癌症的一些切身体会(八)预测癌症的发生
癌症的一些切身体会(八)预测癌症的发生
平等性
前面几篇讲了癌症的预测,以及预测因子和生物标志物,有朋友提到了最近颇为流行的液体活检,并问我液体活检和生物标志物有什么关系。这一篇我先来谈谈液体活检的事儿,再介绍一下关于癌症的预测模型。
根据教科书上的解释,液体活检是指一种从血液等非实性生物组织中取样并分析,主要用于诊断或监测肿瘤疾病的方法。液体活检的主要检测指标,是血液中的循环肿瘤细胞(circulating tumor cells, CTC)和循环肿瘤DNA(circulating tumor DNA, ctDNA)。因为CTC和ctDNA直接与肿瘤有关系,因此我们可以通过血液取样,利用细胞分离和测序技术,使用液体活检技术来帮助医疗工作者估算CTC和ctDNA的数量,这样就能够显著提高肿瘤的预测精度和治疗的准确性。
因为液体活检技术主要是通过抽取患者的外周血液进行检测分析并获得肿瘤的相关信息,这样就不会对被检测者造成任何创伤,操作起来也方便快捷,而且能够反复取样,易于实时检测和监控。从血液中获得的CTC和ctDNA可以是来源于实时的肿瘤组织的任何部分,同时也包含了异质性的各个方面,因此能够更全面地反映肿瘤的全貌。有研究显示,CTC和ctDNA携带的信息各有侧重,其中ctDNA相比较CTC会更实时,更能够动态地反映人体内肿瘤的变化情况,所以在现有的癌症预测中使用得最为广泛;不过CTC也非常重要,它不仅包含了DNA信息,还有RNA和蛋白质信息,因此能够全方位地揭示肿瘤特征。总的来说,这两者的相互结合,对于癌症预测的作用更大。
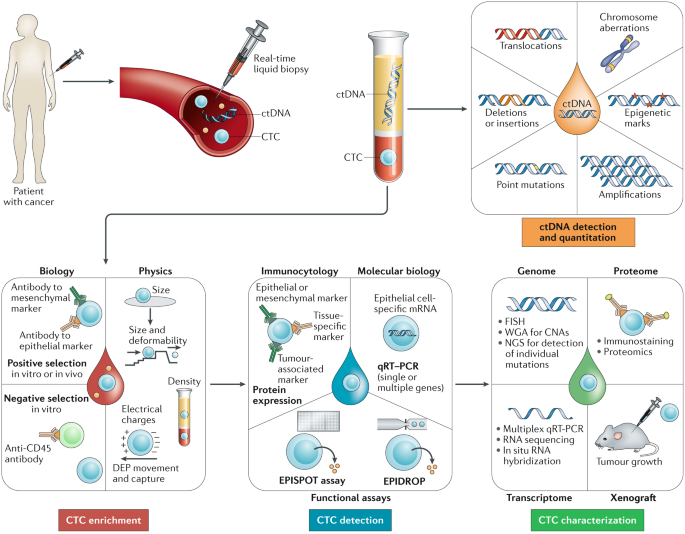
通过前面的介绍,我们可以看出液体活检是一整套生物信息技术,它所提取的CTC和ctDNA其实也是属于生物标志物的范畴。而不管是利用液体活检,还是利用其它生物标志物进行癌症的预测和确定精准治疗方案,都需要用到我前面几篇所提到的统计模型和机器学习的方法。
大家可能都听说过数学模型,也就是用抽象化的数学公式去描述现实世界的规律,最有名的几个数学模型,有勾股定理,牛顿的三大定律,麦克斯韦的电磁方程组,爱因斯坦的质能公式,等等。这些都是在理想情况下,将确定性的规律定量化的经典。但是,在实际生活中,还有很多的规律是具有不确定性的。比如说,天气变化,量子态的分布,股市起伏,以及和这一个系列有关系的,癌症的发病率和生存预期。
对具有不确定性的规律进行归纳和总结,就需要用到统计模型。而统计模型的基础,一个是数据,一个是概率。研究概率是对生活智慧和经验的总结,是个极其实用的法门,我们日常的生活中其实也在不自觉的运用概率而帮助我们的决定。比如说天阴了出门要拿伞,打雷了就最好不要出门,甚至在疫情期间去人多的地方戴口罩,都有一个根据概率做出相应决定的过程。
概率的基础就是差异和分布,通俗的说就是多种可能性。最简单的例子就是抛硬币,有可能是正面,也有可能是反面;复杂一点的是掷骰子,一到六,哪一面都有可能。这个就叫差异。简单点说,就是即使给足了条件,也不会只有一个结局,这个是和决定论的最大不同。然后就是分布,也就是每一面出现的可能性。
建立统计模型,就是需要在收集的数据基础上建立概率分布的模型,然后根据这个模型去计算具体的概率分布值,并作出相应的判断和执行。有一些人因为不确定性,就走向了不可知论。他们的理论是,既然事情的真相或发展都有不同的可能性,那么不如什么结论都不做,反正怎么也说不准。这个当然不对,因为如果能深入了解不确定性,并且能够量化概率并总结出规律,是可以有效帮助我们作出最优化判断与决策的。在进行癌症预测的时候,我们就是基于历年收集来的所有致癌因子和生物标志物,建立一套最符合实际发生率的统计模型,并对新的样本进行预测,来精确计算发病的概率。
这是统计模型,那什么又是机器学习呢?机器学习和传统的统计模型其实是有很多交叉的,一般来说,机器学习是建立在大样本和高维数据的基础上,运用更复杂的计算方法,包括了一些人工智能的算法,来建立预测模型的,比如说,决策树,随机森林,神经网络或深度学习神经网络,蒙特卡洛方法,等等。也就是说,统计模型和机器学习的最终目的,在癌症预测这一点上是一致的,都是为了提供更精确的癌症预测。

正因为癌症的预测是基于统计模型和机器学习,所以它们所得到的,都是概率判断。概率判断并不能保证百分百的正确,但是它们可以显著提高预测的成功率。有些学术界的人士对这些预测模型有所质疑,尤其是担心那些关于预测的假阳性,假阴性,以及相关的成本和风险是否超过了挽救实际寿命的可能收益。为什么呢?这是因为建立这样的预测模型,必须进行回顾性研究,并收集和存储大量的患者和健康人群的数据。这样的研究,往往非常烧钱,因此这些大型的研究几乎从未由私营部门完成,基本上都是由政府提供赞助。因此,用于早期检测大多数癌症的血液测试的使用范例在几十年内进展甚微。比如说,在美国,PSA仍然是唯一广泛使用的用于癌症筛查的血液试验,且甚至其使用已成为有争议的。在世界上其它地区,尤其是远东地区,检测各种癌症的血液检测更为普遍,但几乎没有标准化或经验性方法来确定或改善世界这类地区这类测试的准确性。

我自己的看法是,研究都是一步一步的向前发展的,总的来说,统计模型和机器学习系统对于分析信息,帮助我们进行癌症预测和判断,是起到了显著成效的。不过尽管现在已经开发了很多的癌症预测和决策系统,但是这样的系统在医疗实践中并未广泛使用,而且因为这些系统遭受了限制,从而无法将其融入到卫生组织的日常操作中。其它还有一些具体实施中的难点,比如说患者数据的录入繁琐,需要检查的项目太多太昂贵,预测模型背后的机理不太透明,等等。
现在的液体活检,对预测全癌(overall cancer)的敏感性和特异性都达到了相当高的精度。当然,液体活检技术目前也存在着很多局限性,比如说,液体活检对区分不同癌症的精确度也还有很大的提升空间,而且无论CTC还是ctDNA在血液中都极其微量,需要更好的技术来增加仪器检测的灵敏度。现在液体活检的使用成本较高,应用范围不广,主要还是在实验室的研究阶段,到临床的大规模应用还有很长一段路要走。将来液体活检在癌症的早期诊断中究竟能达到多及时?液体活检揭示肿瘤动态变化的反应有多灵敏?对每个特定种类癌症的敏感性与特异性如何?它与现在做为金标准的病理组织活检的相关性有多高?这些都是当前液体活检技术亟待解决的问题。
我自己觉得液体活检是个非常有前景的方向,使用血液测试的方法和技术所收集的数据,建立并提供更多更精确的统计模型和机器学习系统,可以极大程度的帮助癌症的早期检测和预测。
(本文图片来自网络)