大规模语言模型在自然语言处理方面展现出令人惊讶的推理能力,但其内在机理尚不清晰。随着大规模语言模型的广泛应用,阐明模型的运行机制对应用安全性、性能局限性和可控的社会影响至关重要。近期,中美多家研究机构(新泽西理工学院、约翰斯・霍普金斯大学、维克森林大学、佐治亚大学、上海交大、百度等)联合发布了大模型可解释性技术的综述,分别对传统的 fine-tuning 模型和基于 prompting 的超大模型的可解释性技术进行了全面的梳理,并探讨了模型解释的评估标准和未来的研究挑战。
- 论文链接:https://arxiv.org/abs/2309.01029
- Github 链接:https://github.com/hy-zhao23/Explainability-for-Large-Language-Models

为何解释大模型有点难?大语言模型在自然语言处理任务上的惊艳表现引起了社会广泛的关注。与此同时,如何解释大模型在跨任务中令人惊艳的表现是学术界面临的迫切挑战之一。不同于传统的机器学习或者深度学习模型,超大的模型架构和海量的学习资料使得大模型具备了强大的推理泛化能力。大语言模型 (LLMs) 提供可解释性的几个主要难点包括:- 模型复杂性高。区别于 LLM 时代之前的深度学习模型或者传统的统计机器学习模型,LLMs 模型规模巨大,包含数十亿个参数,其内部表示和推理过程非常复杂,很难针对其具体的输出给出解释。
- 数据依赖性强。LLMs 在训练过程中依赖大规模文本语料,这些训练数据中的偏见、错误等都可能影响模型,但很难完整判断训练数据的质量对模型的影响。
- 黑箱性质。我们通常把 LLMs 看做黑箱模型,即使是对于开源的模型来说,比如 Llama-2。我们很难显式地判断它的内部推理链和决策过程,只能根据输入输出进行分析,这给可解释性带来困难。
- 输出不确定性。LLMs 的输出常常存在不确定性,对同一输入可能产生不同输出,这也增加了可解释性的难度。
- 评估指标不足。目前对话系统的自动评估指标还不足以完整反映模型的可解释性,需要更多考虑人类理解的评估指标。
为了更好的归纳总结大模型的可解释性,我们将 BERT 及以上级别的大模型的训练范式分为两种:1)传统 fine-tuning 范式;2)基于 prompting 的范式。对于传统 fine-tuning 范式,首先在一个较大的未标记的文本库上预训练一个基础语言模型,再通过来自特定领域的标记数据集进行 fine-tuning。常见的此类模型有 BERT, RoBERTa, ELECTRA, DeBERTa 等。基于 prompting 的范式通过使用 prompts 实现 zero-shot 或者 few-shot learning。与传统 fine-tuning 范式相同,需要预训练基础模型。但是,基于 prompting 范式的微调通常由 instruction tuning 和 reinforcement learning from human feedback (RLHF) 实现。常见的此类模型包括 GPT-3.5, GPT 4, Claude, LLaMA-2-Chat, Alpaca, Vicuna 等。其训练流程如下图:
基于传统 fine-tuning 范式的模型解释包括对单个预测的解释(局部解释)和对模型结构级别组分如神经元,网络层等的解释(全局解释)。局部解释对单个样本预测进行解释。其解释方法包括特征归因(feature attribution)、基于注意力机制的解释(attention-based)、基于样本的解释(example-based)、基于自然语言的解释(natural language explanation)。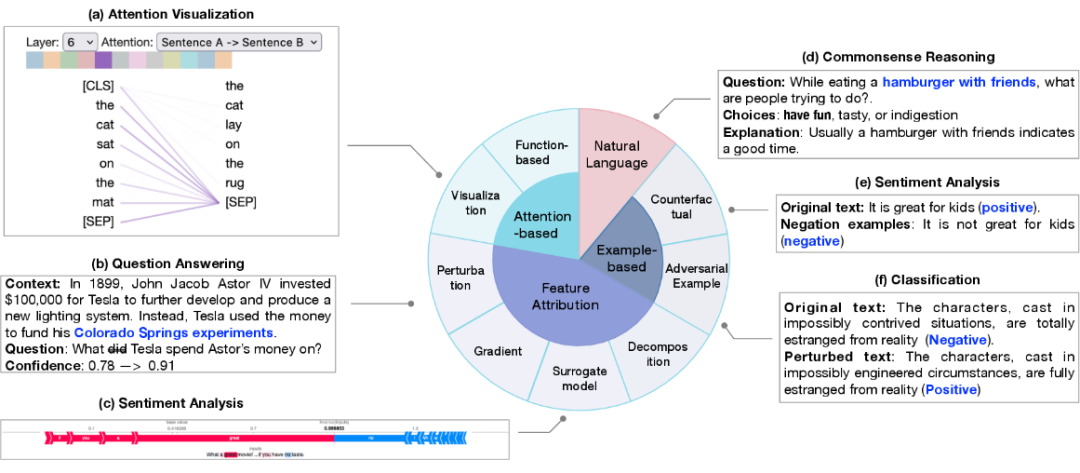
1. 特征归因旨在衡量每个输入特征(例如单词、短语、文本范围)与模型预测的相关性。特征归因方法可以分类为:
基于扰动的解释,通过修改其中特定的输入特征观察对输出结果的影响;
基于梯度的解释,将输出对输入的偏微分作为相应输入的重要性指标;
替代模型,使用简单的人类可理解的模型去拟合复杂模型的单个输出,从而获取各输入的重要性;
基于分解的技术,旨在将特征相关性得分进行线性分解。
2. 基于注意力的解释:注意力通常被作为一种关注输入中最相关部分的途径,因此注意力可能学习到可以用于解释预测的相关性信息。常见的注意力相关的解释方法包括:- 注意力可视化技术,直观地观察注意力分数在不同尺度上的变化;
- 基于函数的解释,如输出对注意力的偏微分。然而,学术界对于将注意力作为一个研究角度依然充满争议。
3. 基于样本的解释从个例的角度对模型进行探测和解释,主要分为:对抗样本和反事实样本。- 对抗样本是针对模型对微小变动非常敏感的特性而生成的数据,自然语言处理中通常通过修改文本得到,人类难以区别的文本变换通常会导致模型产生不同的预测。
- 反事实样本则是通过将文本进行如否定的变形,通常也是对模型因果推断能力的检测。
4. 自然语言解释使用原始文本和人工标记的解释进行模型训练,使得模型可以生成自然语言解释模型的决策过程。全局解释旨在从模型构成的层面包括如神经元,隐藏层和更大的组块,为大模型的工作机制提供更高阶的解释。主要探究在不同网络构成部分学习到的语义知识。- 基于探针的解释 探针解释技术主要基于分类器进行探测,通过在预训练模型或者微调模型上训练一个浅层分类器,然后在一个 holdout 数据集上进行评估,使得分类器能够识别语言特征或推理能力。
- 神经元激活 传统神经元激活分析只考虑一部分重要的神经元,再学习神经元与语义特性之间的关系。近来,GPT-4 也被用于解释神经元,不同于选取部分神经元进行解释,GPT-4 可以用于解释所有的神经元。
- 基于概念的解释 将输入先映射到一组概念中,再通过测量概念对预测的重要性来对模型进行解释。
基于 prompting 范式的模型解释,需要对基础模型和助手模型分别解释以区别两种模型的能力,并探究模型学习的路径。其探究的问题主要包括:为模型提供解释对 few-shot learning 的益处;理解 few-shot learning 和思维链能力的来源。- 解释对模型学习的好处 探究在 few-shot learning 的情况下解释是否对模型学习有帮助。
- 情境学习 探究情境学习在大模型中的作用机制,以及区分情境学习在大模型中和中等模型中的区别。
- 思维链 prompting 探究思维链 prompting 提高模型的表现的原因。
- Fine-tuning 的角色 助手模型通常先经过预训练获得通用语义知识,在通过监督学习和强化学习获取领域内知识。而助手模型的知识主要来源于哪个阶段依然有待研究。
- 幻觉与不确定性 大模型预测的准确性和可信度依然是目前研究的重要课题。尽管大模型的推理能力强大,但其结果常常出现错误信息和幻觉。这种预测的不确定性为其广泛应用带来了巨大的挑战。
模型解释的评估指标包含合理性 (plausibility),忠实度 (faithfulness),稳定性 (stability),鲁棒性 (robustness) 等。论文主要讲述了两个被广泛关注的围度:1)对人类的合理性;2)对模型内在逻辑的忠实度。对传统 fine-tuning 模型解释的评估主要集中在局部解释上。合理性通常需要将模型解释与人工标注的解释按照设计的标准进行测量评估。而忠实性更注重量化指标的表现,由于不同的指标关注模型或数据的方面不同,对于忠实性的度量依然缺乏统一的标准。基于 prompting 模型解释的评估则有待进一步的研究。1. 缺乏有效的正确解释。其挑战来源于两个方面:1)缺乏设计有效解释的标准;2)有效解释的缺乏导致对解释的评估同样缺乏支撑。2. 涌现现象的根源未知。对大模型涌现能力的探究可以分别从模型和数据的角度进行,从模型的角度,1)引起涌现现象的模型结构;2)具备跨语言任务超强表现的最小模型尺度和复杂度。从数据的角度,1)决定特定预测的数据子集;2)涌现能力与模型训练和数据污染的关系;3)训练数据的质量和数量对预训练和微调各自的影响。3. Fine-tuning 范式与 prompting 范式的区别。两者在 in-distribution 和 out-of-distribution 的不同表现意味着不同的推理方式。1)在数据同分布(in-distribution)之下,其推理范式的不同之处;2)在数据不同分布的情况下,模型鲁棒性的差异根源。4. 大模型的捷径学习问题。两种范式之下,模型的捷径学习问题存在于不同的方面。尽管大模型由于数据来源丰富,捷径学习的问题相对缓和。阐明捷径学习形成的机理并提出解决办法对模型的泛化依然重要。5. 注意力冗余。注意力模块的冗余问题在两种范式之中广泛存在,对注意力冗余的研究可以为模型压缩技术提供一种解决方式。6. 安全性和道德性。大模型的可解释性对控制模型并限制模型的负面影响至关重要。如偏差、不公平、信息污染、社会操控等问题。建立可解释的 AI 模型可以有效地避免上述问题,并形成符合道德规范的人工智能系统。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]