机器之心 & ArXiv Weekly
参与:楚航、罗若天、梅洪源
本周重要论文包括英伟达提出的首个大模型驱动、可以终身学习的游戏智能体VOYAGER,以及马腾宇团队新出的大模型预训练优化器。
VOYAGER: An Open-Ended Embodied Agent with Large Language Models
- Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
- RWKV: Reinventing RNNs for the Transformer Era
- CoDi: Any-to-Any Generation via Composable Diffusion
- LIMA: Less Is More for Alignment
- WebCPM: Interactive Web Search for Chinese Long-form Question Answering
- A Comprehensive Survey on Segment Anything Model for Vision and Beyond
- ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:VOYAGER: An Open-Ended Embodied Agent with Large Language Models - 作者:Guanzhi Wang、 Yuqi Xie 等
- 论文地址:https://arxiv.org/pdf/2305.16291.pdf
摘要:通用 AI 大模型 GPT-4 进游戏了,进的是开放世界,而且玩出了高水平。近日,英伟达发布的 VOYAGER 给 AI 圈内带来了一点小小的震撼。VOYAGER 是第一个大模型驱动,可以终身学习的游戏智能体,著名 AI 学者,刚回 OpenAI 的 Andrej Karpathy 看论文了之后表示:还记得在大约 2016 年的时候,在像《我的世界》这样的环境里开发 AI 代理是多么绝望的一件事吗?
推荐:英伟达把 GPT-4 塞进我的世界,打游戏快 15 倍:AI 大佬沉默了论文 2:Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training - 论文地址:https://arxiv.org/pdf/2305.14342.pdf
摘要:大语言模型(LLM)的能力随着其规模的增长而取得了显著的进展。然而,由于庞大的数据集和模型规模,预训练 LLM 非常耗时,需要进行数十万次的模型参数更新。例如,PaLM 在 6144 个 TPU 上进行了为期两个月的训练,总共耗费大约 1000 万美元。因此,提高预训练效率是扩展 LLM 规模的一个主要瓶颈。本文来自斯坦福大学的研究者撰文提出了 Sophia(Second-order Clipped Stochastic Optimization)轻量级二阶优化器,旨在通过更快的优化器提高预训练效率,从而减少达到相同预训练损失所需的时间和成本,或者在相同预算下实现更好的预训练损失。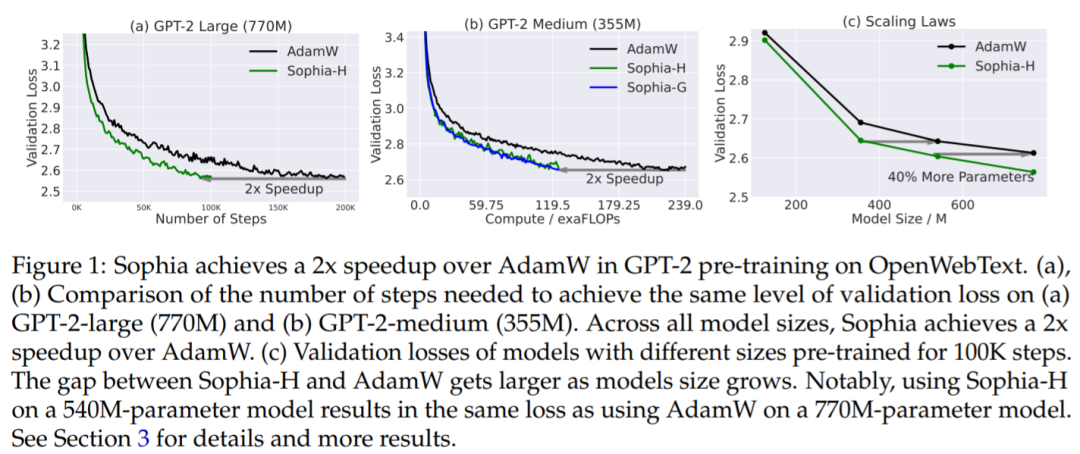
推荐:马腾宇团队新出大模型预训练优化器,比 Adam 快 2 倍,成本减半论文 3:RWKV: Reinventing RNNs for the Transformer Era - 作者:Alon Albalak、 Samuel Arcadinho 等
- 论文地址:https://arxiv.org/pdf/2305.13048.pdf
摘要:Transformer 模型在几乎所有自然语言处理(NLP)任务中都带来了革命,但其在序列长度上的内存和计算复杂性呈二次方增长。相比之下,循环神经网络(RNNs)在内存和计算需求上呈线性增长,但由于并行化和可扩展性的限制,很难达到与 Transformer 相同的性能水平。本文提出了一种新颖的模型架构,Receptance Weighted Key Value(RWKV),将 Transformer 的高效可并行训练与 RNN 的高效推理相结合。实验证明,RWKV 的性能与相同规模的 Transformer 相当。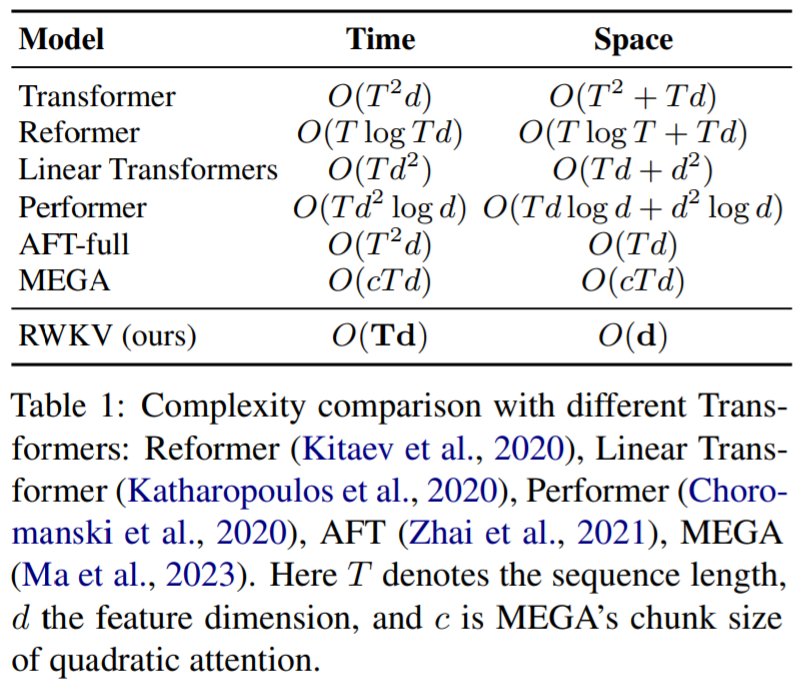
推荐:在 Transformer 时代重塑 RNN,RWKV 将非 Transformer 架构扩展到数百亿参数论文 4:CoDi: Any-to-Any Generation via Composable Diffusion
- 作者:Zineng Tang、Ziyi Yang 等
- 论文地址:https://codi-gen.github.io/
摘要:给定一句话,然后让你想象这句话在现实场景中的样子,对于人类来说这项任务过于简单,比如「一辆进站的火车」,人类可以进行天马行空的想象火车进站时的样子,但对模型来说,这可不是一件容易的事,涉及模态的转换,模型需要理解这句话的含义,然后根据这句话生成应景的视频、音频,难度还是相当大的。现在,北卡罗来纳大学教堂山分校、微软提出的可组合扩散(Composable Diffusion,CoDi)模型很好的解决了这个问题。与现有的生成式人工智能系统不同,CoDi 可以并行生成多种模态,其输入不限于文本或图像等模态。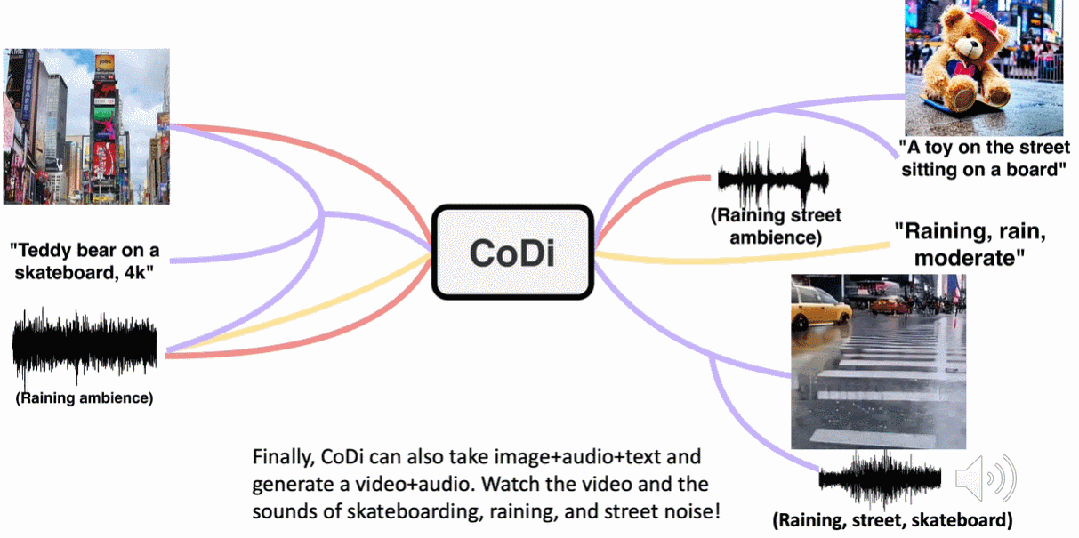
推荐:可组合扩散模型主打 Any-to-Any 生成:文本、图像、视频、音频全都行论文 5:LIMA: Less Is More for Alignment- 作者:Chunting Zhou、Pengfei Liu 等
- 论文地址:https://arxiv.org/abs/2305.11206
摘要:使用 RLHF 方法,大型语言模型可与人类偏好保持对齐,遵循人类意图,最小化无益、失真或偏见的输出。但 RLHF 方法依赖于大量的人工标注和评估,因此成本非常高昂。最近,来自 Meta AI 等机构的研究者在一项研究中指出:在对齐方面,少即是多。该研究使用了一个 65B 参数的 LLaMa 模型(该模型称为 LIMA)在 1000 个精选样本上进行有监督学习,在完全没使用 RLHF 方法的情况下,LIMA 表现出非常强大的性能,并且能够很好地泛化到训练数据以外的任务上。在人类评估结果中,LIMA 甚至可与 GPT-4、Bard、DaVinci003 相媲美。
推荐:没有 RLHF,一样媲美 GPT-4、Bard,Meta 发布 650 亿参数语言模型 LIMA论文 6:WebCPM: Interactive Web Search for Chinese Long-form Question Answering- 论文地址:https://arxiv.org/abs/2305.06849
摘要:2021 年 12 月 WebGPT 的横空出世标志了基于网页搜索的问答新范式的诞生,在此之后,New Bing 首先将网页搜索功能整合发布,随后 OpenAI 也发布了支持联网的插件 ChatGPT Plugins。大模型在联网功能的加持下,回答问题的实时性和准确性都得到了飞跃式增强。近期,来自清华、人大、腾讯的研究人员共同发布了中文领域首个基于交互式网页搜索的问答开源模型框架 WebCPM,相关工作录用于自然语言处理顶级会议 ACL 2023。WebCPM 搜索交互界面如下。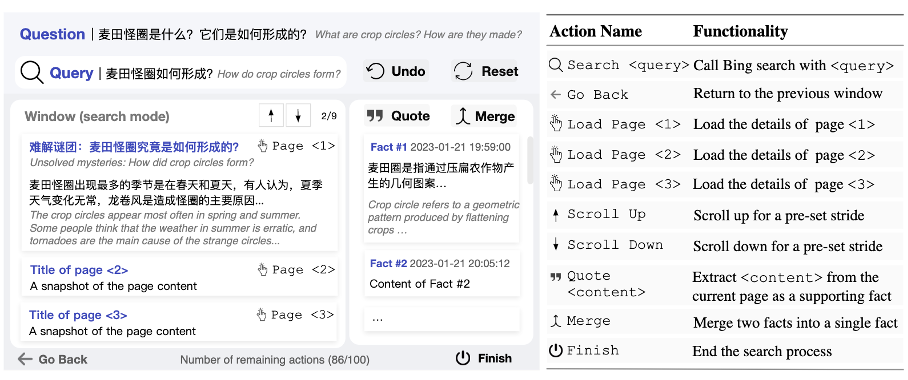
推荐:首个基于交互式网页搜索的中文问答开源框架,清华、人大、腾讯联合发布 WebCPM论文 7:A Comprehensive Survey on Segment Anything Model for Vision and Beyond- 作者:Chunhui Zhang、 Li Liu 等
- 论文地址:https://arxiv.org/pdf/2305.08196.pdf
摘要:作为首个全面介绍基于 SAM 基础模型进展的研究,本文聚焦于 SAM 在各种任务和数据类型上的应用,并讨论了其历史发展、近期进展,以及对广泛应用的深远影响。SAM 架构如下所示,主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。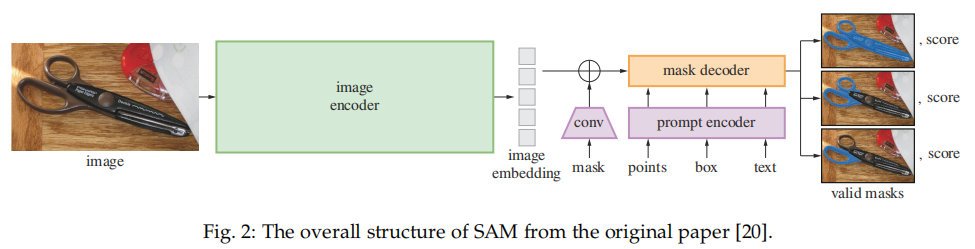
推荐:分割一切模型 SAM 首篇全面综述:28 页、200 + 篇参考文献ArXiv Weekly Radiostation机器之心联合由楚航、罗若天、梅洪源发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Text-Augmented Open Knowledge Graph Completion via Pre-Trained Language Models. (from Jimeng Sun, Jiawei Han)
2. All Roads Lead to Rome? Exploring the Invariance of Transformers' Representations. (from Bernhard Schölkopf)
3. MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions. (from Christopher D. Manning, Christopher Potts)
4. Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts. (from Kurt Keutzer, Trevor Darrell)
5. BeamSearchQA: Large Language Models are Strong Zero-Shot QA Solver. (from Yan Zhang)
6. Modeling rapid language learning by distilling Bayesian priors into artificial neural networks. (from Thomas L. Griffiths)
7. Language Model Tokenizers Introduce Unfairness Between Languages. (from Philip H.S. Torr)
8. The False Promise of Imitating Proprietary LLMs. (from Pieter Abbeel, Sergey Levine)
9. COMET-M: Reasoning about Multiple Events in Complex Sentences. (from Raymond Ng)
10. Cascaded Beam Search: Plug-and-Play Terminology-Forcing For Neural Machine Translation. (from Roger Wattenhofer)
1. Refocusing Is Key to Transfer Learning. (from Trevor Darrell)2. Robust 3D-aware Object Classification via Discriminative Render-and-Compare. (from Alan Yuille)3. DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification. (from Harry Zhang)4. All Points Matter: Entropy-Regularized Distribution Alignment for Weakly-supervised 3D Segmentation. (from Dacheng Tao)5. Anomaly Detection with Conditioned Denoising Diffusion Models. (from Thomas Brox)6. Zero-shot Generation of Training Data with Denoising Diffusion Probabilistic Model for Handwritten Chinese Character Recognition. (from Kai Chen)7. ChatCAD+: Towards a Universal and Reliable Interactive CAD using LLMs. (from Dinggang Shen)8. High-Similarity-Pass Attention for Single Image Super-Resolution. (from Wenzhong Guo, C. L. Philip Chen)9. Learning Occupancy for Monocular 3D Object Detection. (from Deng Cai)10. T2TD: Text-3D Generation Model based on Prior Knowledge Guidance. (from Nicu Sebe)
1. Operationalizing Counterfactual Metrics: Incentives, Ranking, and Information Asymmetry. (from Michael I. Jordan)2. Understanding Label Bias in Single Positive Multi-Label Learning. (from Pietro Perona)3. Dealing with Cross-Task Class Discrimination in Online Continual Learning. (from Bing Liu)4. Uncertainty Quantification over Graph with Conformalized Graph Neural Networks. (from Jure Leskovec)5. Characterizing Out-of-Distribution Error via Optimal Transport. (from Katia Sycara)6. AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback. (from Jimmy Ba, Carlos Guestrin)7. Weakly Supervised AUC Optimization: A Unified Partial AUC Approach. (from Ming Li, Zhi-Hua Zhou)8. Lightweight Learner for Shared Knowledge Lifelong Learning. (from Laurent Itti)9. Patient Outcome Predictions Improve Operations at a Large Hospital Network. (from Dimitris Bertsimas)10. AUC Optimization from Multiple Unlabeled Datasets. (from Ming Li)© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]