大语言模型 (LLM) 压缩一直备受关注,后训练量化(Post-training Quantization) 是其中一种常用算法,但是现有 PTQ 方法大多数都是 integer 量化,且当比特数低于 8 时,量化后模型的准确率会下降非常多。想较于 Integer (INT) 量化,Floating Point (FP) 量化能更好的表示长尾分布,因而越来越多的硬件平台开始支持 FP 量化。而这篇文章给出了大模型 FP 量化的解决方案。文章发表在 EMNLP 2023 上。

- 论文地址:https://arxiv.org/abs/2310.16836
- 代码地址:https://github.com/nbasyl/LLM-FP4
要了解本文,必须要先具备基本的有关 Floating Point Format 以及 Floating Point Quantization 的知识,首先 Floating Point Number 可以用以下公式表示:s 代表正负符号位 (sign bit),m 代表尾数位 (mantissa bits),e 代表指数位 (exponent bits)。p 是一个介于 0 到 2^e - 1 之间的值,用来表示当前数字该被划分到哪一个指数区间,d 取 0 或 1 的值,用来表示第 i 个 mantissa bit。b 是 bias,一个用来调整 exponent 区间的整数值。接下来介绍 Floating Point Quantization 是怎么运作的,首先输入值必须经过一个 scale and clip 的步骤,先把 input clip 到 Floating Point 能表示的最大区间 (±Qmax),如以下公式所示:
可以看到类似于 integer 量化,FP 量化也会加入一个 full-precision 的缩放因子 (scaling factor) 来缩放 input 到合适的区间。而缩放因子在运算矩阵乘法的时候,和低比特的矩阵乘法分开计算,所以并不会造成很大的 overhead。融入了这个 full-precision 的缩放因子之后,不同的 quantized tensor 能够被相应地 clip 到不同的最大最小值区间。在实际使用过程中,会根据输入 tensor 的值域确定需要的量化区间,然后利用公式 (4) 推导出相对应的 bias。注意公式 (4) 里的 bias 可以被用作实数值的缩放因子,见公式 (2)(3)。Floating-Point Quantization 的下一个步骤是在决定好量化区间后把区间内的值分配到相对应的量化区间内,这个步骤称为 Compare and Quantize: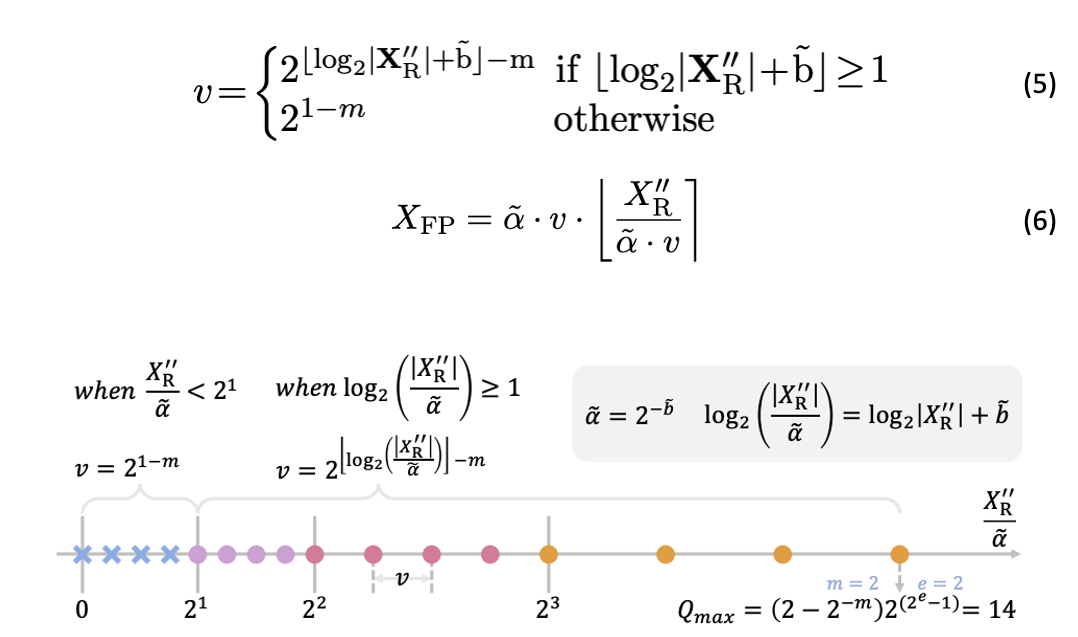
上图直观说明了量化的过程,当前的输入值,在用公式 5 比较过后,量化到不同的量化区间中。在得到量化过的 activation 和 weight 后,这里的 scaling factor 提到前面先计算,而达到如下的 efficient matrix multiplication,完成矩阵乘法的加速:接着本文指出 FP 量化的准确度,和 exponent bits 的设定以及量化的区间息息相关。如下图所示,不同的 FP format (浮点数的指数位 / 尾数位设定) 之间存在巨大的量化误差差异,只有当选取合适的 FP format 时,FP Quantization 比 INT Quantization 能更好的表示长尾分布。这个现象也在之前的论文中得到验证 [1]。
而这篇文章提出了对应的解决方案,用一个 search-based 浮点量化算法,统筹搜索出最适合的浮点数的指数位 / 尾数位设定以及对应的量化区间。除此之外,另一个同时出现在各种不同类别 Transformer 模型 (Bert,LLaMA,ViT) 中的现象也会严重影响量化的难度:那就是模型的 activation 中不同 channel 之间的数量级会有很高的差异,而同 channel 之间的量级十分一致。之前 LLM.int8 [2] 和 SmoothQuant [3] 也有类似的发现,不过这篇文章指出这个现象不仅仅存在于 LLM 中,并且在其他 Transformer 模型里也有类似现象 如下如所示,LLaMA 与 BERT 以及 DeIT-S 中的 activation 的分布都发现了类似的现象:
从图中可以看到,那些异常大的 channel 都比剩余的 channel 大很多,所以在量化 activation tensor 的过程中,量化的精度很大程度会被这些异常值决定,从而抑制其他 channel 值的量化区间,最终降低整体影响量化精度。这会导致量化的最终结果崩坏,尤其当比特数降到一定程度的时候。值得注意的是,只有 tensor-wise 和 token-wise 量化可以在 efficient matrix multipilication 的时候将 scaling factor 提取出来,而 channel-wise 量化是不支持 efficient matrix multipilication 的,见下图。
为了解决这个问题,同时维持高效率矩阵乘法 (Efficient Matrix Multiplication),本文利用少量的校正资料集,预先算出 activation 的每个 channel 的最大值,从而计算缩放因子。然后将这个缩放因子一拆为二,拆解成一个 per-tensor 的实数乘以 per-channel 的 2 的幂。而这个 2 的整数次方即用 FP 里的 exponent bias 表示。完整的过程可以用以下公式表示:进一步地,在 calibration 完成之后,这个 per-channel exponent bias 就不再变化,因此可以和 weight quantization 一起进行预计算 (pre-compute),将这个 per-channel exponent bias 整合进量化后的 weights 中,提高量化精度。完整的过程如以下公式:
可以看到在 pre-shifted 后,原本 activation 中的 full-precision per-channel biases 的位置变成了一个 tensor-wise 的实数 scaling factor ,而被拆解出来的整数 per-channel biases 被移到了 weight 中原本 integer bias 的位置,如公式 4。从而这个方法 (pre-shifted exponent bias) 能在维持 efficient matrix multiplication 的原则下,更好得提高量化精度,方法的直观展示如下图所示:
最后本文展示 Floating Point Quantization (FPQ) 方法,在 LLaMA, BERT 以及 ViTs 模型上,4-bit 量化皆取得了远超 SOTA 的结果。特别是,这篇文章展示了 4-bit 量化的 LLaMA-13B 模型,在零样本推理任务上达到平均 63.1 的分数,只比完整精度模型低了 5.8 分,且比之前的 SOTA 方法平滑量高出了 12.7,这是目前少数已知可行的 4-bit 量化方案了。

参考文献:
[1] FP8 Quantization: The Powerof the Exponent, Kuzmin et al., 2022
[2] llm.int8(): 8-bit matrix multiplication for transformers atscale, Dettmers et al., 2022
[3] Smoothquant: Accurate and efficient post-training quantization for large language models ,Xiao et al., 2022
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]