PinnerSAGE、ENSFM、MHCN、FFM…你都掌握了吗?一文总结推荐系统必备经典模型(二)
机器之心专栏
第 1 期:DSSM、Youtube_DNN、SASRec、PinSAGE、TDM、MIMD 第 2 期:PinnerSAGE、ENSFM、MHCN、FFM、FNN、PNN 第 3 期:Wide&Deep、DCN、xDeepFM、DIN、GateNet、IPRec
具体到推荐算法/模型部分,一般包括两大环节:召回和排序。
召回主要是指“根据用户的兴趣和历史行为,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品”。召回方法主要要求具备处理数据量大、处理速度快的能力。经典的召回方法包括基于统计的启发式召回和基于深度学习的向量召回方法。本报告主要聚焦于基于深度学习的召回方法。 排序则是指根据多类特征,使用模型进行个性化的推荐。排序环节还可以进一步细分为粗排、精排和重排。
1、 PinnerSage
PinnerSage的处理步骤具体如下:
第一步,聚类用户行为。具体要求是:类中的物品尽可能相似,并且聚类数目是由算法决定并不是人为规定的。所以选择了Ward层次化聚类算法来达到上述目标。首先,算法1将每个pin分配到它自己的集群。在随后的每一步,将集群内方差增加最小的两个集群合并在一起。假设经过一些迭代后,我们有集群{C1,C2,. .},集群Ci和Cj之间的距离表示为d_ij。那么,如果两个聚类Ci和Cj被合并,其距离将被更新如下:
第二步:表示每个聚类结果。为了使表示结果更具有鲁棒性,对于每个聚类表示并不是取所有embedding的均值,而是选择类中的某个物品,使这个物品与类中的其他物品距离最小,具体优化目标如下:
2、 ENSFM
图2. ENSFM框架说明,显示了如何以矩阵分解的方式表示FM(为了清晰起见,图中没有显示一阶线性回归部分)
(2) 通过记忆策略设计,我们将上式的调频得分重新表述为一个没有任何近似的广义矩阵分解函数:yˆ_F M (x) = (h_aux)^T (p_u⊙ q_v) ,其中,p_u、q_v和h_aux是辅助向量,分别表示用户u、项目v和预测参数。
(3) 本文提出了一种有效的mini-batch非采样算法来优化ENSFM框架,由于在每次参数更新中都考虑了所有的样本,因此更加有效和稳定。
上式中的二阶特征交互f(x),可以重写如下:
3、 MHCN
MHCN引入超图模拟社交关系中的高阶关系。超图推广了边的概念,使其连接到两个以上的节点,为建模用户之间复杂的高阶关系提供了一种自然的方法。尽管超图在用户建模方面比简单图有很大的优势,但是在社交推荐方面,超图的优势还没有得到充分的开发。本文通过研究超图建模和图卷积网络的融合潜力,填补了这一空缺,提出了一种多通道超图卷积网络(MHCN),通过利用高阶用户关系来增强社交推荐。从技术上讲,通过统一形成特定三角形关系的节点来构造超图,这些三角关系是具有底层语义的三角主题的实例(如图3所示)。
然而,尽管多通道设置有好处,但聚合操作也可能掩盖不同类型的高阶连接信息的固有特征,因为不同的通道会学习不同超图上分布的嵌入。为了解决这一问题并充分继承超图中丰富的信息,本文在多通道超图卷积网络的训练中集成了一个自监督任务,提出通过利用超图结构来构造自监督信号,全面用户表示应该反映不同超图中用户节点的局部和全局高阶连接模式。具体来说,利用了超图结构中的层次结构,并分层最大化了用户表示、以用户为中心的子超图和全局超图之间的互信息。互信息度量了子超图和整个超图的结构信息量,通过减少局部和全局结构不确定性来推断用户特征。最后,在主&辅学习框架下,将推荐任务和自监督任务统一起来。通过联合优化这两个任务并利用所有组件的相互作用,推荐任务的性能获得了显著提高。
多通道超图卷积。本文使用了三种通道设置,包括“社交通道(s)”、“联合通道(j)”和“购买通道§”,以应对三种类型的三角形主题,但通道的数量可以调整,以适应更复杂的情况。每个通道负责编码一种高阶用户关系模式。因为不同的模式可能会对最终的推荐性能表现出不同的重要性,所以直接将整个基本的用户嵌入p(0)提供给所有通道是不明智的。为了控制从基本的用户嵌入p(0)到每个通道的信息流,设计了一个具有自门控单元(SGU)的预过滤器,其定义为:
令𝑩=s⊙sT和𝑼=𝑺 - B分别表征双向和单向社交网络的邻接矩阵。我们用A_Mk表示图诱导的邻接矩阵,(A_Mk)_ i,j =1是指顶点𝑖和顶点𝑗出现在M_k 的一个实例中。因为两个顶点可以出现在M_k 的多个实例中,(A_Mk)_ i,j计算公式如下:
学习用户表示。在通过𝐿层传播用户嵌入后,平均每一层获得的嵌入,以形成最终的特定于通道的用户表示:
为了避免过度平滑问题,利用注意力机制对不同通道的用户嵌入信息进行选择性聚合,以形成全面的用户嵌入。对于每个用户𝑢,学习一个三元组(𝛼𝑠、𝛼𝑗、𝛼𝑝)来测量三个特定于通道的嵌入对最终推荐性能的不同贡献。注意力函数f_att的定义为:
需要注意的是,由于显性的社交关系是嘈杂的,孤立的关系并不是亲密关系的强烈信号,丢弃那些不属于以上定义的图的实例。因此,不能直接对显式社交网络𝑺做卷积操作。此外,在用户-物品交互图上进行简单的图卷积,对购买信息进行编码,并补充多通道超图卷积。简单图卷积定义为:
这样,就考虑了子超图中每个用户的权重,形成子超图嵌入z_u。类似地,定义了另一个函数𝑓out2,这实际上是一个平均池化,将获得的子超图嵌入到一个图级表示中:
1、 FFM
FFM是在FM的基础上引入了filed的概念,把几个相同性质的特征归结为一个filed。如,不同的日期属于一个field,不同的年龄属于一个filed。不同field中的特征单独进行one—hot。FFM认为,一个特征和另一个特征的关系,不仅仅由这两个特征决定,还应该和这两个特征所在的field有关。因此,每个特征,应该针对其他特征的每一种field 都学一个隐向量,也就是说,每个特征都要学习 f 个隐向量,那么FFM的二次项,有nf个隐向量。
文中使用的样例如下:
2、 FNN
第一种模型是FNN结构。输入的分类特征是由字段组成的独热编码。对于每个字段,例如城市,有多个单元,每个单元代表这个字段的一个特定值,例如,城市=伦敦,只有一个正的(1)单元,而其他的都是负的(0)。编码的特征,表示为x,是许多CTR估计模型以及本文DNN模型的输入,如图6的底层所描述的。从图16可以看出,FNN的思想非常简单——直接在FM上接入若干全连接层。利用DNN对特征进行隐式交叉,可以减轻特征工程的工作,同时也能够将计算时间复杂度控制在一个合理的范围内。
最底层是field-wise one-hot的。文中从上到下对整个模型进行了说明。最上面一层用sigmoid来输出预估的CTR值:
初始化最底层的权重,本文采用了RBM和DAE来做预训练。对于每个field,只有1维是1,然后采样m个负单元,图中黑色的单元是没有被采样到的,因此在预训练的过程中将被忽略。用对比散度来训练RBM,用SGD来训练DAE,然后将训练好的dense vector作为剩余网络部分的输入。与FNN一样,也使用back-pop来fine-tuning模型。为了防止过度拟合,将L2正则化项添加到损失函数中,损失函数如下:
3、 PNN
预测用户的反应,如点击和转换,是非常重要的,并且已经在许多网络应用中使用,包括推荐系统、网络搜索和在线广告。这些应用中的数据大多是分类的,并且包含多个fields;针对这些数据的一个典型的表示方法是通过单次编码将其转化为高维稀疏二进制特征表示。面对极端的稀疏性,传统模型可能会限制其从数据中挖掘浅层模式的能力,即低阶特征组合。另一方面,由于巨大的特征空间,像深度神经网络这样的深度模型不能直接应用于高维度的输入。本文提出了一个基于产品的神经网络( Product-based Neural Networks,PNN),它有一个嵌入层来学习分类数据的分布式表示,一个产品层来捕捉领域间类别的互动模式,以及一个全连接层来探索高阶特征互动。
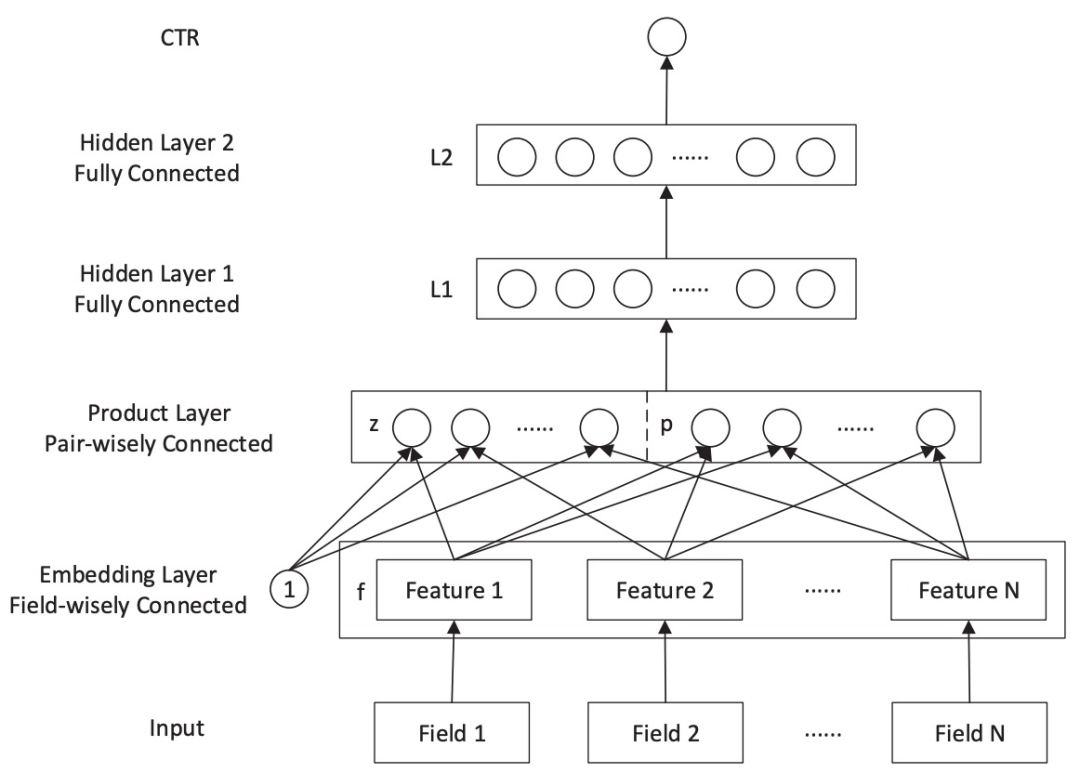 图8. PNN结构
图8. PNN结构
PNN结构如图8所示。输入层(Input):一个类别型特征就是一个Field。比如用户信息包括:性别、职业等,这里的性别是一个Field,职业是另一个Field。图18中的Input是one-hot之后的,而且只给出了类别型特征。所以每个Field i都是一个向量,向量的大小就是类别型特征one-hot之后的维度。所以不同Field的维度是不同的。
嵌入层(Embedding):是Field-wisely Connected,就是每个Field只管自己的嵌入,Field之间网络的权重毫无关系,自己学习自己的。而且只有权重,没有bias。不同的Field之间没有关系。一个Field经过嵌入后,得到一个Feature,也就是对应的嵌入向量(Embedding Vector)。其维度一般是预先设定好的固定值,论文中采用的是10。也就是说,不同Feature的维度经过embedding后都是一样的。
Product层:product思想来源于,在CTR预估中,认为特征之间的关系更多是一种and“且”的关系,而非add"加”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。Product层可以分成两个部分,一部分是线性部分l_z,一部分是非线性部分l_p。二者的形式如下:
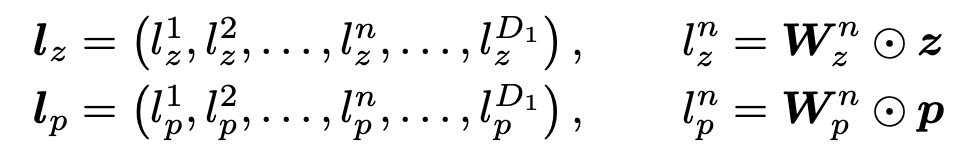 通过引入一个 "1 "的常数信号,product层不仅可以生成二次信号p,还可以保持线性信号z,如图18所示。
通过引入一个 "1 "的常数信号,product层不仅可以生成二次信号p,还可以保持线性信号z,如图18所示。
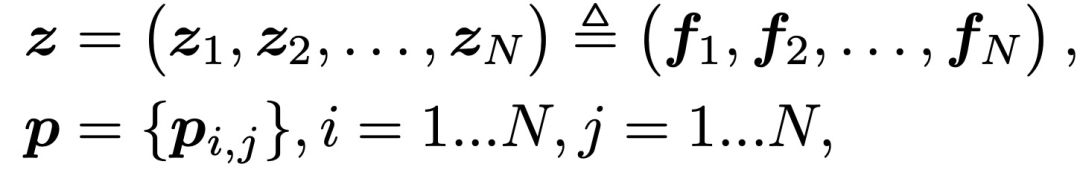 其中,f_i∈RM是field i的嵌入向量。p_i,j = g(f_i, f_j )定义了成对的特征交互。PNN模型可以通过设计不同的操作而有不同的实现方式。本文提出了PNN的两个变体,即IPNN(Inner Product-based Neural Network)和OPNN(Outer Product-based Neural Network)。field i的嵌入向量f_i,是嵌入层的输出:
其中,f_i∈RM是field i的嵌入向量。p_i,j = g(f_i, f_j )定义了成对的特征交互。PNN模型可以通过设计不同的操作而有不同的实现方式。本文提出了PNN的两个变体,即IPNN(Inner Product-based Neural Network)和OPNN(Outer Product-based Neural Network)。field i的嵌入向量f_i,是嵌入层的输出:
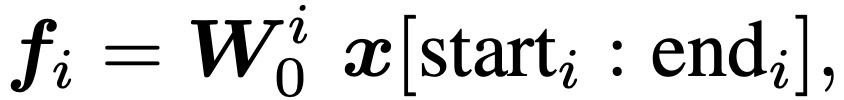 其中,x是包含多个field的输入特征向量,x[start_i: end_i]代表field i的独热编码向量。W_0代表嵌入层的参数,(W_0)i∈RM×(end_i-start_i+1)与field全连接。
其中,x是包含多个field的输入特征向量,x[start_i: end_i]代表field i的独热编码向量。W_0代表嵌入层的参数,(W_0)i∈RM×(end_i-start_i+1)与field全连接。
最后,将监督训练应用于最小化对数损失,以捕捉两个概率分布之间的分歧:
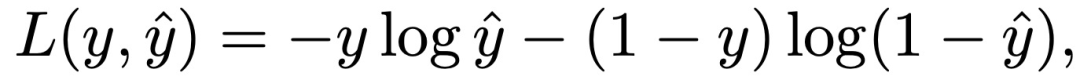 IPNN
IPNN
在IPNN中,首先将成对的特征交互定义为矢量内积:g(f_i, f_j ) =<f_i, f_j>。在恒定信号 "1 "的情况下,线性信息z被保留为:
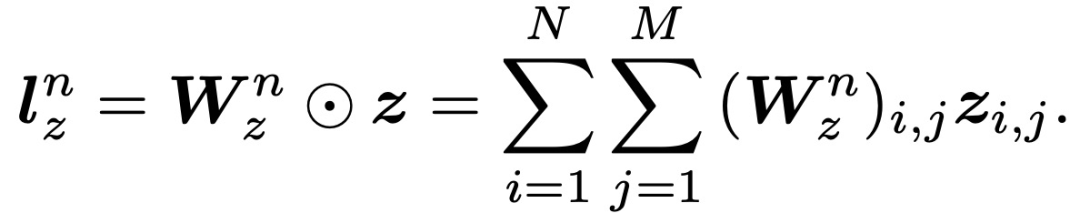 至于二次信息p,g(f_i, f_j )的成对内积项形成一个方形矩阵p∈RNxN。
至于二次信息p,g(f_i, f_j )的成对内积项形成一个方形矩阵p∈RNxN。
受FM启发,作者提出了矩阵分解的想法,以降低复杂性。通过引入(W_p)n=θn θnT的假设,其中,θn∈RN,简化l_1的表述为:
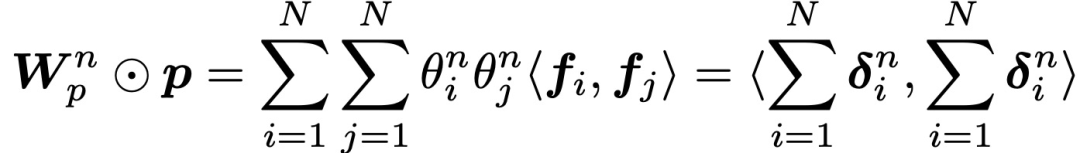 通过对第n个节点的一阶分解,得到l_p如下:
通过对第n个节点的一阶分解,得到l_p如下:
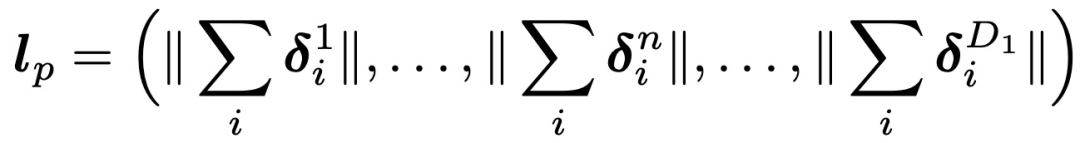 更一般地说,我们讨论(W_p)n的K阶分解。(W_p)n=θnθnT只是强假设下的一阶分解。一般的矩阵分解方法可以由下式推导出来:
更一般地说,我们讨论(W_p)n的K阶分解。(W_p)n=θnθnT只是强假设下的一阶分解。一般的矩阵分解方法可以由下式推导出来:
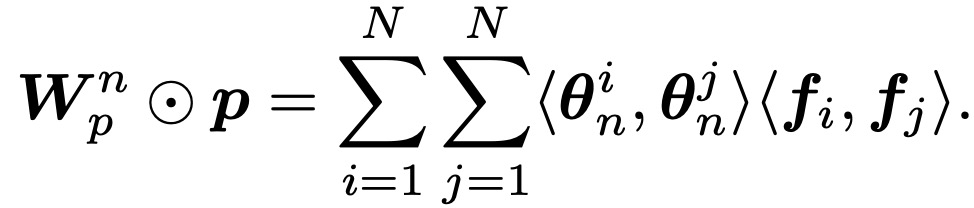
OPNN
矢量内积将一对矢量作为输入,输出一个标量。与此不同的是,矢量外积需要一对矢量并生成一个矩阵。IPNN通过向量内积定义了特征交互,接下来我们讨论基于外积的神经网络(OPNN)。IPNN和OPNN之间的唯一区别是二次项p。在OPNN中,定义特征交互如下:
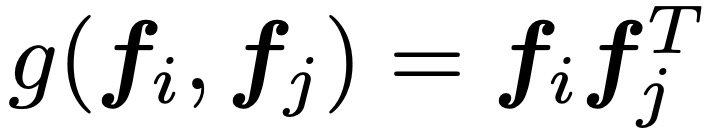
此时,OPNN复杂度比IPNN还高。作者引入sum pooling降低复杂度,重新定义p的表述如下:
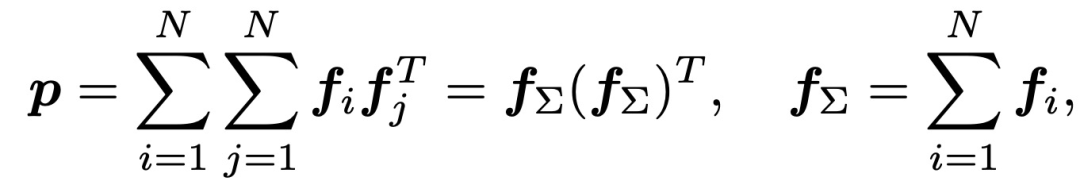
| 项目 | SOTA!平台项目详情页 |
|---|---|
PNN | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/pnn |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。
微信扫码关注该文公众号作者
戳这里提交新闻线索和高质量文章给我们。
来源: qq
点击查看作者最近其他文章