给你几张照片,你可以猜到在三维世界中他们究竟长什么样子吗?

我们可以凭借丰富的视觉先验知识,仅凭一张照片轻松推断出其3D几何形态及在不同视角下的样貌。这种能力得益于我们对视觉世界的深入理解。而今,恰如人类,一些卓越的图像生成模型,如Stable Diffusion和Midjourney,同样拥有丰富的视觉先验知识,展现出高质量的图像生成效果。基于这样的观察,研究员们提出假设:一个高质量预训练图像生成模型具有和人类一样的能力,即可以从一个真实或AI生成的图像中推理出3D内容。这个任务非常具有挑战性,既要估计潜在的 3D 几何结构,也要同时产生未见过的纹理。基于之前的假设,来自上海交通大学、HKUST、微软研究院的研究者们提出了 Make-It-3D 方法,通过使用 2D 扩散模型作为 3D-aware 先验,从单个图像中创建高保真度的 3D 物体。该框架不需要多视图图像进行训练,并可应用于任何输入图像。这篇论文也被 ICCV 2023 所接收。



- 论文链接:https://arxiv.org/pdf/2303.14184.pdf
- 项目链接:https://make-it-3d.github.io/
- Github链接:https://github.com/junshutang/Make-It-3D
该论文刚公布,就引发了推特上的热烈讨论,随后的开源代码在 Github 累计收获超过 1.1k星星。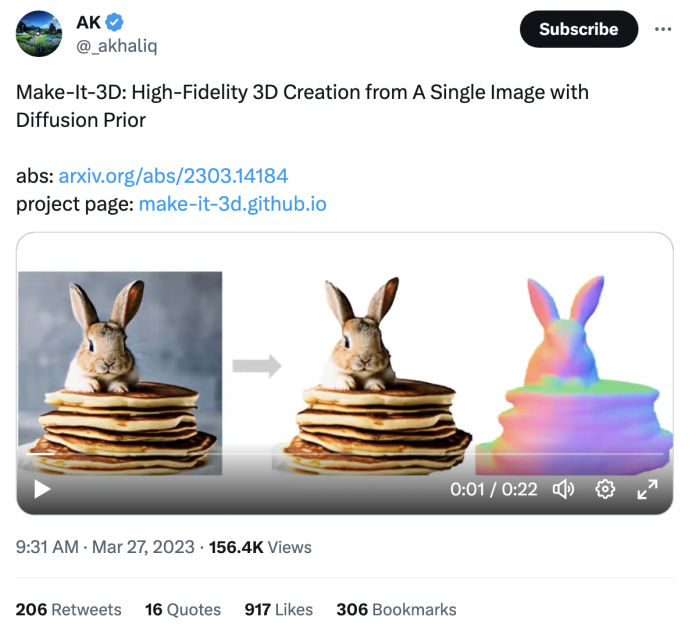
该方法在优化三维空间时,主要依据两个核心的优化目标:1. 在参考视角下的渲染结果应该与输入图片高度一致;2. 在新视角的渲染结果显示与输入一致的语义。其中,研究者采用 BLIP2 模型来为图片标上文本。基于这样的优化目标,在一阶段时期,该方法对参考视角周围的相机姿态进行随机采样。在参考视角下对渲染图和参考图施加像素级别的约束,在新视角下利用来自预训练扩散模型的先验信息度量图像和文本之间的相似性。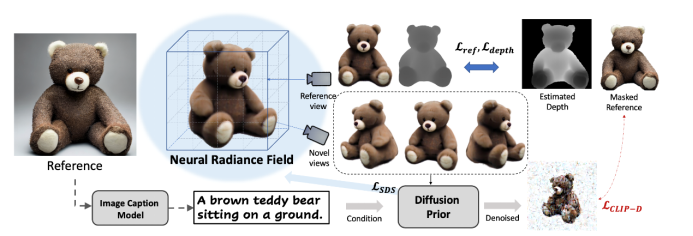
然而,只用文本难以描述一张图的全部信息,这会导致生成的 3D 模型难以和参考图像完全对齐。因此,为了增强生成几何模型和图片的相关程度,论文额外约束了在扩散过程中的去噪图和参考图之间 的图像相似性,即约束了图像之间的 CLIP 编码距离。这一方法进一步有效提升了生成模型和图片的相似程度。
此外,论文还利用了从单张图估计的单目深度来避免一些几何歧义性,例如凹陷面等问题。然而,研究者认为,优化得到的纹理隐式场,难以完全重建出图片的纹理细节,例如小熊表面的绒毛纹和局部的颜色信息,在一阶段生成的结果中都没有体现。因此该方法提出聚焦于纹理精细化的二阶段优化过程。
在第二阶段,该方法根据第一阶段得到的几何模型,将参考图像的高质量纹理映射到 3D 空间中。然后着重于增强参考视角中被遮挡区域的纹理。为了更好地实现这一过程,该方法将一阶段的隐式表示导出到显式表示形式 —— 点云。与 Marching Cube 导出的噪声网格相比,点云可以提供更清晰的几何特征,同时也有利于划分遮挡区域和非遮挡区域。随后,该方法聚焦于优化遮挡区域的纹理。点云渲染采用了基于 UNet 结构的 Deferred-Renderer (延迟渲染器),并同样使用来自预训练扩散模型的先验信息优化产生遮挡区域的精细纹理。从左到右依次是参考图,一阶段优化得到的法向图和纹理渲染结果,二阶段纹理精细化后的渲染结果。
该方法还可以支持多种有趣的应用,包括可以对三维纹理进行自由编辑和风格化。以及用文本驱动产生复杂多样的三维内容。
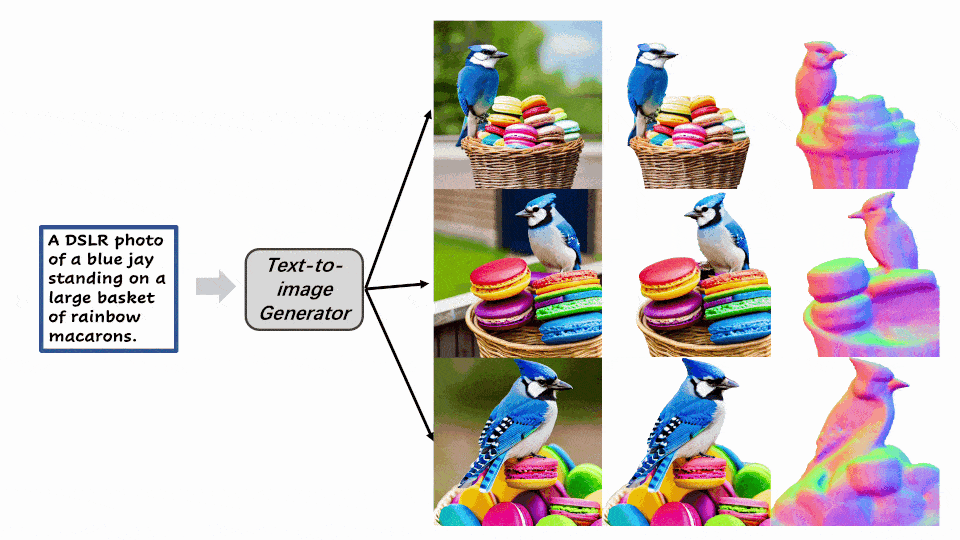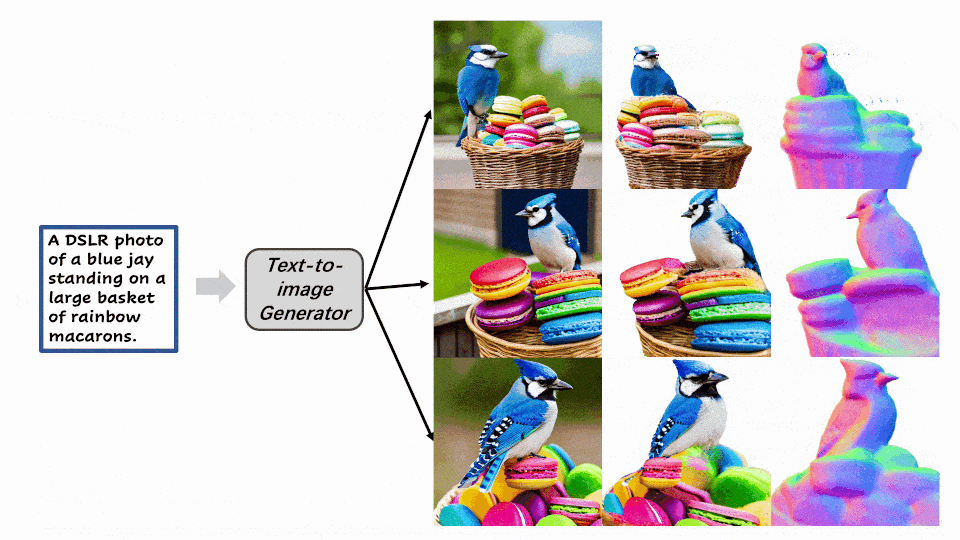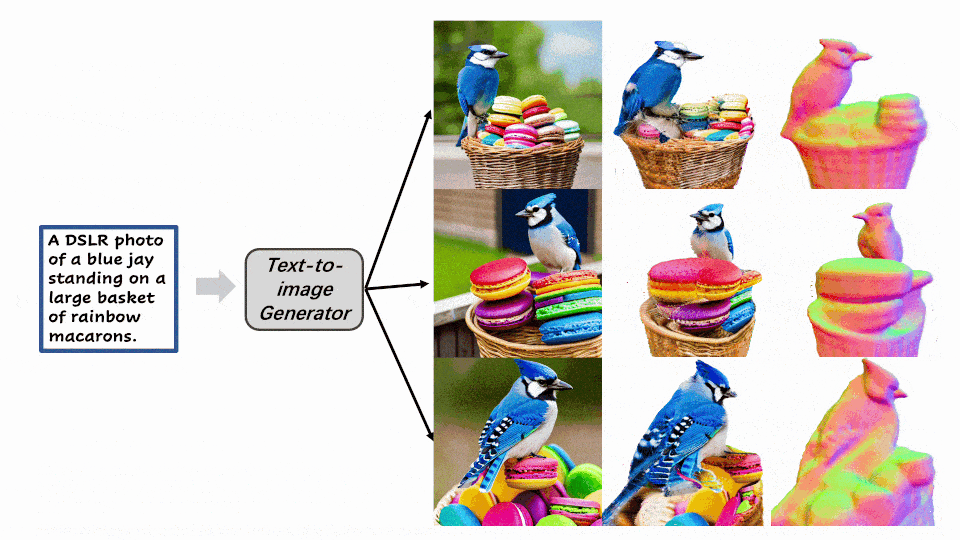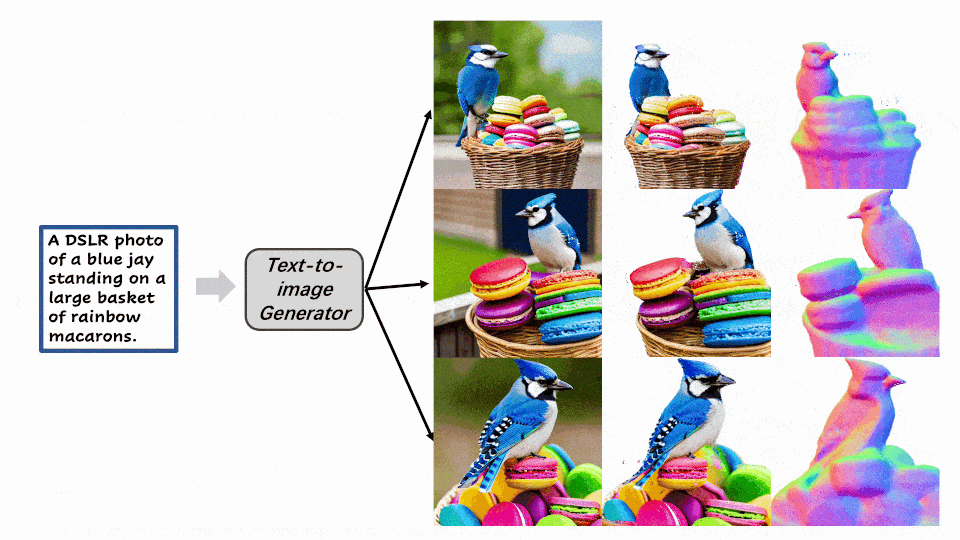
Make-It-3D作为首个将二维图片拓展到三维空间,同时保持了和参考图片相同的渲染质量和真实感的方法,致力于创作和二维图片视觉效果相同的三维内容。研究员们希望可以通过Make-It-3D这篇工作,引发学术界或工业界对于2D转3D这一方案更多的关注,加速三维内容创作的发展。对于方法的更多实验细节和更多结果,请详见论文内容和项目主页。












© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]