
众所周知,最近聊天机器人 ChatGPT 吸引了所有人的注意力,一方面人们想要在国内复刻相同的成功,另一方面也有人焦虑于研究范式的转变,担忧现在的一些传统研究方向可能会在大模型的威力下灰飞烟灭。比如最经典的分布外问题 (Out-of-distribution, OOD)和与它相接近的对抗鲁棒性 (Adversarial Robustness) 问题: - 如果这个模型足够大,见过足够多的数据,是不是分布外这个问题就不成立了?
- 如果类似的大模型被应用到日常生活的方方面面,面对一些常见的对抗性文本,它是否具有抵抗干扰的能力?
从这一点出发,我们的工作率先对 ChatGPT 及相关大规模语言模型 (Large Language Model, LLM) 的分布外泛化性能与对抗鲁棒性做了一些评测。

On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective论文链接:
https://arxiv.org/abs/2302.12095代码链接:
https://github.com/microsoft/robustlearn
对抗文本数据集我们主要选择了 AdvGLUE [1] 和 ANLI [2]。AdvGLUE 是从自然语言理解领域被广泛使用的基准数据集 GLUE [3] 衍生出来的一个对抗版本,包含五个自然语言理解任务:斯坦福情感树库情感分析 (SST2),多种体裁自然语言推理 (MNLI),问题自然语言推理 (QNLI),Quora 问题对 (QQP) 和文本蕴涵识别 (RTE)。按照任务的不同,模型需要判断句子的情感是正面负面还是中性;两个文本之间是否具有蕴含、矛盾或中立关系;以及两个问题之间是否具有等价、不等价或中性关系。▲ Photo Credit: AdvGLUE
AdvGLUE 在构建数据集的时候分别从词汇层面,句子层面和人工构造这三个层面来构造对抗样本。比如:
- 词汇层面:笔误;同义词替代;语境下潜在词替换;知识引导扰动等;

从 AdvGLUE 展示的结果来看,仅仅只是添加微小的扰动(甚至这些扰动在我们人类看来微乎其微),就能让(强大的)语言模型得出错误的结果。那么,ChatGPT 在这上面表现如何呢?他是否能火眼金睛地识别出这些用来诱导它做出错误选择的扰动?
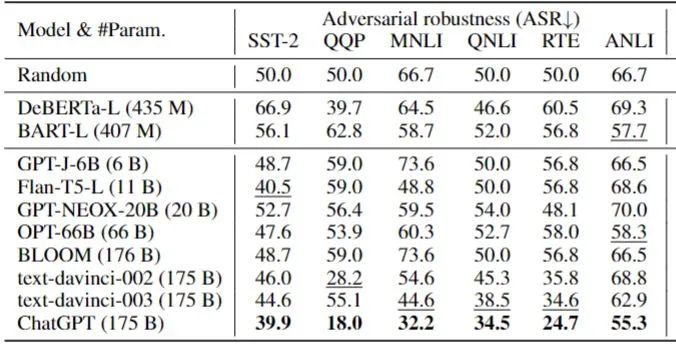
这里我们选择了一系列大规模语言模型来作为对比的参照物:从参数量上亿的 DeBERTa、BART 到参数量上十亿的 GPT-J,上百亿的 T5、OPT 到最后参数量上千亿的 BLOOM、GPT3。 表格展示的是成功攻击几率(Attack Success Rate, ASR, 越低说明模型鲁棒性越好),从表格中我们可以看到在一众模型里,ChatGPT 抵御对抗扰动的效果一骑绝尘(黑色加粗表示该任务下最低 ASR)。但是面对这些对抗性文本,ChatGPT 还是没有强大到可以完全不受其影响的程度。
接下来我们来看一下 ChatGPT 在分布外数据上的表现如何。如何选择代表分布外泛化的数据集是件不容易的事情,因为我们无法得知 ChatGPT 在训练的时候都见过了哪些数据。考虑到 ChatGPT 使用的是 2021 年及以前的数据进行训练,我们选取了 2022 年发表的两个新数据集 flipkart 与 ddxplus 对它进行 OOD 性能的检验。 flipkart [4] 是来自 kaggle 的一个商品评论数据集,模型需要判断该评论的情感色彩是积极、消极还是中性。ddxplus [5] 是 Neurips 2022 Datasets and Benchmarks 赛道释出的一个自动医疗诊断的数据集,包含合成患者的性别、年龄、初始症状、问诊对话与诊断结果。由于原始数据集过大,无法应测尽测,我们从这两个数据集中分别随机抽取了 300 条与 100 条数据进行评测。结果如图所示,我们这里汇报的是 F1 分数(越高说明模型性能越好),可以看到自 GPT2 之后的模型 (text-davinci-002, text-davinci-003, ChatGPT) 在分布外数据集上都表现良好,领先其他模型一大截,但距离完美的表现还有比较长的路要走。我们还进一步在翻译任务上评测了 ChatGPT 对扰动文本的鲁棒性。我们从前文中的 AdvGLUE 数据集中随机抽样出对抗性英文文本,手动翻译成中文作为基准,测试了 finetuned 过的 OPUS-MT-EN-ZH, Trans-OPUS-MT-EN-ZH 与 text-davinci-002, text-davinci-003 和 ChatGPT 在该对抗文本翻译任务上的效果。从结果中可以看出,相比前两个在相关数据集上进行过微调的模型相比,大规模语言模型 text-davinci-002, text-davinci-003 和 ChatGPT 在对抗文本上的零样本 (zero-shot) 翻译性能均表现得十分亮眼,翻译文本对于人类来说非常易读与合理。通过上述的评测我们可以看到,以 ChatGPT 为代表的大规模语言模型 (LLM) 在鲁棒性和分布外泛化性上相较以前的模型确实有很大的提升,但距离接近人类水平的鲁棒性和泛化性仍需更多修炼,直接大规模部署进生产环境仍需警惕。如何真正构建可信赖的智能系统,是我们需要持续思考的主题。要该从何说起呢,这跌跌撞撞的第一次。想起那个我们第一次用 CPU 推理模型,总耗时长达 101 个小时的时候,就忍不住笑。 从误用 zero-shot 模型到发现 api,到内存爆炸,从只会用单卡到多卡,到提示词调参师,这背后的故事可以有一大箩筐了。 ChatGPT 是 OpenAI 11 月 30 日发布的最先进的语言聊天模型,但是在国内渐渐掀起波澜却是年后一两个月的事情了。
我是一个研究视觉领域模型对抗鲁棒性的人,众所周知,对抗鲁棒界只需要一个非常小的肉眼都无法察觉的扰动,就能让机器做出完全错误的预测。
▲ 对抗鲁棒的经典例子
看着 ChatGPT 这么神,我也想找点对抗鲁棒性的难题考考它,可惜它不能直接接收图片,我尝试了一阵子,还是放弃了。但是转而就在思考,是不是可以用对抗性文本去检测它一下?但是由于当时有别的任务在身,所以没有做过多尝试,就把这个想法先放下了。第二天晚上,我的实习导师王老师突然发了邮件,约我们晚上碰头,讲有关 ChatGPT 的事情。一问才知道,原来王老师也产生了跟我一样的想法,想要测一测 ChatGPT 的对抗鲁棒性。王老师比我更进一步,已经帮我们确认了出发的起点:AdvGLUE 数据集,它是机器语言理解领域一个多任务对抗文本基准数据集。它旨在挑战自然语言处理模型在多个任务上的鲁棒性,包括句子分类、自然语言推理和问答等任务。
于是我们就放下手头其他的任务,第二天各自回去熟悉数据集和模型,准备开始一场酣畅淋漓的战斗。
在没开始实习之前,我在学校里做的是领域自适应方面的工作,当时懵懵懂懂被师兄师姐带入门的时候,就是用的王老师组织编写的代码库,一直深受其益。没想到这一次合作再次体会到了王老师和其他队友们强大的代码能力。我们使用的模型主要来自两大模型库,一个是 huggingface,另一个是 OpenAI。我还在磕磕绊绊从零开始摸索的时候,第二天上午王老师和其他队友已经迅速写好了各个接口的集成代码库了,我只需要在上面修改相应的数据集接口和提示词,直接调用模型名字就可以。一下子,我们的项目就开了个好头,接下来的工作就可以在这个代码库上高效展开了。由于对抗鲁棒性部分的数据集已经确定,所以剩下来的难点在于如何寻找分布外数据集。由于 ChatGPT 使用的训练数据没有披露,所以我们无从得知它到底见过哪些数据,唯一可以利用的就是它只见过 2021 年第四季度之前的数据,好吧,那我们就从 2022 年发布的新数据集中找。王老师给了我几个备选项,于是我就逐个去看这些新数据集我们能不能下载,下载之后能不能用。一番筛选之后只剩下了一个 DDXPlus 数据集能下载并且能够使用,于是我们就用了这个数据集来作为分布外鲁棒性评测的一部分。原数据集的原始数据记录是法语,不会法语的我在阅读数据集的时候完全就是抓瞎,只有把法语关键字在通过数据集附带的字典转化为英文后才能勉强读懂一二。于是,我下午的任务就是把这个数据集整理成语言模型能够阅读的输入和输出。晚上九点半我们照例碰头,大家凑在一起聊了聊各自手头的进度,一起讨论了一些未定的问题,就打算把程序跑起来然后休息了。由于队友们都十分给力,第三天一大早我们就收获了不少的结果,于是王老师就着手开始写文章,我们就继续调试提示词和实验,确保万无一失。第三天就在忙碌的调试和代码合并中度过了。第四天,我在忙完手上的分布外数据集之后又接手了一个新活,测试 ANLI 上语言模型的对抗鲁棒性,同时陈皓建议我们增加一个对抗鲁棒性文本的翻译任务,于是整体文章的内容又更丰富了。但是此时也遇到一个棘手的问题,对于比较长的文本,载入 CPU 的大模型推理起来太慢了,仅在 DDXPLUS 这一个数据集上,OPT 这个模型的推理总时长都要达到 101 小时,这是我们无法接受的。原有机器 CPU 的性能不足一下子就显现出来,但手头其他的机器都没有这么大的 RAM,于是我们半夜又折腾借机器折腾了好一会,最后终于搞到一台核数更多更强的机器,勉强跑起来了。换了新的机器之后,推理时间长的问题就可以通过一晚上的昼夜不停的工作解决了。第五天,我们的实验结果差不多都完成了,于是开始最后的收尾讨论,以及重跑一遍实验来确保结果的可靠。这个时候,最大的问题出现了,我们无法原样还原原来的实验结果,这意味着之前昼夜战斗的一切可能都化为泡影。所有人都紧张了起来,大家来不及吃午饭就匆匆进了会议开始讨论。经过一番紧张的讨论之后,我们终于明白是之前我们调用模型的方式出了错误,得到的是无意义的结果。▲ 数据集示例
于是乎我们再一次开始了模型的重新选择与重新实验。由于已经过了一遍流程,代码也不断优化了,所以虽然一切都得重来,但整体速度还是很快的。唯一的问题还是出在了几个大模型上,推理的时间太长了,试错的代价等不起。该怎么办呢?前面提到过,由于大模型体量太大,我们没有那么大显存的机器,所以我们选择了将模型载入 CPU 进行推理。在更换了一批模型后,我们发现有一些中等参数量的模型显卡的显存也能 hold 得住,用上了 GPU 推理之后速度快如闪电,再也不是之前一两个小时得漫长等待了。那么,更大的模型,能否用多卡将其载入进行推理呢?已经是第五天的深夜,全部的希望都寄托在了陈皓的身上,我们期待着他能解决这个大模型多卡推理的问题。经过一番试探之后,他成功地将 OPT 这个最大的模型分布式地载入了多张显卡中。▲ 多卡推理
这下子,即使是参数量高达 1760 亿的模型,我们也不害怕了,因为我们终于找到了正确打开大模型的方式。第六天的任务就是继续紧锣密鼓地完善论文,复核实验。我们在核对实验的时候发现有几个模型由于性能不够强大,无法读懂我们给出的提示词,所以给出了不可靠的答案。那这该怎么办呢?只能拿掉这个模型,让论文的内容变得寡淡无味吗?不,我不愿意接受这样的结果。于是我在处理完手上的事情后,开始静下心来调提示词,直到模型能够正常给出输出。
终于在最终定稿之前把这几个模型的实验结果给更新上去了。至此,终于可以长舒一口气,但也真切体会到了所谓的人工智能,就是有多少人工,就有多少智能。至此,紧锣密鼓的战斗终于告一段落,接下来的就是不断地修改润色,使之更加完美的过程。看着王老师邮件里写的"最后一次碰头",心里感慨万千。既有过去一个星期不分昼夜的拼搏的感慨,也有磕磕绊绊终于越过大山的感慨。但是最为激动和开心的,是第一次跟上了时代的浪潮,跟时下最出圈的大规模语言模型做了一次交手。近距离了解了它的不足,也讶异于它的强大。为人工智能的浪潮最终进入千家万户做了一些潮头前的评测。科技的进步不随任何个人的意志为转移,作为一个社会计算领域的科研工作者,我们能做的是用我们的所知所学,建立起人类与智能和谐相处的保护伞。希望机器智能能够发展的越来越好,也希望人类可以乘着机器的东风,站到更高更远,更自由的未来。
[1] https://adversarialglue.github.io/
[2] https://github.com/facebookresearch/anli
[3] https://gluebenchmark.com/
[4] https://www.kaggle.com/datasets/niraliivaghani/flipkart-product-customer-reviews-dataset
[5] https://github.com/bruzwen/ddxplus

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
