
David S. Soriano, CC BY-SA 4.0 via Wikimedia Commons
以ChatGPT为代表的新的人工智能语言模型的出现与更迭,引发人们极大的兴奋和关注。 物理学家祁晓亮从信息动力学的角度分析,认为AI革命的标志是信息处理复杂度的临界点。AI还没有真正学会思考,但它的迅速发展会给科学研究和人类社会带来深刻的改变。
过去几个月,人工智能的新闻目不暇接,我感到自己好像是三体世界的一个居民,在看着地平线上的朝霞,知道一定有什么要发生,却不知道将要升起的是一轮还是两轮太阳。在这样一个时刻,个人的思考也许没什么用,但是却不能不思考,这也算是人类的本能。因此,我在这里把一些粗浅的想法写下来,以供抛砖引玉之用。需要提醒读者的是,本文不是广为接受的科研成果的介绍,而是只代表个人看法,观点谬误在所难免,欢迎读者批评指正。许多人都认为ChatGPT的横空出世是一个大事件,人工智能可能带来一场科技革命,但这究竟是一场怎样的变革,用什么样的判据来断言这场变革有多么重要?例如农业的发明、工业革命,是在能量利用的意义上,成为人类文明的里程碑。相比之下,人工智能显然是在信息的层面上发生的革命。这一点本身已经是老生常谈了,但这里有一个我想深入讨论的问题,就是大语言模型的诞生究竟是一个什么意义上的临界点?我认为,重要的并不是ChatGPT能够实现多少功能,能够比之前的AI多做多少事情,问题的关键不是能力,而是复杂性——我们今天所看到的,是AI的信息处理复杂度的临界点。我们先来谈一下什么是信息处理。从信息的角度来看人类历史,一切事件本质上都是信息的处理过程。比如轮子的发明,需要有人(或者很多人)想到这个主意,摸索出制作方法,再把这个方法传下去。轮子发明以后的人,在基因上和以前的人是一样的,但是他们可以享受轮子带来的便利,因为这条信息传了下来。张良“运筹帷幄之中,决胜千里之外”是信息处理,他的传令兵把这个命令传给前线也是信息处理。因为“处理”这个词给人一种信息是被动的、静态的感觉,我认为对于信息的传播和演化更准确的描述应该是“信息动力学”(information dynamics)。人类历史本身就是信息的动力学过程,而具体的个人就是信息动力学演化的媒介和载体。不同的信息处理有不同的复杂度,比如张良的决策复杂度显然要高于传令兵传令的复杂度。粗略地来讲,复杂度量的就是最少需要多少个简单的步骤来实现一件事情。这个复杂度有三个方面,一是输入信息的复杂度,二是信息处理本身的计算复杂度,三是输出信息的复杂度。如果张良面对前线传来的复杂混乱的信息,考虑了方方面面的问题,最后让传令兵发了两个字“撤退”,那么在这个例子中,输入和处理的复杂度是高的,输出的复杂度是低的。现在让我们回到现代。在人工智能生成内容(Artificial Intelligence Generated Content,简称AIGC)之前的世界里,电脑、互联网、智能手机的发明已经极大地改变了人类社会,但从信息动力学的角度来看,你会发现机器做的事情非常简单,只有三种:复制,粘贴,排序。互联网、社交媒体是通过一个网络,让人与人之间的信息传播(也就是复制粘贴)变得更加便捷。Google搜索、各种推荐算法是排序。这个时代的信息动力学可以用图1(a)中的网络来代表。从复杂性的角度来看,可以说所有复杂的信息处理都发生在人脑中。机器除了复制粘贴以外,只有排序是复杂的运算,但是排序虽然可以是很复杂的算法,最终的输出却是简单的,只是一个序号,所以这个复杂运算一步之后就终结了,机器下一步只能把这个序号返回给人类,而无法自行迭代运用它的运算能力来完成更复杂的任务。当一个中学生看到一个事件,发一个150字的微博表达自己的意见,这对于信息的处理就已经比ChatGPT以前任何的机器更复杂了。图 1:(a)大语言模型出现之前的信息动力学。电脑的工作局限于简单的复制粘贴(浅蓝色)或提供排序(深蓝色)。(b)大语言模型出现之后的信息动力学。AI可以和人一样进行复杂信息的处理。当然,在GPT之前,人工智能在一些特定目标上的表现,例如围棋、作画,已经相当惊艳,但在信息处理的意义上,这些人工智能模型有着跟排序算法一样的问题:输出的信息形式比较简单固定,因此无法通过多次迭代运用这种信息处理能力来实现更高的复杂性。换言之,信息动力学的复杂性取决于输入、处理、输出这三者中的瓶颈。ChatGPT带来的革命,正是由于它在这三个步骤中,都达到了与人类匹敌的复杂性。GPT可以接收模糊的指令,各种语言、各种程序代码都可以;面对各种输入都能给出比较合理的输出,而输出本身也和人类一样复杂,比如写文章,写代码。在GPT诞生之后,信息动力学的图示变成了图1b的样子。即使最新版的GPT-4也还存在着很多问题,对于不熟悉的事情经常犯错甚至胡说,但在复杂性方面,我认为:它已经达到了人类水平。问题的关键是复杂度而不是具体问题上的表现:一旦处理信息的复杂度达到了人类水平,解决准确度和其他方面的问题已经没有本质的障碍。以AI的进化速度,一旦它达到人类水平,很快就会远超人类。正因为复杂度是关键,AI的这场革命才会出自大语言模型,而不是其他的AI领域。《圣经》第一句说,“太初有言”,《老子》第一句说“道可道,非常道”。在地球的历史中,人类语言的涌现是一个标志性的事件,从那之后,这个星球上最重要的信息动力学不再是DNA的遗传和变异,而是语言的传播和演进。从信息动力学的角度来说,ChatGPT出现以来的人工智能迅速进化,可能是在人类语言出现之后第二个如此重要的事件,它标志着这个星球上起决定性作用的信息动力学过程不再由人类脑中的化学过程垄断,而越来越多地发生在芯片上的电子过程中。为什么语言如此重要?人类语言不是像蜜蜂的舞蹈那样传递固定信号的工具,而是可以用来描述从具体到抽象的任何东西。我们不仅可以谈及世界上的事物,还可以描述它们之间的关系,以及关系的关系。现实世界中只有苹果、桔子、香蕉,人类却可以从中创造出“水果”这一抽象概念。水果、蔬菜等不同的概念,又同属于“植物”,以及“名词”这两个更概括的概念。这些不同的概念属于不同的层级,因此一个图像识别的人工智能可以通过训练学会从具体的图像中识别出“水果”这个概念,但是如果要让它再明白水果和蔬菜属于植物,就又需要重新训练。语言的魔力在于,一旦我们把这些概念都看成词语,它们都是平等存在的,不管是“苹果”还是“植物”,还是“量子力学的非定域性”,都一样可以成为思考的对象。有了语言,我们脑中的世界不只是外部世界的一个映像,而是多了一个拥有无限可能的新维度。有了这个新维度,世界的结构变得扁平,原来一层叠一层的抽象结构,全都变得和一只苹果一样可以被我们思考。运用语言,我们可以理解直线和三角形的概念,总结出欧几里得几何的公理,并且应用它们去证明勾股定理。一旦证明了所有直角三角形都满足勾股定理,我们不再需要任何数据就可以掌握和运用这个知识。语言的界限并非人类能力的界限,但却是思考的界限。人类可以通过训练学会一些技能,例如骑自行车,这并非通过语言和思考来达成,但不通过语言的技能,就无法通过思考来改进,也无法通过沟通来传播。例如我们可以写一本骑自行车教程,但读教程不能让我们学会骑自行车,而必须通过实践训练才能学会。所以我们能够理解和告诉别人的世界的复杂度,最高不会超过语言所能描述的范围。因此维特根斯坦说:“我的语言的界限意味着我的世界的界限。”[1]换言之,对于人类来说,信息动力学也就是语言的动力学。这种动力学既包括严密的推导和论证,也包括跳跃的灵感,甚至白日梦和幻觉。正是因为语言在我们的世界中具有这样核心的地位,它在AI的发展中也具有独特的地位。我们今天看看ChatGPT的发展,不难想象语言模型可以有一天学会自动驾驶,但是反过来一个做自动驾驶的AI很难有一天学会语言。特德 · 蒋说ChatGPT是“整个互联网的模糊图像”(a blurry jpeg of the web)[2]。我觉得他说的有些道理,但这个比喻过于静态了。比起静态的知识来说,更重要的是时间的维度:可以说ChatGPT是对于人类语言动力学的模糊印象。也就是说,它还没真正学会思考,但是它学会了大略地模仿人类的思考过程。例如数学家Terence Tao介绍过如何让ChatGPT来建议定理证明,虽然它说的有错,却可以提供新的思路[3]。这就是因为虽然这个定理在数学中是未知的,但ChatGPT懂得如何把以前看过的其他证明的思路或套路应用到这个定理上来。有一种常见的观点,认为人工智能只会模仿,不会创造,但我认为模仿和创造之间并没有绝对的鸿沟。其实人类那些最具创造性的想法,也不是无中生有的,而是在已知的思路和知识背景的基础上生发出来的。牛顿从苹果落地想到引力,也是已知和未知的类比。这种类比的过程跟GPT对于定理证明提供的新思路并无本质的区别。作为一个例子,我让ChatGPT猜想未来量子引力的研究可能有哪些意想不到的突破,下面是它给我的一个答案。虽然这不能说是什么特别令人激动的想法,但猜测的方向是有一定道理的。可以说ChatGPT在开脑洞方面的能力并不弱于人类,甚至可能因为它渊博的知识而强于人类,但它的问题在于不能从很多的想法中去自行验证哪个方向更可行和准确。图 2 ChatGPT对于量子引力研究方面发挥想象力的一个示例。说到ChatGPT无法区分正确与错误的弱点,我们就可以来讨论一下今天的语言模型和人类之间最本质的差别是什么。换句话说,GPT-4和通用人工智能(Artificial General Intelligence, AGI)的本质差距在哪里。丹尼尔·卡尼曼在《思考,快与慢》[4]这本书中指出,人类的思维活动有两套系统。系统1是我们的快速、直觉式、自动、无意识的思维方式。它处理日常生活中的大部分任务,如识别物体、表情、语言理解和做出简单的决策。系统1常常以经验为基础,通过关联和模式识别来实现快速决策。然而,这种快速决策往往容易受到认知偏差的影响。系统2是我们的缓慢、分析式、有意识的思维方式。这个系统需要更多的注意力和努力来运作,因为它负责处理复杂的问题、逻辑推理、规划和长期决策。系统2可以纠正系统1的错误,但它的运作速度较慢。今天的大语言模型本质上是系统1的模拟,它根据输入的文字直接按照一个概率分布来输出文字,这很像是人类凭直觉作出判断时的操作。比如一个数学运算,GPT-4可以根据你的指令,给出推导过程,但是如果你直接让它给出结果,它并不是自己在“脑中”进行这个推导过程再给出结果,而是直接凭“直觉”给出结果的。这就是为什么在给GPT-4下达“写出推导过程”的指令时,它的计算准确率会明显提高[5,6]。从这个例子我们可以看出,GPT-4已经懂得运用语言,但它只是用语言跟人类交流,而没有用语言来思考。用语言来思考,就是系统2和系统1的最主要差别。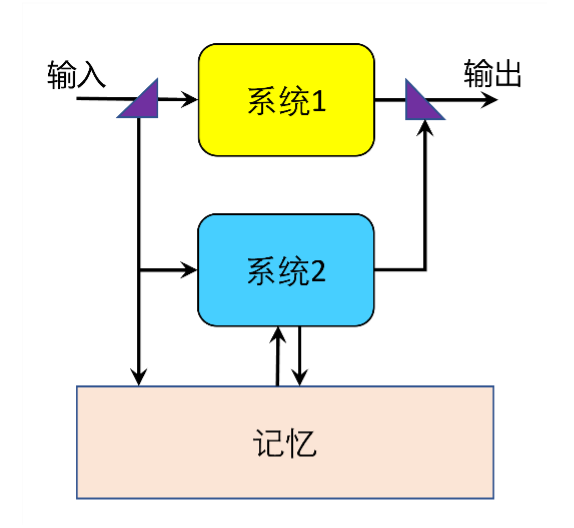
图 3 具有系统1(直觉判断)和系统2(用语言思考)的人工智能系统的简单示意图。(1)它需要有长期记忆。现在的GPT-4对于对话的上下文会有一定的记忆,但在开始一个新的对话时这些记忆就清除了。它虽然“记得”大量的知识,但那些并不是在对话中获得的记忆。如果和人类类比,GPT的知识更像是人类先天自带的能力,例如婴儿知道哭和吃奶。如果想让语言模型能够像人类一样在经验中学习,首先必须让它对于自己的历史有长期的记忆。(2)语言模型要能够对于长期记忆进行处理,吸取经验为自己所用。人类如果一道数学题做错了,学到正确解法之后就会改正,因为正确解法已经存在记忆里,并且知道在下次遇到类似问题的时候调用出来,而GPT虽然也会改正错误,下次却仍然会再犯[6],除非通过进一步的训练来改变模型的参数。最近已经有一些研究工作尝试为语言模型加上长期记忆和调用记忆的能力。例如[7]提出了一种名为reflexion的架构,将GPT尝试解决一个问题的过程记录下来并且让另一个语言模型进行“反思”,根据反思的结果告诉GPT下次如何改进。在一些任务上这个架构可以将成功率提高30%。在另外一个工作[8]中,作者设计了25个人工智能角色的虚拟小镇,每个角色都有他们的不同人物设定和记忆。比如两个人第一次见面,会在记忆中留下记录,下一次见面时就会记得之前见过。在遇到一个新的事件时,一个角色会从自己记忆中搜寻最可能与此相关的记忆,作为参考来决定当前的行为。这样的架构使得多个角色之间的复杂互动(例如聚在一起办一场生日庆祝会)成为可能。最近一个很流行的程序autoGPT[9],让GPT对于给定的复杂任务先列出计划,然后调用用户电脑上的各种资源去一步步执行。所有这些努力的方向都是让人工智能拥有像人类一样的系统2,具有自己的“心理活动”并且能够在情境中不断学习进步。拥有系统1和系统2的人工智能的结构可以用图3来简单概括。我认为在这方面近期内就会有非常快的进展,因为从复杂性的角度来看,这样的系统2的信息处理复杂度,并不显著高于现有语言模型的系统1。在AI带来的各种影响中,作为一个物理学研究者,我自然会关心AI会如何改变科学研究这样的创造性活动。为了思考这个问题,我们可以先从信息动力学的角度来看一下什么是科学研究。和人类的其他一切活动一样,科研也是输入—处理—输出信息的过程,但它区别于其他活动的地方在于创造性:科研的目标是输出以前不存在的新知识。科研工作者的社群,恰似一个神经网络,每一个工作的输出又成为未来工作的输入。研究者首先必须先消化理解已有的知识,将它们用自己需要的方式来归纳总结重组。这种知识的来源对于理论家来说可能是别人的论文、书籍,对于实验家则还要加上实践经验。可以超越各种障碍学到有用知识,是优秀科研工作者的一个重要素质。同一个东西的理解还有深浅不同,一个人如果能够把学到的知识从一个完全不同的角度,或者用一种完全不同的语言解释出来,就比只会照本宣科讲出来的人要理解得深,也更可能在这基础上创造新知识。研究者会运用这些对已有知识的理解,让自己的想法逐步成型,就像stable diffusion里面一开始模糊的图画如何慢慢清晰起来。在一项工作完成之后,还有一个重要的环节是把这个新知识传播出去:传播的方式包括写论文,给学术报告等等。信息传播的方式,对于一项科研工作的影响力也很重要,所以努力在顶级期刊上发表论文成了很多科研工作者付出大量精力的一项工作。AI拥有了人类水平的信息处理能力后,对于科研工作的这几个环节可能都会带来重要的改变。在信息输入的环节,AI可以帮助人类研究者更快更好地理解其他作者的文章,根据研究者的需求给出各种不同详细度的总结概述。它还可以运用自己海量的知识来指出在研究者不了解的领域里,有什么知识可能对于目前的科研有用。AI还可以让信息传播的形式更加灵活。例如,在研究中我们往往觉得,比起读论文来说,听报告或者跟作者直接聊要有效率得多,但我们并不总是有机会和作者直接对话。如果AI可以把论文像作者一样讲解出来,还能回答问题,扮演一个作者的代理人,对于科研来说一定是非常有帮助的。在信息的输出环节,这样的灵活输出方式也可以根本地改变科研的论文出版方式。如果作者可以把自己的想法教给AI,AI可以自由输出学术报告或者学术论文,随时回答别人的问题,那么印在纸上的“论文”也就没有必要了。也许取代论文的就是“出版”一个AI agent,它可以用读者希望的方式输出各种不同的讲解方式,是“活着”的知识载体。在创造新知识的环节,AI也可以提出可能的新想法和问题,根据已有的经验提出可能的尝试方向,这个现在的ChatGPT已经可以做,只是未来需要更准确的理解,让它的建议更有价值。我想,未来的科研应该是“AI in the loop”,AI全程在场,从事务性的工作到创造性的工作都参与,让整个科研活动的信息处理过程变得高效。但这可能还不是最重要的改变。AI不仅会改变每一个独立的科研组的工作方式,更会带来人与人之间合作的新可能。在有些领域中,科研工作已经发展成了大规模的合作,例如粒子物理领域的论文常常有上百名作者,但在绝大部分的基础科学研究中,合作仍然局限在几个人、十几个人的范围。特别是在我从事的基础理论研究中,假设所有的学者都拥有无限的经费,可以任意扩大自己组的规模,恐怕实际上每个人带的学生不会比现在多太多,不同的组之间的合作交流的深度恐怕也不会跟现在有本质的差别。这是因为,在做出原创性成果这方面,瓶颈不在资源(但是没有资源也是不行的,funding agency请不要看到这句话削减我们的科研经费),而是在于高质量信息处理的时间和智力成本——如果研究组规模太大,或者跟其他组有太多合作,大家弄懂彼此想法需要的时间可能就占用了太多的精力,得不偿失。所以现实中一个重要idea的发现,往往是具有极大的偶然性,例如两个从事不同领域的人不期而遇,他们又都具有优秀的理解和沟通能力,擦出了火花。也许两个人都有某个模糊的idea,都去跟身边的人讲,一个人遇到了好的合作者就可能相互激荡成就一篇优秀的工作,另一个人讲了别人没什么反应,这个讨论可能就无疾而终。AI的出现不会改变这些偶然性,但会让整个尝试的过程变得高效得多。在AI的帮助下,我们可能就好像从一个偏远地方来到顶级研究机构,能够超越以前的现实环境限制,获得更多思想激荡的机会,让重要的idea出现的更快。也许有人会觉得这样的前景太危险,如果AI超出了人类的智力,我们科研工作者是不是也都要失业?但即便真的失业,在科研方面我还是会觉得期待而不是畏惧。设想如果有人给牛顿一部时光机,他可以按下快进键学到此后三百年的现代科学,他应该也会觉得充满期待和兴奋,而不是遗憾做出量子力学和相对论的不是自己吧。当然,AI来得如此快,必然意味着对于社会的巨大冲击。未来可能是阳光普照,也可能是乱纪元。已经有公开信呼吁要对巨型人工智能模型的发展按下暂停键,暂停六个月来思考人类如何掌控AI [10]。在我看来,这种担忧有充分的理由,但是暂停已经不可能。大模型能力的涌现并非通过什么独门秘技实现,OpenAI就算关门,别人也会很快做出相似的模型。面对可能的危机,人类要做的不是躲避AI,而是更快地熟悉它,明白怎么运用它的巨大力量。人类需要思考整个社会如何适应AI时代,搞好社会分配机制,在AI和重要的社会功能之间建立安全阀。我们今天无法为所有的问题做好准备,但是我们需要尽早在整个社会层面开始充分的讨论。我相信,AI带来的问题,最终也会由AI来解决,就好像工业革命带来的社会问题,不可能通过消除工业来解决,而只能通过合理运用工业带来的财富来解决。当AI对于人类心理和人类社会的理解足够好,我们也可以让AI来帮助我们模拟未来社会可能出现的问题,实验可能的应对方案。这方面涉及到的问题会很多,本文只想谈其中的一点。AI和人类很大的区别,是AI的“大脑”相对于人类的大脑来说是可以透明的。这并不是说我们理解AI的计算过程——AI模型的可解释性本身是一个很难的研究课题——而是说在AI执行一个多步骤的任务时,它用语言来“思考”的过程(即上文所说的运用系统2的过程)是可以记录下来为人所知的。相比之下,人类的心理活动天然对他人保密。当然,AI的思考和执行过程很有可能被人为加密,只为它的主人知晓。我认为,未来在保证AI安全方面一个重要的原则,就是强大到某一程度的AI要保持透明,其“思考过程”可检查可监管,而不能变成少数人控制的黑箱。在实践中,如何确保这样的透明原则,又能保持私有数据的安全性,是技术上的重要课题。我们这一代人一直都有这种认知,即我们身处在一个前所未有的时代中,但直到今天我们才真正来到这个时代的黎明。未来存在着巨大的不确定性,但我愿意相信,AI难以捉摸,但不怀恶意。
作者简介:
祁晓亮,美国斯坦福大学物理系教授,主要研究方向为量子信息和量子引力。
参考文献:
[2] https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web[3]https://mathstodon.xyz/@tao/109971374075988443[5] OpenAI, “GPT-4 Technical Report”, arXiv preprint arXiv:2303.08774 (2023)[6] Bubeck, Sébastien, et al. "Sparks of artificial general intelligence: Early experiments with gpt-4." arXiv preprint arXiv:2303.12712 (2023).[7] Shinn, Noah, Beck Labash, and Ashwin Gopinath. "Reflexion: an autonomous agent with dynamic memory and self-reflection." arXiv preprint arXiv:2303.11366 (2023).[8] Park, Joon Sung, et al. "Generative Agents: Interactive Simulacra of Human Behavior." arXiv preprint arXiv:2304.03442 (2023).[10] https://futureoflife.org/open-letter/pause-giant-ai-experiments/
欢迎关注我们,投稿、授权等请联系
[email protected]