训练图上的图分类探究实验,惊奇的发现,即使因果相关性一直存在,GNN还是更倾向于利用虚假相关性做预测。这意味着目前在这样有偏差数据上训练得到的图神经网络具有很差的泛化性能。通过以因果视角分析该问题,可以发现解耦和去相关因果和偏差隐变量对于去偏差是至关重要的。受启发于此,我们提出了一个通用的图神经网络解耦框架以学习因果和偏差子结构。具体而言, 我们设计了一个参数化的边掩码生成器来显示的将输入图划分为因果和偏差子图。然后训练两个由因果/偏差感知损失函数监督的GNN模块以编码因果和偏差子图的信息到对应的表示中。给定了解耦的表示,我们合成反事实无偏样本以进一步去除因果和偏差变量之间的相关性。此外, 为了更好地基准测试严重偏差问题,我们构造三个新的数据集, 其有偏差可控制并且易于可视化和解释的特点。实验结果很好的证明了我们提出的方法比现有基线方法有优越的泛化性能。此外,由于学到的边掩码,提出的方法有吸引人的可解释性和可迁移性。
引言
图神经网络在各种应用的图数据上表现出强大的性能。一大类应用是图分类任务,如分子图属性预测,超像素图分类,社交网络类别分类。众所周知,图分类通常由相关子结构决定,而不是整个图结构。例如,对于MNIST超像素图分类任务,数字子图对于标签是因果(决定性)关系;分子图的诱变特性取决于官能团(比如,二氧化氮)而不是不相关的模式(比如,碳环)。因此,识别因果子结构以做出正确预测是图神经网络基本要求。理想情况下,当图是无偏的,即只有因果子结构与图标签相关时,图神经网络能够利用这种子结构来预测标签。然而,由于不可控的数据收集过程,图不可避免地存在偏差,即现有的无意义子结构与标签虚假相关。以彩色手写数字体(Colored MNIST)超像素图数据集为例(如图1),每一类数字子图主要对应一种颜色背景子图,比如,数字0子图与红色背景子图相关。因此,颜色背景子图将被视为偏差信息,它与标签高度相关,但在训练集中并不能决定标签。在这种情况下,图神经网络还会稳定地利用因果子结构来做出决策吗?▲ 图1. CMNIST-75sp中图数据的例子和图神经网络在这个数据上的性能
为了研究偏差对图神经网络的影响,进行了一项实验研究,以证明偏差(尤其是在严重偏差场景中)对图神经网络泛化能力的影响。发现图神经网路实际上同时利用了偏差和因果子结构来进行预测。然而,随着偏差相关性变得更严重,即使偏差子结构仍然不能像因果子结构那样准确地确定标签,图神经网络还是主要利用偏差子结构作为捷径进行预测,导致泛化性能大幅下降。为什么会发生这种情况?使用因果图分析图分类背后的数据生成过程和模型预测机制。因果图说明观察到的图是由因果和偏差潜在变量生成的,现有的图神经网络无法从耦合的图中区分因果子结构。如何从观察到的图中解耦出因果子结构和偏差子结构,以便图神经网络在出现严重偏差时扔然能利用因果子结构进行稳定预测?1. 如何识别严重偏差图中的因果子结构和偏差子结构?在严重的偏差场景中,偏差子结构对于图神经网络将“更容易学习”并最终主导预测。使用正常的交叉熵损失,如DIR中所用的损失,无法完全捕捉到这种激进的偏差属性。2. 如何从耦合图中提取因果子结构?统计因果子结构通常由整个图群的全局属性决定,而不是由单个图决定。在从图中提取因果子结构时,需要建立所有图之间的关系。 在本研究中,通过学习解耦的因果子结构,提出了一种新的图神经网络去偏差框架,称为DisC。给定一个输入的有偏差图,提出通过一个参数化边掩码生成器将边显式过滤为因果子图和偏差子图,掩码器的参数在整个图数据中共享。因此,边掩码器自然能够确定每个边的重要性,并从整个观测的全局视图中提取因果子图和偏差子图。然后,分别使用因果感知(加权交叉熵)损失和偏差感知(广义交叉熵)损失来监督两个功能性图神经网络模块。基于监督,边缘掩码生成器可以生成相应的子图,而图神经网络以将相应的子图编码到它们的解耦表示中。有了解耦的表示之后, 随机排列从不同图中提取的潜在向量,以在嵌入空间中生成更多无偏的反事实样本。新生成的样本仍然包含因果信息和偏差信息,而它们的相关性已经去相关。此时,只有因果变量与标签之间相关性,因此模型可以专注于因果子图和标签之间的真实相关性。构建了三个具有各种属性和可控偏差度的新数据集,可以更好地对新问题进行基准测试。提出的模型大大优于相应的基础模型(平均提高4.47% 到 169.17%)。各种调查研究表明,提出的模型可以发现并利用因果子结构进行预测。

首先通过一个动机实验说明现有的图神经网络倾向于利用偏差子结构作为预测的捷径。然后从因果角度分析图神经网络的预测过程。基于这个因果视角, 它启发了提出的解决方法来减轻偏差的影响。
2.1 动机实验
为了衡量GNN在有偏差情况下的泛化能力,构建了一个具有可控偏差度的图分类数据集,称为 Colored MNIST-75sp。为构建此数据集,首先构建一个有偏差的MNIST图像数据集,其中每个数字类别与其背景中的预定义颜色高度相关。例如,在训练集中,90% 的0数字是红色背景(即有偏样本),其余的10% 图像是随机背景颜色(无偏样本),其偏差在这种情况下,偏差程度记为0.9。考虑四个偏差度 {0.8, 0.85, 0.9, 0.95}。对于测试集,构建了有偏测试集和无偏测试集。有偏差的测试集与训练集具有相同的偏差度,旨在衡量模型依赖偏差的程度。数字标签与背景颜色不相关的无偏测试集旨在测试模型是否可以利用固有的数字信号进行预测。请注意,训练集和测试集具有相同的预定义颜色集。然后,将有偏差的MNIST图像转换为每个图最多75个节点的超像素图,其中边是通过基于超像素的二维坐标的KNN方法构建的,节点特征是坐标和超像素的平均颜色拼接。每个图都由其数字类别打标签,因此其数字子图对于标签是决定性的,而背景子图与标签虚假相关但不是决定性的。图的例子如图1(a)所示。 在Colored MNIST-75sp上运行了三种流行的图神经网络方法:GCN, GIN和GCNII,结果如图1(b)所示。相同颜色的虚线和实线分别代表相应方法在有偏测试集和无偏测试集上的结果。总体而言,图神经网络方法在有偏测试集上的性能要好于无偏测试集。该现象表明,尽管图神经网络仍然可以学习一些因果信号进行预测,但偏差信息也被意外地用于预测。更具体地说,随着偏差度的增大,图神经网络在有偏差的测试集上的性能提高,准确度值几乎与偏差度一致,而在无偏差测试上的性能则急剧下降。因此,尽管因果子结构可以完美地确定标签,但在严重偏差的情况下,图神经网络倾向于利用更容易学习的偏差信息而不是固有的因果信号来进行预测,偏差子结构最终将主导预测。2.2 问题分析
对图神经网络进行无偏预测需要了解图分类任务的自然机制。展示数据生成过程和任务背后的模型预测过程结合的因果关系。通过探究五个变量之间的因果关系将因果视图形式化为结构因果模型 (SCM) 或因果图:未观察到的因果变量,未观察到的偏差变量,观察到的图,图嵌入,标签/预测。图2(a)展示了SCM,其中每个边表示一个因果关系。- 。观察到的图数据由两个未观察到的潜在变量生成:因果变量和偏差变量,例如Colored MNIST-75sp数据集中的数字子图和背景子图。所有下面的关系都由Colored MNIST-75sp说明。
- 。这个箭头意味着因果变量是唯一决定生成真实标签的内生父代节点。例如,是数字子图,这正好解释了为什么标签被标记为。
- 。此链接表明和之间的虚假相关性。这种概率依赖通常是由直接原因或未观察到的混淆因素引起的。这里不区分这些场景,只观察和之间的虚假相关性,例如颜色背景子图和数字子图之间的虚假相关性。
- 。现有的图神经网络通常基于观察到的图 学习图嵌入,并根据学习到的嵌入进行预测。
根据SCM,图神经网络将利用这两种信息进行预测。由于偏差子结构(背景子图)通常比有意义的因果子结构(数字子图)具有更简单的结构,如果图神经网络利用这种简单的子结构,它可以非常快速地实现低损失。因此,当大多数图有偏差时,图神经网络倾向于利用偏差信息。基于图2(a)中的SCM,根据d-分离理论:如果两个变量是依赖的,则它们至少被一条畅通的路径连接,可以找到两条路径会导致偏差变量和标签之间的虚假相关性:1)和 2)。为了使预测与偏差不相关,需要截断这两条连接的路径。为此,提出以因果视角对图神经网络去偏,如图2(b)所示。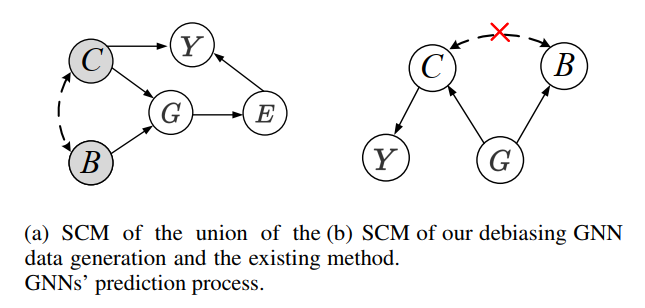
▲ 图2. SCMs, 灰色和白色变量分别代表未观测和观测到的变量
受上述因果分析的启发,在本小节中,呈现提出的去偏图神经网络框架DisC,以消除虚假相关性。整体框架如图3。首先,学习边掩码生成器将原始输入图的边掩码为因果子图和偏差子图。其次,训练两个独立的图神经网络模块及其相应的掩码子图,以分别将相应的因果子结构和偏差子结构编码为解耦的表示。最后,在解耦的表示经过良好训练之后,置换训练图中的偏差表示以生成反事实无偏样本,从而消除因果表示和偏差表示之间的相关性。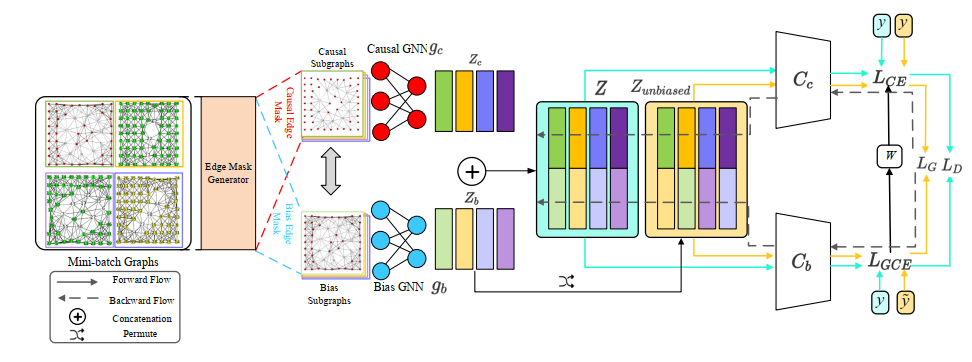
3.1 因果和偏差子结构生成器
给定一个小批量的有偏图数据,核心思想是:设计一个生成概率模型来学习过滤边进入因果子图或偏差子图。具体而言,给定一个图 ,其中是邻接矩阵,是节点特征矩阵,利用多层感知器 (MLP) 连接节点的节点特征 和节点的 来衡量边对于因果子图重要性: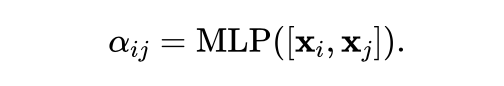
然后用一个sigmoid函数将 投影的(0,1)的区间,其表示了边(i,j)属于因果子图中的概率如下: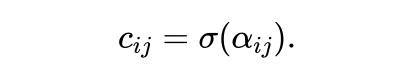
自然地,可以得到边作为偏差子图中边的概率:。现在可以构造因果边掩码和偏差边掩码 。最后,将原始图分解为因果子图和偏差子图 。直观地说,边掩码可以突出原始图结构信息的不同部分,因此建立在不同子图上的图神经网络可以对图信息的不同部分进行编码。1. 全局视图:在单个图级别,掩码生成器 (MLP),其参数由图中所有边共享,对图中所有边进行全局视图,这使得能够在图中识别社区。众所周知,边的效应不能独立判断,因为边通常会相互协作,形成社区,进行预测。因此,以全局视图中评估边至关重要。在整个图总体级别,掩码生成器对训练集中的所有图进行全局视图,这使得能够识别因果/偏差子图。特别地,由于因果/偏差是总体水平的统计信息,因此有必要查看所有图样本以识别因果/偏差子结构。考虑到这种联合效应和总体级别的统计信息,生成器能够更准确地测量边的重要性。2. 泛化性:掩码生成器可以将掩码生成的机制推广到新的图而不需要重新训练,因此它能够有效地修剪未知的图数据。3.2 学习解耦的图表示
给定和,如何确保它们分别是因果子图和偏差子图?提出的方法同时训练了一对图神经网络和线性分类器,如下:1)受第2.1节偏置子结构更容易学习的观察启发,利用偏差感知损失来训练偏差图神经网络和偏差分类器;2)相反,在偏差图神经网络难以学习的图上训练训练因果图神经网络和一个因果分类器。接下来,将详细介绍每个组件。如图3所示,图神经网络和将对应的子图分别嵌入到因果表示和偏置表示,其中 是图神经网络的参数。随后,拼接向量 输入线性分类器和以预测目标标签。为了训练和作为偏差提取器,利用广义交叉熵 (generalized cross entropy, GCE) 损失来放大偏差图神经网络和分类器的偏差:其中和分别是偏差分类器softmax的输出和其属于目标类别的概率, 是分类器的参数。这里是一个控制偏差增大程度的超参。给定,GCE损失的梯度提升了标准交叉熵损失 (cross entropy, CE) 对于可以以很高置信度来预测正确目标类别的样本的权重,如下:因此,与CE损失相比,GCE损失将通过置信度得分放大样本上的梯度。根据观察,偏差信息通常更容易学习,因此有偏差的图将比无偏差的图具有更高的。因此,通过GCE损失训练的模型 和将关注偏差信息,最终得到偏差子图。请注意,为确保主要基于预测目标标, 的损失不会反向传播到,就是仅更新上式中的,反之亦然。同时,还训练了一个因果图神经网络和加权交叉熵损失。与具有低交叉熵损失的样本相比,来自的具有高交叉损失的图可以被视为无偏样本。基于此,可以得到每个图的无偏分数为:值比较大的意味着该图是一个无偏样本,因此可以使用这些权重来重新加权这些图的损失来训练和,强制它们学习无偏信息。因此,学习解耦表示的目标函数是:3.3 反事实无偏样本生成
到目前为止,已经实现了在第2.2节中分析的第一个目标,即解耦因果子结构和偏差子结构。接下来,将展示如何实现第二个目标使因果变量和偏差变量不相关。尽管已经解耦了因果和偏差信息,但是它们是从有偏差的图数据中解耦出来的。因此,从有偏差的观测图中继承的因果变量和偏差变量之间将存在统计相关性。为了进一步去除和之间的相关性,根据数据生成过程的因果关系,t提出通过交换来生成嵌入空间中的反事实无偏样本。更具体地说,在每个批处理中随机置换偏差向量,得到,其中表示的随机置换偏差向量。由于 中的和是从不同的图中随机组合的,因此它们的相关性将远低于两者都来自同一张图的。为了使 和仍然关注偏差信息,还将标签随着一起交换为;以便和的虚假相关性仍然存在。有了生成的无偏样本,利用以下损失函数来训练两个图神经网络模块: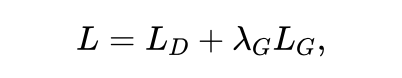
其中 是用于加权生成模块重要性的超参数。此外,使用更多样化的样本进行训练也将对于更好地泛化模型到未见过的测试场景。请注意,由于需要良好解开的表示来生成高质量的无偏样本,因此在训练的早期阶段,只用训练模型。在某些轮次之后,用训练模型。

实验与分析
构建了三个具有不同属性和偏差程度的数据集来对这个新问题进行基准测试,这些数据集具有清晰的因果子图,使得结果可以解释。继第2.1节中介绍的CMNIST-75sp之后,基于Fashion-MNIST和Kuzushiji数据集,使用类似的方式构建CFashion-75sp和CKuzushiji-75sp数据集。由于这两个数据集的因果子图更复杂(时尚产品和平假名字符),它们更具挑战性。这里将偏差度设置为 {0.8, 0.9, 0.95}。在主实验报告了无偏测试集的结果。由于DisC是一个可以构建在各种基本图神经网络模型上的通用框架,因此选择了三个流行的图神经网络:GCN, GIN, 和GCNII。相应的模型分别称为 ,和。4.1 定量评估
与基础模型相比,DisC具有更好的泛化能力。DisC 始终以较大的幅度优于相应的基础模型。在更大偏差时,提出的模型比基础模型实现了更大的提高。具体来说,对于具有较小偏差度(0.8)的CMNIST-75sp,CFashion-75sp和CKuzushiji-75sp,提出的模型比相应的基础模型分别实现了40.02%、4.47%和29.82%的平均提高。令人惊讶的是,在更严重的偏差 (0.9 和 0.95) 下,DisC 在三个数据集上分别比基础模型实现了 169.17%, 14.67% 和 49.35%的平均提高。这表明所提出的方法是一个通用框架,可以帮助现有的图神经网络对抗偏差的负面影响。DisC明显优于现有的去偏方法。我们注意到DIR无法取得令人满意的结果。原因是DIR利用交叉损失来提取偏差信息,在严重偏差情况下无法完全捕捉偏差的属性。并且DIR设置一个固定的阈值划分所有子图是次优的。另外,StableGNN由于其基础模型DiffPool并且得到了有竞争力的结果,体现了其提出的因果变量区分正则化器的有效性。然而,其框架基于原始数据调整分布,当无偏样本稀缺时很难产生无偏分布。DisC可以基于解耦的表示产生更多的无偏样本。此外,LDD是一种通用的去偏方法,不是为图数据设计的。DisC 的平均性能优于相应的LDD变体,平均为 23.15%,表明全局图数据感知边掩码器与去偏解耦框架的无缝结合非常有效。在未知偏差上的鲁棒性:表2报告了DisC与其对应的基础模型在不可见偏差测试集上的结果比较,不可见偏差意思是训练集和测试集的预定义颜色(偏差)集是不相交的。与表1可见偏差场景的结果相比,基础模型的性能进一步下降。然而,提出的模型仍然取得了非常稳定的性能,充分展示了提出的模型在不可知偏差场景下的泛化能力。4.2 定性评估
边掩码可视化:为了更好地说明提取了显着因果子图和偏差子图,将CMNIST-75sp数据集的原始图像,原始图以及对应的因果子图和偏差子图在图4可视化,其中边的宽度表示学习权重或者的值。图4(a)显示了在训练集中见过的偏差(颜色)的测试图的可视化结果。正如所看到的,提出的模型可以发现数字子图中最显着边的因果子图。通过这些突出数字结构信息的因果子图,图神经网络将更容易地提取这些因果信息。图4(b)显示了具有未见偏差的测试图的可视化结果。根据可视化,提出的模型仍然可以发现因果子图轮廓,这表明提出的模型可以识别因果子图,无论偏差是可见还是不可见。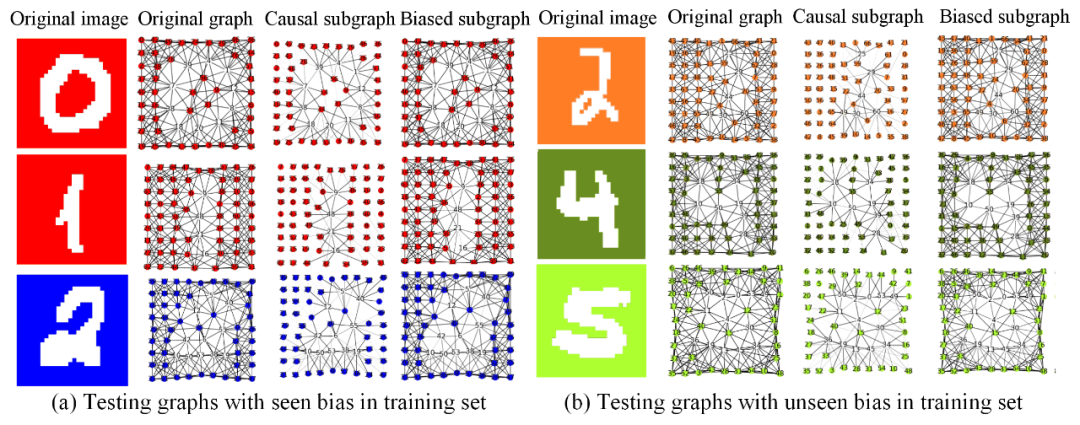
解耦可视化:图5分别显示了的因果图神经网络和偏差图神经网络提取的隐向量和 的投影。图5(a-b) 分别是由目标标签(数字)和偏置标签(颜色)标记的 的投影。图5(c-d)分别是由目标标签和偏差标签标记的的投影。观察到是根据目标标签聚类的,而是根据偏差标签聚类的。在偏置标签下是混乱的,在目标标签下是混合的。结果表明,DisC成功地学习了解耦的因果和偏差表示。
▲ 图5. 解耦可视化
可迁移性:由于提出的模型可以提取与图神经网络无关的子图,因此学习边权重可用于纯化原始的有偏图。这些稀疏子图代表重要的语义信息,可以通用地转移到任何图神经网络。为了验证这一点,通过学习边掩码,并修剪最小的{0%, 20%, 40%, 60%} 权重的边缘,同时保留剩余的边权重。然后在这些加权的修剪后数的据集上训练原始GIN和GCNII。图6是结果的比较,其中虚线表示基础模型在原始偏差图上的结果,实线表示图神经网络在加权修剪后数据集上的性能。结果表明,在修剪后的数据集上训练的图神经网络取得了更好的性能,表明学习到的边掩码具有相当好的可迁移性。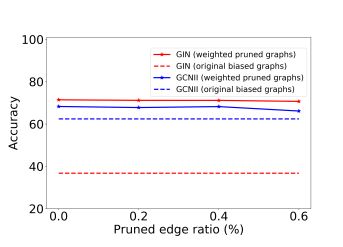

结论
我们首先研究了GNN在严重偏差下的信息利用机制,即更倾向于利用易学习的偏差信息做预测。构建了三个易于控制偏差,易解释和可视化的数据集,并取得了显著的效果。

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
点击「关注」订阅我们的专栏吧
