
说起字符编码,让我想起了科幻巨作《三体-黑暗深林》人类遇到外星文明魔戒的画面卓文用中频电波发送了一个问候语。这是一幅简单的点阵图,图中由六行不同数量的点组成了一个质数数列:1,3,5,7,11,13.太空艇收到了来自“魔戒”的一系列点阵图,第一幅是很整齐的一个8×8点阵,共六十四个点;第二幅图中点阵的一角少了一个点,剩下六十三个;第三幅图中又少一点,剩六十二个……“这是倒计数,也相当于一个进度条,可能表示‘它’已经收到了罗塞塔,正在译解,让我们等侍。”韦斯特说。“使用二进制时一个不大不小的数呗,与十进制的一百差不多。”卓文和关一帆都很庆幸能带韦斯特来,在与未知的智慧体建立交流方面、心理学家确实很有才能。在倒计数达到五十七时,令人激动的事情出现了:下一个计数没有用点阵表示,“魔戒”发来的图片上赫然显示出人类的阿拉伯数字56!
在人类探索外星文明,迈向星辰大海的宇宙征程里,也离不开这种最最基础的编码问题。前一阵跟同事碰到了字符乱码的问题,了解后发现这个问题存在两年了,我们每天都在跟编码打交道,但是大家对字符编码都是一知半解,我们“天天吃猪肉却很少见过猪跑”,今天我们就把它讲讲透。我们知道计算机的世界只有0和1,如果没有字符编码,我们看到的就是一串"110010100101100111001....",我们的沟通就好像是在对牛弹琴,我看不懂它,它看不懂我。字符编码就好比人类和机器之间的翻译程序,把我们熟知的字符文字翻译成机器能读懂的二进制,同时把二进制翻译成我们能看懂的字符。字符编码(Character encoding)也称字集码,是把字符集中的字符,编码为指定集合中的某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储或者通信网络的传递。常见的例子是将拉丁字母表编码成摩斯电码和ASCII,比如ASCII编码是将字母、数字和其它符号进行编号,并用7比特的二进制来表示这个整数。
字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字。
编码(Encode)是信息从一种形式转换为另一种形式的过程,比如用预先规定的方法将字符(文字、数字、符号等)、图像、声音或其它对象转换成规定的电脉冲信号或二进制数字。我们现在看到的一幅幅图画,听到的一首首音乐,甚至我们写的一行行代码,敲下的一个个字符,所看到的所听到的都是那么的真实,但其实在背后都是一串「01」的数字,你昨天在手机上看到的那个心动女孩,真实世界中并不存在,只是计算机用「01」数字帮你生成的“骷髅”而已。你可能认为计算机中的数据就是「01」二进制,但是实际上计算机中并没有二进制,即便我们知道所有的内容都是存储在硬盘中,但是你把它拆开可找不到里面有任何「0101」的数字,里面也只有盘片、磁道。就算我们放大了去看盘片,也只有凹凸不平的盘面,凸起的地方是被磁化过的,凹进去的地方是没有被磁化的;只是我们给凸起的地方取了个名字叫数字「1」,凹进的地方取名叫数字「0」。同样内存里你也找不到二进制数字,内存放大了看就是一堆电容组,内存单元存储的是「0」还是「1」取决于电容是否有电荷,有电荷我们认为他是「1」,无电荷认为他是「0」。但是电容是会放电的,时间一长,代表「1」的电容会放电,代表「0」的电容会吸电,这也是我们内存不能断电的原因,需要定期对电容进行充电,保证「1」的电容电量有电。再说显示器,这个大家感受是最直接的,你透过显示器看到的美女画皮、日月山川,其实就是一个个不同颜色的发光二极管发出强弱不一的光点,显示器就是一群发光二极管组成的矩阵,其中每一个二极管可以被称为一个像素,「1」表示亮,「0」表示灭,而我们平时能看到五彩的颜色,是把三种颜色(红绿蓝三原色)的发光二极管做到了一起。那对于一个ASCII编码「65」最后又怎么显示成「A」的呢?这就是显卡的功劳,显卡中存储了每一个字符的图形数据(也称字形码),将二维矩阵的图形数据传给显示器成像。因此,所谓的0和1都是电流脉冲信号,二进制其实是我们抽象出来的数学逻辑概念,那我们为什么要用二进制表示?因为二进制只有两种状态,使用有两个稳定状态的物理器件就可以表示二进制中的每一位,例如用高低电平或电荷的正负性、灯的亮和灭都可以很方便地用「0」和「1」来表示,这为计算机实现逻辑运算和逻辑判断提供了便利条件。
正因为计算机只能表示「01」的逻辑概念,无法直接表示图片以及文字,所以我们需要一定的转换过程。这其实就是我们按照一定的规则维护了字符-数字的映射关系,比如我们把「A」抽象成计算机中的「1」,当我们看到1的时候就认为这是「A」,本质上就是一张映射表,理论上你可以随意给每个字符分配一个独一无二的编号(character code,字符编码),比如下表接下来我们来看下一个文字从输入-转码存储-输出(显示/打印)的简单流程,首先我们知道计算机是美国人发明的,规则是美国人定的,键盘上的按键也都是英文字母,所以编号不是你想怎么分配就怎么分配。对于英文字母的输入,键盘和ASCII码之间是直接对应的,键盘按键「A」对应的编号「65」,存储到磁盘上也是「65」的二进制直译「01000001」,这很好理解。但是对于汉字输入就不是这么回事了,键盘上可没有汉字对应的输入按键,我们不可能直接敲出汉字字符。于是就有了输入码、机内码、字形码的转换关系,输入码帮助我们把英文键盘按键转换成汉字字符,机内码帮助我们把汉字字符转换成二进制序列,字形码帮助我们把二进制序列输出到显示器成像。输入码
我们模拟下汉字的输入过程,首先打开txt文本敲下「nihao」的拼音字母,然后输入栏会弹出多个符合条件的汉字词组,最后我们会选择相应的编号,就能实现汉字的输入。那这过程又是如何实现的呢?计算机领域有一句如同摩西十诫般的神圣哲言:"计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决"。这里我们再加一层按键字母组合和汉字的映射表,好比英汉字典,这层我们称为输入码,输入码到内码的过程就是一次查表转换操作,比如「nihao」这几个ASCII字符,大家可以随便修改映射表以及候选编号,我可以把他映射成「你好骁飏」。机内码
机内码也称内码,是字符编码最核心的部分,是字符集在计算机中实际存储、交换、通信使用的二进制编码,通过内码我们可以达到高效率的存储、传输文本的目的。我们的外码(输入码)实现了键盘按键和字符的映射转换,但是机内码是让字符真正变成了机器能读懂的二进制语言。字形码
计算机中的字符都是以内码的二进制形式表示,我们怎么把数字对应的字符在显示器上显示出来呢,比如数字「1」代表汉字「你」,怎么把「1」显示成「你」?这就需要依赖字形码,字形码本质上是一个n*n 的像素点阵,把某些位置的像素设置为白色(用 1 表示),其它位置像素设置为黑色(用 0 表示),每一个字符的字形都是预先存放在计算机内,而这样的字形信息库我们称为字库。比如中文「你」的点阵图,这样一个 16*16 的像素矩阵,需要 16 * 16 / 8 = 32 字节的空间来表示,右边的字模信息称为字形码。不同的字库(如宋体、黑体)对同一个字符的字形编码是不同的。所以字符编码到显示的字形码,其实又是另一张查找表,也就是字符编码-字形码的映射关系表。其实我们也可以认为字符编码是字形码的一种压缩方式,一个占32字节的像素点阵压缩成了2字节的机内码。
从广义上来说,编码的历史很悠久,一直可以追溯到结绳记事的远古时期,但跟现代字符编码比较接近的还是摩尔斯电码的发明,自此开启了信息通信时代的大门。摩尔斯电码是由美国人摩尔斯在1837年发明的,比起ASCII还要早100多年,在早期的无线电上作用非常大,它是每个无线电通讯者需必知的,它的是由点dot「.」和划dash「-」这两种符号所组成的,电报中表达为短滴和长嗒,跟二进制一样也是二元码。一个二元肯定不够表示我们的字母,那么就用多个二元来表示,比如嘀嗒「.-」代表字母「A」,嗒嘀嘀嘀「-...」代表字母「B」。计算机一开始发明出来时是用来解决数学计算问题的,后来人们发现,计算机还可以做更多的事,例如文本处理等,那个时候的机器都很大,机器之间都是隔离的,没考虑过机器的通信问题,各大厂商也各干各个的,搞自己的硬件搞自己的软件,想怎么编码就怎么编码。后来机器间需要相互通信的时候,发现在不同计算机上显示出来的字符不一样,在IBM上「00010100」数字代表「A」,跑到微软系统上显示成了「B」,大家就傻眼了。于是美国的标准化组织就跑出来制定了ASCII编码 (American Standard Code for Information Interchange),统一了游戏规则,规定了常用符号用哪些二进制数来表示。统一ASCII 码标准对于英语国家很开心,但是ASCII编码只考虑了英文字母,后来计算机传到欧洲地区,法国人需要加个字母符号(如:é),德国人又需要加几个字母(Ä ä、Ö ö、Ü ü、ß),幸好ASCII只用了前127个编号,于是欧洲人就将ASCII没用完的编码(128-255)为自己特有的符号编码,也能很好的一起玩耍。但是等传到我们中国后,做为博大精深的汉语言就彻底蒙圈了,我们有几万个汉字,255个编号完全不够用啊,所以有了后来的多字节编码… 因此,各个国家都推出了本国语言的编码表,也就有了后来的 ISO 8859 系列、GB系列(GB2312、GBK、GB18030、GB13000)、Big5、EUC-KR、JIS … ,不过为了能在计算机系统中通用,这些扩展的编码均直接或间接兼容 ASCII 码。而微软/IBM这些国际化产商为了把自己的产品卖到全世界,就需要支持各个国家的语言,要在不同的地方采用当地的编码方式,于是他们就把全世界的编码方式都集中到一起并编上号,并且起了个名字叫代码页(Codepage,又称内码表),所以我们有时候也会看到xx代码页来指代某种字符编码,比如在微软系统里 中文GBK编码对应的是936代码页,繁体中文 Big5编码对应的是950代码页。这些既兼容ASCII又互相之间不兼容的字符编码,后来又统称为ANSI编码。看到下面这张图估计大家就很熟悉了,window下面我们基本上都用ANSI编码保存。ANSI的字面意思并非指字符编码,而是美国的一个非营利组织,是美国国家标准学会(American National Standards Institute)的缩写,ANSI这个组织为字符编码做了很多标准制定工作,后来大家习惯把这类混乱的多字节编码叫ANSI编码或者标准代码页。ANSI编码只是一个范称,一般代表系统默认的编码方式,而且并不是确定的某一种编码方式——比如在Window操作系统里,中国区ANSI编码指的是GB编码,在香港地区ANSI编码指的是Big5编码,在韩国ANSI编码指的是EUC-KR编码。由于各个国家各搞各的字符编码,如果有些人想装逼中文里飚两句韩文怎么办呢?不好意思,你的逼级太高,没法支持,你选择了GB2312就只能打出中文字符。同时各大国际厂商在兼容各种字符编码问题上也深受折磨,于是忍无可忍之下,决定开发一套能容纳全世界所有字符的编码,就有了后面大名鼎鼎的Unicode。Unicode也叫万国码,包括字符集、编码方案等,Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,在这种语言环境下,不会再有语言的编码冲突,在同屏下也可以显示任何国家语言的内容,这就是Unicode的最大好处。在Unicode编码方案里常见的有四种编码实现方案UTF-7、 UTF-8、UTF-16、UTF-32,最为知名的就是 UTF-8,不过Unicode设计之初是采用双字节定长编码的UTF-16,但是发现历史包袱太重推不动,最后出了个变长的UTF-8才被广泛接受。

在传统字符编码模型中,基本上都是将字符集里的字符用十进制进行逐一的编号,然后把十进制编号直接转成对应的二进制码,可以说该字符编号就是字符的编码。计算机在处理字符与数字的转换关系上其实就是查找映射表的过程。像ASCII编码就是给每个英文字符编一个独一无二的数字,整个编码处理过程相对还是比较简单的,计算机内部直接就映射成了二进制,十进制的编号只是方便我们看的。Unicode编码模型采用了一个全新的编码思路,将编码模型划分为4 个层次,也有说5个层次的,不过第五层是传输层的编码适配,放在编码模型里严格来说不是很恰当。第一层,抽象字符集 ACR(Abstract Character Repertoire):定义抽象字符集合,明确各个抽象字符;
第二层,编号字符集 CCS(Coded Character Set):将抽象字符集进行数字编号
第三层,字符编码方式 CEF(Character Encoding Form):将字符编号编码为逻辑上的码元序列
第四层,字符编码方案 CES(Character Encoding Scheme):将逻辑上的码元序列编码为物理字节序列
第一层:抽象字符集 ACR
所谓抽象字符集,就是抽象字符的合集,是一个无序集合,这里强调了字符是抽象的,也就是不仅包括我们视觉上能看到的狭义字符,比如「a」这样的有形字符,也包括一些我们看不到的无形字符,比如一些控制字符「DELETE」、「NULL」等。抽象的另一层含义是有些字形是由多个字符组合成的,比如西班牙语的 「ñ」 由「n」和「~」两个字符组成,这一点上 Unicode 和传统编码标准不同,传统编码标准多是将 ñ 视作一个独立的字符,而 Unicode 中将其视为两个字符的组合。同时一个字符也可能会有多种视觉上的字形表示,比如一个汉字有楷、行、草、隶等多种形体,这些都视为同一个抽象字符(即字符集编码是对字符而非字形编码),如何显示是字形库的事。抽象字符集有开放与封闭之分。开放的字符集指还会不断新增字符的字符集,封闭字符集是指不会新增字符的字符集。比如ASCII就是封闭式的,只有128个字符,以后也不会再加,但是Unicode是开放式的,会不断往里加新字符的,已经从最初的 7163 个增加到现在的144,697 个字符。第二层:编号字符集 CCS
编号字符集就是对抽象字符集里的每个字符进行编号,映射到一个非负整数的集合;编号一般用方便人类阅读的十进制、十六进制来表示,比如「A」字符编号「65」,「B」字符编号是「66」;大家需要清楚对于有些字符编码的编号就是存储的二进制序列,如ASCII编码;有些字符编码的编号跟存储的二进制序列并不一样,比如GB2312、Unicode等。另外,编号字符集合是有范围限制的,比如ASCII字符集范围是0~127,ISO-8859-1范围是0~256,而GB2312是用一个94*94的二维矩阵空间来表示,Unicode是用Plane平面空间的概念来表示,这称为字符集的编号空间。编号空间中的一个位置称为码点( Code Point 代码点 )。一个字符占用的码点所在的坐标(非负整数值对)或所代表的非负整数值,就是该字符的码值(码点编号)。第三层:字符编码方式 CEF
抽象字符集和编号字符集是站在方便我们理解的角度来看的,所以最后我们需要翻译成计算机能懂的语言,将十进制的编号转换成二进制的形式。因此字符编码方式就是将字符集的码点编号,转换成二进制码元序列( Code Unit Sequence )的过程。码元:字符编码的最小处理单元,比如ASCII一个字符等于一个字节,属于单字节码元;UTF-16一个字符等于两个字节,处理过程是按字「word」来处理,所以是双字节码元;UTF-8是多字节编码,有单字节字符,也有多字节字符,每次处理是按单个单个字节解析处理,所以处理最小单位是字节,也属于单字节码元
这里大家可能会有疑问,十进制直接转二进制不就好了吗,为什么要单独抽出这么一层?早期的字符编码确实也是这么处理的,十进制和二进制之间是直接转换过去的,比如ASCII码,字符「A」的十进制是「65」,那对应的二进制就是「1000001」,同时存储到硬盘里的也是这个二进制,所以那时候的编码比较简单。随着后来多字节字符编码(Muilti-Bytes Character Set,MBCS多字节字符集)的出现,字符编号和二进制之间不是直接转换过去的,比如GB2312编码,「万」字的区位编号是「45,82」,对应的二进制机内码却是「1100 1101 1111 0010」(其十进制是「205,242」)。如果这里不转换直接映射成二进制码会出什么问题呢?「万」字的字符编号「45,82」,45在ASCII里是「-」,82是「U」,那到底是显示两个字符「-U」还是显示一个字符「万」字,为了避免这种冲突 所以增加了前缀处理,详细的过程会在下文具体来讲解。第四层:字符编码方案 CES
字符编码方案也称作“序列化格式“( Serialization Format ),指的是将字符编号进行编码之后的码元序列映射为字节序列(即字节流)的形式,以便经过编码后的字符能在计算机中进行处理、存储和传输。字符编码方式CEF有点像我们数据库结构设计里的逻辑设计,而这一层编码方案CES就像是物理设计了,将码元序列映射为跟特定的计算机系统平台相关的物理意义上的二进制过程。这里大家可能又会有疑问,为什么二进制的码元序列和实际存储的二进制又会不一样呢?这主要是计算机的大小端序造成的,具体端序内容会在UTF-16编码部分详细介绍。大小端序名词出自Jonathan Swift的《格列夫游记》一书 :所有人都认为,吃鸡蛋前,原始的方法是打破鸡蛋较大的一端。可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋时碰巧将一个手指弄破了,因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令者重罚。
老百姓们对这项命令极为反感。历史告诉我们,由此曾发生过六次叛乱,其中一个皇帝送了命,另一个丢了王位…关于这一争端,曾出版过几百本大部著作,不过大端派的书一直是受禁的,法律也规定该派的任何人不得做官。
很久以前,计算机制造商都是按各自的方式来将字符渲染到屏幕上,当时的计算机动不动可就是一套房子的大小,这家伙可不是谁都能玩的起的,那时人们并不关心计算机如何交流。随着上世纪七八十年代微处理器的出现,计算机变得越来越小,个人计算机开始进入大众的视线,随后出现了井喷式的发展,但是之前厂商都是各自为政,没考虑过自家的产品要兼容别人家的东西,导致在不同计算机体系间的数据转换变得十分蛋疼,因此美国的标准协会在1967年制定出了ASCII编码,到目前为止共定义了128个字符。ASCII 编码(注意该表是列表示字节高 4 位)其中前 32 个(0~31)是不可见的控制字符,32~126 是可见字符,127 是 DELETE 命令(键盘上的 DEL 键)。其实早在ASCII之前,IBM在1963年也推出过一套字符编码系统EBCDIC,跟ASCII码一样囊括了控制字符、数字、常用标点、大小写英文字母。
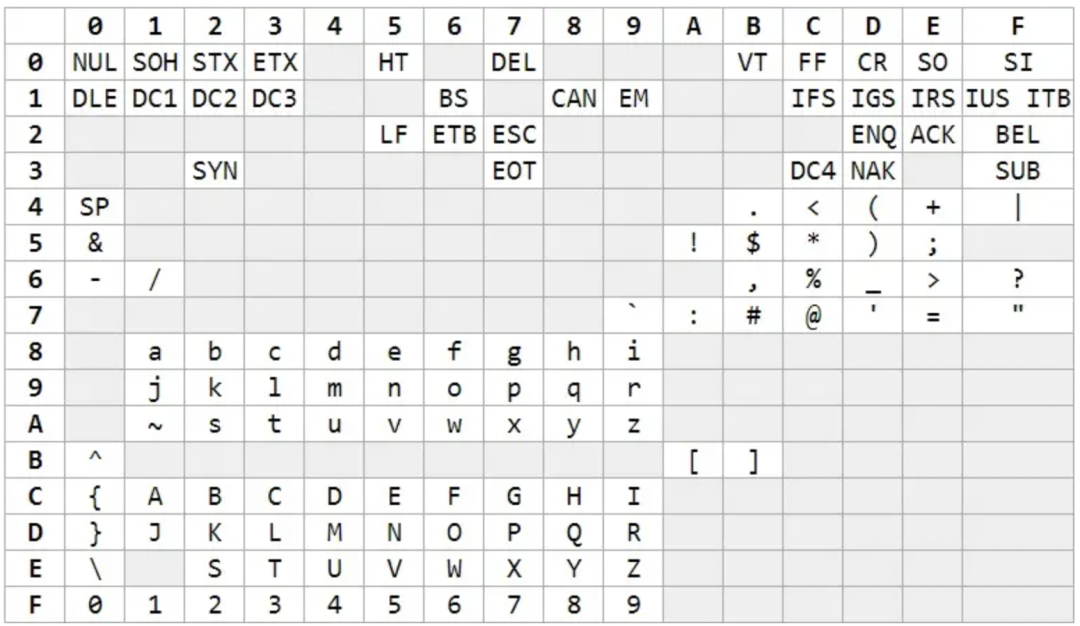
但是他的字符编号并不是连续的,这给后续程序处理带来了麻烦,后来ASCII 编码吸取了 EBCDIC 的经验教训,给英文单词分配了连续的编码,方便程序处理,因此被后来广泛接受。ASCII 和 EBCDIC 编码相比,除了字符连续排列之外,最大的优点是ASCII 只用了一个字节的低 7 位,最高位永远是 0。可别小看了这个最高位的 0,看似无足轻重,但这是ASCII设计最成功的地方,后面介绍各编码原理的时候你会发现,正是因为这个高位0,其它编码规范才能对 ASCII 码无缝兼容,使得 ASCII 被广泛接受。美国市场虽然统一了字符编码,但是计算机制造商在进入欧洲市场的时候又遇到了麻烦,欧洲的主流语言虽然也是用拉丁字母,但却存在很多扩展体,比如法语的「é」,挪威语中的「Å」,都无法用 ASCII 表示。但是大家发现ASCII后面的128个还没有被使用可以利用起来,这对于欧洲主流语言就足够了。于是就有了大家所熟知的这个ISO-8859-1(Latin-1),它只是扩展了ASCII后128个字符,还是属于单字节编码;同时为了兼容原先的 ASCII码,当最高位是0的时候仍然表示原先的 ASCII 字符不变,当最高位是1的时候表示扩展的欧洲字符。但是到这里还没有完,刚说了这只是欧洲主流的语言,但主流语言里没有法语使用的 œ、Œ、Ÿ 三个字母,也没有芬兰语使用的 Š、š、Ž、ž ,而单字节编码里的256个码点都被用完了,于是就出现了更多的变种 ISO-8859-2/3/.../16 系列,他们都兼容 ASCII,但彼此间又不完全兼容。ISO8859-1 字符集,也就是 Latin-1,是西欧常用字符,包括德法两国的字母。
ISO8859-2 字符集,也称为 Latin-2,收集了东欧字符。ISO8859-3 字符集,也称为 Latin-3,收集了南欧字符。ISO8859-4 字符集,也称为 Latin-4,收集了北欧字符。ISO8859-5 字符集,也称为 Cyrillic,收集了斯拉夫语系字符。ISO8859-6 字符集,也称为 Arabic,收集了阿拉伯语系字符。ISO8859-7 字符集,也称为 Greek,收集了希腊字符。
当计算机进入东亚国家的时候,厂商们更傻眼了,美国和欧洲国家语言基本都是表音字符,一个字节就足够用了,但亚洲国家有不少是表意字符,字符个数动辄几万十几万的,一个字节完全不够用,所以我们国家有关部门按照ISO规范设计了GB2312双字节编码,但是GB2312是一个封闭字符集,只收录了常用字符总共也就7000多个字符,因此为了扩充更多的字符包括一些生僻字,才有了之后的GBK、GB18030、GB13000(“GB” 为 “国标” 的汉语拼音首字母缩写)。按照 GB 系列编码方案,在一段文本中,如果一个字节是 0~127,那么这个字节的含义与 ASCII 编码相同,否则,这个字节和下一个字节共同组成汉字(或是 GB 编码定义的其他字符),所以GB系列都是兼容ASCII编码的。GB2312
GB2312是使用两个字节来表示汉字的编码标准,共收入汉字6763个和非汉字图形字符682个,为了避免与 ASCII 字符编码(0~127)相冲突,规定表示一个汉字的编码字节其值必须大于127(即字节的最高位为 1 ),并且必须是两个大于 127 的字节连在一起来共同表示一个汉字( GB2312 为双字节编码),所以GB2312 属于变长编码,当是英文字符的时候占一个字节,中文字符的时候占两个字节,可以认为 GB2312是对 ASCII 的中文扩展。GB2312字符集编号空间是一个94*94的二维表,行表示区(高位字节),列表示位(低位字节),每区有94个位,每个区位对应一个字符,称为区位码。区位码上加2020H,就得到国标码,国标码上加8080H,就得到常用的计算机机内码。这里引入了区位码、国标码、机内码概念,下面我们说下三者的关系国标码
国标码是我国汉字信息交换的标准编码,规定由4位16进制数组成,用两个低7位字节表示,为了避开 ASCII 字符中的前32个控制指令字符,所以每个字节都是从第33个编号开始,如下图所示区位码
由于上述国标码的16进制可编码区不够直观不方便我们使用,所以我们把他映射成了十进制的94*94二维表编号空间,我们称之为区位码,同时区位码也可以当成一种外码使用,输入法可以直接切换成区位码进行汉字输入,不过这种输入法无规则可言 人们很难记住区位编号,用的人也不多了。下图是区位码的二维表,比如「万」字是45 区 82 位,所以「万」 字的区位码是「45,82」。- 01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
- 16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
- 56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
机内码
GB2312国标码规范是覆盖掉ASCII中可见部分的符号和英文字母,使用两个7位码将其中的英文字母和符号重新编入,但是这样产生一个弊端,早期用ASCII码编码的英文文章无法打开,一打开就是乱码,也就是说应该要兼容早期ASCII码而不是覆盖它,后来微软为了解决这个问题,将字节的最高位设为1,因为ASCII中使用7位,最高位为0,转换后的编码称为机内码(内码),这种方式本质上是修改了GB2312的编码标准,最后被大家接受沿用。总结下三者转换关系:区位码 ---> 区码和位码分别 + 32(即 + 20H )得到国标码 ---> 再分别 + 128(即 + 80H)得到机内码(与 ACSII 码不再冲突)GBK
GBK即“国标扩展”的意思,因为GB2312双字节的最高位都要求大于1,上限也不会超过1万个字符,所以对此进行了扩展,对GB2312的字符不重新编码直接沿用,因此完全兼容GB2312。GBK虽然也是双字节编码,但是只要求第一个字节大于 127 就固定表示这是一个汉字的开始,正因为如此,GBK的编码空间比GB2312大很多。GBK 整体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线,总计 23940 个码位,共收入 21886 个汉字和图形符号;其中 GBK/1 收录除 GB 2312 字符外的其他增补字符,GBK/2 收录 GB2312 字符,GBK/3 收录 CJK 字符,GBK/4 收录 CJK 字符和增补字符,GBK/5 为非中文字符,UDC 为用户自定义字符。→ 这里大家可能会有两个疑问,为什么尾字节要从40开始,而不是00开始;为什么要排除 FF、xx7F这两条线的编号?GBK的尾字节编码高位没有强制要求是1,当高位是0时跟ASCII码是冲突的,ASCII码里00-40之间大部分都是控制字符,所以排除控制字符主要是为了防止丢失高字节导致出现系统性严重后果;排除FF是为了兼容GB2312,GB2312这个位是保留不使用的;而7F表示DEL字符就是向后删除一个字符,如果传输过程中丢失首字节那么就会出现严重的后果,所以需要将xx7F也排除,这是所有编码方案都需要注意的地方。GB18030
随着计算机的发展,GBK的2万多个字符也还是扛不住,于是2000年我国又制定了新标准 GB18030,用来替代 GBK 标准。GB18030是强制性标准,现在在中国大陆销售的软件都支持 GB18030。GB18030其实是对齐Unicode标准的,里面包括了所有Unicode字符集,也算是Unicode的一种实现(UTF)。那既然有了UTF我们为什么还要搞一套Unicode实现?主要是UTF-8/UCS-2他们是不兼容GB2312的,如果直接升级那么就全乱码了,所以GB18030是为了兼容GB系列,是GBK、GB2312的超集,当我们原先的GB2312(GBK)软件考虑升级到国际化Unicode时,可以直接使用GB18030进行升级。GB18030虽然也是GB2312的扩展,但它和GBK的扩展方式不一样,GBK主要是充分利用了GB2312的一些没定义的编码空间,而GB18030采用的是字节变长编码,单字节区兼容ASCII、双字节区兼容GBK、四字节区对齐所有Unicode 码位。实现原理上主要是采用第二字节未使用到的0x30~0x39编码空间来判断是否四字节。* 双字节,第一个字节的值从0x81到0xFE,第二个字节的值从0x40到0xFE(不包括0x7F)。* 四字节,第一个字节的值从0x81到0xFE,第二个字节的值从0x30到0x39,第三个字节的值从0x81到0xFE,第四个字节的值从0x30到0x39。背景介绍
在统一码之前,各国创造了大量的节编码标准,有单字节的、双字节的(如 GB 2312、Shift JIS、Big5 、ISO8859等),各自又相互不兼容。在1987 年,苹果、Sun、微软等公司开始讨论囊括全世界所有字符的统一编码标准,组成了 Unicode 联盟,这个期间做了很多研讨工作,讨论核心要点如下:工作组统计了当时全世界的报纸等刊物,结论是两个字节足以囊括全世界有实用意义的字符(当然这只统计了当前使用的字符,不包括古代语言或者废弃语言)。一种采用变长编码形式,对于 ASCII 字符使用一个字节,其他字符使用两个字节,类似 GBK;另一种采用定长编码形式,不管是不是 ASCII 字符统一使用两个字节。方案选择上主要从计算机处理过程中的时间和空间两个维度,也就是编解码的执行效率和存储大小两方面,最后结论是采用双字节定长编码,因为定长带来的空间变大在整体传输、存储成本上其实影响并不大,而定长编码处理效率会明显高于变长编码,所以早期 Unicode 采用了定长编码形式。由于汉字表意文字字符量较大,如果可以统一那么能大幅减少收录汉字的数量,所以最初收录汉字遵循两个基本原则:表意文字认同原则和字源分离原则。所谓表意文字认同原则,即“只对字,不对形”编码,将同一字的不同字形(即异体字)合并。例如“房”字的第一笔,在中日韩的写法都不同,但它本身是同一个字,只给一个编码,而写法的不同交由字体进行区分。字源分离原则,是指一个字源中同时收录了同一个字的不同字形,则给予两个字形分别编码。例如:之前GBK中就收录了“戶”、“户”、“戸”三个字,那么Unicode也需要保留三个字,如果直接合并会造成使用上的困扰。原句 :户有三种写法,分别是“戶”、“户”、“戸”,改写后:户有三种写法,分别是“户”、“户”、“户”
Unicode介绍
Unicode 称为统一码(也叫万国码),是按现代编码模型进行设计的一套字符编码体系,涵盖抽象字符集、编号、逻辑编码、编码实现。Unicode是为了解决传统的字符编码方案的局限而产生的,在这种语言环境下,不会再有语言的编码冲突,可以在同屏下显示任何国家的语言。UTF-n编码(Unicode Transformation Format Unicode字符集转换格式,n表示码元位数)是Unicode这套编码体系里的编码实现CES部分,像UTF-8、UTF-16、UTF-32都是将数字转换到实际的二进制编码实现,Unicode的编码实现除了UTF系列之外,还有UCS-2/4,GB18030等。但是现在很多人误把Unicode当成只是一个字符编号,这其实是不对的。Unicode可以容纳世界上所有国家的文字和符号,其编号范围是0-0x10FFFF,有1,114,112个码位,为了方便管理划分成17个平面,现已定义的码位有238,605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其中平面0又称为基本多语言平面(Basic Multilingual Plane,简称BMP),这个平面基本涵盖了当今世界上正在使用中的常用字符。我们平常用到的字符,一般都是位于 BMP 平面上的,其范围拥有 65,536 个码点,其他平面统称增补平面,关于平面的概念会在UTF-16章节详细介绍。与UCS的关系
说起Unicode我们不得不提UCS(全称Universal Multiple-Octet Coded Character Set 通用多八位编码字符集),国际标准编号ISO/IEC 10646,是由 ISO 和 IEC 两家国际标准组织联合成立的工作组设计的一套新的统一字符集项目,目的与Unicode 联盟一样致力于开发一款全世界通用的编码集。早在1984 年ISO 和 IEC 两家组织就成立了一个联合工作组来设计一套新的统一字符集标准,但是这两个组织都不知道对方的存在,直到Unicode联盟1988年发布了Unicode草案(UCS草案1989年发布),才发现大家在做同一件事,没有必要搞两套标准 所以后面又考虑合并,由于UCS 最初设计的是 31 位编码空间(UCS-4编码实现),可以容纳 2^31 约 21 亿个字符,而Unicode是16位空间(UTF-16编码实现),所以最开始Unicode 打算作为 UCS 的真子集,即 Unicode 中的每个字符都存在于 UCS 中,而且两者的码点相同,但 UCS 中的字符(编号超过65,536的)则不一定存在于 Unicode 中。不过由于双方利益关系并没有说谁解散谁,最后双方作出一些妥协保持一致共同发展,两个标准中相同字符的编码(码点)必须是一样的,这是一个屁股决定脑袋的决策,如果最初Unicode知道UCS的存在,就不会再出现Unicode了。当然合并工作不是一蹴而就的而是经过多轮迭代, ISO/IEC 和 Unicode在 1993 年发布了第一版相互兼容版本,到了 1996年Unicode 2.0标准发布时,Unicode 字符集和 UCS 字符集(即 ISO/IEC 10646-1 )基本保持了一致,同时Unicode为了跟UCS的四字节保持一致推出了UTF-32编码实现,UCS为了跟Unicode的两字节保持一致推出了UCS-2编码实现。所以现在我们可以认为UCS和Unicode是同一个东西,比如我们常见的java内部运行就采用的是UTF-16编码,而window操作系统采用的是UCS-2,他们都是同一个Unicode标准。→ 为什么这里使用的是2字节编码,而不是4字节呢?先留个悬念,后续会详细讲解UTF-16(Java内部编码)
UTF是Unicode Transfer Format的缩写,即把Unicode转做某种格式的意思,所以UTF-16是Unicode编码里的其中一种实现方式,16代表的是字节位数,占两个字节(UTF-32则表示4个字节)。Unicode 设计之初是采用UTF-16这种双字节定长编码的,其字符编号就是对应的二进制编号,也就是说第二层的CCS和第三层的CEF是一致的。比如汉字「万」的 Unicode 码点是 「U+4E07」,其二进制序列就是直译的「0100 1110 0000 0111 」,这种编码方式的优点是高效,不需要检查标志位,但缺点是不兼容ASCII,ASCII编码的文本都会显示乱码。不过后来Unicode联盟发现 16 位编码空间根本不够用,与此同时 ISO/IEC组织也觉得 UCS的 32 位编码空间太多了,实际中根本没有几十亿字符,也挺浪费空间的,所以最终 Unicode 联盟和 ISO/IEC 工作组达成一致:两者使用统一的编码空间「 0000 ~ 10FFFF」(即 UCS 保证永远不分配大于 10FFFF 的字符码点),而且双方在字符编码上保持同步,即一方标准中增加了字符,也要通知另一方同步。于是Unicode在UTF-16基础上拓展编码空间到 21 位,UCS则搞了一个双字节的UCS-2编码实现。→ UTF-16 编码是双字节的,上限也只有6w多个码点,怎么让他支持到10FFFF(100w+)个码点呢?本质就是多加几个字节来表示更多的字符,只是UTF-16不像UCS那样采用定长4字节,而是使用变长的形式,但是这个跟UTF-8变长方式又不太一样,他是采用代理对的方式实现,大部分常用字符用一个码元表示(定长2个字节),其他扩展的特殊字符用两个码元表示(定长4字节)。代理对
UTF-16跟UTF-8、GB系列等都算是变长字节,但是设计初衷却不一样,像GBK是为了兼容ASCII,但是UTF-16一开始就没考虑要兼容ASCII,所以他的变长是为了节约存储空间而采用的自然增长方案,当空间不够的时候增长到4个字节。那问题来了,我怎么知道存储的4个字节是表示一个字符,还是两个字符呢?比如当程序遇到字节序列01001110 00101101 01010110 11111101时,到底是判断成一个字符还是两个字符?这就需要一个前导识别,比如GB2312识别第一个字节高位是不是1来判断是单字节还是双字节,但是UTF-16的高位1已经被用来编码了,当然这也难不倒我们,第一位被用了那么就用前几位的组合形式。UTF-16采用了代理对来解决,也就是高半区编码(前两个字节)范围D800-DBFF(称为代理码点),低半区编码(后两个字节)范围DC00-DFFF,组成一个四个字节表示的字符。上述前导6位组合也是有讲究的,ISO组织要求编号范围是0~10FFFF(),也就是说用20位就可以表示10FFFF个字符,对于双码元就是每个码元各自负责10位,一个码元是16位,数字位占去10位后,剩下的6位做为前导位。当UTF-16使用一个码元表示的时候,Unicode字符编号跟码元序列是等值映射的,但是当采用双码元后,字符编号跟码元序列就需要转换了,下面是码元和Unicode编号值之间的计算公式:平面空间
UTF-16把编码空间0000 ~ 10FFFF切成了17个平面,其实就是划分成17个区块,每个平面空间码点数都是=65536个,第一个平面称为基本多语言平面(Basic Multilingual Plane,简称BMP),这个平面涵盖了当今世界上最常用的字符,固定使用定长两个字节,除此之外的字符都放到增补平面里,都是使用两个码元的定长4个字节,下面是各个平面的用途增补平面的编号是采用双码元4个字节来表示的,去除代理对之后有效位数是20位,然后将这20位的编号再划成16个平面区域,其中高半区的数字位里取出4位表示平面,剩下的16位表示每个平面可以表示的字符数也就是2的16次方65536个(两个字节大小)UTF-16可看成是UCS-2的父集。在没有辅助平面前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。字节序
字节序顾名思义是指字节的顺序,对于单字节编码来说,一个字符对应一个字节,也就不存在字节序问题;但是对于UTF-16这种定长多字节编码,就有字节顺序问题了。字节序其实跟操作系统和底层硬件有关,不仅只是UTF-16这种多字节编码存在字节序,只要是多字节类型的数据都存在字节顺序问题,比如short、int、long。为了方便说明,我们这里举个例子,比如存一个整数值「305419896」对应16进制是0x12345678,有人习惯从左到右按顺序去存,也有人说高位当然要放到高位地址而低位放到低位地址,要从右往左存。于是就有了下面两种存取方式。其实这两种方式没有孰优孰劣,只是我们认知习惯有所不同 最终的设计不同,说来这都是阿拉伯人的锅啊,为什么数字高位非要在左边,这也引起了著名的大小端之争。因此字节序也就有了大端和小端的概念,也形成了各自的阵营,比如Windows、FreeBSD、Linux 是小端序,Mac是大端序。其实大小端序并没有技术上的好坏之分。小端序( Little-Endian)就是低位字节(即小端字节、尾端字节)存放在内存的低地址,而高位字节(即大端字节、头端字节)存放在内存的高地址。大端序(Big-Endian )就是高位字节(即大端字节、头端字节)存放在内存的低地址,低位字节(即小端字节、尾端字节)存放在内存的高地址。UTF-8
简介&规则
Unicode还是UCS最初都是采用多字节定长编码,由于没有兼容现有的 ASCII 标准的文件和软件,新标准很难被推广,于是兼容ASCII版本的UTF-8就诞生了。UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,是现代字符编码模型中的第三层 CEF 。它可以用一至四个字节对 Unicode 字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,UTF-8 就是为了解决向后兼容 ASCII 码而设计,Unicode 中前 128 个字符(与 ASCII 码一一对应),使用与 ASCII 码相同的二进制值的单个字节进行编码,这使得原来处理 ASCII 字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。
UTF-8需要兼容ASCII,所以也需要有前缀码来控制,前缀规则如下:- 如果首字节以 0 开头,则是单字节编码(即单个单字节码元);
- 如果首字节以 110 开头,则是双字节编码(即由两个单字节码元所组成的双码元序列);
- 如果首字节以 1110 开头,则是三字节编码(即由三个单字节码元所组成的三码元序列),以此类推。
理论上UTF-8变长可以超过4个字节,只是Unicode联盟规范上限是10FFFF,所以UTF-8规则设计上也限制了大小。程序算法
用文字不太好描述算法结构,我们就直接来欣赏一下UTF-8鼻祖写的这段解析代码,这是Ken 和 Rob 用一个晚上写出来的编解码算法,代码非常简短精炼,为了方便阅读我加了注释解读。typedefstruct{ int cmask; int cval; int shift; long lmask; long lval; } Tab;
staticTab tab[] ={ 0x80, 0x00, 0*6, 0x7F, 0, 0xE0, 0xC0, 1*6, 0x7FF, 0x80, 0xF0, 0xE0, 2*6, 0xFFFF, 0x800, 0xF8, 0xF0, 3*6, 0x1FFFFF, 0x10000, 0xFC, 0xF8, 4*6, 0x3FFFFFF, 0x200000, 0xFE, 0xFC, 5*6, 0x7FFFFFFF, 0x4000000, 0, };
int mbtowc(wchar_t *p, char *s, size_t n){ long l; int c0, c, nc; Tab *t; if(s == 0) return 0; nc = 0; if(n <= nc) return -1; c0 = *s & 0xff; l = c0; for(t=tab; t->cmask; t++) { nc++; if((c0 & t->cmask) == t->cval) { l &= t->lmask; if(l < t->lval) return -1; *p = l; return nc; } if(n <= nc) return -1; s++; c = (*s ^ 0x80) & 0xFF; if(c & 0xC0) return -1; l = (l<<6) | c; } return -1;}
容错性
通过上面的程序我们知道解析过程是一个字节一个字节往下处理的,我们在传输过程中如果发生局部的字节错误、丢失,或者中间有一个字节规则对不上,会不会影响整个文本的解析?我们先来看下其他编码的容错情况,从对于单字节的ASCII码来说,丢失一个字节就丢失一个字符,并不影响后续文本的内容,比如Hello world,丢失b2字节后内容是Hllo world少个e而已我们再来看GB2312这种多字节编码,如果丢失了b2字节那么整个文本都乱套了,这是最糟糕的,大部分多字节编码都有类似问题,一旦出现错误可能导致整个文件都需要重传。接下来我们看看UTF-8是如何避免这种“一颗老鼠屎坏了一锅粥”的情况,UTF-8 的码元序列的第一个字节指明了后面所跟字节的个数,比如首字节高位是0就表示单字节,110表示总共两个字节,1110表示三个字节依次类推,除首字节之外后续字节都是10开头。所以UTF-8的前缀码具有很强的鲁棒性,即使丢失、增加、改变个别字节也不会导致后续字符全部错乱这样的传递性、连锁性的错误问题。单单一个字符编码,深入了解之后发现也有这么浓重的发展历程,试想一下,如果计算机还是跟之前大型机一样,个人计算机没有井喷式发展起来就没有这些字符编码的事了,如果ASCII当初就设计成多字节编码,也没有后面UNICODE什么事了。这是一个很典型的架构设计问题,到底好的架构是设计出来的,还是演化出来的?一个好的架构是既要靠设计又要靠演化,老话说的好三分靠设计七分靠演化,我们既要学会务实,也要懂得前瞻,至少我们首先需要活下来。重磅来袭!2022上半年阿里云社区最热电子书榜单!
千万阅读量、百万下载量、上百本电子书,近200位阿里专家参与编写。多元化选择、全领域覆盖,汇聚阿里巴巴技术实践精华,读、学、练一键三连。开发者藏经阁,开发者的工作伴侣~
点击阅读原文查看详情。