©PaperWeekly 原创 · 作者 | 蔡旭恒
单位 | 香港大学
研究方向 | 推荐系统

论文题目:
LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation
ICLR 2023
https://arxiv.org/abs/2302.08191
https://github.com/HKUDS/LightGCL
https://sites.google.com/view/chaoh
近年来,图神经网络(Graph Neural Networks,或简称 GNN)在基于图的推荐系统上展现了良好的效果,而这得益于其整合相邻结点信息以进行协同过滤(Collaborative Filtering)的能力。总的来说,基于 GNN 的推荐模型在用户-物品交互图上进行多层的信息传递,以此挖掘高阶的(high-order)连接信息。很大一部分基于 GNN 的协同过滤模型采用了监督学习(Supervised Learning)的范式,而这需要大量而准确的带标签信息用以训练。然而,在实际的应用场景中,数据往往十分稀疏,导致监督学习无充分的信息可供利用。为了解决信息稀疏问题,最新的模型往往采用对比学习(Contrastive Learning)来对数据进行增强操作。具体来说,对比学习的主旨是在原有图结构的基础上略作扰动,并以此增强后的新图产生一组新的表征向量,然后将这组新的表征向量与原图产生的表征向量进行对齐,并将不属于同一结点的表征向量互相推远。虽然对比学习在提升图推荐系统的效果上作用十分明显,它的效果很大程度上依赖于数据增强的方法。绝大部分现有的图对比学习方法使用基于随机过程(stochastic-based)或基于经验的(heuristic-based)数据增强方法。虽然这些方法达到了不错的效果,但亦存在几种问题:首先,基于随机过程的图数据增强可能会损失图中重要的结构信息,从而误导模型;其次,基于经验的对比学习方法建立在对数据分布较强的假设上,而这会限制模型的普适性,并容易受数据中的噪声影响;再者,绝大部分基于 GNN 的对比学习推荐系统仍然存在图表征过平滑问题,无法有效地将正负样例区分开来。为了解决上述问题,本文重新探索了图对比学习的范式,并提出了一种简单且高效的图对比学习框架 LightGCL。在此新框架下,图数据增强是由奇异值分解及重构(Singular Value Decomposition and Reconstruction)来指导的。以此方式进行图数据增强具有多种好处:首先,奇异值分解重构所得的新图为全连接图,不但能挖掘局部的用户-物品交互信息,而且可以提取全局的协同过滤信号;其次,以奇异值分解重构作为数据增强的方法相比于随机过程或基于经验的方法含有更多有效信息;最后,由于该数据增强方法有效保存了原图的信息,我们得以进一步精简图对比学习的框架,将数据增强图的数量由两个减为一个,大大提升了训练效率。
本文提出了一种轻量而有效的图对比学习范式,现具体介绍如下。
与通常的协同过滤范式相类似,每个用户和物品都具有一个可学习的隐式表征向量,以表示结点的特征。LightGCL采取了常用的双层图卷积网络(Graph Convolutional Network,或简称 GCN),对用户与物品间局部的领域关系进行学习。在每一层图卷积网络中,每个结点的表征向量都会依着图的边传播到相邻结点。为了防止过拟合,LightGCL 采用了剩余连接(residual connection)的方法,使每个结点在信息传播和整合中不至于丧失自身的有效信息。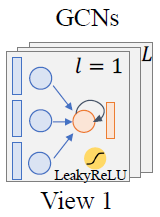
为了使图对比学习推荐系统能挖掘图中全局的结构信息,LightGCL 采用了奇异值分解重构的数据增强方法来探索图中隐藏的信息。具体而言,LightGCL 首先对用户-物品交互矩阵进行奇异值分解,得到两个包含交互矩阵行与行之间相关量矩阵的特征值向量的低阶矩阵,以及一个对角线上包含交互矩阵的奇异值的对角矩阵。将奇异值由大到小排列,越大的奇异值往往对应着矩阵中重要的组成成分。在计算机视觉和图像处理中常常使用保留图像较大的奇异值,丢弃较小的奇异值的方法进行图像去噪。本文借用这种想法,截取最大的 q 个奇异值,抛弃剩余的较小奇异值,并重构邻接矩阵。这个重构的邻接矩阵实际上是原零阶矩阵的低阶近似,不仅包含了原邻接矩阵中的重要组分信息,而且由于其为全连接图,考虑了每一对用户和物品之间的潜在关联,更能挖掘图中的全局信息。鉴于以上的优点,LightGCL 采用了这个重构的邻接矩阵作为对比学习中的增强图。然而,在大型矩阵上计算精确的奇异值分解需要很长的计算时间,在数据量庞大的推荐场景中并不实际。因此,本文采取了 Halko 等人于 2011 年提出的近似奇异值算法。近似奇异值算法是一种随机算法,主旨是首先以一个低阶的正交矩阵近似原矩阵的数值范围(range),然后再在这个低阶正交矩阵上进行奇异值分解,以近似原矩阵的奇异值分解。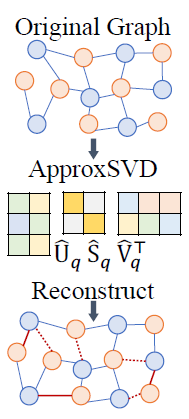
传统的图对比学习方法(如 SGL,SimGCL 等)需要创建两个增强图,而在原图上产生的表征向量并不参与对比学习。这些模型之所以采用这种低效的结构,可能是因为他们采用的基于随机过程的图增强方法可能对主任务的学习起到误导效果。然而,在本文提出的 LightGCL 框架中,增强图实际上包含奇异值分解带来的有效信息,可以加强主任务的学习。因此,我们得以将奇异值分解重构图产生的表征向量于原图产生的表征向量直接进行对比学习。这样一来,模型只需计算一个增强图,大大简化了对比学习的范式。而且,奇异值分解重构的图可以由低阶矩阵表示,而低阶矩阵大大提高了矩阵乘法的效率。
经过理论分析(如上图所示),LightGCL 的训练复杂度不到现有最佳图对比学习方法 SimGCL 的二分之一。
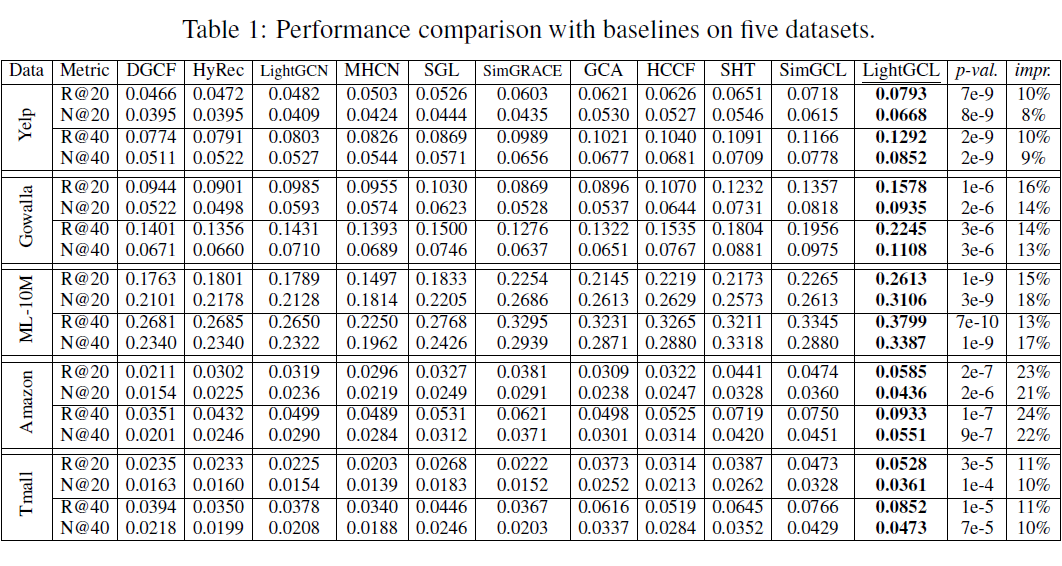
本文在五个大型真实数据集(Yelp, Gowalla, Movielens-10M, Amazon 和 Tmall)上进行了大量实验。数据集统计信息如下表。数据集均按照 7:1:2 的比例划分为训练集、验证集和测试集。本文采用全排列测试方式,以 Recall@N 和 NDCG@N 指标对预测准确性进行衡量。本文将 LightGCL 与来自 5 个类别的 16 个基准模型进行比较。
下图中的两个表格总结了 LightGCL 和各个基准模型在五个数据集上效果的对比。从结果中可以看出,对比学习方法(如 SGL, HCCF, SimGCL)具有明显的优势,而本文所提出的 LightGCL 在所有数据集上大幅超越了现有的对比学习方法,证明了本文所描述的方法的有效性。
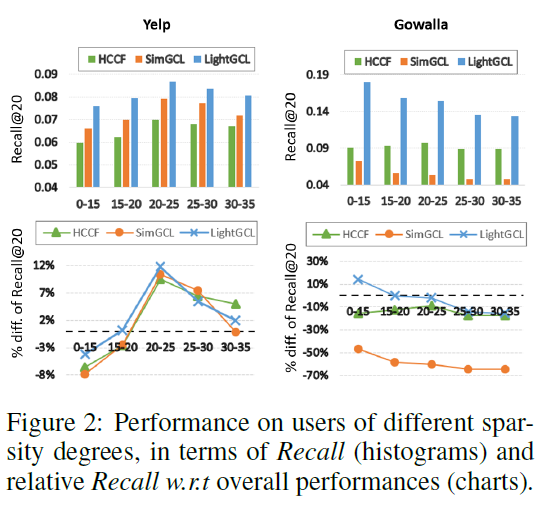
数据稀疏性(data sparsity)和流行偏见(popularity bias)是推荐场景下常见的两大问题,其根源在于数据分布的不均等。本文以实验衡量了 LightGCL 与基准模型面对不同程度的稀疏数据时的表现。如下左图所示,横轴代表用户的交互数量范围,纵轴代表对应用户组的召回效果及其相对于总召回效果的比例。可见在极稀疏的用户上,LightGCL 的表现优于基准模型。如下右图所示,横轴代表物品被交互的数量范围,纵轴代表对应物品组对总召回数值的贡献。可见在绝大部分物品组中,LightGCL 优于基准模型。这证明了 LightGCL 对抗数据稀疏和流行偏见的能力。
基于图神经网络的模型普遍具有过平滑的问题,即所学得的表征向量互相之间十分接近,难以区分;而基于图对比学习的方法由于致力于将表征向量互相推远,又可能导致表征向量空间中丧失应有的簇落结构(community structure)。本文通过测量学得表征的平均距离(MAD)以及表征可视化,探究并对比 LightGCL 和基准模型学习得到的表征分布。如上图所示,非对比学习方法(如 LightGCN 和 MHCN)呈现明显的过平滑显现,表现为所学得的表征向量密集扎堆,难以互相区分。而现有的对比学习方法(如 SGL 和 SimGCL)则存在两种问题:首先,表征向量在空间中的分布过于均匀,无明显的簇落结构,如 SGL 在 Yelp 上的可视化结果;其次,存在许多极小的聚落,在这些小聚落之中存在严重的过平滑问题,如 SimGCL 在 Gowalla 上的可视化结果。与这些现有模型相比,LightGCL 所学得的表征向量分布既保存了清晰的簇落结构,在簇落内部又合理分散。如下表所示,LightGCL 的 MAD 亦介于非对比学习方法和对比学习方法之间。
为了探究 LightGCL 作为一种范式的普适性,本文尝试将奇异值分解重构的数据增强方法替换为其他矩阵分解方法,以研究以矩阵分解指导对比学习这一想法的有效性。本文实现了两种 LightGCL 的变体:CL-MF 采用了预训练的矩阵分解模型作为数据增强图;CL-SVD++ 采用了考虑隐式用户反馈的 SVD++ 方法作为数据增强方法。由下表可见,通过利用预训练矩阵分解或 SVD++ 所得的信息,模型得以达到较为满意的效果,证明了矩阵分解指导对比学习的有效性。然而,这些变体不但训练效率较低,而且在效果上也逊于 LightGCL。本文探究了 LightGCL 对于超参数的敏感性。文章中选取了三种重要的参数:对比学习损失函数的系数、对比学习中的温度参数和近似奇异值分解算法的阶。如下图所示,在一定范围内,超参数的变化对模型效果的影响较小。
为了直观地展示本文所述模型在去除噪声和预测用户潜在兴趣上的有效性,本文进行了一个案例研究。从下图可见,Yelp 数据集中的 26 号用户的交互历史主要发生在两个地点:克利夫兰(很可能为该用户的住处)和亚利桑那(该用户可能在此处旅行)。在奇异值分解重构的过程中,这些被该用户访问的地点获得了一个新的权重,代表他们潜在的重要性。可见 2583 号地点,一家位于亚利桑那州的租车公司,被分配了负权重。这与常识相符,因为人们通常不会在一次旅途中访问多家租车公司。奇异值分解重构图同样会为不可见的连接判断重要性,比如 2647 号和 658 号地点(均为克利夫兰的餐厅)便被赋予了较高的权重。值得注意的是,在挖掘图中信息时,LightGCL 并不会忽略亚利桑那这个较小的簇落,这让用户较小的兴趣类别不至于被主要的兴趣类别所掩盖。

本文为图对比学习提出了一种简单且高效的数据增强范式。本文探索了使用奇异值分解重构进行数据增强的方法,并证明了这种方法在对抗数据稀疏、流行偏见和过平滑等问题上有良好表现。本文提出的 LightGCL 框架更提高了对比学习的训练效率,且在多个数据集上达到目前的最佳效果。本文希望这种新式的图对比学习框架可以为图对比学习相关工作带来启发。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
