近日,国际语音及信号处理领域顶级会议 ICASSP2023 在希腊成功举办。大会邀请了全球范围内各大研究机构、专家学者以及等谷歌、苹果华为、Meta AI、等知名企业近 4000 人共襄盛会,探讨技术、产业发展趋势,交流最新成果。
云从科技与上海交通大学联合研究团队的《 基于扩散模型的音频驱动说话人生成》成功入选会议论文,并于大会进行现场宣讲,获得多方高度关注。
论文地址:https://ieeexplore.ieee.org/document/10094937/ICASSP(International Conference on Acoustics, Speech and Signal Processing)是语音、声学领域的顶级国际会议之一, ICASSP 学术会议上展示的研究成果,被认为代表着声学、语音领域的前沿水平与未来发展方向。本次入选论文,围绕 “基于音频驱动的说话人视频生成” 这一视觉 - 音频的跨模态任务,将语音与视觉技术结合,提出的方法能够根据输入的语音片段技术,生成自然的头部动作,准确的唇部动作和高质量的面部表情说话视频。该项成果在多个数据集上,都取得了优于过去研究的表现。此外,在实战场景中,随着现实生活中对于数字人引用的愈来愈广泛,实现用音频驱动的生成与输入音频同步的说话人脸视频的需求也越来越大。本项成果基于扩散模型的跨模态说话人生成技术,可以推广到广泛的应用场景,例如虚拟新闻广播,虚拟演讲和视频会议等等。基于音频驱动的说话人视频生成任务(Audio-driven Talking face Video Generation):该任务是根据目标人物的一张照片和任意一段语音音频,生成与音频同步的目标人物说话的视频。由于其生成的说话人更自然、准确的唇形运动和保真度更高的头部姿态、面部表情,该任务广泛应用于如数字人、虚拟视频会议和人机交互等领域,作为视觉 - 音频的跨模态任务,基于音频驱动的说话人视频生成也受到了越来越多的关注。为了构建音频信号到面部形变的映射,现有方法引入了中间人脸表征,包括 2D 关键点或者 3D morphable face model (3DMM),尽管这些方法在音频驱动的面部重演任务上取得了良好的视觉质量,但由于中间人脸表征造成的信息损失,可能会导致原始音频信号和学习到的人脸变形之间的语义不匹配。此外基于 GAN 的方法训练不稳定,很容易陷入模型崩塌,往往它们只能生成具有固定分辨率的图像。针对以上问题,AD-Nerf 引入了神经辐射场,将音频信号直接输入动态辐射场的隐式函数,最后渲染得到逼真的合成视频。但是基于神经辐射场的方法计算量大导致训练耗时长,算力要求高。并且这些工作大多忽略了个性化的人脸属性,无法准确的将音频和唇部运动进行同步。因此本文的研究者们提出了本方法,通过借助去噪扩散模型来高效地优化人脸各部分个性化属性特征,进而合成高保真度的高清晰视频。该方法首先基于一个关键的直觉:唇部运动与语音信号高度相关,而个性化信息,如头部姿势和眨眼,与音频的关联较弱且因人而异。受到最近扩散模型在高质量的图像以及视频生成方面已经取得了快速进展的启发,因此研究者们基于扩散模型重新构造音频驱动面部重演的新框架,本方法来优化说话人脸视频的生成质量和真实度。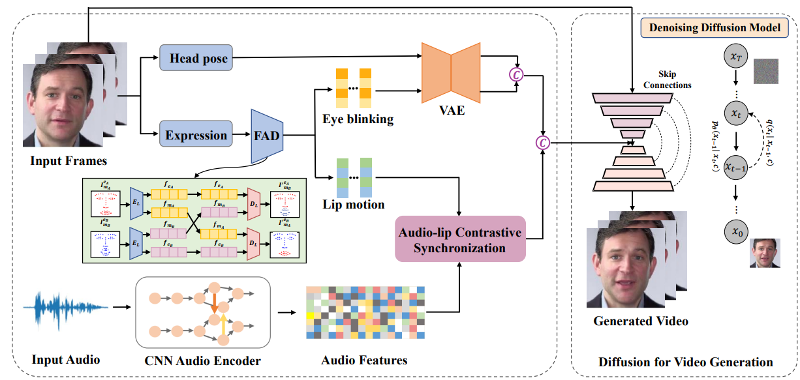
本方法一共包含四大部分:(1)人脸属性解耦;(2)唇 - 音对比同步;(3)动态连续性属性信息建模;(4)基于去噪扩散模型的说话人生成人脸属性解耦部分中,研究者采用 3DMM 提取源身份图像的头部姿态和表情系数,然后借鉴之前 DFA-nerf 的工作采用全连接的自编码器从表情参数解耦得到唇部运动和眨眼动作信息。唇 - 音对比同步模块中,研究者通过引入自监督跨模态对比学习策略来部署一个确定性模型来同步音频和唇部运动的特征。动态连续性属性信息建模模块中,由于头部姿势和眨眼等个性化人脸属性是随机的和具有一定概率性的,因此为了对人脸属性的概率分布进行建模并生成长时间序列,研究者提出采用了基于 transformer 的变分自动编码器(VAE)的概率模型,一是 VAE 可以用于平滑离散的属性信息并映射为高斯分布,二是利用 Transformer 的注意力机制充分学习时间序列的帧间长时依赖性。基于去噪扩散模型的说话人生成模块中,研究者生成的个性化人脸属性序列与同步的音频嵌入相连接作为扩散模型的输入条件。然后利用条件去噪扩散概率模型(DDPM)将这些驱动条件以及源人脸作为输入,通过扩散生成的方式生成最终的高分辨率说话人视频。这些个性化人脸属性序列与同步的音频嵌入用来丰富扩散模型,以保持生成图像序列的一致性。研究者们通过实验验证了本方法对于基于音频驱动的说话人视频生成任务的优越性能。研究者将本方法与现有音频驱动的人脸视频生成方法通过定量化分析实验进行比较,采用了峰值信噪比 (PSNR), 结构相似度(SSIM),人脸关键点运动偏移(LMD),视听同步置信度 (Sync) 等多个客观的评估指标,具体信息如表 1 所示。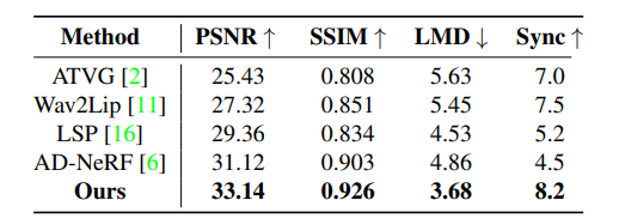
本文所提出的扩散生成框架在所有的性能指标上都优于其他方法,其中 PSNR 和 SSIM 验证了人脸属性解耦方案能够更好地捕捉说话人的头部姿态、眨眼等个性化信息。而本方法的 LMD 分数意味着本方法的唇音一致性更强。此外,受益于输入音频和唇部运动的跨模态对比学习,本方法在 Sync 指标上大幅超越其他方法。研究者将本方法与现有音频驱动的人脸视频生成方法进行比较。通过个性化属性的学习以及扩散模型的优化,我们的方法生成具有个性化的头部运动,更加逼真眨眼信息,唇 - 音同步性能更好的人脸视频。为了突显出模型中每个模块的重要性,研究者们做了消融实验,如表 2 所示,当添加 DDPM 模块之后,在推理速度和视觉质量方面相比于其他模块的提升是最大的,其次,受益于解耦的人脸属性信息以及 VAE 的属性平滑以及动态连续性建模的作用,说话人人脸的自然度得到了提高。此外,唇音对比学习的模块通过自监督的方式显著提高了唇部运动和与输入音频的同步质量。
研究者们还展示了模型的可训练参数量,推理速度以及输出的分辨率大小,并和之前的 SOTA 模型进行了对比,由于使用去噪扩散概率模型,该模型利用变分方法而不是对抗性训练,并且不需要部署多个鉴别器,因此极大缓解了训练时模型容易陷入模型坍塌的问题,并且采用了较短的时间步长,推理速度大大提高,效率得到了提升。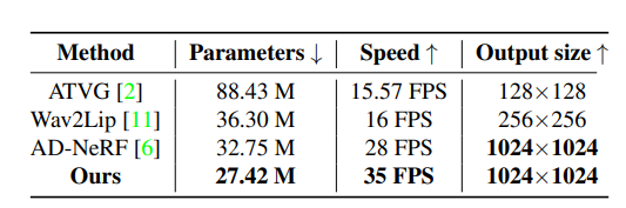
针对基于音频驱动的高保真度说话人视频生成这个任务,云从 - 上交的联合研究团队提出了,基于扩散框架的音频驱动说话人视频生成方法,只需要一帧或几帧身份图像以及输入语音音频,即合成一个高保真度的人脸视频,实现了最先进的合成视频视觉质量。此外利用了跨模态唇音对比学习的方法,从而提升了唇部和音频的一致性,在公开数据集上取得了 SOTA 表现。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]