
来源:内容由半导体行业观察(ID:icbank)综合自天下杂志等,谢谢。
说到AI伺服器的能耗问题,不少半导体业者的直觉反应,就是靠摩尔定律解决不就好了?例如,台积刚量产的3纳米制程,能耗可以较前一代5纳米降三成到三成五。但有趣的是,英伟达最新、最高阶的GPU都不是当下台积的最先进制程。
「已经好几代都是这样,」一位资深半导体分析师也观察到这现象。
「黄仁勋算盘打得很精,」该分析师说,主要是近年先进制程愈来愈贵,得到的效能提升却愈来愈小,英伟达宁可等个两年,待制程良率稳定、价格下跌再进场,并选择将资源投在软体优化、新架构上,「效果可能好上10倍,可说是本小利多,」该分析师坦言。
英伟达能如此好整以暇,一大原因也是其寡占AI市场,没有导入昂贵新制程的迫切理由。这对于台积的未来可能是个警讯。
首先,去年台积高速运算业务占营收比重达41%,首度超越智能型手机的39%。
业界都将之视为典范转移。智能型手机市场已成熟,以AI为首的高速运算,将成为未来台积的成长火车头。
但英伟达对最先进制程的不积极态度,让上述说法,显得有点一厢情愿。
然而,一位英伟达供应商高层告诉《天下》,英伟达GPU之一H100的技术重点,其实是在旁边整颗用台积的CoWoS技术,与6颗昂贵的第三代高频记忆体(HBM3)连接起来的架构,每一颗记忆体可扩充到80GB、每秒3TB的超高速资料传输,让美国科技媒体惊呼「怪物」。
这是「后摩尔时代」的技术特征。英伟达竞争者超微的MI300,也有类似架构。与此同时,据台湾《电子时报》,近期业界传出,微软正在接触台积电供应链及旗下设计公司,希望将台积电代工厂的CoWoS封装技术用于其自研AI芯片。
正如之前所说,台积电根据中介层(interposer)的不同,将其“CoWoS”封装技术分为三种类型。一种是“CoWoS_S(Silicon Interposer)”,它使用硅(Si)衬底作为中介层。这种类型是2011年开发的第一个“CoWoS”技术,在过去,“CoWoS”是指以硅基板作为中介层的先进封装技术。另一种是“CoWoS_R(RDL Interposer)”,它使用重新布线层(RDL)作为中介层。第三个是“CoWoS_L(Local Silicon Interconnect and RDL Interposer)”,它使用小芯片(chiplet)和RDL作为中介层。请注意,“本地硅互连”通常被台积电缩写为“LSI”。“CoWoS_S”(传统的“CoWoS”)的横截面结构示例。是所谓2.5D封装的代表。通过在作为中介层的硅基板上形成高密度布线和硅通孔(TSV),可以在硅芯片之间紧密放置并传输高速信号“CoWoS_S”(原“CoWoS”)于2011年开发。这被称为“第一代(Gen-1)”CoWoS封装技术首先是被 Xilinx 的高端 FPGA 采用。其中,Si 中介层的最大尺寸为775mm 2 (25 mm x 31 mm)。它接近一个掩模版的曝光尺寸(26mm x 33mm)(在 ArF 浸入式光刻机的情况下)。FPGA 芯片制造技术是 28 纳米 CMOS 工艺。采用该技术的赛灵思高端FPGA“7V2000T”在“CoWoS_S”中配备了四个FPGA逻辑芯片。在2014年开发的第二代“CoWoS_S”中,硅中介层扩大到1150mm2。接近1287mm2,这是1.5分划板的曝光面积。2015年被赛灵思高端FPGA“XCVU440”采用。它配备了三个 FPGA 逻辑芯片。FPGA 芯片制造技术是 20 纳米 CMOS 工艺。在2016年开发的第三代“CoWoS_S”中,虽然Si中介层的尺寸没有太大变化,但高速DRAM模块“HBM”和逻辑首次混合使用。2016年率先被NVIDIA的高端GPU“GP100”采用。在这种封装下,GPU 芯片和“HBM2”混合在一起。HBM2 是硅片叠层模块(4 个 DRAM 芯片和 1 个基片(底部)通过 TSV 连接),“GP100”配备了 4 个16GB(128Gbit的HBM2 模块和大容量的DRAM和GPU高速连接。在 2019 年开发的第4代“CoWoS_S”中,Si 中介层的尺寸已扩大到相当于两个光罩的曝光面积——大约1700 mm 2。这个巨大的中介层装有一个大型逻辑芯片和 6 个 HBM2。由于一个HBM2存储的容量增加到8GB(64Gbit),所以总容量为48GB(384Gbit),是第三代容量的3倍。
“CoWoS_S”(传统的“CoWoS”)的演变。在上文中我们谈到,高性能封装技术“CoWoS(Chip on Wafer on Substrate)”从首次开发起约10年的时间内推出了多款衍生产品。接下来,让我们还回顾一下“CoWoS”技术自 2011 年首次开发以来的发展历程。最初的“CoWoS”技术使用硅(Si)衬底作为中间衬底(中介层)。目前,台积电称这种类型为“CoWoS_S(Silicon Interposer)”。正如第一部分所解释的,从2011年的第一代到2019年的第四代,CoWoS技术不断扩大中介层面积、晶体管数量和内存容量。
“CoWoS_S”(传统的“CoWoS”)的演变。从2011年的第一代升级到2021年的第五代。2023年研发下一代“CoWoS_S”中介层原本很大,但现在变得更大了。第一代的面积相当于一个标线(775mm2),第二代和第三代的面积相当于1.5个标线(1150mm2和1170mm2)。在第 4 代中,它变得更大,达到了相当于两个标线 (1700mm2 ) 的面积。最初,安装在中介层上的硅芯片是多个逻辑芯片。从第3代开始,它支持逻辑和内存的混合加载。它现在配备了一个逻辑 (SoC) 芯片和一组高速DRAM模块“HBM(高带宽内存)”的层压芯片。具体来说,将一个SoC芯片和四个 HBM(4GBx4,总共16GB)安装在一起。到了第4代,SoC die的面积(集成规模)扩大了,要混合的 HBM 数量增加到了6个。通过将一个 HBM 的存储容量增加一倍,HBM 的总容量已显著增加到第三代的三倍(48GB)。台积电在今年(2021年)开发的第5代“CoWoS_S”将Si中介层进一步扩大到2500mm2,这相当于3个光罩,是第3代的两倍大,安装了8个HBM。Logic 的硅芯片再次成为小芯片,在总面积为1200mm2 的地方放置了两个迷你芯片。可安装的 HBM 规格为“HBM2E”(HBM 2nd generation 的增强版)。通过使铜 (Cu) 布线比以前更厚,Si 中介层的重新布线层 (RDL) 将薄层电阻降低到不到一半。用 5 层铜线连接硅芯片。台积电还重新设计了 TSV,以减少由于硅穿透孔 (TSV) 引起的高频损耗。重新设计后,2GHz至14GHz高频范围内的插入损耗(S21)从传统的0.1dB以上降低到0.05dB以上。此外,通过将具有深槽的高容量电容器“eDTC(嵌入式深沟槽电容器)”装入 Si 中介层,台积电进一步稳定了电源系统。eDTC 的电容密度为 300nF/mm2。在100MHz至2GHz的频率范围内,配电网络 (PDN) 的阻抗已通过eDTC降低到35%以下。支持第5代“CoWoS_S”(传统“CoWoS”)的基本技术
下一代(第6代)“CoWoS_S”计划于2023年开发。Si中介层的尺寸更大,有四个掩模版。通过简单的计算,它达到约3400mm2 (约58.6mm见方)。逻辑部分配备了两个或更多带有小芯片的迷你芯片,内存部分配备了12个HBM。相应的HBM规范似乎是“HBM3”。 “CoWoS_S”发展路线图高性能计算(HPC)的封装技术“CoWoS(Chip on Wafer on Substrate)”首次出现在10年前(2011年)。正如前文所说,在过去十年里,我们不断扩大集成规模,提升每一代的性能,并为“CoWoS”开发了衍生产品,目前主流产品的名称已更改为“CoWoS_S”。“_S”表示将硅(Si)基板用于中间基板(中介层)。除了高密度连接之外,硅中介层在缓解封装基板(树脂基板)和硅芯片(逻辑芯片、存储器芯片等)之间发生的热变形方面也扮演着重要的角色。因为热失真会导致电路操作延迟。在一个活动上,台积电展示了倒装芯片连接封装和 CoWoS 封装与7nm代 CMOS 逻辑的 CPI(每条指令的时钟数)的比较结果。如果在倒装芯片连接到封装板(树脂板)的700 mm 2 SoC(片上系统)芯片上将 CPI 设置为“1”,则采用 CoWoS_S 技术封装的 840mm2 SoC 芯片的 CPI短至“0.4”。成为。这意味着指令处理性能提高了 2.5 倍。
“CoWoS_S”发展路线图高性能计算(HPC)的封装技术“CoWoS(Chip on Wafer on Substrate)”首次出现在10年前(2011年)。正如前文所说,在过去十年里,我们不断扩大集成规模,提升每一代的性能,并为“CoWoS”开发了衍生产品,目前主流产品的名称已更改为“CoWoS_S”。“_S”表示将硅(Si)基板用于中间基板(中介层)。除了高密度连接之外,硅中介层在缓解封装基板(树脂基板)和硅芯片(逻辑芯片、存储器芯片等)之间发生的热变形方面也扮演着重要的角色。因为热失真会导致电路操作延迟。在一个活动上,台积电展示了倒装芯片连接封装和 CoWoS 封装与7nm代 CMOS 逻辑的 CPI(每条指令的时钟数)的比较结果。如果在倒装芯片连接到封装板(树脂板)的700 mm 2 SoC(片上系统)芯片上将 CPI 设置为“1”,则采用 CoWoS_S 技术封装的 840mm2 SoC 芯片的 CPI短至“0.4”。成为。这意味着指令处理性能提高了 2.5 倍。
将CPI(每条指令的时钟数)与“CoWoS_S”和倒装芯片进行比较。由于Si中介层减轻了热变形,“CoWoS_S”的CPI(相对值)为0.4,比倒装芯片的CPI短。如果时钟频率相同,指令处理性能将提高2.5倍混合宽带存储器“HBM”和SoC的“CoWoS_S”的标准化配置和布局
“CoWoS_S”的特点是混合了宽带内存模块“HBM(High Bandwidth Memory)”和大规模SoC的高性能子系统。通过Si中介层连接HBM和SoC,实现了宽带内存访问。“HBM”的规格对于每一代都有共同的标准。产品的传播始于第二代“HBM2”。下一代是HBM2的增强版“HBM2E”。下一代是“HBM3”,容量越来越大,带宽越来越宽。此外,“CoWoS_S”中安装的HBM数量将增加,Si中介层面积将增加,SoC制造技术将小型化。SoC 的形式将从单芯片变为小芯片,再到SoIC(集成芯片系统)。构成“CoWoS_S”的元素技术将会增加并变得更加复杂。 宽带内存模组“HBM”(横轴)的演进以及对应“CoWoS_S”(纵轴)的功耗、速度、内存带的转变因此,台积电提供具有标准化配置和布局的“CoWoS_S STAR(标准架构)”,以便作为客户的半导体供应商可以快速开发采用“CoWoS_S”的子系统。可使用对应于 HBM2 的“STAR 1.0”和对应于 HBM2E 的“STAR 2.0”。
宽带内存模组“HBM”(横轴)的演进以及对应“CoWoS_S”(纵轴)的功耗、速度、内存带的转变因此,台积电提供具有标准化配置和布局的“CoWoS_S STAR(标准架构)”,以便作为客户的半导体供应商可以快速开发采用“CoWoS_S”的子系统。可使用对应于 HBM2 的“STAR 1.0”和对应于 HBM2E 的“STAR 2.0”。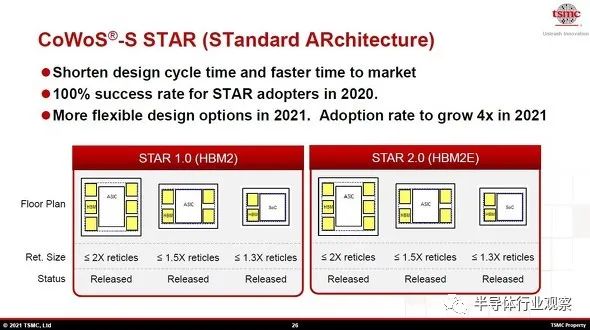 将SoC和HBM混合的“CoWoS_S”的配置标准化的“CoWoS_S STAR”概述标准化的是硅中介层的最大尺寸、HBM 的数量和硅芯片的布局。客户可以从三种基本规格中进行选择:最大配置、中间配置和最小配置。最大配置是硅中介层,其曝光面积相当于掩模版的两倍。SoC(或ASIC)布置在中央,三个HBM分别放置在其左右两侧。中间配置的曝光面积相当于硅中介层最大尺寸的掩模版的 1.5 倍。SoC布局在中央,左右两侧分别放置了两个HBM。最小配置是硅中介层的最大尺寸,即相当于光罩1.3倍的曝光面积。两个 HBM 沿 SoC(或 ASIC)的侧面放置。HBM2兼容“STAR 1.0”和HBM2E兼容“STAR 2.0”从最大配置到最小配置的标准规格相同。似乎他们有意识地在“STAR 2.0”中重用“STAR 1.0”的开发资源。
将SoC和HBM混合的“CoWoS_S”的配置标准化的“CoWoS_S STAR”概述标准化的是硅中介层的最大尺寸、HBM 的数量和硅芯片的布局。客户可以从三种基本规格中进行选择:最大配置、中间配置和最小配置。最大配置是硅中介层,其曝光面积相当于掩模版的两倍。SoC(或ASIC)布置在中央,三个HBM分别放置在其左右两侧。中间配置的曝光面积相当于硅中介层最大尺寸的掩模版的 1.5 倍。SoC布局在中央,左右两侧分别放置了两个HBM。最小配置是硅中介层的最大尺寸,即相当于光罩1.3倍的曝光面积。两个 HBM 沿 SoC(或 ASIC)的侧面放置。HBM2兼容“STAR 1.0”和HBM2E兼容“STAR 2.0”从最大配置到最小配置的标准规格相同。似乎他们有意识地在“STAR 2.0”中重用“STAR 1.0”的开发资源。
台积电院士兼副总裁 LC Lu 在之前的一个短短 26 分钟演讲内用数十张幻灯片谈到了实现系统创新。
台积电是全球排名第一的半导体代工企业,他们的开放式创新平台 (OIP) 活动很受欢迎,参加人数也很多,因为所提供的工艺技术和 IP 对许多半导体设计领域都非常有吸引力。台积电技术路线图显示了到 2025 年的 FinFET 和 Nanosheet 计划的时间表。
从 N3 开始,出现了一种名为FinFlex的新产品,它使用设计技术协同优化 (DTCO),有望为节能和高性能等细分市场改进功率、性能和面积 (PPA)。借助 FinFlex 方法,设计人员可以根据其设计目标从三种晶体管配置中进行选择:
3-2 fin blocks,用于高性能
2-2 fin,高效性能
2-1 fin,功率最低,密度最佳
工艺节点 N16 到 N3 中使用的fin选择的历史如下所示:
EDA 供应商 Synopsys、Cadence、Siemens EDA 和 ANSYS 已经更新了他们的工具以支持 FinFlex,并且在单个 SoC 中,您甚至可以混合使用fin block选项。沿着时序关键路径,您可以使用高fin单元,而非关键路径单元可以是低fin。作为进程缩放优势的示例,Lu 展示了一个 ARM Cortex-A72 CPU,在 N7 中实现,具有 2 个fin,N5 具有 2 个fin,最后是 N3E 具有 2-1 个fin:
N3E 的 IP 单元来自多家供应商:TSMC、Synopsys、Silicon Creations、Analog Bits、eMemory、Cadence、Alphawave、GUC、Credo。IP 准备状态分为三种状态:硅报告准备就绪、硅前设计套件准备就绪和开发中。
在 TSMC,他们的模拟 IP 使用结构化程度更高的规则布局,这会产生更高的产量,并让 EDA 工具自动化模拟流程以提高生产力。TSMC 模拟单元具有均匀的多晶硅和氧化物密度,有助于提高良率。他们的模拟迁移流程、自动晶体管大小调整和匹配驱动的布局布线支持使用 Cadence 和 Synopsys 工具实现设计流程自动化。
模拟单元可以通过以下步骤进行移植:原理图移植、电路优化、自动布局和自动布线。例如,使用他们的模拟迁移流程将 VCO 单元从 N4 迁移到 N3E 需要 20 天,而手动方法需要 50 天,快了大约 2.5 倍。
台积电需要考虑三种类型的封装,分别是二维封装(InFO_oS、InFO_PoP)2.5D封装(CoWoS)和3D封装(SoIC和InFO-3D)
3DFabric 中有八种包装选择:
最近使用 SoIC 封装的一个例子是 AMD EPYC 处理器,这是一种数据中心 CPU,它的互连密度比 2D 封装提高了 200 倍,比传统 3D 堆叠提高了 15 倍,CPU 性能提高了 50-80%。
3D IC 设计复杂性通过 3Dblox 解决,这是一种使用通用语言实现 EDA 工具互操作性的方法,涵盖物理架构和逻辑连接。四大 EDA 供应商(Synopsys、Cadence、Siemens、Ansys)通过完成一系列五个测试用例,为 3Dblox 方法准备了工具:CoWoS-S、InFO-3D、SoIC、CoWoS-L 1、CoWoS-L 2。
台积电通过与以下领域的供应商合作创建了 3DFabric 联盟:IP、EDA、设计中心联盟 (DCA)、云、价值链联盟 (VCA)、内存、OSAT、基板、测试。对于内存集成,台积电与美光、三星内存和 SK 海力士合作,以实现 CoWoS 和 HBM 集成。EDA测试厂商包括:Cadence、西门子EDA和Synopsys。IC测试供应商包括:Advantest和Teradyne。
AMD、AWS 和 NVIDIA 等半导体设计公司正在使用 3DFabric 联盟,随着 2D、2.5D 和 3D 封装的使用吸引了更多的产品创意,这个数字只会随着时间的推移而增加。台积电拥有世界一流的DTCO工程团队,国际竞争足以让他们不断创新新业务。数字、模拟和汽车细分市场将受益于台积电在 FinFlex 上宣布的技术路线图选择。3D 芯片设计得到 3DFabric 联盟中聚集的团队合作的支持。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3368内容,欢迎关注。
『半导体第一垂直媒体』
实时 专业 原创 深度
识别二维码,回复下方关键词,阅读更多
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装
回复 投稿,看《如何成为“半导体行业观察”的一员 》
回复 搜索,还能轻松找到其他你感兴趣的文章!