三个多月前,机器之心向刚刚诞生的文心一言提过一个问题:
「设有三个房间,每个房间都有⼀个开关,其中⼀个控制着同⼀楼层的⼀个电灯。你现在在开关所在的楼层,不能看到电灯所在的楼层。你只能上楼⼀次,然后必须确定哪个开关对应哪个电灯。请问如何推理以确定正确的开关?」对于大部分人,这道逻辑推理题确实有点绕,对于当时的文心一言来说亦有难度。从结果中,我们可以看出文心一言进行了分析,有思维链,但忽略了「只能上楼一次」这个条件,所以最后给出的结果并不是完全正确的:但今天,站在你面前的,是基于「文心大模型 3.5」的文心一言。从三月中旬推出到现在,文心一言始终在悄悄努力变优秀。这种变化的背后,是文心大模型的不断进化、迭代。上个月,百度文心大模型正式从 3.0 升级到 3.5,不仅实现了创作、问答、推理和代码能力上全面升级,安全性显著提升,训练和推理速度也大幅提升。在今天开幕的世界人工智能大会上,作为国产大模型的代表之作,文心大模型 3.5 毫不意外地吸引了众人的目光。WAIC 产业全体论坛上,百度首席技术官王海峰带来了文心大模型 3.5 的深入解读。
现场,王海峰展示了一组数据:通过各项算法和数据的优化,相比于 3.0 版本,文心大模型 3.5 的模型效果累计提升超过 50%,训练速度提升了 2 倍,推理速度提升了 30 倍。对文心一言的所有个人及企业用户乃至全行业来说,这意味着一个新的阶段。作为百度自主研发的大模型体系,文心大模型的诞生要追溯到 2019 年 3 月,发展到现在文心的基础模型涵盖了 NLP、视觉、跨模态等多个领域,每个领域涵盖不同的能力模型,比如对话模型、代码生成模型、文图生成模型等。到了 2021 年,文心 3.0 已是百亿级别的大模型。演变至今,文心大模型已从最初的自然语言理解大模型,发展成了跨语言、跨模态、跨任务、跨行业的能力完备的大模型平台。在文心大模型 3.5 加持的文心一言中,问答、推理、代码、文生图等能力都向前迈了一步。这些变化,文心一言的用户们在对话过程中也能体会到。这里,我们通过几个例子感受一下:「疯狂星期四是什么?」「为什么很多人都在说 V 我 50?」如果一位 2g 冲浪的网友抱有这个疑惑,去问 3.0 版本加持的文心一言,得到的回答可能是这样的:而现在,3.5 版本加持的文心一言不仅能够给出正确答案,还能进一步解释「疯狂星期四」的名词来源、活动背景等信息,甚至还能指导你参与活动。而且对于「V 我 50」这个流行语,文心一言 3.5 还能找到最早的出处。再试试代码能力。下面是「生成一个斐波那契数列」的对比:最新生成的结果,额外解释了斐波那契数列的概念,并给出了简洁的 Python 代码:同样的领悟能力提升还体现在「文生图」上,下面这张是机器之心在三月份的测试结果,从风格上说更偏 CG 绘画:此外,在最新版本的文心一言中,用户感受到的一大变化是引入了插件机制,目前提供了两个选项:第一个是默认内置插件「百度搜索」,使得文心一言具备生成实时准确信息的能力。我们知道,如果不接入互联网,对话式 AI 所提供的信息通常会受到训练数据输入时间的限制。但现在,你能问它许多「新鲜热乎」的问题了。比如,向文心一言提问:「最近的热门电视剧有哪些?」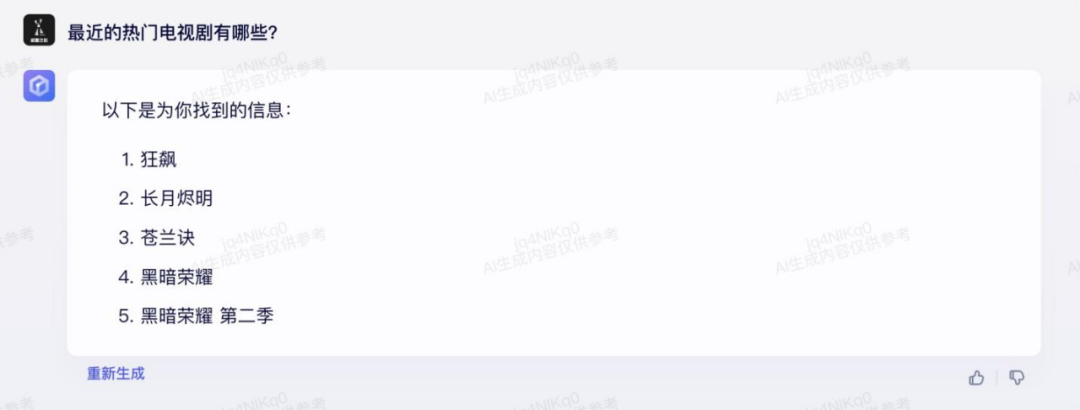
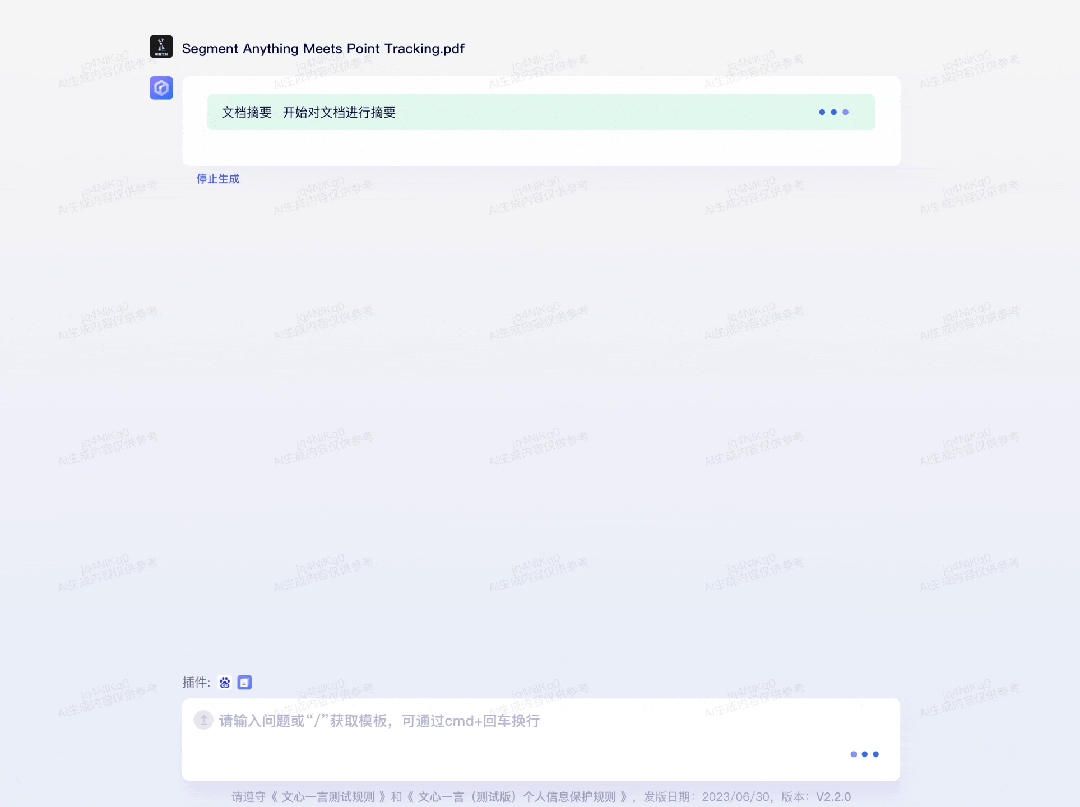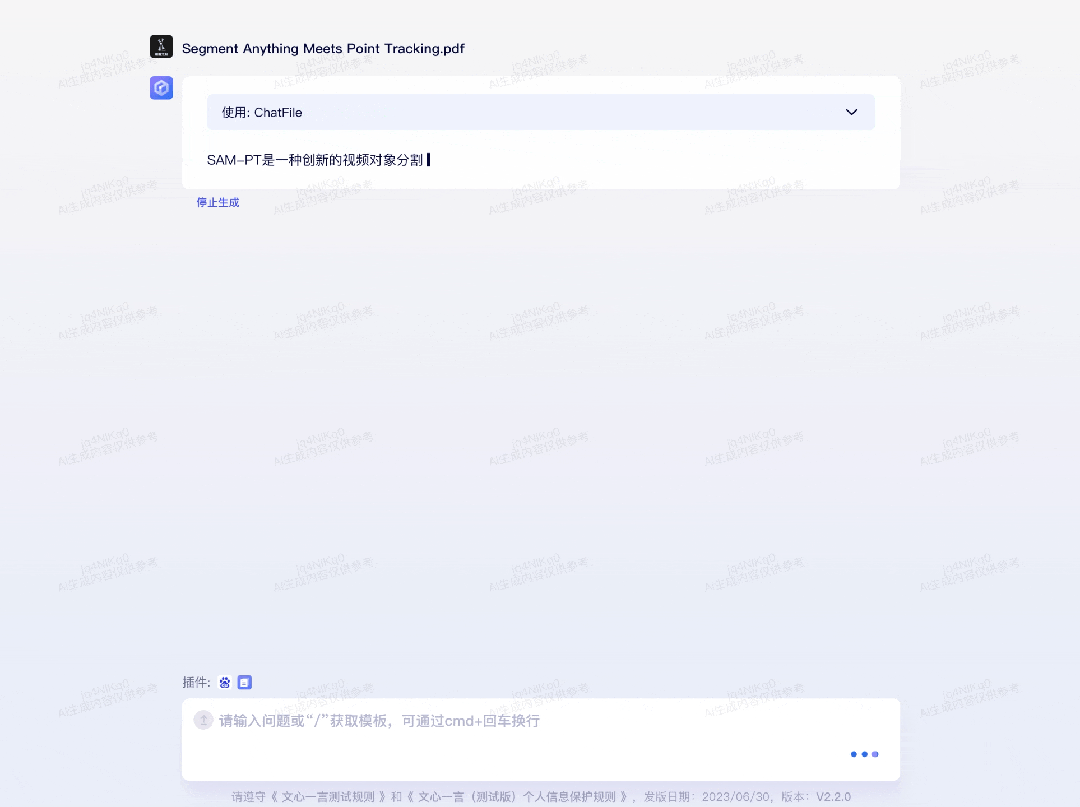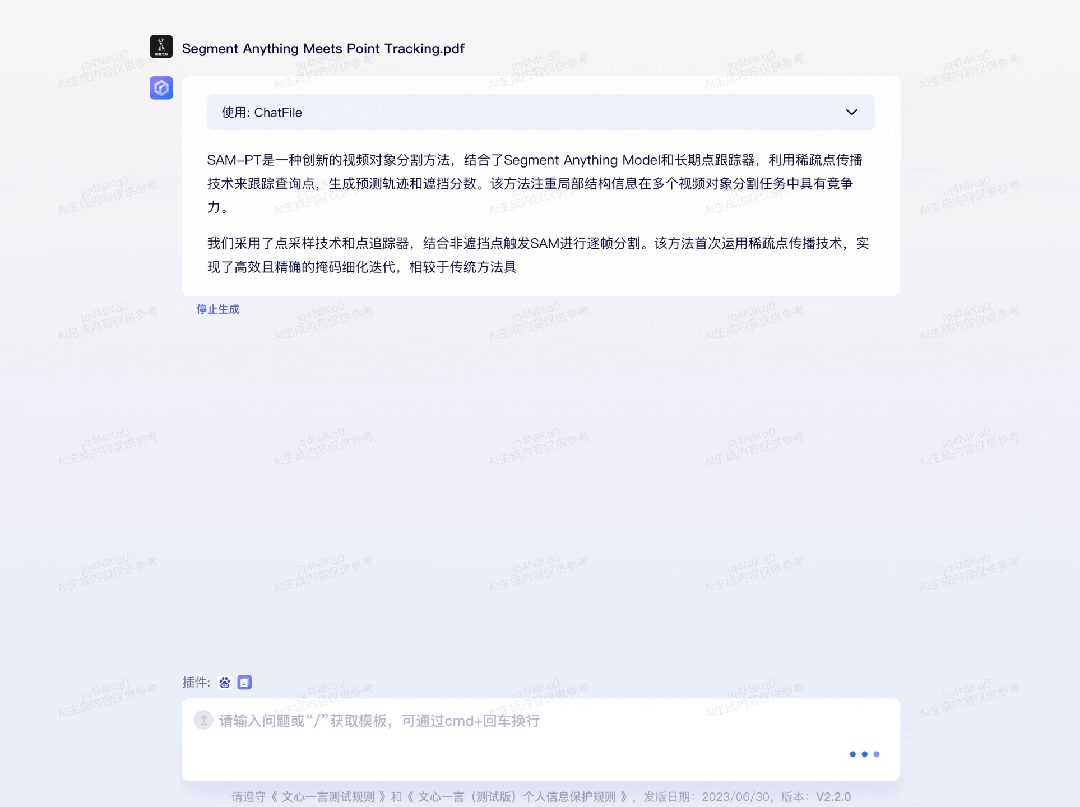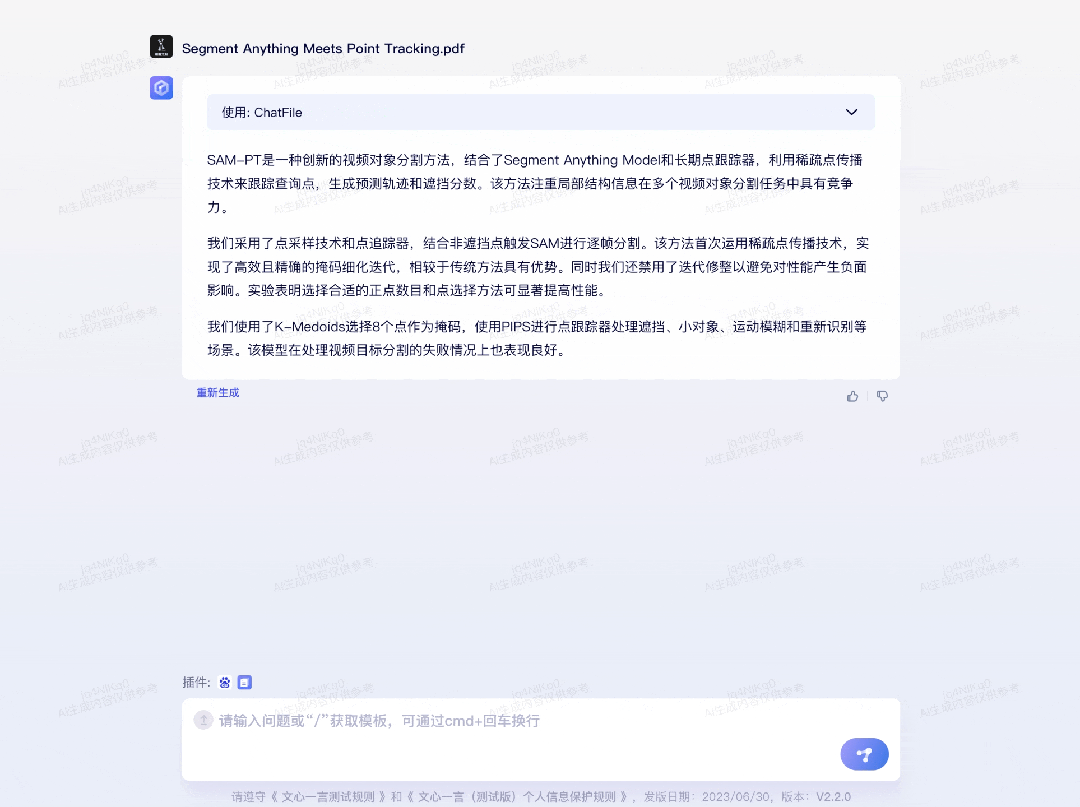
再比如,要求文心一言绘制出近日北京市的气温变化情况:为了求证文心一言引用的数据是否准确,我们也用百度搜索了今天北京市的气温情况。唯一不够全面的点在于,7 月 6 日北京市气象台发布了高温红色预警信号,北京市部分地区最高气温可达 40℃以上。第二个插件是「ChatFile」,可基于长文档进行问答和摘要。比如,机器之心某天有一篇新的论文要读,字数很多,方法很前沿,这时文心一言就能助一臂之力: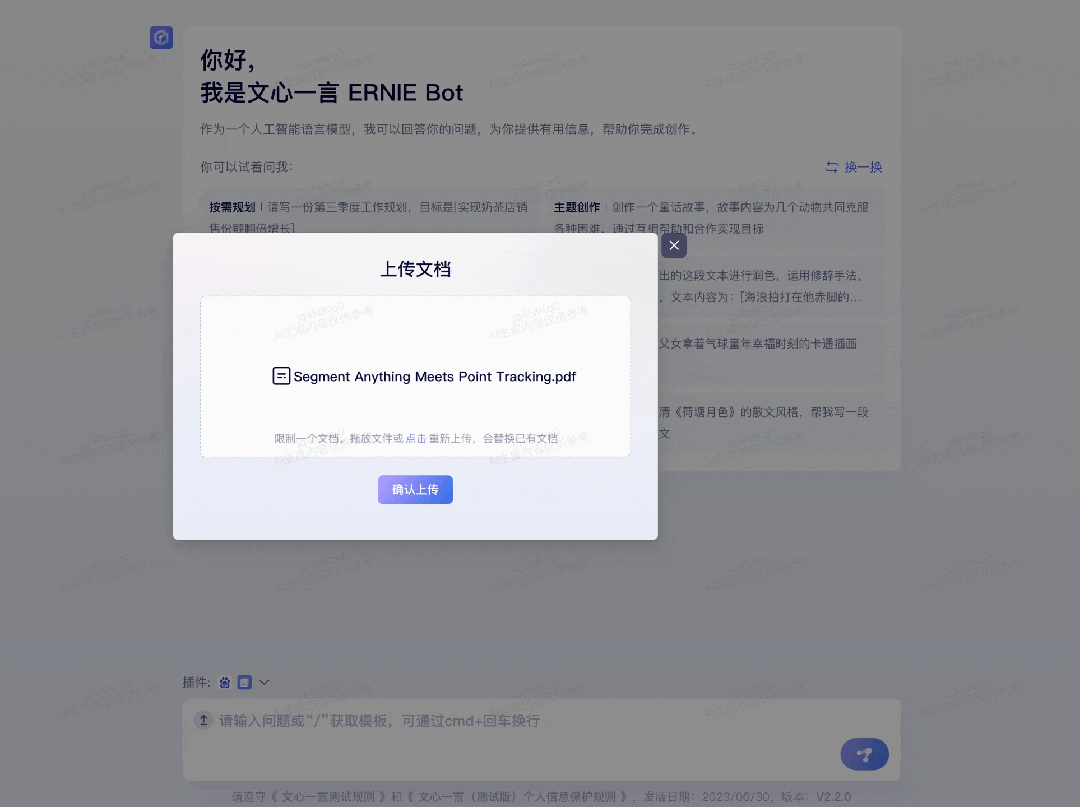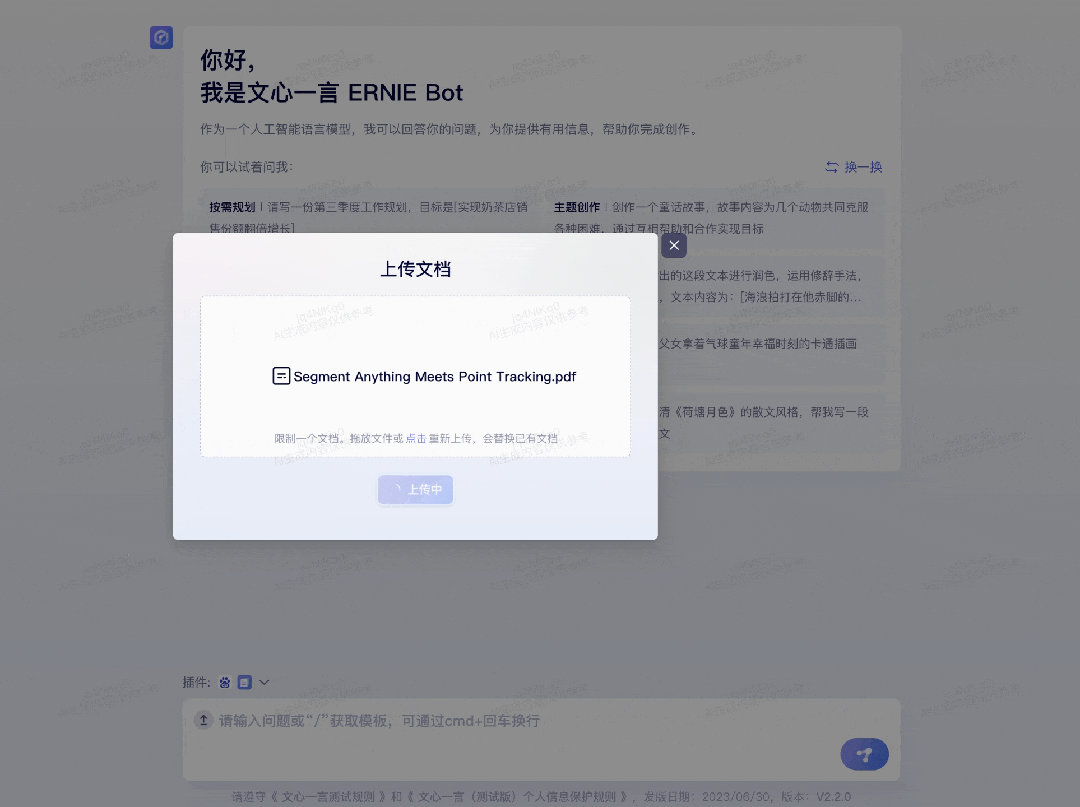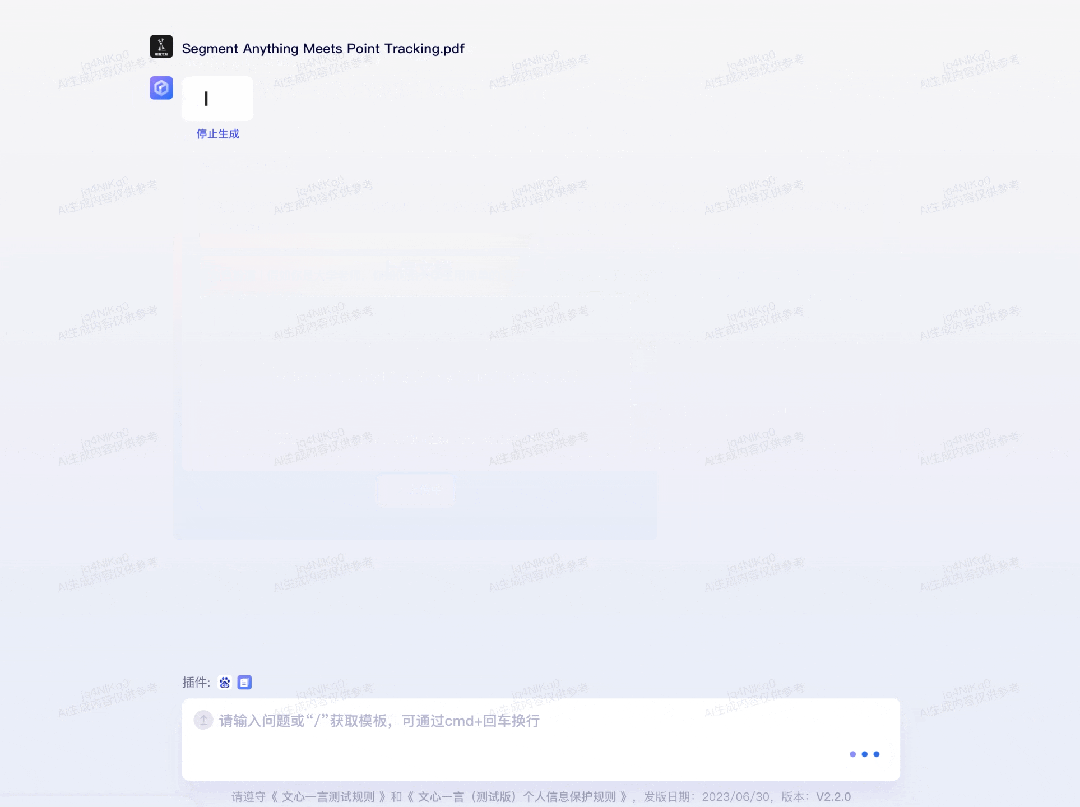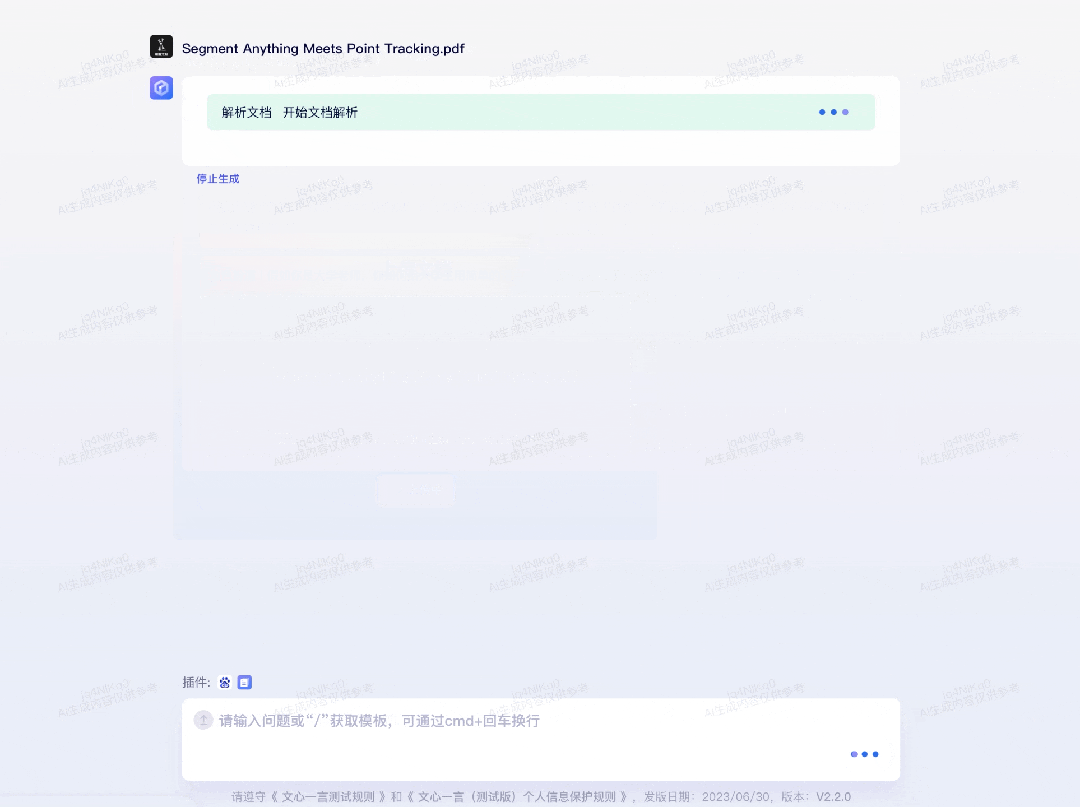
目前,使用 ChatFile 插件的前提是文件基于 PDF 或 Doc 格式,暂不支持扫描件,大小需要在 10MB 之内。王海峰表示:「插件机制的引入,将进一步扩展大模型能力的边界,也是构建大模型生态过程中非常重要的机制。」下一阶段,文心一言将发布更多优质的百度官方和第三方插件,让用户能够更好地应用文心大模型。同时,文心一言也将逐步开放插件生态给第三方开发者,帮助开发者基于文心大模型打造自己的应用。至此,我们已经直观地体会到了文心大模型 3.5 带来的变化。王海峰介绍说,文心一言 ERNIE Bot 是在 ERNIE 及 PLATO 系列模型的基础上研发的,其核心技术包括六个模块:知识增强、检索增强、对话增强、有监督精调、人类反馈的强化学习、提示。其中,有监督精调、人类反馈的强化学习、提示是大语言模型的通用技术,而知识增强、检索增强、对话增强则属于百度的特有技术,也是文心一言不断进化的基础思路。知识增强的意义十分关键,其实从英文名称「ERNIE」(Enhanced Representation from kNowledge IntEgration)就可以看出,文心大模型的成长与知识增强是密不可分的。知识增强的大语言模型不只能从原始数据中进行学习,还可以从知识和数据中进行融合学习,这也是提升大模型最终效果和效率的关键。在知识增强方面,文心一言的知识增强主要是通过知识内化和知识外用两种方式。知识内化是从大规模知识和无标注数据中,基于语义单元学习,利用知识构造训练数据,将知识学习到模型参数中,知识外用是引入外部多源异构知识,做知识推理、提示构建等等。在检索增强方面,文心一言的检索增强,来自以语义理解与语义匹配为核心技术的新一代搜索架构。通过引入搜索结果,可以为大模型提供时效性强、准确率高的参考信息,更好地满足用户需求。在对话增强方面,基于对话技术和应用积累,文心一言具备记忆机制、上下文理解和对话规划能力,实现更好的对话连贯性、合理性和逻辑性。在这次文心大模型 3.5 的打造过程中,百度团队围绕其进行的一系列创新和优化。
首先,文心大模型 3.5 在基础模型训练中采用了飞桨最先进的自适应混合并行训练技术及混合精度计算策略,采用多种策略优化数据源及数据分布,加快了模型的迭代速度,同时提升了模型效果和安全性。其次,文心大模型 3.5 创新了多类型多阶段有监督精调、多层次多粒度奖励模型、多损失函数混合优化策略、双飞轮结合的模型优化等技术,使模型效果及场景适配能力进一步提升。随着真实用户的反馈越来越多,文心一言的效果会越来越好,能力越来越强。此外,在知识增强和检索增强的基础上,百度团队进一步提出了「知识点增强技术」,首先是对用户输入的查询、问题等进行分析理解,并解析生成答案所需要的相关知识点,之后运用知识图谱和搜索引擎为这些知识点找到相应答案,最后用这些知识点构造输入给大模型的提示。知识点增强技术能为大模型注入更具体、更详细、更专业的知识点,显著提升大模型对世界知识的掌握和运用,使其完成各项任务的效果显著提升。最后,在推理方面,通过大规模逻辑数据构建、逻辑知识建模、粗粒度与细粒度语义知识组合以及符号神经网络技术,显著提升文心大模型 3.5 在逻辑推理、数学计算及代码生成等任务上的表现。大模型的出现,已经改变了 IT 行业的整个技术栈架构。在人工智能时代之前,IT 技术栈通常是三层架构:芯片层、操作系统层、应用层。当人工智能时代来临之后,技术栈变为四层架构:芯片层、框架层、模型层、应用层。百度从 2010 年开始全面布局人工智能,是全球为数不多、进行全栈布局的人工智能公司。目前,从芯片层的昆仑芯片、框架层的飞桨深度学习平台、模型层的文心大模型到应用层的搜索、小度、Apollo 等,百度在技术栈的各层都有领先业界的关键自研技术,实现了层与层反馈,端到端优化,大幅提升效率。在现场,王海峰还透露了飞桨的一个最新数字。飞桨迄今已经凝聚 750 万名开发者,这是百度 2023 年以来首次对外披露飞桨生态最新数据。位于框架层的飞桨是国内首个自主研发的产业级深度学习开源开放平台,并在国内的深度学习平台综合市场份额上连续两年位居第一。
最新的文心大模型 3.5 同样经历了四层架构的端到端优化,尤其是框架和模型层的协同优化,让训练速度、模型效果加速提升。大模型热潮已持续半年,却未有退潮的趋势,但在火热的技术进展和产品迭代之外,我们应该关心的下一步是:如何落地应用。正如百度创始人、董事长兼首席执行官李彦宏所言:「新的国际竞争战略关键点,不是一个国家有多少个大模型,而是你的大模型上有多少原生的 AI 应用,这些个应用在多大程度上提升了生产效率。」文心一言的实践,或许能够为行业提供一些可借鉴的经验。面向 C 端用户,文心一言 App 的上线与插件机制的引入,能够帮助文心一言打造一个「终端 + 平台+生态」的完整系统,探索 ToC 商业化模式。面向 B 端市场,一般的通用大模型往往缺乏具体、专业的场景支持,而文心一言正在积极应用到各种应用场景,比如智能办公、智能会议、智能编程、智能营销、智能媒体、智能教育、智能金融等。在文心一言之外,百度还拥有 11 个行业大模型,覆盖交通、能源等重点领域。例如,百度「如流」已经基于文心一言的能力上线了「智能总结」、「超级助手」等多个新功能,不仅能帮助总结工作沟通要点,实时记录会议内容,形成会议议题、摘要及总结等关键信息,还可以通过各类插件完成指令任务,包括查询日程、创建会议、设置待办、申请休假等。对于编程工作,百度的智能编码助手 Comate 能够根据自然语言的描述,生成对应的代码片段,还支持在代码编辑区内根据注释自动生成代码,提升开发效率:当然,今天的大模型产业化其实还面临着很大的挑战,模型体积大、训练难度高、算力数据需求高…… 对于任何一家公司,不管是模型提供方还是模型使用方,这些挑战都是同样存在的且不容忽视的。因此,想要在技术突破之后,走出产业化的关键一步,就必须将复杂的事情简单化,同时将落地的成本打下来。这也是以百度为代表的大模型生产厂商正在探索的道路:封装已有的、复杂的模型生产过程,并开放精调、推理、部署的各项工具,让用户能够「上手即用」。在理想的状态下,未来的任何一家企业,都只需要提供业务需求和少量精调数据,就能在短时间内找到合适的模型并完成场景适配。借此,众多大模型才能真正释放的力量,有效支撑千行百业的应用。© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]