【新智元导读】要说ChatGPT已经是核弹级的现象,那么微软今天发布的Visual ChatGPT可以称的上宇宙大爆炸。在视觉模型加持下的ChatGPT,聊天生图全拿捏了。
刚刚,微软亚研院发布了一个炸弹级模型Visual ChatGPT。
论文地址:https://arxiv.org/abs/2303.04671以前的ChatGPT虽然具有卓越的对话能力和推理能力,但也有短板——还不能处理或生成视觉图像。而Visual Transformers或Stable Diffusion,虽然在视觉理解和生成能力上很强大,却只有一轮固定的输入和输出。微软亚研院学者提出的模型,就把视觉模型信息注入了ChatGPT,使用户能够与ChatGPT以语言和图像的形式交互,还能提供复杂的视觉指令,让多个模型通过多步骤协作。微软前不久推出的Kosmos-1,就属于多模态大语言模型,传言下周发布的GPT4,据说也是转向了多模态。看来,微软在下一盘多模态的大棋。
注入视觉模型后,ChatGPT直接化身艺术大师,想要什么作品,动动嘴就行了。-帮我画一个苹果。Visual ChatGPT直接生成了一张画好的图。这还仅是前菜,Visual ChatGPT各种画风全能hold住,比如:另外,上色、「抠图」、深度图、基于深度图再生成图片都能拿捏。一张简陋的图经过你的精心调教后,就变成了这个样子。当然了,Visual ChatGPT没有忘本,让它进行创作的同时,还能描述图片、回答问题。有了Visual ChatGPT的加持,微软必应简直可以制霸全世界了。Prompt Manager,让视觉模型立刻和ChatGPT合体
当红炸子鸡ChatGPT能输入输出文字类的信息,但是在图像理解和生成方面能力有限。Visual ChatGPT并非是从头训练的,而是直接基于ChatGPT构建,并向其注入了许多可视化模型(VFMs)。Stable Diffusion就是可视化模型的典型代表。VFMs虽然在文本-图像生成上展现出巨大能力,但在人机交互上却不如对话语言模型灵活。微软亚研院的研究人员便get了一个点,将这两者结合,提出Visual ChatGPT,岂不是强强联合。点子有了,那视觉模型信息如何注入ChatGPT呢?就是通过一系列提示。论文中提出了Prompt Manager,具体步骤是——1 首先明确告诉ChatGPT每个VFM的能力,并指定输入-输出格式。2 然后转换不同的视觉信息,比如将Png图、深度图和掩模矩阵,转换为语言格式。在Prompt Manager的帮助下,ChatGPT可以利用这些VFMs,并以迭代的方式接收其反馈,直到满足用户的要求或达到结束条件。如图,上传一个黄色花朵的图像,然后输入一个复杂语言指令「请根据图像的预测深度生成一朵红色花朵,然后一步一步地把它做成卡通形象」。首先应用深度估计模型来检测深度信息,然后利用深度图像模型生成一个带有深度信息的红色花朵图形,最后利用基于Stable Diffusion的风格转换VFM,将该图像转化为卡通风格。在上述管道中,Prompt Manager通过提供可视化格式的类型,和记录信息转换的过程,来充当ChatGPT的调度器。最后,当 Visual ChatGPT从Prompt Manager获得「卡通」提示时,将结束执行管道,并显示最终结果。
对于一个由N个问题-答案对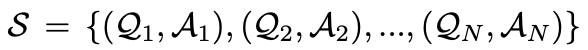 构成的集合,想要从第i轮对话中得到答案
构成的集合,想要从第i轮对话中得到答案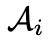 ,就需要一系列的VFM和中间输出。我们记第i轮对话中,第j次的工具调用中间答案
,就需要一系列的VFM和中间输出。我们记第i轮对话中,第j次的工具调用中间答案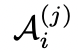 。这种工作机制可用一个公式表示,这个公式也定义了什么是Visual ChatGPT。
。这种工作机制可用一个公式表示,这个公式也定义了什么是Visual ChatGPT。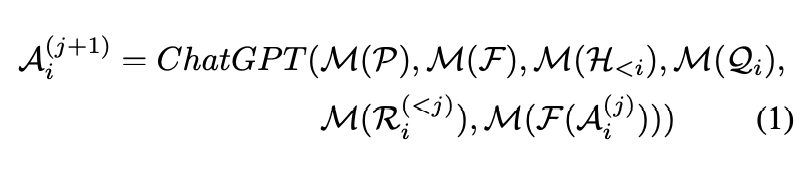
其他符号代表:P是全局原则,F是各个视觉基础模型,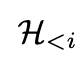 是历史会话记忆,
是历史会话记忆,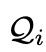 是这一轮的用户输入,
是这一轮的用户输入,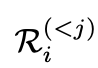 是这轮对话里的推理历史,
是这轮对话里的推理历史,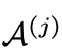 是中间答案,M是Prompt Manager,用来把上面各个功能转化成合理的文本prompt,进而将其交给ChatGPT处理。
是中间答案,M是Prompt Manager,用来把上面各个功能转化成合理的文本prompt,进而将其交给ChatGPT处理。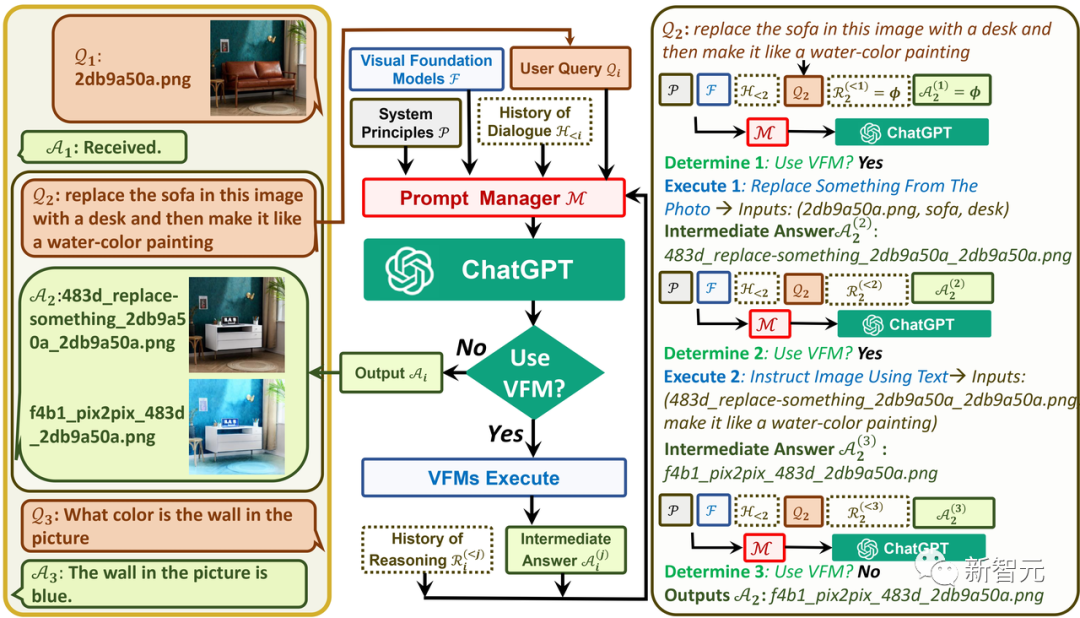
左边是进行的三轮对话;中间是Visual ChatGPT如何迭代调用VFMs并提供答案的流程图;右侧是第二个QA的详细过程。Visual ChatGPT为了能让不同的VFM理解视觉信息并生成相应答案,需要设计一系列系统原则,并将其转化为ChatGPT能够理解的提示。通过生成这样的提示,Prompt Manager能够帮助Visual ChatGPT完成生成文本、图像的任务,能够访问一系列VFM并自由选择使用哪个基础模型,提高对文件名的敏感度,进行链式思考和严格推理。Prompt Manager需要帮助Visual ChatGPT区分不同的VFM,以便准确地完成图像任务。为此,Prompt Manager对各个基础模型的名称、应用场景、输入和输出提示以及实例给出了具体定义。Prompt Manager会对用户新上传的图像生成唯一文件名,并生成假的对话历史,其中提到该名称的图片已经收到,这样可以在涉及引用现有图像的查询时忽略文件名的检查。Prompt Manager会在查询问题之后加上一个后缀提示,来确保成功触发VFM,强制Visual ChatGPT进行思考,给出言之有物的输出。VFM给出的中间输出,Prompt Manager会为其生成链式文件名,作为下一轮内部对话的输入。ChatGPT生成最终答案要经历一个不断迭代的过程,它会不断自我询问,自动调用更多VFM。而当用户指令不够清晰时,Visual ChatGPT会询问其能否提供更多细节,避免机器自行揣测甚至篡改人类意图。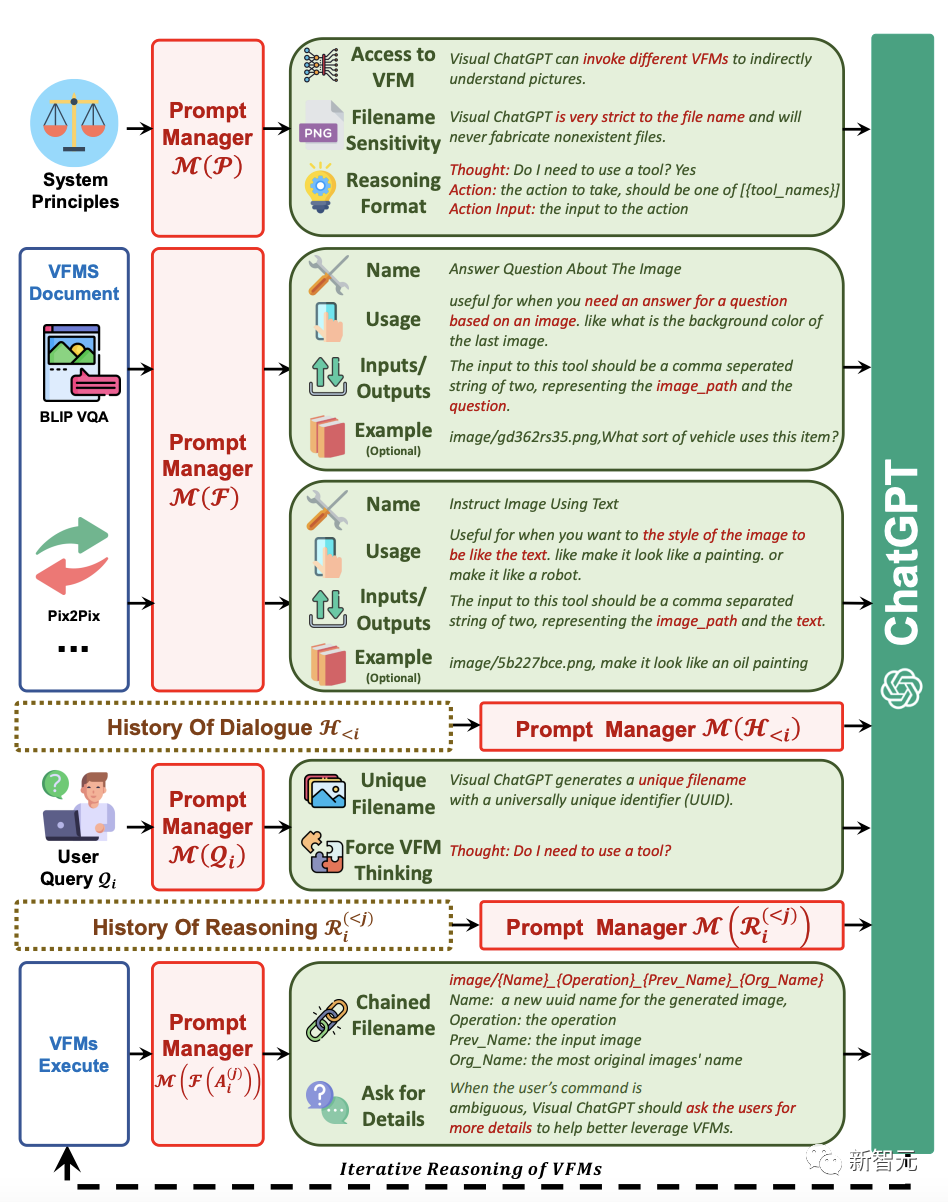
通过修改self.tools来调整模型的使用数量,便可以节省显存。
此外,论文还分析了在各个模块,如果Prompt Manager的设计不到位,会各自出现什么问题。比如,对于工具包的描述,需要对其名字、功能、输入输出有严格的设计。不过举例影响不大,只要描述清楚,ChatGPT便可以理解。另外,在M(P)中,不强调对图片文件名的敏感,没有严格的思考链格式、不强调可靠性、还有可以使用链式使用工具,模型在输出时就会产生错误。论文中,作者也指出了当前Visual ChatGPT存在的一些局限。比如,需要大量的提示来将VFMs转换成语言,实时能力有限、token长度有限制等等。
论文一作吴晨飞,高级研究员,2020年加入微软亚洲研究院自然语言计算组,研究领域为多模型的预训练、理解和生成。通讯作者段楠,微软亚洲研究院首席研究员及自然语言计算组研究经理,中国科学技术大学兼职博导,天津大学兼职教授,研究领域为自然语言处理、代码智能、多模态智能和机器推理等。Visual ChatGPT的横空出世,让ChatGPT聊天更加丝滑了。
有网友预测,这个功能会迅速集成到新必应中,可能作为付费服务,让日常消费者更接近与「人类」的对话……
也有网友说,这个应用简直堪比早期的智能手机,相当于人们早期的应用程序开发。可以想象,它们最终的使用范围会比最初设想的要广泛得多。
https://arxiv.org/abs/2303.04671
https://www.reddit.com/r/MachineLearning/comments/11mlwty/r_visual_chatgpt_talking_drawing_and_editing_with/