©作者 | 吴紫屹
单位 | 多伦多大学
研究方向 | 计算机视觉/Robotics
TL;DR
现如今, SOTA CV 模型往往从视觉信号中提取一个巨大的 feature map,然后直接加上各种 head 输出 task-specific output。但是,人类视觉系统在处理视觉输入时更加层次化,往往会先从图像、视频信号中识别出独立的物体(objects),然后在此基础上进行进一步的推理,例如分析物体间相互作用关系、从而预测物体未来运动等。在这一过程中,如何高效准确地提取物体是一个重要的难题。本文提出了一个基于 Slot-Attention 和 Diffusion Model 的方法——SlotDiffusion,可以无监督地从图像或视频数据中学习物体的概念(objectness)。我们的模型在 unsupervised segmentation,compositional generation 等多个任务上均取得了 SOTA 效果,同时可以用于 image editing,VQA,video prediction 等下游任务。代码已开源,详见 project page(https://slotdiffusion.github.io/)。SlotDiffusion: Object-Centric Generative Modeling with Diffusion Models论文链接:
https://arxiv.org/abs/2305.11281代码链接:
https://github.com/Wuziyi616/SlotDiffusion项目主页:
https://slotdiffusion.github.io/是的没错各位我又来了,这次做的也是 Object-Centric Learning(OCL)相关的研究,上回(SlotFormer [1],ICLR'23)提到终于蹭到 XXFormer 的热度 结果当时最火的东西早已是 Diffusion Model,这回算是圆梦 XXDiffusion(你醒啦, Segment Anything 已经打爆所有 segmentation model 了;拉到文末有碎碎念)闲言少叙,这次来介绍一下这篇工作,也是先投的 ICLR workshop 再投的 NeurIPS 正会,说来我还蛮喜欢 ML 的这种形式,有时候 workshop 讨论反而比主会 poster session 更有收获。
Background and Motivation
首先讲讲 OCL. OCL 的目的是从视觉信号(图像或视频)中无监督地分割物体,本文采用 Slot-Attention(SA)[2] 的大框架,如下图所示。一个 SA 模型往往由四部分构成:- Image Encoder 提取 feature map;
- Slot Attention 在 feature map 上进行 soft feature space clustering 得到物体划分,具体做法是 iterative cross-attention,这样得到的 attention map 作为 segmentation mask,而 output feature vectors 可以认为包含了各个物体的信息(位置,颜色,大小形状,etc.);
- Predictor 在视频数据上才有用,这里不重要;
- 本文研究的重点,Slot Decoder,因为 OCL 是无监督学习,因此监督信号往往是 input reconstruction loss,最原始的 SA,SAVi [3] 使用 DeConv-based CNN decoder,直接重建 raw pixels,然而这一简单的设计只在 synthetic data 有效;SLATE [4],STEVE [5] 以 VAE token 作为重建目标,使用 Transformer decoder 进行 autoregressive reconstruction。相较 SA 和 SAVi,SLATE 和 STEVE 大幅提升了无监督物体分割的性能,甚至能够在 real-world data 上成功。
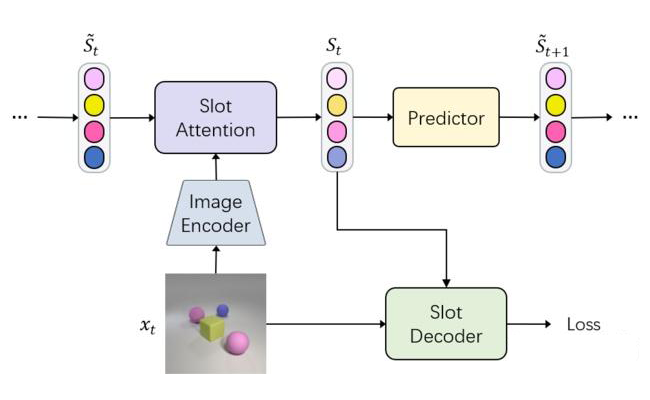
▲ Fig.1 A general framework for Slot-Attention based models
那么 OCL 有什么用呢?不谈 Introduction 里都会提到的 human-like perception,interpretable,data-efficient 这些虚的,OCL 本身提供了无监督物体分割,学习到的 object-centric representation 也可用于下游任务例如 VQA,visual generation(见下图),总的来讲,object-centric 作为一种 structured inductive bias,确实可以在特定应用上取得比一个巨大 unstructured feature map 更好的效果。

▲ Fig.2 Application of object-centric models: image editing (left), video prediction (right)SlotDiffusion 这篇工作的直接 motivation 来自 SlotFormer(SF)——简单介绍一下,SF 是一个视频预测(video prediction)模型,具体做法是先从视频中提取 object slots,然后用 Transformer 预测 future slots,由于显示建模了物体,模型可以更好的模拟物体之间相互作用,从而更好地学习 dynamics。Video prediction 的最终目标是生成视频 也即一系列图像,因此我们需用 Slot Decoder decode future slots back to frames。这在简单的数据集上 work,例如上图右侧 2D 纯色背景和物体构成的视频;然而一旦数据变得复杂(e.g. 更多的纹理信息),如下图两例(左侧为原始视频,右侧为 STEVE decoding 结果),不难看出虽然物体的运动大致预测正确,但 STEVE 重建的图片有极其严重的扭曲失真,生成质量相当糟糕。因此本文目标就是提升 slot-to-image decoding 的质量,从而让 object-centric models 更好地服务于 generation tasks.
▲ Fig.3 STEVE slot decoding results on Physion dataset
Previous Slot Decoders
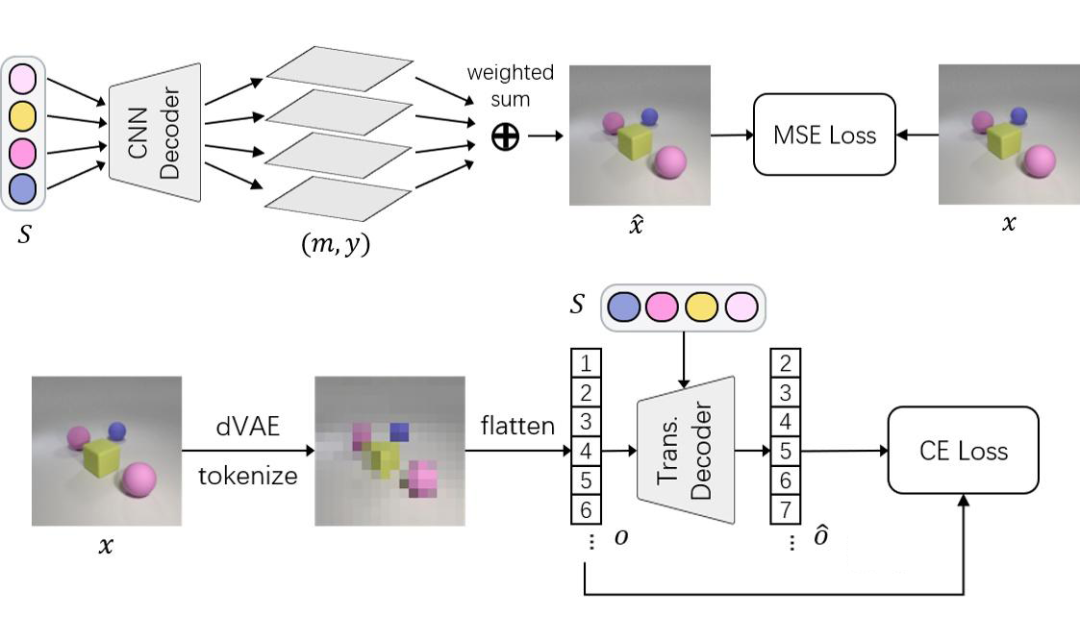
▲ Fig.4 Previous slot decoders: CNN-based (top) and Transformer-based (bottom)
这里我们来分析此前两种 Slot Decoder 的得失:- SA,SAVi 的 CNN decoder(又称 mixture-based decoder)直接重建 raw pixels,这会导致模型学习太过 low-level 的信息如 color statistics,也因此只能分割单一颜色背景下均匀着色的简单物体,一旦上点强度例如下图左稍微复杂点的纹理,模型直接就不 work;
- SLATE,STEVE 的 Transformer decoder 本身性能就比 CNN decoder 更强大,加之使用 pre-trained VAE token 这一 feature-level reconstruction target,包含更高级的语义信息,因此模型的训练信号更明确,能够学习无监督分割复杂场景下的物体,如下图右。

▲ Fig.5 Segmentation results of previous methods on CLEVRTex images: SA (right), SLATE (left)
然而, Transformer Slot Decoder 虽有良好的分割效果,其生成效果却堪忧,究其原因是这种 autoregressive generation 的模式,将图片展成一维序列,从左上角开始一个 patch 一个 patch 生成,忽略了图像其实是二维信号;同时,这种方式无法反复 refine 生成的结果,也容易造成图像不同区域 inconsistent。那么,是否有这样一种生成模型,它既有不俗的建模能力,又有强大的生成能力呢?答案自然是有的——Diffusion Model。
Method: SlotDiffusion
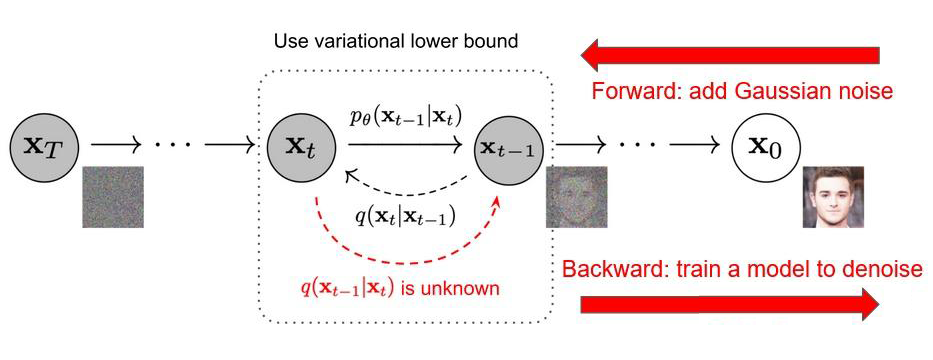
▲ Fig.6 Diffusion Models. Figure credit: DDPM
Diffusion Model(DM)可谓是近年最火爆的模型了,其原理简单而言就是把图像生成的过程从以往的一个 decoder 一步到位,拆解成了多步 denoise,通过反复把(noisy)image 输入一个 denoiser 预测 noise 来做生成。训练时我们通过往干净样本上加噪声得到训练数据,然后训练 denoiser 预测所加的噪声。这里最大的问题是,如何把 object slots 输入(condition)DM 来指导其重建正确的图像?受到最近 text-guided DM 的启发,我们提出可以把 slots 看做 text embedding——从形状上来说,text embedding 是一系列 1D tensors,slots 也是一系列 1D tensors;从语义上来说,text 往往是描述图像中各个物体的特征和背景,而每个 slot 恰恰也是 capture object information,object slots 其实是另一种模态的 “语言”,通过 slots 的组合,我们也可以描述丰富的视觉数据。因此,我们借鉴 LDM [6](Stable Diffusion)的做法,通过 cross-attention 将 slots 与 denoiser feature map 进行融合,从而引导 DM 预测正确的噪声。同时我们也在 VQ-VAE latent space 中进行去噪,latent space 较低的分辨率大大降低了 SlotDiffusion 的计算量和训练时长。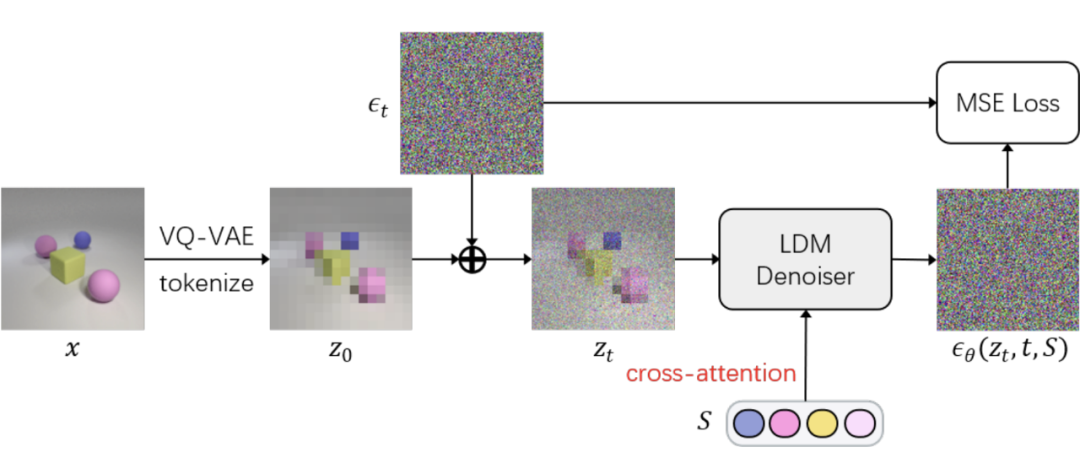
▲ Fig.7 Architecture of SlotDiffusion's Slot Decoder
Experiments
本工作曾被朋友一针见血地指出 “方法已经这么 A+B 了,实验总得健全一点吧”,于是堆了不少:
Unsupervised Segmentation & Compositional Generation
虽然 SlotDiffusion 的重点是放在更好的生成质量上,我们同样取得了 SOTA 的无监督物体分割结果。不过本节还是主要展示一些生成的结果。Compositional generation 的原理很简单,我们首先用模型从数据集中的每张图像提取 object slots,每个 slot 都代表了一定的语义信息,可以是一个物体,或者人脸五官、头发。我们将 slot 视为 “Visual Concepts”,通过组合来自不同样本的 slot 并 decode,就能生成新的样本。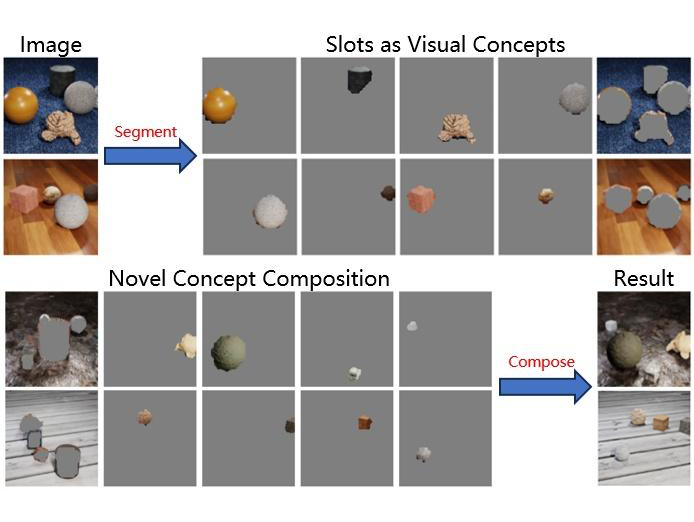
▲ Fig.8 The mechanism of compositional generation
Quantitative results(FID, FVD, etc.)就不放了,直接上图:
▲ Fig.9 Compositional generation results on CLEVRTex (left) and CelebA (right)
SA 直接 reconstruct raw pixels,因此生成结果十分模糊;SLATE 的 autoregressive Transformer 会生成扭曲变形的物体;SlotDiffusion 受益于 DM 强大的生成能力,生成质量最佳。得益于 slot object-centric 的性质,我们可以很直观地进行 image editing,只需增/删/替换相应的 slot,再丢进 Slot Decoder,就能得到想要的结果,如下图展示的物体操作和换脸:
▲ Fig.10 Image editing results: object manipulation (left), face replacement (right)
VQA & Video Prediction
同样只放几个 video prediction 的例子,SlotDiffusion 结合 SlotFormer(SF)既能保持长期物体属性的稳定(不会消失/变色变形),同时也可以习得正确的 dynamics,帮助下游 VQA 任务。
▲ Fig.11 GT (left) and video prediction results of baselines, and SlotDiffusion+SF (rightmost)
Scaling Up to Real-World Data
OCL 经常被 reviewer 攻击的一点是不 scale,只能玩玩 toy data。不过这篇文章 [7] 提出如果用上 SSL pre-trained model 如 DINO,OCL 也是可以在真实世界图像上 work 的。我们仿照他们的做法,将 Image Encoder 换成 DINO ViT,成功地在 COCO 和 VOC 上取得了不错的分割效果。除了标注的物体,SlotDiffusion 还能发现一些未标注但有意义的区域,例如小路、键盘、屏幕等等。▲ Fig.12 SlotDiffusion can segment real-world images from COCO (left) and PASCAL VOC (right)
Ablation Study
最后提一个比较有趣的 ablation study。DM 中有一个重要的参数 即 total denoising step,我们分析模型在不同 下的性能。不难想象,更大的 将生成过程拆解为更多步 denoise,因此生成效果应该是提升的;不过我们发现更大的 也会导致分割效果的下降。
这其实很像 SSL 里的一个发现,即 pretext task(在合理的范围内)越难,学到的 representation 就越好——在我们的例子里 越小,denoise 越难,因此学到的 object-centric representation 越好,于是无监督物体分割效果更佳。显然,这里有一个 generation-segmentation trade-off。

▲ Fig.13 Ablation study regarding the total number of diffusion steps T Limitations & Future Works
感谢你看到这里!接下来完全是一下想法和碎碎念,看看就好,如果有启发欢迎在评论区讨论:OCL 的终极目标大抵是两个:1)无监督分割 real-world data;2)通过 slot 组合生成逼真的 real-world data。现在 1)其实勉强算实现了,借助了 DINO 这一强大的 feature extractor,但说实话 DINO feature map 直接做 clustering 效果都挺不错的,多做一步 Slot-Attention 肯定也差不到哪去,所以完全不 surprising。
但是 2)现在还是完全不行,在 COCO 上的生成效果极其感人。一个可能得解法是用 pre-trained DM 例如 Stable Diffusion(SD),我有尝试过 fine-tune SD + Slot-Attention,但效果一般,有待未来的工作研究。Unsupervised object segmentation 其实是一个很 ambiguous 的问题,synthetic data 中 object 就是一个个 3D assets,很明确;但 real-world data 中什么是 object?从上面 COCO results 中不难看出,模型 1)有时会分割整个物体(电脑);2)有时会分割物体的部分(电脑 --> 屏幕、键盘),这一 part-whole ambiguity 本身是无解的(吗?),除非有 task signal 告诉模型怎样是最优解,例如我要移动整个电脑,那 1)是好的;如果我是要开合电脑,那 2)是好的,这也说明我们应当更多地把 OCL 和 downstream task 结合起来,例如 RL,robotics manipulation。此外 SAM output 3 masks per-pixel 的做法也是一个解决 part-whole ambiguity 的好思路。最后还是那个老问题,我们到底需不需要 object-centric representation。Object-centric inductive bias 是好的,在很多任务上更佳 data-efficient,interpretable,这我相信。但现在有了 SAM,我完全可以 predict object mask + RoIPooling 得到 object-centric features,还有必要从头学 slot 吗?SAM 当然不是万能解药,也需要特定 domain fine-tune,但看看 slot model 现在的效果... 我选择 SAM 老师!最后的最后,既然都看到这里,我们的代码已开源,欢迎 star 欢迎试用!https://github.com/Wuziyi616/SlotDiffusion
[1] https://zhuanlan.zhihu.com/p/596942670[2] https://arxiv.org/abs/2006.15055[3] https://slot-attention-video.github.io/[4] https://sites.google.com/view/slate-autoencoder[5] https://sites.google.com/view/slot-transformer-for-videos[6] https://arxiv.org/abs/2112.10752
[7] https://arxiv.org/abs/2104.14294
[8] https://arxiv.org/abs/2209.14860

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
