【新智元导读】科技的伟大之处不仅仅在于改变世界,更重要的是如何造福人类,科技向善,才是最美科技。
以前,让失明者重见光明往往被视为一种医学「奇迹」。而随着以「机器视觉+自然语言理解」为代表的多模态智能技术的爆发式突破,给AI助盲带来新的可能,更多的失明者将借助AI提供的感知、理解与交互能力,以另一种方式重新「看见世界」。
一般来说,目不能视的视障患者认知外界世界的渠道是除了视觉之外的其它感官感觉,比如听觉、嗅觉和触觉,这些其他模态的信息一定程度上帮助视障人士缓解了视力缺陷带来的问题。但科学研究表明,在人类获取的外界信息中,来自视觉的占比高达70%~80%。
因此基于AI构建机器视觉系统,帮助视障患者拥有对外界环境的视觉感知与视觉理解能力,无疑是最直接有效的解决方案。
在视觉感知领域,当下的单模态AI模型已经在图像识别任务上超越了人类水平,但这类技术目前只能实现视觉模态内的识别及理解,难以完成与其他感觉信息交叉的跨模态学习、理解与推理,简单来说,就是只能感知无法理解。为此,计算视觉奠基人之一的 David Marr 在《视觉》一书中提出了视觉理解研究的核心问题,认为视觉系统应以构建环境的二维或三维表达,并可以与之交互。这里的交互意味着学习、理解和推理。可见,优秀的AI助盲技术,其实是一个包含了智能传感、智能用户意图推理和智能信息呈现的系统化工程,只有如此才能构建信息无障碍的交互界面。为了提升AI模型的泛化能力,使机器具备跨模态的图像解析与理解能力,以「机器视觉+自然语言理解」为代表的多模态算法开始兴起并飞速发展。这种多个信息模态交互的算法模型,可以显著提升AI的感知、理解与交互能力,一旦成熟并应用于AI助盲领域,将能够造福数以亿计的失明者,重新「看见世界」。据世卫组织统计,全球至少22亿人视力受损或失明,而我国是世界上盲人最多的国家,占世界盲人总数的18%-20%,每年新增的盲人数量高达45万。第一人称视角感知技术,对于AI助盲来说意义重大。它无需盲人跳出参与者身份去操作智能设备,而是可以从盲人的真实视角出发,帮助科学家们构建更符合盲人认知的算法模型,这促使了盲人视觉问答这一基础研究任务的出现。
盲人视觉问答任务是学术界研究AI助盲的起点和核心研究方向之一。但在现有技术条件下,盲人视觉问答任务作为一类特殊的视觉问答任务,相比普通视觉问答任务,精度提升面临着更大的困难。一方面,盲人视觉问答的问题类型更复杂,包括目标检测、文字识别、颜色、属性识别等各类问题,比如说分辨冰箱里的肉类、咨询药品的服用说明、挑选独特颜色的衬衣、介绍书籍内容等等。另一方面,由于盲人这一感知交互主体的特殊性,盲人在拍照时,很难把握手机和物体间的距离,经常会产生虚焦的情况,或者虽然拍摄到了物体,但没有拍全,亦或是没有拍到关键信息,这就大大增加了有效特征提取难度。同时,现存的大部分视觉问答模型是基于封闭环境下的问答数据训练实现的,受样本分布限制严重,难以泛化到开放世界下的问答场景中,需要融合外部知识进行多段推理。
盲人视觉问答数据
其次,随着盲人视觉问答研究的开展,科学家们在研究过程中发现,视觉问答会遭遇到噪声干扰的衍生问题。因此如何准确定位噪声并完成智能推理,也面临重大挑战。盲人由于不具备对外界的视觉感知,因此在图文配对的视觉问答任务中,往往会产生大量的错误。比如说,盲人去超市购物的时候,由于商品外观触感相似,很容易提出错误的问题,如拿起一瓶醋,却询问酱油的生产厂商是哪一家。这种语言噪声往往会导致现有AI模型失效,需要AI能够具有从庞杂的环境中分析噪声与可用信息的能力。最后, AI助盲系统不应仅仅解答盲人当下的疑惑,还应该具备智能意图推理与智能信息呈现能力,而智能交互技术作为其中重要的研究方向,算法研究依然处于起始阶段。智能意图推理技术的研究重点在于,通过让机器不断学习视障用户的语言和行为习惯,来推断其想要表达交互意图。比如说,通过盲人端水杯坐下的动作,预测到可能会将水杯放置在桌子上的下一步动作,通过盲人询问衣服颜色或样式的问题,预测到可能会出行等等。而这项技术的难点在于,由于使用者的表达方式和表达动作在时间和空间上都存在随机性,由此引发了交互决策的心理模型同样带有随机性,因此如何从连续随机的行为数据中提取用户输入的有效信息,设计出动态非确定的多模态模型,从而实现对不同任务的最佳呈现,非常关键。毋庸置疑的是,在上述基础研究领域的重大突破,才是AI助盲技术早日落地的关键所在。目前来自浪潮信息的前沿研究团队通过多项算法创新、预训练模型和基础数据集构建等工作,正在全力推动AI助盲研究的进一步发展。
在盲人视觉问答任务研究领域,VizWiz-VQA是卡内基梅隆大学等机构的学者们共同发起的全球多模态顶级盲人视觉问答挑战赛,采用「VizWiz」盲人视觉数据集训练AI模型,然后由AI对盲人提供的随机图片文本对给出答案。在盲人视觉问答任务中,浪潮信息前沿研究团队解决了盲人视觉问答任务常见的多个难题。首先,由于盲人所拍摄图片模糊、有效信息少,问题通常也会更主观、模糊,理解盲人的诉求并给出答案面临挑性。团队提出了双流多模态锚点对齐模型,将视觉目标检测的关键实体及属性作为连结图片及问题的锚点,实现多模态语义增强。其次,针对盲人拍摄图片难以保证正确方向的问题,通过自动修正图像角度及字符语义增强,结合光学字符检测识别技术解决「是什么」的理解问题。最后,盲人拍摄的画面通常是模糊、不完整的,这导致一般算法难以判断目标物体的种类及用途,需要模型需具备更充分的常识能力,推理用户真实意图。为此,团队提出了答案驱动视觉定位与大模型图文匹配结合的算法,并提出多阶段交叉训练策略。推理时,将交叉训练后的视觉定位和图文匹配模型用于推理定位答案区域;同时基于光学字符识别算法确定区域字符,并将输出文本传送到文本编码器,最终通过图文匹配模型的文本解码器得到盲人求助的答案,最终多模态算法精度领先人类表现9.5个百分点。当前视觉定位研究应用落地的最大障碍之一是对于噪声的智能化处理,真实场景中,文本描述往往是有噪声的,例如人类的口误、歧义、修辞等。实验发现,文本噪声会导致现有AI模型失效。
为此,浪潮信息前沿研究团队探索了真实世界中,由于人类语言错误导致的多模态失配问题,首次提出视觉定位文本去噪推理任务FREC,要求模型正确定位噪声描述对应的视觉内容,并进一步推理出文本含噪的证据。
FREC提供3万图片和超过25万的文本标注,囊括了口误、歧义、主观偏差等多种噪声,还提供噪声纠错、含噪证据等可解释标签。
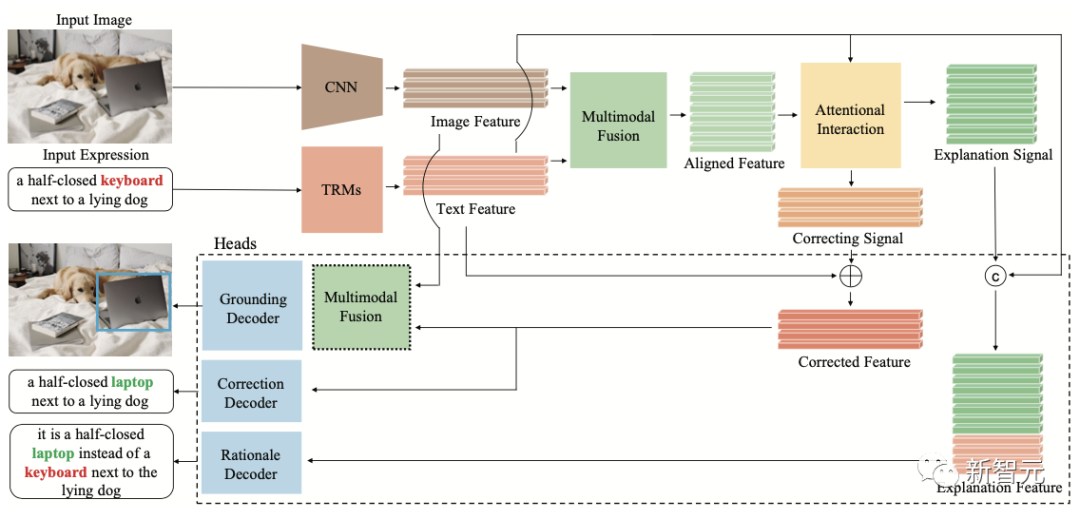
同时,团队还构建了首个可解释去噪视觉定位模型FCTR,噪声文本描述条件下精度较传统模型提升11个百分点。
这一研究成果已发表于ACM Multimedia 2022会议,该会议为国际多媒体领域最顶级会议、也是该领域唯一CCF推荐A类国际会议。

论文地址:https://dl.acm.org/doi/abs/10.1145/3503161.3548387为探索AI在图像和文本的基础上进行思维交互的能力,浪潮信息前沿研究团队给业界提出了一个全新的研究方向,提出可解释智能体视觉交互问答任务AI-VQA,通过建立逻辑链在庞大的知识库中进行检索,对图像和文本的已有内容实现扩展。目前,团队构建了AI-VQA的开源数据集,包含超过14.4万条大型事件知识库、全人工标注1.9万条交互行为认知推理问题,以及关键对象、支撑事实和推理路径等可解释性标注。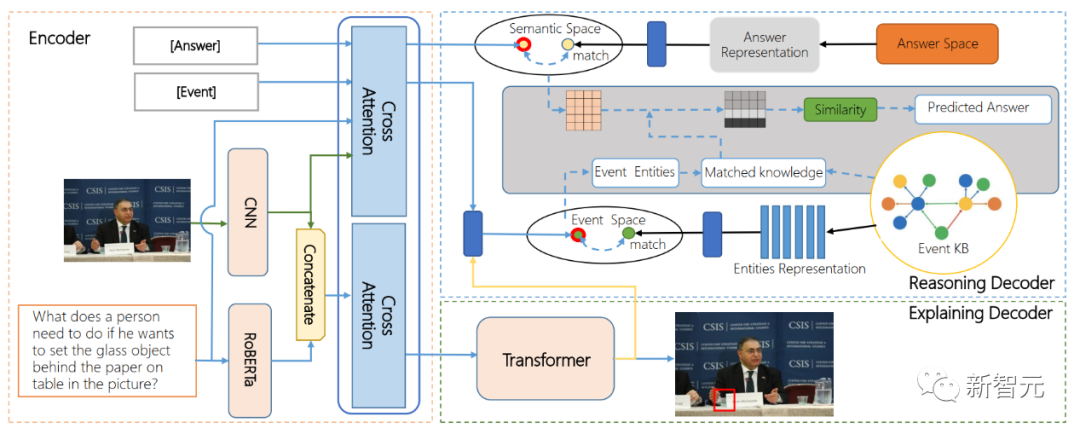
同时,团队提出的首个智能体交互行为理解算法模型ARE(encoder-decoder model for alternative reason and explanation)首次端到端实现交互行为定位和交互行为影响推理,基于多模态图像文本融合技术与知识图谱检索算法,实现了具备长因果链推理能力的视觉问答模型。科技的伟大之处不仅仅在于改变世界,更重要的是如何造福人类,让更多的不可能变成可能。而对于失明者而言,能够通过AI助盲技术像其他人一样独立的生活,而不是被特殊对待,恰恰体现了科技最大的善意。在AI照入现实的当下,科技已经不再是高山仰止的冰冷,而是充满了人文关怀的温度。站在AI技术的前沿,浪潮信息希望,针对人工智能技术的研究,能够吸引更多人一起持续推动人工智能技术的落地,让多模态AI助盲的浪潮延伸到AI反诈、AI诊疗、AI灾情预警等更多场景中去,为我们的社会创造更多价值。https://dl.acm.org/doi/abs/10.1145/3503161.3548387
