
©作者 | 杨学
单位 | 上海交通大学
研究方向 | 目标检测
前言
这是一篇弱监督+自监督的旋转目标检测方法解读,性能比肩全监督的方法。arXiv预印文章链接:
https://arxiv.org/abs/2210.06742https://github.com/yangxue0827/h2rbox-mmrotatehttps://github.com/open-mmlab/mmrotate/tree/1.x/configs/h2rboxhttps://github.com/Jittor/JDet/tree/master/projects/h2rboxhttps://github.com/yangxue0827/h2rbox-jittorhttps://zhuanlan.zhihu.com/p/586806807
动机
相比通用目标检测(水平框检测),旋转检测的研究兴起较晚。以我熟悉的遥感图像旋转检测为例(场景文字相关的旋转检测出现地更早),我是在 17 年末(国科大研二才进实验室)开始做旋转舰船检测的,当时几乎还找不到相关的研究,大部分还是水平框检测算法(如 Faster RCNN、SSD 等)在遥感图像的应用。旋转框标注的数据集也很少,当时做旋转舰船检测还是举实验室之力标注了一个。从水平框检测发展到旋转检测的这段时间里,很多数据集以水平框标注的形式发布,如果现在想进一步用于旋转检测,似乎只有重新标注。如果数据集量小还好说,一旦实例数达到十万甚至百万级别,所需要花的人力物力是非常大的。比如,DIOR(19.2w 个实例)数据集刚发布的时候是以水平框标注,后来又重新标注了旋转框;SKU110K(173.3w 个实例)数据集也是在后来有了一个旋转标注版本。于是乎,我们想到了这样一个的研究任务:水平框标注的旋转框目标检测。这算是一个弱监督检测任务(也不是很“弱”),就我目前所知好像还没有人做这个事情,算是一个小坑,感兴趣的同学赶紧入坑。如果效果比肩旋转框标注的话,就可以不用重新标注旋转框;即使效果一般般,起码也可以辅助标注旋转框。后来我们查了一下各种标注形式的价格,旋转框每一千个是 86 刀,比水平框高的 63 刀高 36.5% 的价格。相关的研究任务
尽管现在没有直接研究水平框标注的旋转检测算法,但是还是有非常相关的研究方向的,也就是基于水平框标注的实例分割,如本文主要对比的 BoxInst 和 BoxLevelSet。只要在后处理阶段对最后预测的掩码取最小外接矩形就可以实现旋转框的检测了,我们在文中记为 HBox-Mask-RBox 方法,然而这种做法极易受 Mask 这个中间形态的影响。
图1(a) 中飞机的分割往往会把周围的干扰物体(野点、异常点)也分割进去,最后所转换出的来旋转框明显不准。图1(b) 中是两个密集排列的场景,这种场景下常常出现把相邻目标区域也分割进来(BoxInst 采用的 color pair-wise loss 会经常出现这个问题),最终导致转化出来的框过大。除了最后的旋转框不准,模型的效率也会严重下降,因为 Mask 转成 RBox 这一步骤(最小外接矩形)非常耗时。HBox-Mask-RBox 的方法还有一个缺陷是非常耗显存,这和它们所设计的损失函数有关系。下表就是相关参数的对比:
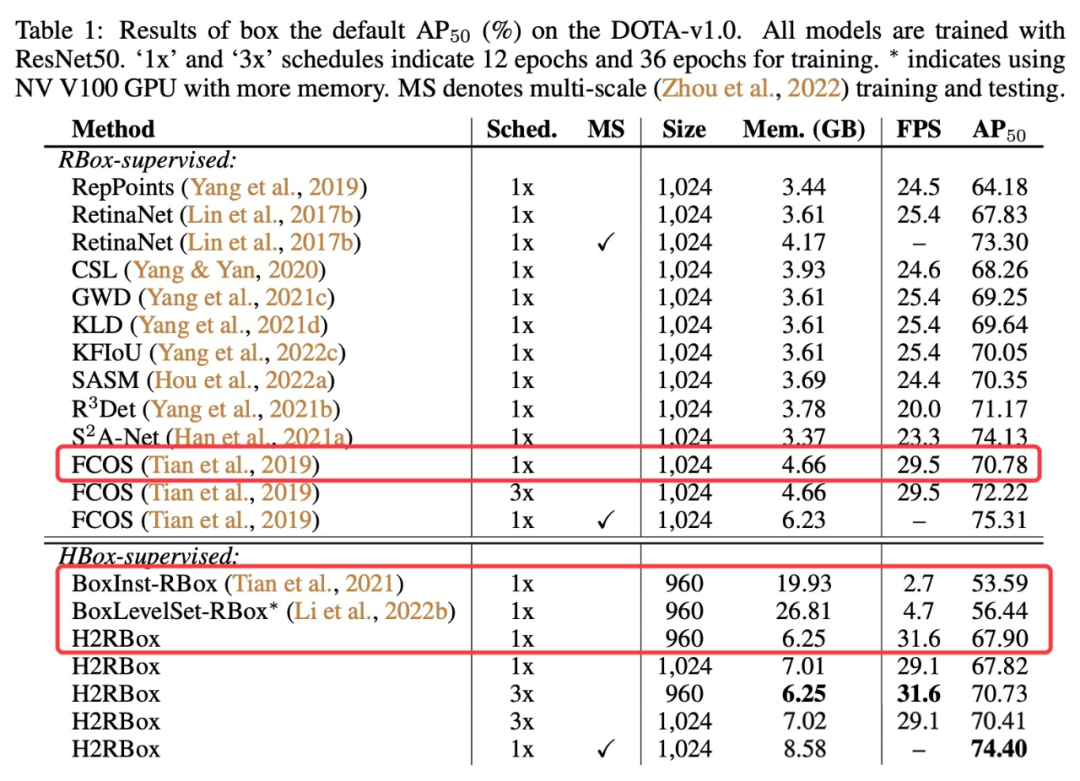
我们也在 H2RBox 代码中给了基于 BoxInst 的代码实现,大家亲自体验一下这类方法。这也解释了审稿人经常问我的一个问题:为什么不用实例分割来做旋转检测以及旋转目标检测这个任务存在的意义。对于预测旋转框可以满足要求的任务来说(如舰船检测、汽车检测等),实例分割的做法有点舍近求远了。
像素级的表示比旋转矩形维度更高,自然会使得模型预测任务更难(图1就是具体的一些难点),最终导致效果更差了,这还不算实例分割会增加标注的成本。借用章老师(文章二作)的一句来做总结:标旋转框相比正框,价格上虽然略贵,但没有量级上的差异。
国内标成本只高 20%,国外标成本高 40%,且目标类别越多价格差异越小。但标框和标分割,价格就差几倍了。所以旋转框的一个正经落地思路就是分割平替。有些场景标分割太隆重,标正框太粗糙,就正好标旋转框。
回到弱监督旋转目标检测这个正题,HBox-Mask-RBox 方法不可行的万恶之源就是 Mask 这个过渡形态,所以我们提出了从 HBox 标注直接预测 RBox 的方法,也就是 HBox-to-RBox 方法,简称 H2RBox。方法介绍
H2RBox 方法既有弱监督也有自监督,先看一下整体的结构图:
整个方法的结构是经典的双塔结构,左边是弱监督分支,右边是自监督分支,它们共享同一个骨干网络(Backbone)和多尺度特征融合网络(Neck)。
4.1 弱监督分支
弱监督分支选用的是 FCOS 作为基准模型,我们在回归子网络多预测了一个角度参数,因此最终的输出是旋转框。由于我们只有水平标注,因此无法直接使用旋转预测框和水平标注框计算损失。在计算回归损失之前,我们将预测的旋转框转换为其对应的水平外接矩形,然后再通过这些水平外接矩形与水平标注框计算损失。这个做法我们记为水平外接矩约束,这也建立了预测旋转框和未标注的旋转框之间的联系,也就是它们的水平外接矩形是高度重合的。当然这是理想情况,需要考虑到训练的模型预测的水平框不一定准,另外就是有些类别水平标注框不一定就是旋转标注框的水平外接矩形,如下图所示:▲ 来源:https://github.com/yangxue0827/h2rbox-mmrotate/issues/1
就从结果来看,这些因素可能会影响 这种高精度指标,对于 这种指标影响不是很大,这里有一篇 ICCV21 的文章研究目标检测中的旋转增强讨论了这类问题并给了一个解决方案。水平外接矩约束的建立只能将弱监督分支预测的旋转框的可能形态减少,但依然有无数种可行解。为了让该分支预测的旋转框就是正确的那个框,需要增加其他约束来筛选,这也是自监督分支的作用。
4.2 自监督分支
自监督分支的输入是原图经过随机角度旋转得到的,旋转中心是图片的中心,旋转矩阵为 R。这里需要注意图像旋转后会出现黑边区域而产生信息泄漏,因此文中提供了两种处理方法:从实验结果上来看,反射填充法效果更好,可能原因是这种做法不会降低图像的输入大小。数据预处理完后就会被送入自监督分支,与弱监督分支不同的是该分支只包含回归子网络。自监督分支会输出新视角下的旋转预测框。有这样一个正确命题:对任意的旋转矩阵 R,如果两个分支对同一个目标预测的旋转框都是正确的,那么所预测的旋转框之间的空间关系应该和两个输入图像的空间关系一致。通过证明,我们发现这个命题在水平外接矩约束存在的前提下是充分必要的。因此,我们将弱监督分支预测的旋转框做了 R 矩阵的变换,再计算变换后的旋转框与自监督分支预测的旋转框的一致性损失,也就是图中的 。 主要包含尺度损失 、中心点损失 和角度损失 ,主要是为了引入尺度约束和角度约束。
到目前为止,已经引入了三种约束,下图描述了三种不同约束是如何引导模型一步步预测出正确的结果。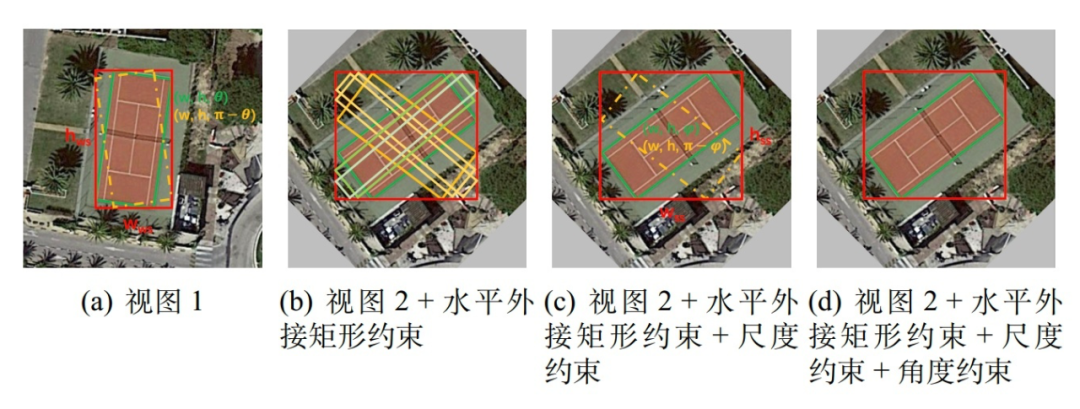 水平外接矩形约束:从上图(b)可以看出尽管水平外接矩形约束已经减少了许多种错误的预测形式,但是依然还是存在无数种可能得情况,只是这些情况的水平外接矩形满足高度重合的条件;尺度约束:图(c)展示了这个约束可以将上述说的无数种可能得情况进一步减少到两种,也就是正确的结果和中心对称的结果。可能大家会迷惑 只是让两个分支对同一目标预测的结果尺度保持一致,但是并不能保证这个尺度就是正确的。
水平外接矩形约束:从上图(b)可以看出尽管水平外接矩形约束已经减少了许多种错误的预测形式,但是依然还是存在无数种可能得情况,只是这些情况的水平外接矩形满足高度重合的条件;尺度约束:图(c)展示了这个约束可以将上述说的无数种可能得情况进一步减少到两种,也就是正确的结果和中心对称的结果。可能大家会迷惑 只是让两个分支对同一目标预测的结果尺度保持一致,但是并不能保证这个尺度就是正确的。这里要稍微补充解释一下,由于自监督分支的输入图像的旋转角度是随机的,那么随着多轮的训练模型就会学习到这样的一个知识,同个目标不管旋转多少度,模型都能输出一个同尺度的旋转框,且这些旋转框的水平外接矩形和对应的水平 gt 保持高度重合,那么这里的尺度只能是目标的实际尺度才能满足。注意,这里的关键条件是同个目标不管旋转多少度。
角度约束:现在模型距离正确预测结果只差消除中心对称的情况,两个分支的预测结果可能出现的下面四种情况(如下式所示),因此只要告诉模型两个分支预测结果的角度关系和输入图像的角度关系一致(R)就可以了。▲ 建议参考https://zhuanlan.zhihu.com/p/586806807中的图9来辅助理解式中 和 分别表示弱监督分支所估计的重合边界框和自监督分支估计的中心对称边界框。这里的 表示中心对称变换。水平外接矩形约束保证 是已知量。尺度约束使得两个分支预测的尺度相同都是 。此时只剩下四个未知数 ,在 时,方程组有唯一解(因为不是线性方程组,所以我暂时还没法严格证明,求助各位大佬)。已知正确的 gt 是上述方程组的一个解,那么预测的结果就只能是正确的 gt。
弱监督分支损失:
具体细节不过多介绍了,可以看原文对公式的具体说明。这里主要是想强调两点:1)自监督分支中的中心点损失 不是必须的,因为弱监督分支中的回归损失已经包含了这部分,因此在实际实验中我们发现 需要设置一个比较小的权重,大概 0-0.15 即可;2)自监督分支的 gt 是需要通过弱监督分支进行标签再分配得到了,本文最终采用了最简单的一对一空间位置对应关系(R 的仿射变换)来进行重分配的,空间关系如下式所示:

具体就是将弱监督分支位置 上的分配到的标签作为弱监督分支位置 的标签。

4.5 对比实验
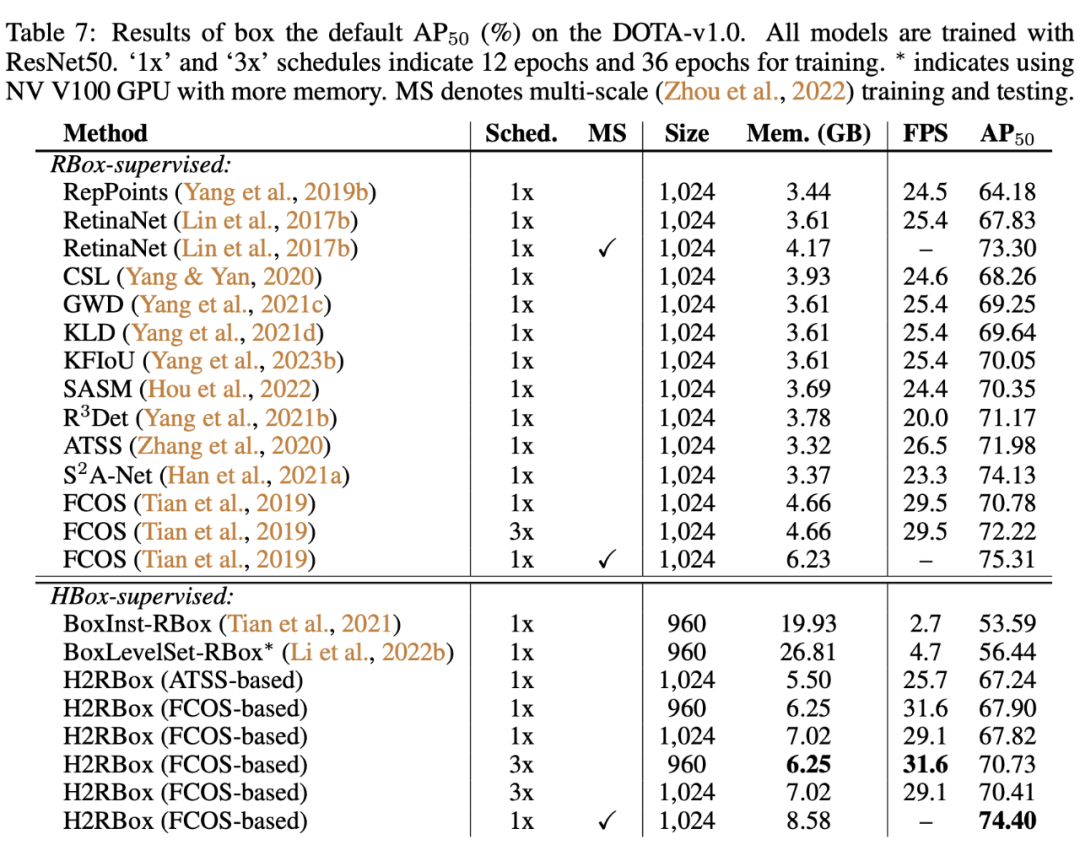
▲ 增加了ATSS为Baseline的H2RBox的实验,代码也已经开源到https://github.com/yangxue0827/h2rbox-mmrotate中
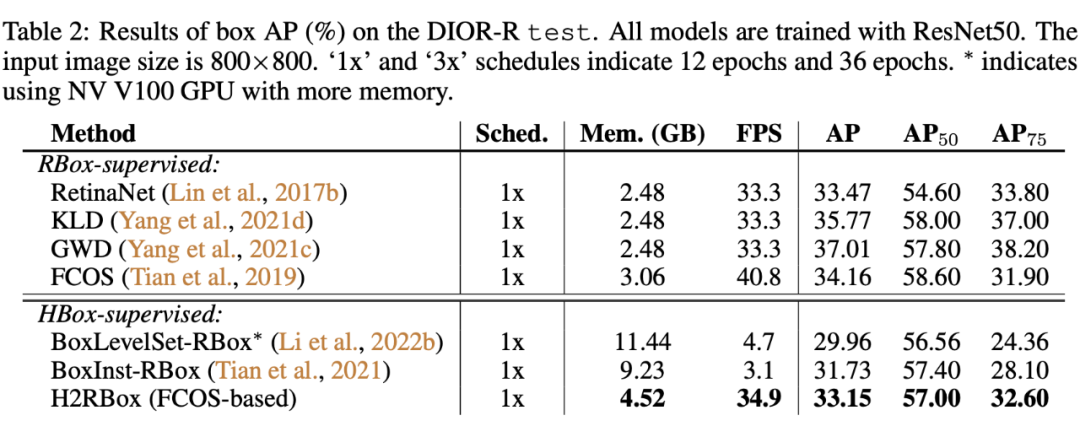
▲ 原arXiv版本实验设置存在错误,导致H2Rbox效果比baseline的FCOS要好,最终版本进行了重新实验并修改了相应的描述。
4.6 DOTA各类别性能补充:

总结
主要想分享一下后续可以继续做的几个研究点。如果有同道中人想接着做这些研究,欢迎加我好友一起交流,一起发 paper~~
1. 基于 H2RBox 的改进:
- 提高高精度指标 :H2RBox 其实在高精度指标 上效果并不好,主要前面有提到,一个是训练的模型预测的水平框不一定准,另外就是有些类别水平标注框不一定就是旋转标注框的水平外接矩形;
适用于 H2RBox 的数据增强:细心的小伙伴可以发现我最终给的表格里最高的性能没有使用数据增强(主要是旋转增强),是因为加了之后发现模型预测不出角度了,猜测的原因是使用的旋转会引入黑边,还有就是会和自监督分支的旋转增强冲突等;
更好的标签再分配策略:当前采用的是最简单的 One-to-One (O2O),完全可以有更好的策略;
孪生/对称网络:目前自监督的预测投只有回归分支,还是和弱监督分支不对称的,这里我们没有做过哪个更好,是可以继续探索一下的。对称的好处是后续可以用 EMA 来更新自监督分支的权重,我个人认为会更加合理,毕竟很多自监督的工作都是这样子的,这也是我目前在扩展的实验;
- 更好的一致性损失:如何让模型更快更鲁棒地学习到旋转信息,这个就比较发散了,其实很多回归损失都可以拿来试一下,本文的一致性损失实际上就是计算两个不同分支对同一个目标预测框在经过 R 变换后的重叠率。
根据不同的标注形式,目前其实已经有了 Point2HBox [1-2]、HBox2RBox(本文)、HBox2Mask [3-5]的工作,那其实还有几个工作需要补齐,比如 Point2RBox、Point2Mask(这个可能有了,我不太了解)、RBox2Mask,甚至设计一个统一的框架,将上述所有范式归纳到同一个框架中,这就非常有意义了。- Object Localization under Single Coarse Point Supervision, CVPR, 2022
- Point-to-Box Network for Accurate Object Detection via Single Point Supervision, ECCV, 2022
- Boxinst: High-performance instance segmentation with box annotations, CVPR, 2021
- Box-supervised Instance Segmentation with Level Set Evolution, ECCV, 2022
Box2Mask: Box-supervised Instance Segmentation via Level-set Evolution, arXiv:2212.01579, 2022
H2RBox 文章放到 arXiv 后没几天出现了一篇和 H2RBox 在框架层面非常相似的半监督语义分割方法 Dense FixMatch,那其实可以思考一下是否还可以应用到其他任务中去。
▲ Dense FixMatch: https://arxiv.org/pdf/2210.09919.pdf

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
