推荐系统正变得越来越懂你。从刷短视频刷到停不下来,到新闻页面满屏都是你关心的资讯,再到各种社交平台和购物平台化身精准“种草”机,直切你的兴趣偏好……一条条你可能感兴趣的优质内容,正被推荐系统源源不断地过滤筛选,然后通过互联网送到你的眼前。基于深度学习的推荐系统堪比“读心术”,它能够在短时间内带给用户大量的愉悦感和满足感,提高内容创作者、商家的转化率,并带给平台越来越强的用户黏性和更大的商业回报。作为各大主流平台留客增收的一大“顶梁柱”,推荐系统的规模正越变越大,难题也随之而来——传统CPU计算资源吃紧,CPU资源利用率的提升已经逼近极限。当底层硬件基础设施的瓶颈,愈发掣肘推荐系统训练和部署的速度,国内某拥有上亿规模用户的互联网头部企业机器学习团队决定将支撑搜广推场景的算力资源从CPU大规模升级至NVIDIA GPU。基于这一思路,其已上线业务的训练性价比实现了2~6倍的提升。具体是怎么做到的?近日,NVIDIA加速计算专家团队技术负责人Gems Guo接受芯东西专访,解读了背后的技术秘籍。
对于用户规模上亿的互联网综合平台,每天都要支撑几十亿的检索流量,需要更强大的推荐/广告/搜索模型,来更懂每一位用户的兴趣偏好。在这一过程中,深度学习算法扮演了关键角色。从2016年谷歌发表了基于Embedding + MLP的网络结构的Wide & Deep模型和YouTube深度学习推荐模型起,深度学习就开始接过搜广推场景的推荐算法大旗,通过累计分析用户行为,映射成兴趣体系,日积月累形成用户的长期兴趣画像,进而提供更贴心的优质服务。Wide & Deep模型论文链接:
https://arxiv.org/abs/1606.07792推荐算法利用了人性普遍存在的社会相似性,即默认你感兴趣的具备趋同性。例如,如果你下单了A商家的化妆品,那你大概率也会考虑B商家的化妆品,如果你和另一位用户喜好相似,那么他爱看爱买的东西,你很可能也会有兴趣。学习的优质数据越多,训练出的算法也变得更加准确。互联网飞速发展带动数据量的爆炸式增长,要训练的数据越来越多,深度学习推荐模型的参数规模不断变大。两年前,Instagram训练的推荐模型参数规模已经高达10TB。如果用传统方法训练和调优这些庞大的模型,动辄花费几个月的时间。为此,算法工程师们通过在深度学习框架上采用分布式训练,将数据或模型拆分到多个处理器上分别做运算,再将结果合并得出最终的完整模型,从而大大压缩模型训练时间。起初互联网团队们通过优化TensorFlow PS-Worker分布式训练框架,将CPU使用率提高到90%以上。但随着模型更加复杂,对训练框架进行更深入的优化变得举步维艰。扩展更多的CPU资源成本较高,且CPU异步训练导致收敛性和稳定性变差,可能会影响算法效果和稳定性,致使计算、存储、网络面临全新挑战。为了扫除影响效率的阻碍,机器学习团队决定对算力基础设施进行一场“釜底抽薪”的升级。
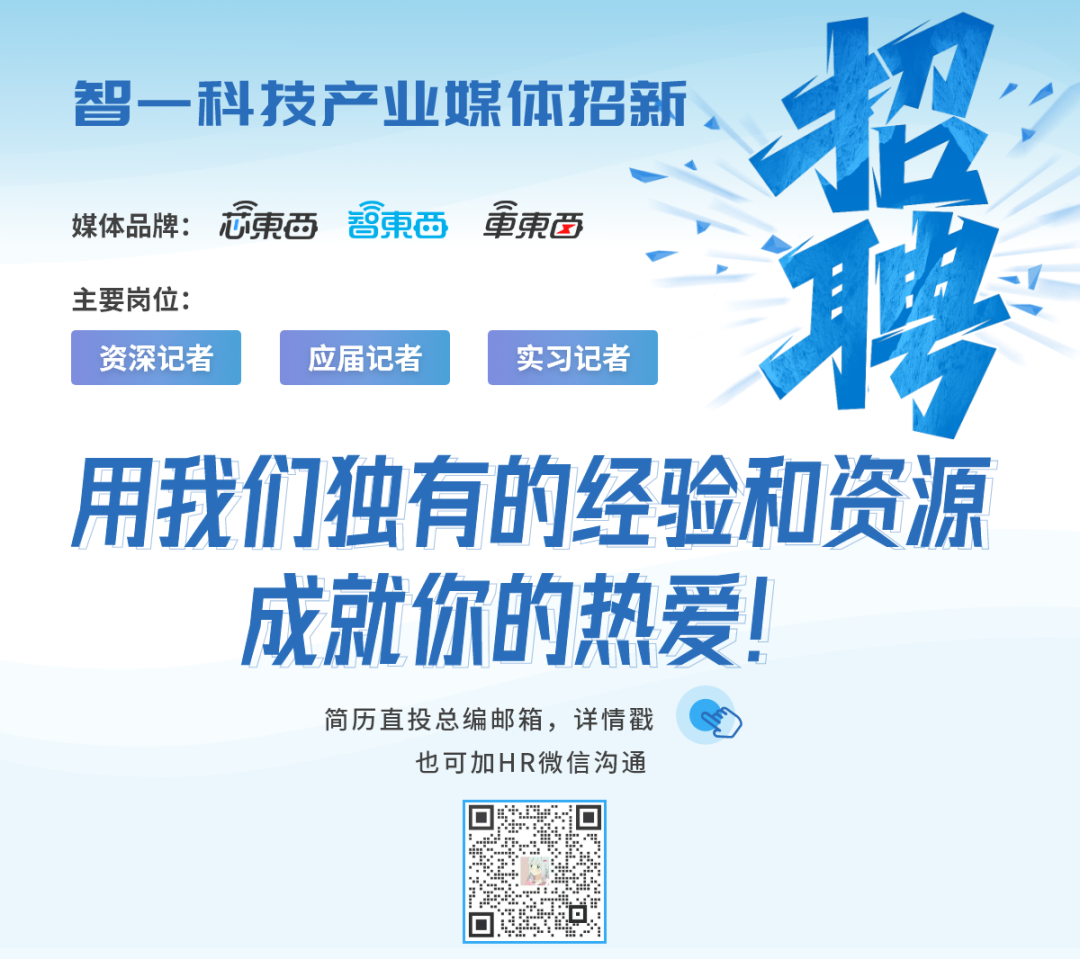
NVIDIA GPU在计算密集型任务方面具有得天独厚的优势,推荐模型中矩阵计算占比提升,使NVIDIA GPU成为更好的加速选择,能够实现远高于CPU的训练速度。嵌入(Embeddings)是深度学习推荐系统中影响模型精度的关键模块,通常位于输入层之后、“特征交互”和全连接层之前。它将每个感兴趣的对象(用户、产品、类别等)表示为数字向量。嵌入层的特点是大而稀疏,拥有庞大的参数量,但查找和更新所需要的计算量很小。比如谷歌Wide & Deep模型的全连接层只有几百万个参数,而其嵌入层可以有数十亿个参数。这与其他深度学习模型形成了鲜明对比,以经典自然语言处理模型BERT为例,BERT的嵌入层只有数百万个参数,其密集的前馈网络和注意力机制层则由数亿个参数组成。比如某业务场景的推荐模型是一种深度兴趣进化网络(DIEN)模型,嵌入层参数规模高达数百亿,每个样本中有数千个特征字段。由于输入特征的范围事先未知且不固定,团队使用哈希表在输入嵌入层之前唯一地标识每个输入特征。在训练嵌入层的过程中,嵌入表的查找和更新和GPU通信非常耗时,会面临大小和访问速度两大挑战。在推荐/广告/搜索场景,用户和内容高频变化,致使训练出的模型生命周期短,具有大规模稀疏特征。随着在线平台的用户数、产品数上涨,嵌入表的大小也不断增加,数百GB到TB级不胜枚举,需占用大量存储资源,同时也会造成很大的通信开销。CPU主存储器具有高容量,但带宽有限,高端型号通常在几十GB/s的范围内。GPU则内存容量有限,但带宽很高,像NVIDIA A100 GPU的缓存也就80GB,却能提供高达2TB/s的内存带宽。一个可行办法是将整个嵌入表保留在主存上,但这会导致极低的吞吐量,使系统无法及时重新训练。另一个办法是将嵌入分散在多个GPU和多个节点上,这又会受通信瓶颈的限制。为此,技术团队决定将HugeCTR TensorFlow插件集成到了基于A100 GPU的训练系统中。使用完全一样的模型结构、优化器和数据加载器,在单个A100 GPU上,HugeCTR TensorFlow插件实现了比原始TensorFlow嵌入11.5倍的加速。在弱缩放情况下,8x A100 GPUs上的迭代时间仅略增至1x A100 GPU的1.17倍。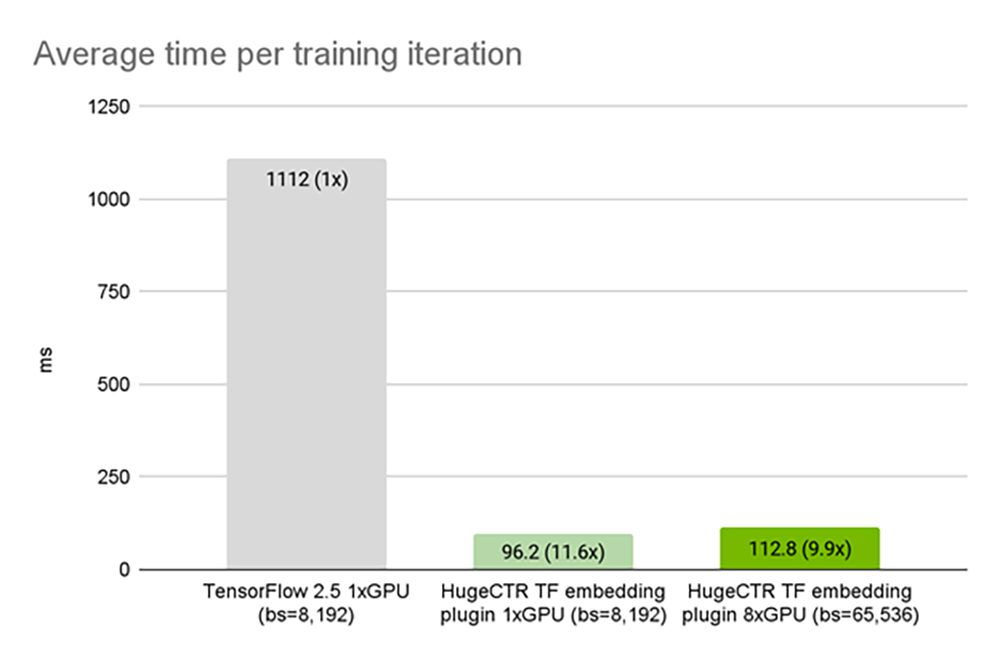
▲NVIDIA DGX A100 80GB上的HugeCTR TensorFlow嵌入插件性能
“一台配备8x A100 GPUs的单机训练任务可以替代几千核CPU的分布式训练任务。成本也大大降低。这是初步的优化结果,未来仍有很大的优化空间。”团队负责人说。在他看来,A100+HugeCTR的软硬一体化设计给搜广推场景的模型训练效率带来了质的飞跃。基于此,该项目在纯GPU显存模式下能轻松支撑100GB模型;如果加上异构的参数存储,支持TB级模型也有余力。最终在训练系统方面,以前需要几千核CPU训练的任务,现在用1台NVIDIA HGX A100服务器就能完成;在推理方面,借助NVIDIA A30服务器及多种优化模型,系统可以支撑算力复杂度10倍的模型上线。
HugeCTR,是NVIDIA为优化大规模推荐系统量身定制的一个端到端训练框架,也是GPU加速的推荐系统框架NVIDIA Merlin的核心组件。HugeCTR能够充分利用GPU资源,加快包括数据预处理、训练、推理的推荐系统开发所有阶段。在此前的权威AI基准测试MLPerf中,HugeCTR将DLRM推荐模型的性能拔高到其他框架的大约8倍。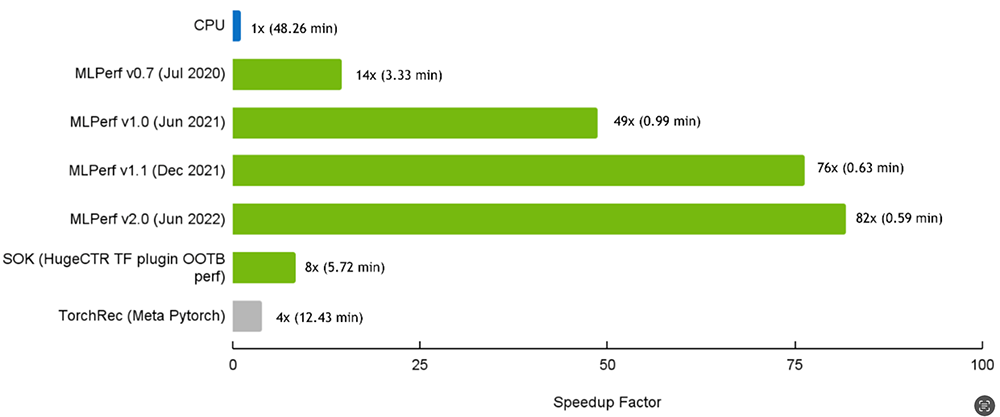
▲MLPerf测试结果对比
针对嵌入表过大、显存不足、通信瓶颈三大训练挑战,HugeCTR用6招制敌:(1)GPU加速哈希表:HugeCTR实现了自己的嵌入层,其中包括GPU加速哈希表、以节省内存的方式实现的高效稀疏优化器、各种嵌入层分布式策略等。哈希表实现基于GPU数据科学与分析套件RAPIDS cuDF,能实现比CPU实现高达35倍的加速。(2)模型并行性:考虑到可扩展性,HugeCTR默认支持嵌入层的模型并行性。嵌入表分布在多个可用的GPU和节点上,解决显存有限的问题,同时提高查表效率。全连接层采用数据并行。
▲HugeCTR中的嵌入层并行性
(3)先进网络技术:HugeCTR利用NVIDIA集合通信库(NCCL)作为其内部GPU通信原语,并结合NVLink、RDMA等NVIDIA先进互连技术,来优化节点内、节点间、多GPU之间的高速通信。(4)混合精度训练:HugeCTR能够发挥NVIDIA Tensor Cores的计算优势,用FP16半精度计算代替FP32单精度做加速矩阵乘法,在不牺牲模型准确性的前提下,提高训练速度,减少占用的存储资源。(5)CUDA Kernel融合:HugeCTR将池化与全连接操作合并到一个CUDA Kernel进行,通过减少与存储单元频繁交互,缓解内存带宽压力。(6)CUDA Graph:HugeCTR在计算过程中会启动多个CUDA Kernel,CUDA Graph通过异步方式,能够隐去不同CUDA Kernel启动之间出现的不必要开销,降低整体延迟。
▲HugeCTR以及两款 Tensorflow libraries是NVIDIA Merlin的训练“主心骨”
推荐系统的推理则对高效部署、低延迟提出更高要求,针对这些挑战,HugeCTR通过使用参数服务器(HPS)和嵌入多个模型实例之间共享的缓存,在多个GPU上提供并发模型推理执行。HugeCTR首创了带GPU缓存的参数服务器,通过使用集群中的存储资源来扩展GPU内存,实现嵌入表分级存储,这样就能综合利用不同存储介质的特性,并对CUDA Kernel、显存等进行优化,从而提高整体访问效率,最终实现推理加速。NVIDIA还提供有HugeCTR to ONNX转换器,这是一个Python包,可将HugeCTR模型自动转换成AI模型的开源格式ONNX。借助这个工具,用户便能够使用不同框架来训练推荐模型。Merlin 对于 Tensorflow的用户还提供了开箱即用的 library – Sparse Operation Kit 给TF1 用户,Distributed Embedding给TF2用户,来帮助用户用简单几行代码实现在多个GPU间通过模型并行的方式使用嵌入表,这些功能进一步提高易用性和通用性,对于TensorFlow上运行的大多数推荐模型,仅更改少数代码即可实现计算加速。因此,即便研发能力不像案例中这么强大的中小企业,也能利用Merlin的 TF libraries实现更低成本的基于GPU训练大规模推荐模型。NVIDIA加速计算专家团队技术负责人Gems Guo告诉芯东西,在该项目中积累的经验,将融入Merlin HugeCTR的后续迭代中。不同企业面临的实际业务需求不同,对推荐系统基础设施的设计会存在差异化。团队负责人认为,NVIDIA提供的端到端推荐系统解决方案,从性能及搭建基础模型的能力上,足以满足大多数企业的基本需求。GitHub链接:
https://github.com/NVIDIA-Merlin/HugeCTR
随着推荐算法日益成熟,互联网企业已经逐渐淘汰低效的大众营销策略,转而向每一位用户提供精准推荐和个性化服务,为他们高效筛选出感兴趣的信息。大量企业实践证明,有效的推荐系统能够转化成显著的营收增长,带给企业巨大的商业价值。如今,推荐系统已经成为许多互联网巨头核心业务背后的一大关键优势。迈向更复杂的推荐系统,硬件资源利用率已是掣肘算法迭代优化的主要因素,在互联网平台的推荐系统实践中,我们看到借助Merlin HugeCTR,1台A100 GPU训练系统比几千核的分布式CPU训练系统更能打,切实做到了大降训练成本。