本文介绍被机器学习顶级国际会议 AAAI 2023 接收的论文 《Improving Training and Inference of Face Recognition Models via Random Temperature Scaling》。论文创新性地从概率视角出发,对分类损失函数中的温度调节参数和分类不确定度的内在关系进行分析,揭示了分类损失函数的温度调节因子是服从 Gumbel 分布的不确定度变量的尺度系数。从而提出一个新的被叫做 RTS 的训练框架对特征抽取的可靠性进行建模。基于 RTS 训练框架来训练更可靠的识别模型,使训练过程更加稳定,并在部署时提供一个对样本不确定度的度量分值,以拒识高不确定的样本,帮助建立更鲁棒的视觉识别系统。大量的实验表明 RTS 可以稳定训练并输出不确定度度量值来建立鲁棒的视觉识别系统。

- 论文地址:https://arxiv.org/abs/2212.01015
- 开源模型:https://modelscope.cn/models/damo/cv_ir_face-recognition-ood_rts/summary
不确定性问题:视觉识别系统在真实场景中通常会遇到多种干扰。例如:遮挡(装饰物或者复杂的前景),成像模糊(焦点模糊或者运动模糊),极端光照(过曝或者曝光不足等)。可以把这些干扰都归纳为噪声的影响,此外还有误检图片,通常有猫脸或狗脸等,这些误检测的数据被称作 out-of-distribution(OOD)数据。对于视觉识别来说,上述的噪声和 OOD 数据都构成了不确定性的来源,受到影响的样本会在基于深度模型提取的特征上叠加不确定性,给视觉识别系统带来干扰。例如若底库图被不确定干扰的样本污染,会形成 “特征黑洞”,给视觉识别系统带来隐患。因此需要对表征可靠性进行建模。传统的在视觉识别链路中对可靠性进行控制的方法是通过一个独立的质量模型完成的。典型的图像质量建模的方式如下:1、收集标注数据进行具体影响质量因素的标注,比如清晰度如何,有无遮挡以及姿态如何。2、根据影响因素的标注 label 进行和 1~10 质量分的映射,分数越高对应的质量越好,具体示例可以参考下图左侧示例。3、由前两步操作得到质量分的标注后进行有序回归训练,从而在部署阶段对质量分进行预测,如下图右侧示例。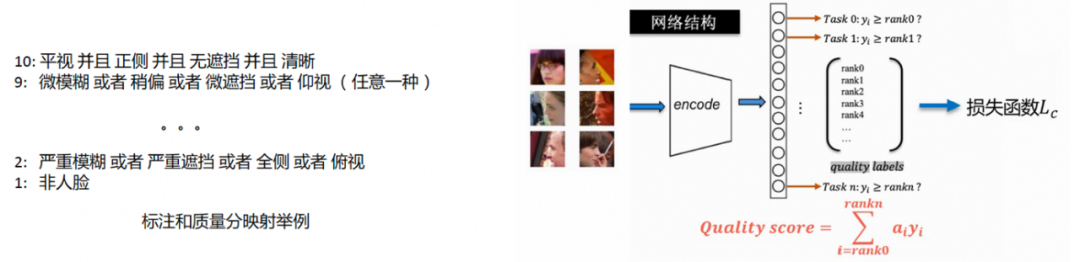
独立质量模型的方案在视觉识别的链路中需引入新的模型,且训练依赖标注信息。不确定度建模的方法有「Data Uncertainty Learning in Face Recognition」,把特征建模为高斯分布均值和方差的加和,把包含不确定性的特征送入之后的分类器进行训练。从而可以在部署阶段得到和图像质量相关的不确定度的分值。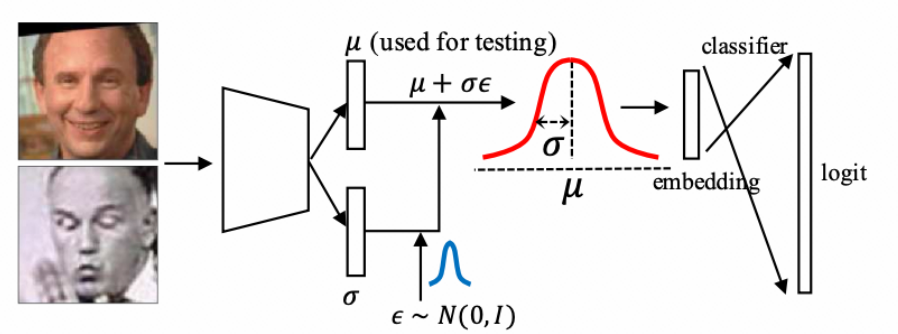
DUL 用加和的方式描述不确定度,噪声估计值的尺度也和某一类数据的特征分布紧密程度相关。如果数据分布是比较紧密的,那么 DUL 估计出的噪声的尺度也是比较小的。在 OOD 领域的工作指出,数据分布的密度对于 OOD 识别来说不是一个好的度量方式。OOD 领域的工作「Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data」用联合概率分布的形式处理 OOD 数据,分别用两个独立的分支 h(x) 和 g(x) 估计分类概率值和温度调节值。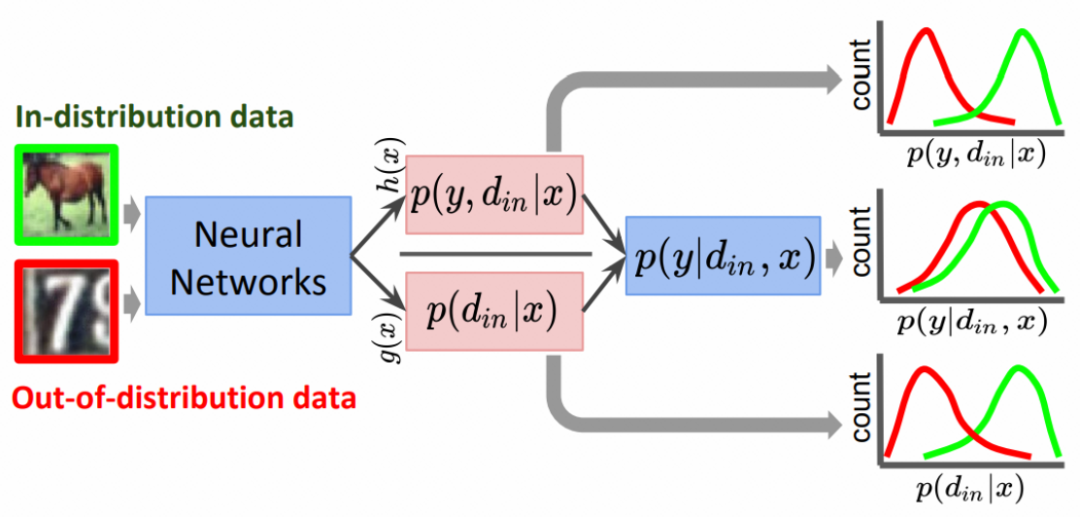
由于温度值被建模为概率值,范围被限制在 0-1 之间,对温度没有进行更好的建模。针对上述问题和相关工作,本文从概率视角出发,对分类损失函数中的温度调节因子和不确定度之间的关联进行分析,提出了 RTS 训练框架。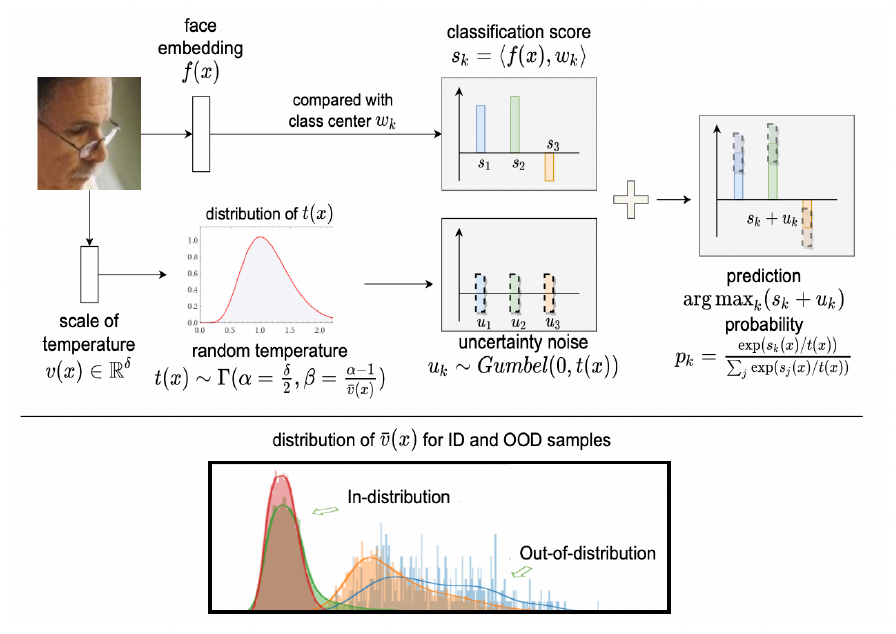
设不确定度 是符合标准 Gumbel 分布的随机变量,则概率密度函数可以写为
是符合标准 Gumbel 分布的随机变量,则概率密度函数可以写为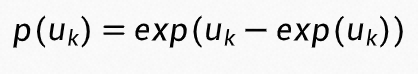 ,累积分布函数为
,累积分布函数为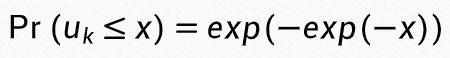 ,分类为 k 类的概率值为:
,分类为 k 类的概率值为: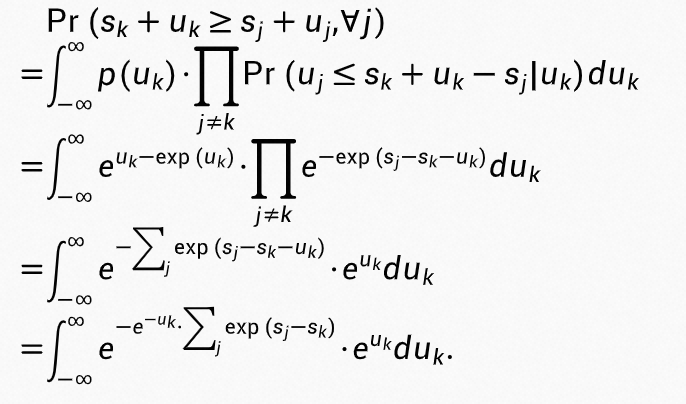
将 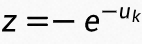 带入上式可以得到:
带入上式可以得到: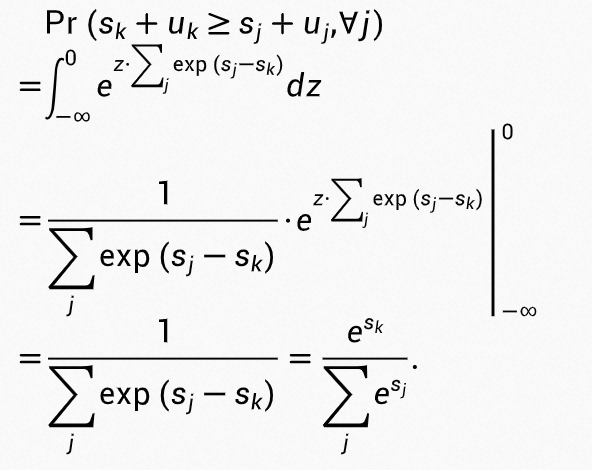
可以看到,分类为 k 类的概率值就是符合 softmax 函数的分值,同时我们可以用一个 t 来调节不确定度的尺度,即 ,则
,则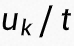 符合标准 Gumbel 分布:
符合标准 Gumbel 分布: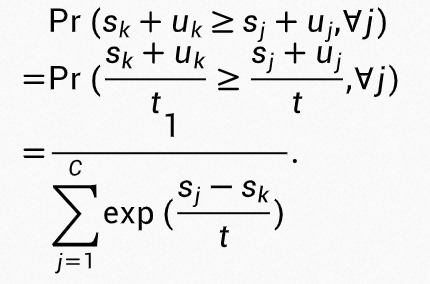
可以看到,此时分类为 k 类的概率值就是符合带温度调节值为 t 的 softmax 函数的分值。为了减少不确定度估计对分类的影响,温度 t 需要在 1 附近,因此我们把温度 t 建模为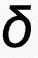 个独立 gamma 分布变量的和:
个独立 gamma 分布变量的和: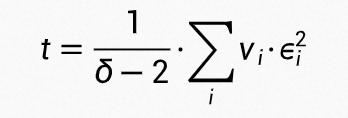
式中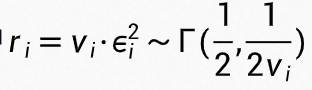 ,这样 t 服从
,这样 t 服从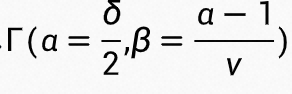 ,\beta = \frac {\alpha - 1}{v})$ 分布。v 和
,\beta = \frac {\alpha - 1}{v})$ 分布。v 和 对分布的影响如下图。
对分布的影响如下图。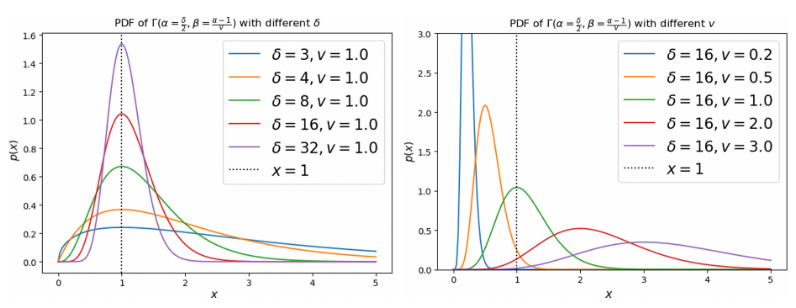
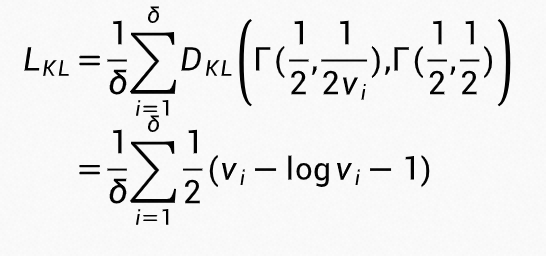

在训练阶段,训练数据只包含 face 训练数据的。误检测的猫脸和狗脸的 OOD 数据,用来在测试时验证对 OOD 数据的识别效果和测试说明 OOD 样本不确定度在训练过程中不同阶段的动态过程。我们画出了 in-distribution 数据(face)和 out-of-distribution 数据(误检测为 face 的猫脸和狗脸)在不同 epoch 数的不确定度分值,从下图可以看到初始阶段所有样本的不确定度分值都分布在较大值的附近,随着训练的进行,OOD 样本的不确定性逐渐升高,face 数据的不确定度逐渐降低,且 face 质量越好,不确定度就越低。通过设置阈值可以区分 ID 数据和 OOD 数据,且通过不确定度的分值反应图像质量。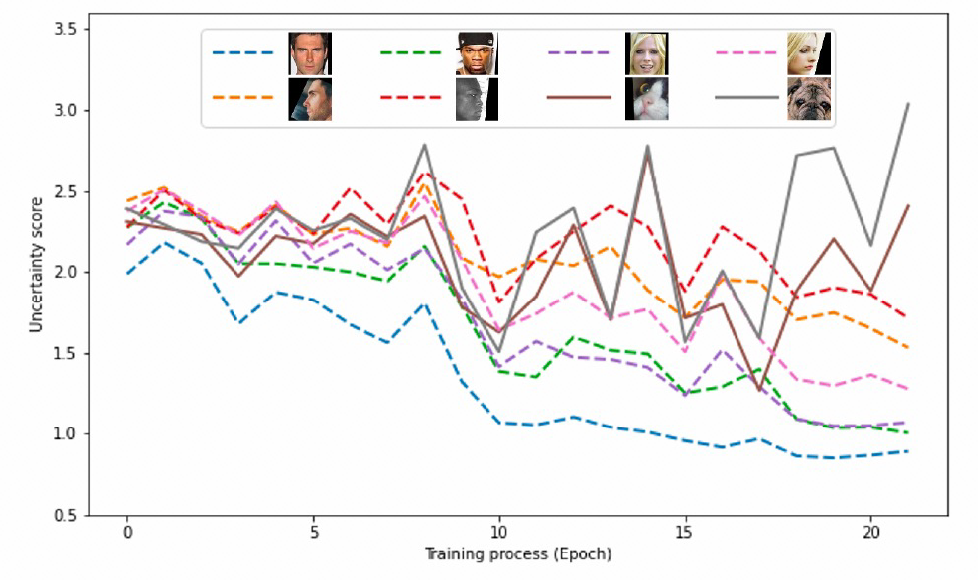
为了说明在训练阶段对噪声训练数据的鲁棒性。本文对训练集施加不同比例的噪声,基于不同比例噪声训练数据的模型识别效果如下表,可以看到 RTS 对基于噪声数据的训练也能得到较好的识别效果。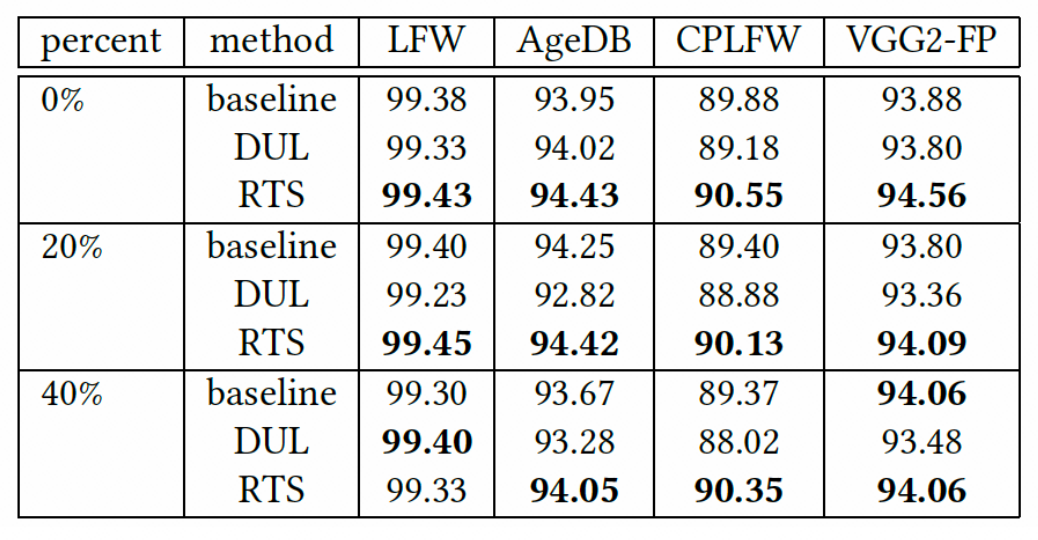
下图表明在部署阶段 RTS 框架得到的不确定度分值和 face 质量呈现高相关性
同时在 benchmark 上绘制了去掉低质量样本之后的错误匹配曲线。根据得到的不确定度分值,按照不确定度从高到底的顺序把 benchmark 中不确定度较高的样本去除,然后绘制剩下样本的错误匹配曲线。从下图可以看到,随着过滤的不确定性较高的样本越多,错误匹配是越少的,而去掉相同数量的不确定性样本时,RTS 的错误匹配更少。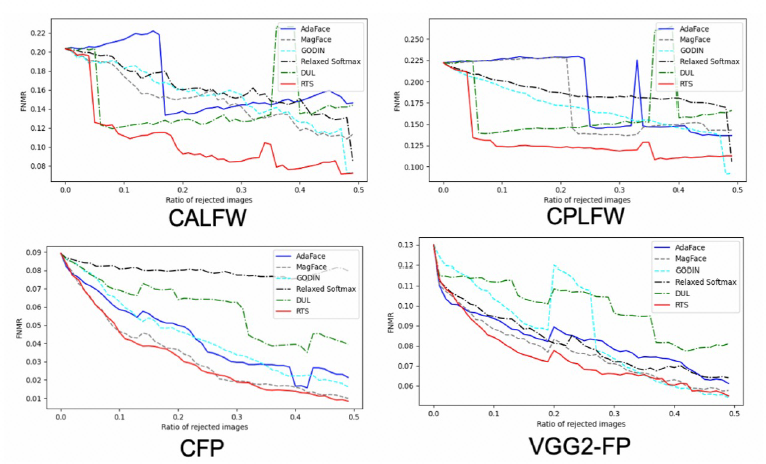
为了验证不确定度分值对 OOD 样本的识别效果,在测试时构建 in-distribution 数据集(face)和 out-of-distribution 数据集(误检测为 face 的猫脸和狗脸)。数据样例如下。
我们从两个方面来说明 RTS 的效果。首先绘制不确定度的分布图,从下图可以看到,RTS 方法对 OOD 数据具有较强的区分能力。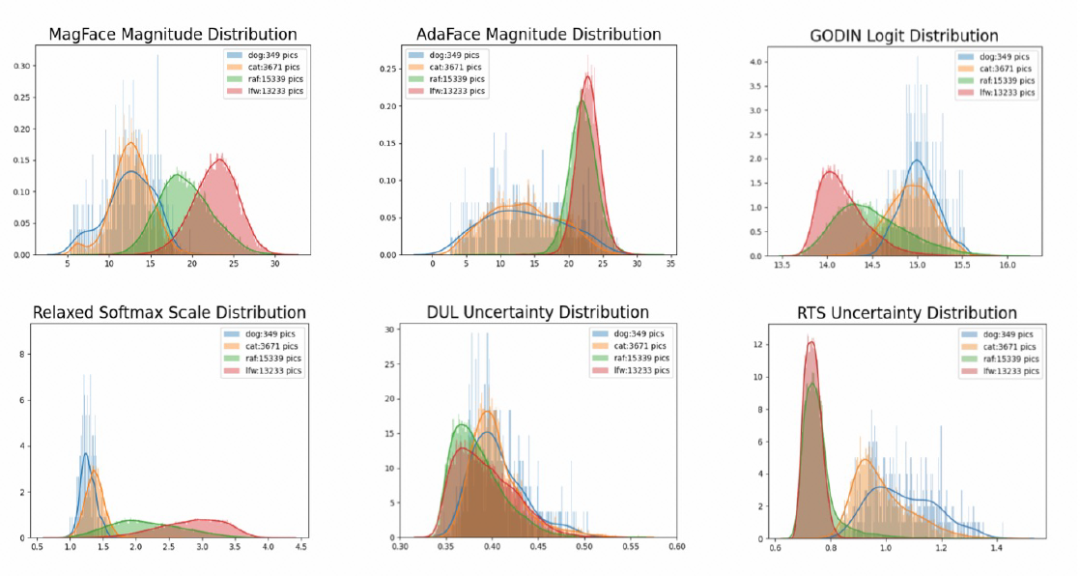
同时还绘制了 OOD 测试集上的 ROC 曲线,计算了 ROC 权限的 AUC 值,可以看到 RTS 的不确定度分值对 OOD 数据可以较好的识别。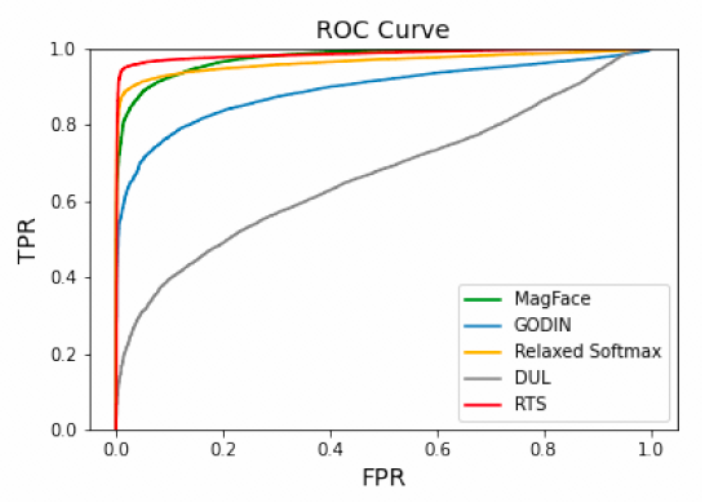

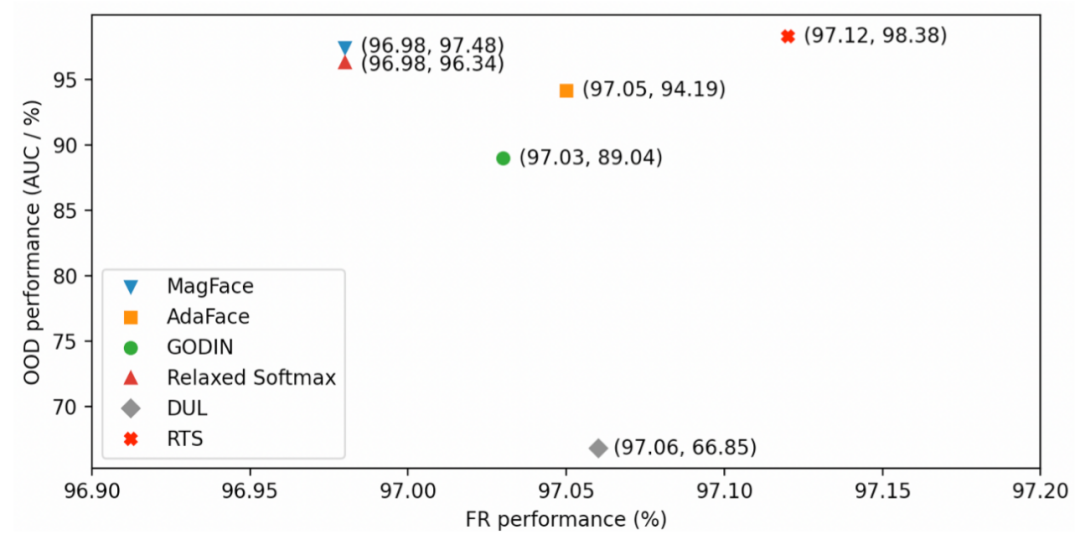
在 benchmark 上测试通用识别能力,RTS 在不影响 face 识别能力的基础上增加了对 OOD 数据的识别能力。使用 RTS 算法可以在识别和 OOD 数据识别上取得一个均衡的结果。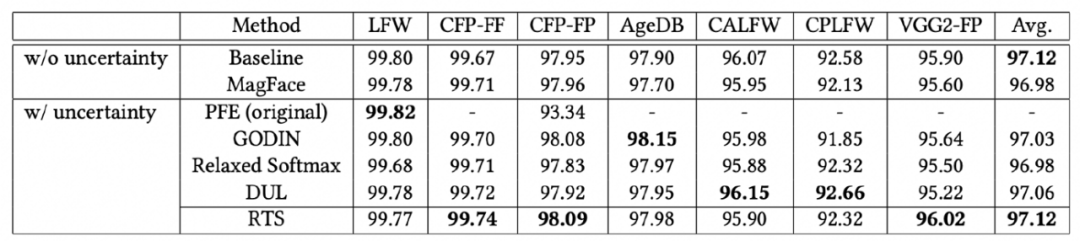
本文模型已在 modelscope 开源。另外给大家介绍下 CV 域上的开源免费模型,欢迎大家体验、下载(大部分手机端即可体验):1.https://modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary2.https://modelscope.cn/models/damo/cv_resnet101_face-detection_cvpr22papermogface/summary3.https://modelscope.cn/models/damo/cv_manual_face-detection_tinymog/summary4.https://modelscope.cn/models/damo/cv_manual_face-detection_ulfd/summary5.https://modelscope.cn/models/damo/cv_manual_face-detection_mtcnn/summary6.https://modelscope.cn/models/damo/cv_resnet_face-recognition_facemask/summary7.https://modelscope.cn/models/damo/cv_ir50_face-recognition_arcface/summary8. https://modelscope.cn/models/damo/cv_manual_face-liveness_flir/summary9.https://modelscope.cn/models/damo/cv_manual_face-liveness_flrgb/summary10.https://modelscope.cn/models/damo/cv_manual_facial-landmark-confidence_flcm/summary11.https://modelscope.cn/models/damo/cv_vgg19_facial-expression-recognition_fer/summary12.https://modelscope.cn/models/damo/cv_resnet34_face-attribute-recognition_fairface/summary
最新CVPP 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
多模态和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-多模态或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲扫码或加微信号: CVer333,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!

▲扫码进群
整理不易,请点赞和在看