

任务定义
模型遗忘是针对于特定的数据而言的,让模型遗忘掉某个数据之后模型的表现能力,应该等同于这个数据没有参与模型训练时模型的表现能力。
Machine Unlearning 这个词其实最火的应该是顶会 S&P-42nd IEEE Symposium of Security and Privacy 上的同名工作:Machine Unlearning(arxiv),因为这整个领域比较新颖,所以知道的人不是很多,但却是一个非常有潜力的研究方向。
一方面,单从任务本身而言,Machine Unlearning 可以有效地保护用户隐私数据。在如今很多应用中,公司都会使用用户的数据去训练模型,而用户又有权力要求公司停止使用他们的数据,当用户发出“被遗忘”要求时,可以等价于模型的训练集发生了变化,如果每次用户要求“被遗忘”时都要重新训练一遍模型,这个时间开销想想都是不可接受的。而 Machine Unlearning 这一领域研究的方法可以探究如何快速高效地达成“敏感数据遗忘”这件事情,从而可以有效地满足用户需求,或者是保护重要的敏感数据。
另一方面,Machine Unlearning 领域中有很多工作从数据对于模型的影响方面开始着手,进一步挖掘出了各种数据,在模型收敛时会贡献怎样的梯度。这件事当然可以有助于更好地达成 Machine Unlearning 的目的,但同时也在 Noisy Data Detection,Less Data Equal Effectiveness 等任务上具有很好的表现能力。
笔者在阅读了近 4 年来大多数 Machine Unlearning 的文章后,总结了 Machine Unlearning 目前两大主流方法,并在这两个方法上各自介绍一篇 2022 年中稿的顶会论文。

方向总结
1. 参数遗忘(粗略遗忘):这类方法会通过直接调整模型的参数,消除遗忘数据对于模型的影响。
2. 剪枝训练(精确遗忘):这类方法会考虑重新训练模型,但是会加入各种各样的剪枝方法让减小模型重新训练的开销。

方向一:参数遗忘

论文名称:
PUMA: Performance Unchanged Model Augmentation for Training Data Removal
AAAI 2022
Borealis AI
https://www.aaai.org/AAAI22Papers/AAAI-10608.WuG.pdf
一句话摘要:从理论的角度探究了每个数据对于模型的影响,从而可以在遗忘的时候更好地消除掉需遗忘数据的影响。
2.1 方法
1. Machine Unlearning 建模:
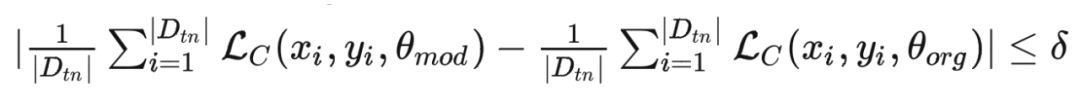
其中 表示的是原始的模型参数, 表示的是遗忘之后的模型参数, 表示的是整个训练集。这个式子表示,期望模型能够以很小的代价( )完成模型参数 的调整从而实现遗忘。
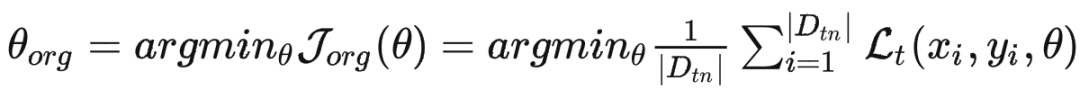
这个式子是原始模型的训练式子,其中 可以理解为目标函数 的最优解。

这个式子表示的是用于遗忘的目标方程,其中 可以理解为目标函数 的最优解。 表示的是遗忘数据集,服从于 的要求。 表示的是加权数据点的权重向量——一般在模型训练的时候,我们可以理解为所有样本的权重都相同,但这篇文章需要通过调整各个数据的权重来弥补遗忘数据所带来的下游应用上的影响。
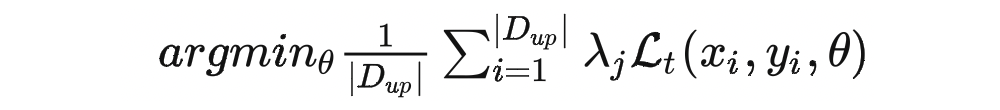
式子可以单独用目标函数 进行表示,后面还会继续用到这个表示方式。
当 足够小时(每个数据点对于梯度的贡献都非常得小),可以对 在 点进行泰勒展开,展开式如下:
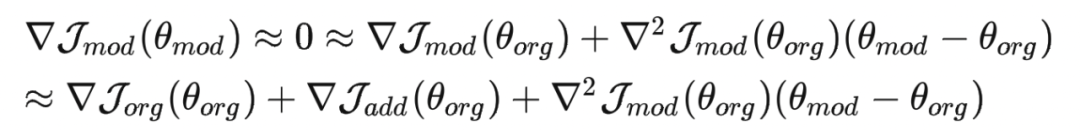
将上面的泰勒展开式进行一些变形之后可以得到遗忘前后模型参数的变化
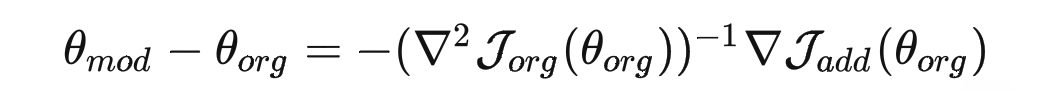
上面的式子中的 Hessian Matrix 发生了一些变化:
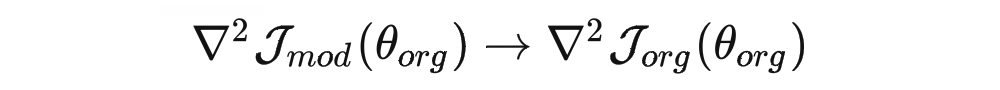
论文中认为这种变化是可以接受的,首先因为 够小时,Hessian Matrix 作为泰勒展开式的二阶项,其实这种变化所引发的差异微不足道;其次,计算 Hessian Matrix 的过程其实是一个迭代的过程,中间引入的噪音会很大,而引入论文中提出的这种变化反而不会带来太多的噪音。
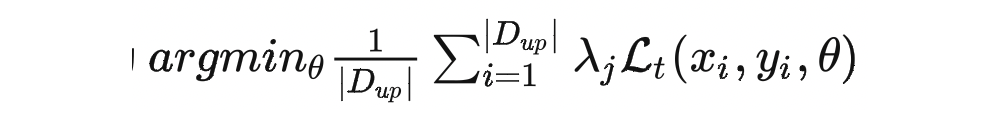
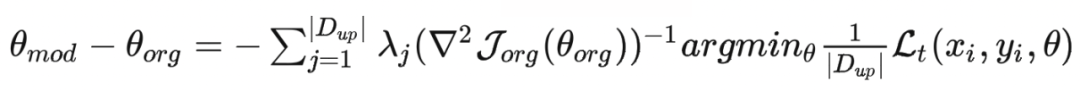
4. 遗忘前后模型效果的变化:模型的表现很难具体地用一个明确的函数建模出来,所以粗略地使用 来表示根据特定参数,模型的表现能力。则可以将遗忘前后,模型在下游应用上表现能力的变化建模为:
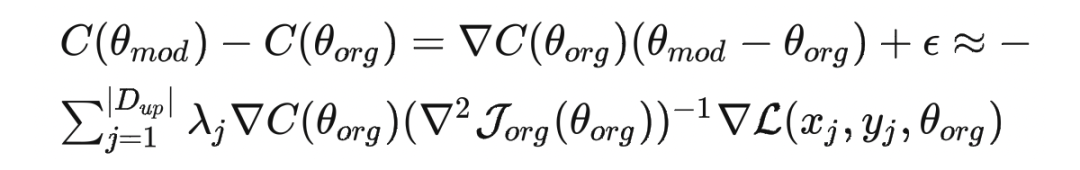
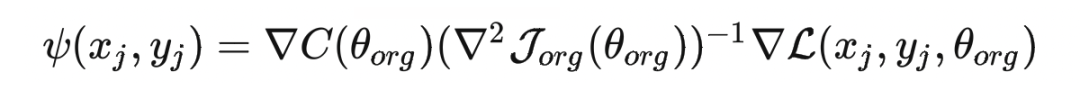
根据上述建模,可以将遗忘过程的目标函数写为如下形式:
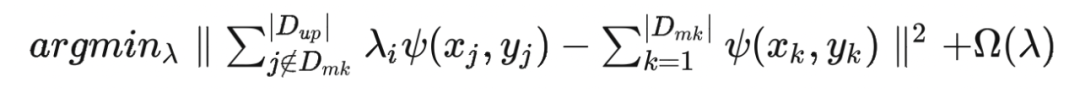
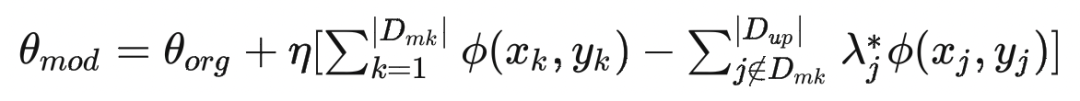
最后,将 PUMA 计算出来的每个数据点对于模型训练时的梯度贡献进行可视化:
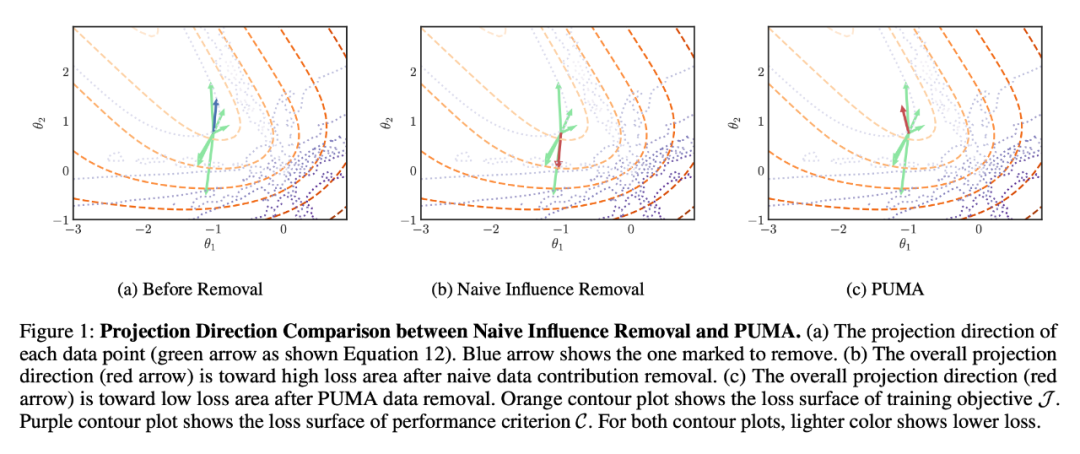
PUMA 是否可以不降低模型性能:图表里的数据比较直观,这里就不做过多释了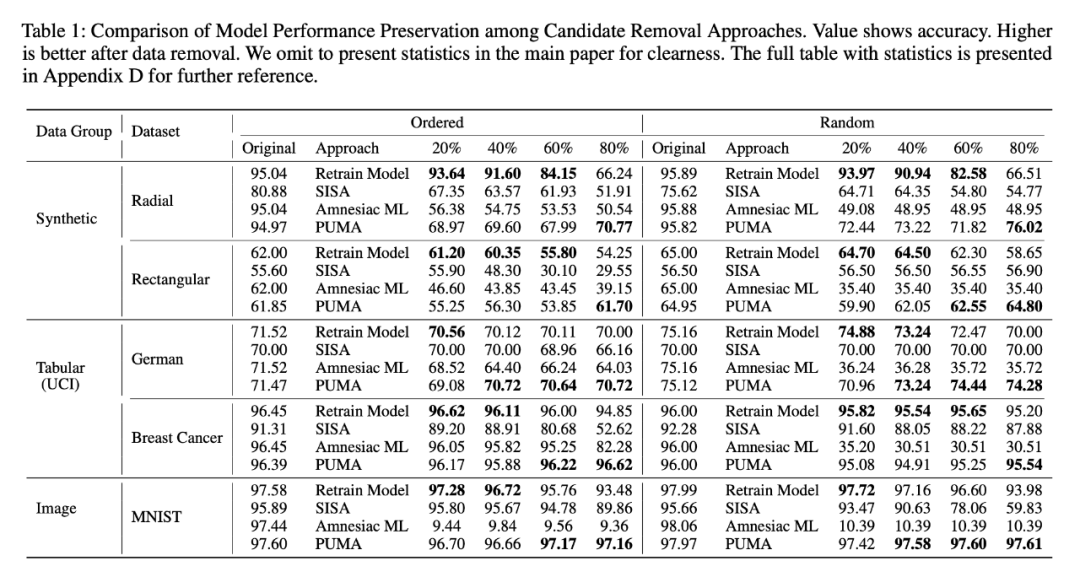
PUMA 是否能够成功遗忘一整个类的数据:成功删除了上面所有的 x 类,表面 PUMA 具有遗忘一整个类的能力。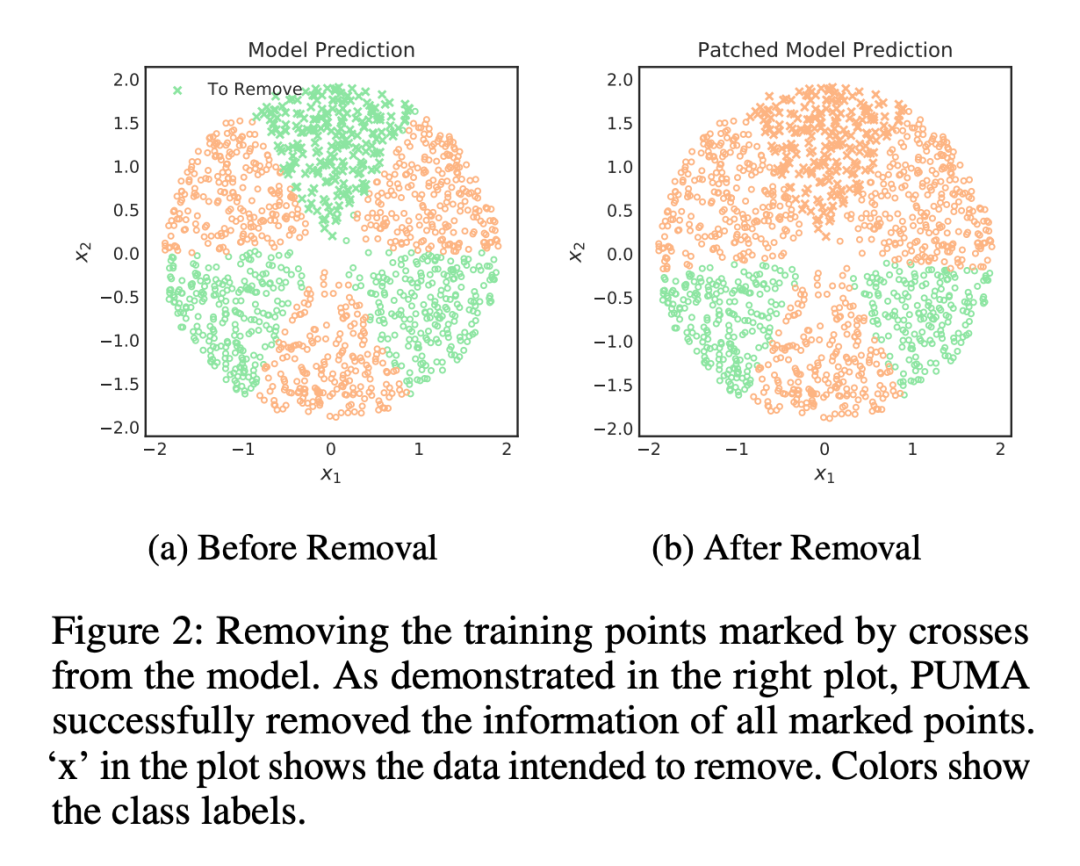
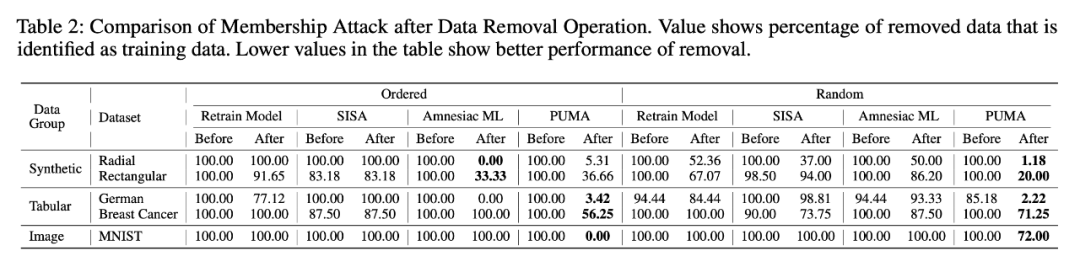
PUMA 是否能够遗忘特定的数据:遗忘的数据有多少还能被检测模型检测到在训练集里出现过。
PUMA 与 baseline 的运行效率进行对比: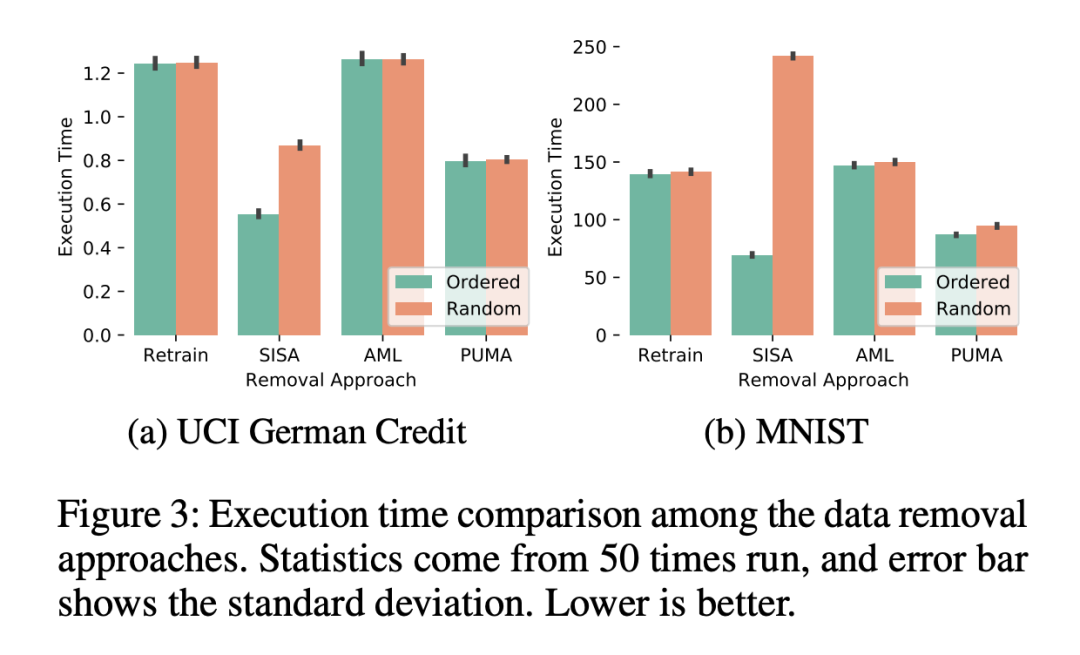
PUMA 对超参数有多么敏感:PUMA 中有个超参数 η,这个参数是在收敛过程中用来调整投影步骤的,太过巨大的 η 将会违反泰勒展开的假设,所以此处超参数的调整也只是对于下游应用影响的观察,其中 Resistance 表示移出率、Accuracy 表示泛化能力。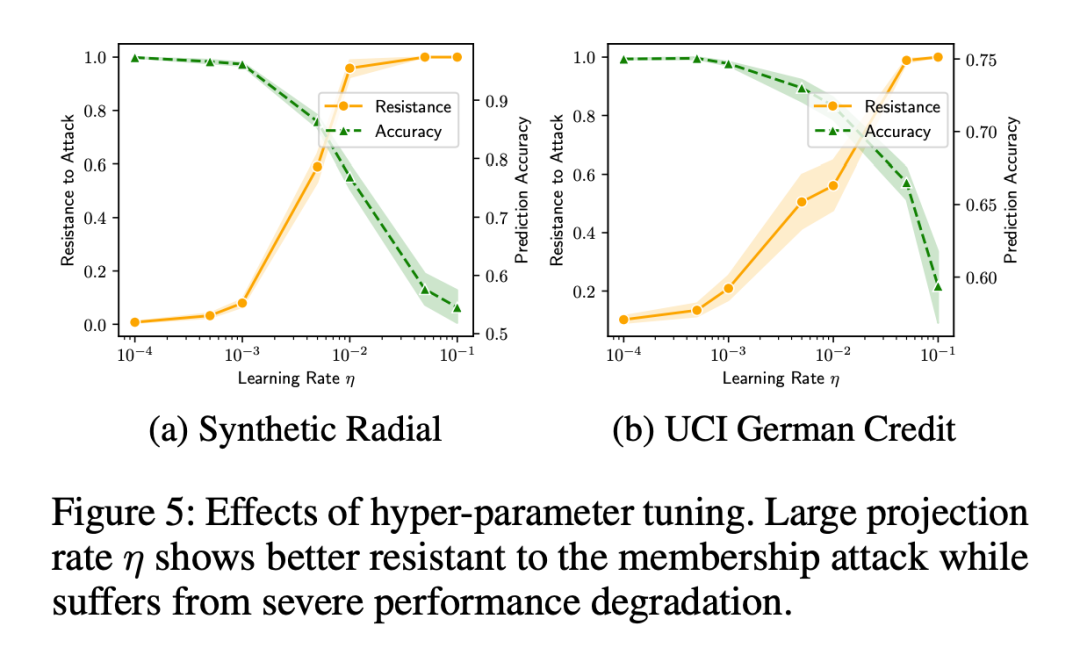
PUMA 能否估计出错误的标记样本:文中并没有说该如何看这张图,对于其中的对比方法也没有进行详细的介绍。我认为,检查越少的 Inspected Fraction 就能得到越高的 Discovered Fraction 则说明模型效果越好。所以当曲线更靠近 Optimal 的时候,模型效果最好。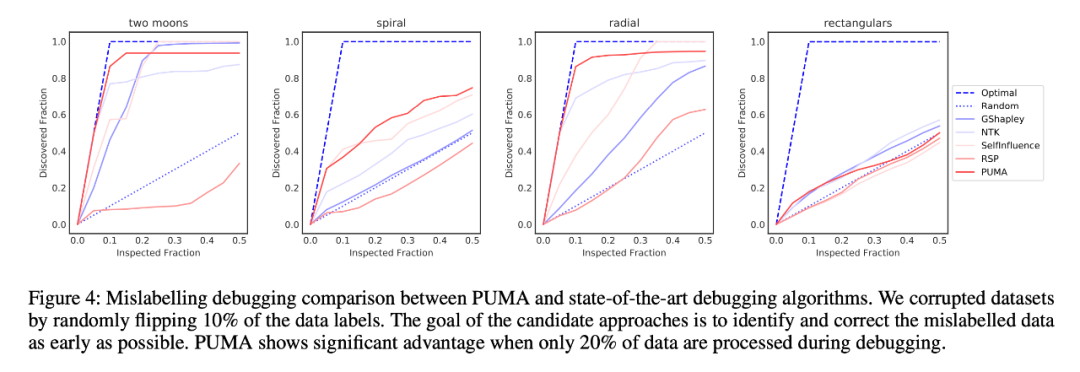
模型运行的时间开销:单位为秒,可以看出 PUMA 不仅效果好,运行速度还高。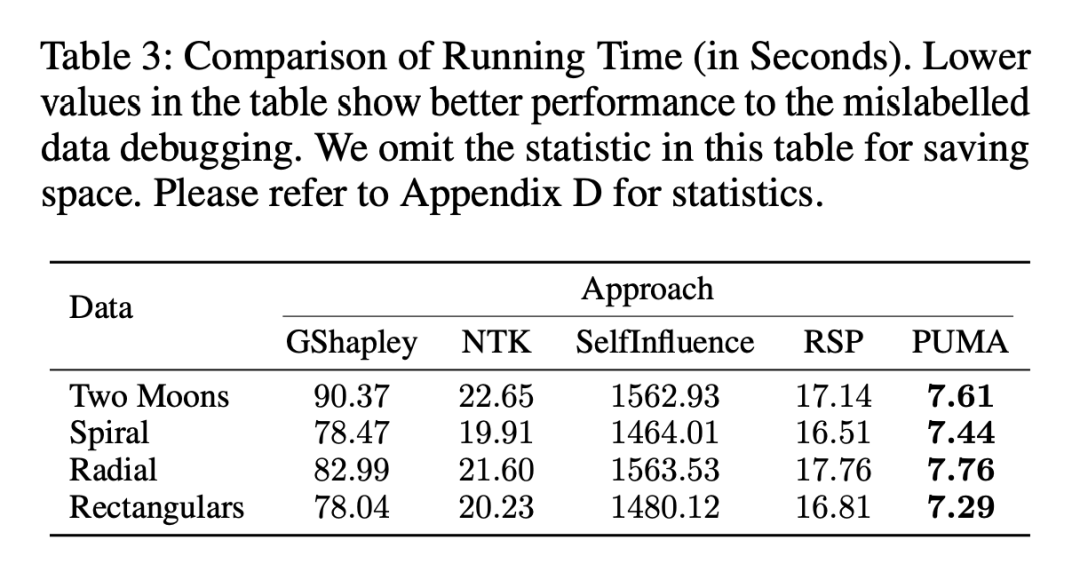

方向二:剪枝训练

论文名称:
ARCANE: An Efficient Architecture for Exact Machine Unlearning
IJCAI-2022
Xidian University
https://www.ijcai.org/proceedings/2022/0556.pdf
一句话介绍:本文将一个大的数据集分为一堆堆小数据集,在遗忘请求到来时,只对遗忘数据所在的数据集对应的模型进行再训练。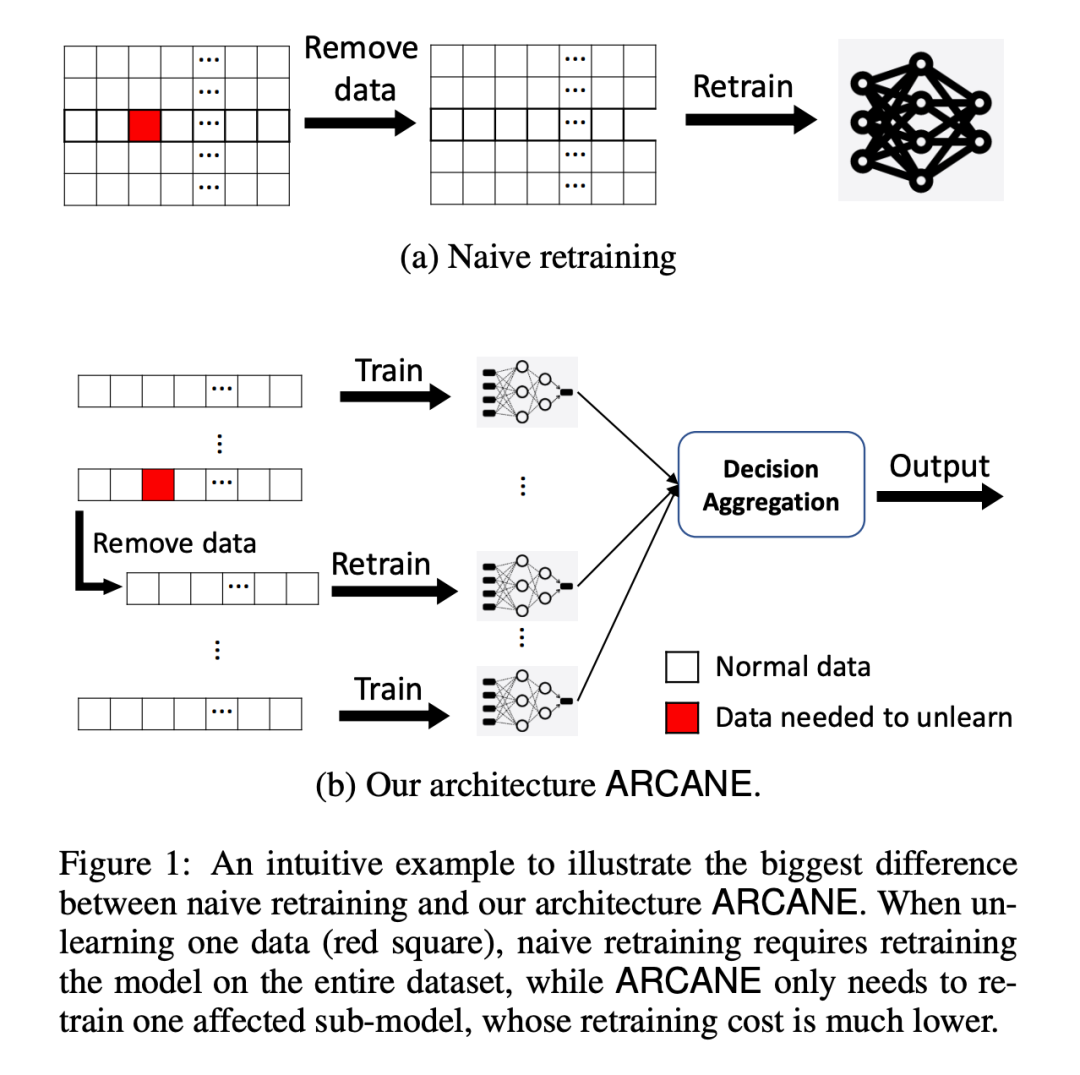
框架图如下所示,注:我没有完全按照论文中的意思进行翻译,主要加入了一些我自己的理解进行解释,让整个过程更加通俗易懂一些。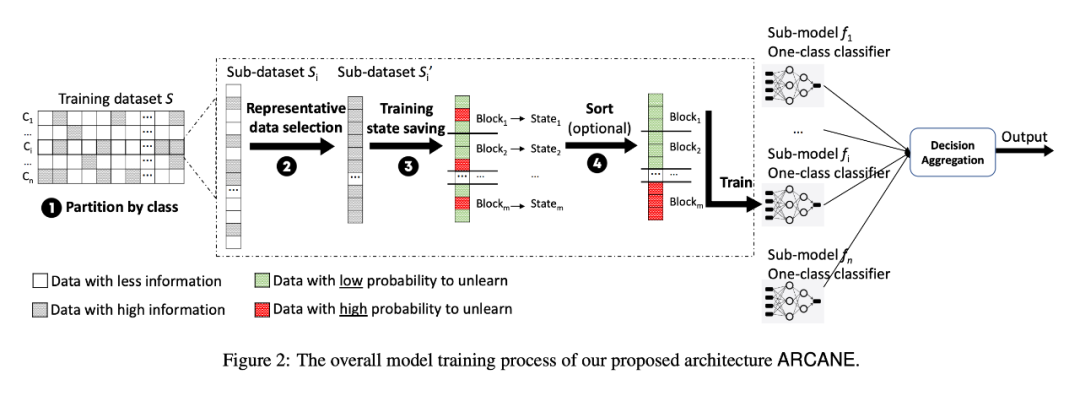
1. 粗分组(Partition by class):根据数据的类别标签对数据进行分类,每个类别的数据分为同一类。2. 选信息量大的数据(Representative Data Selection):利用类间数据的关系计算数据的信息量(Joint Entropy),每次训练时只将一个类内信息量最大的n个数据拿出来参与训练,计算公式如下:
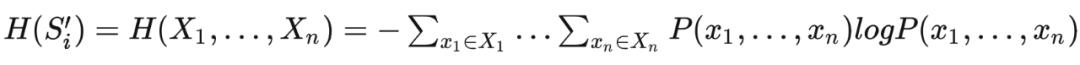
这里的 表示的是粗分组 中各取一个样本,文字解释一下这里的公式——将所有可能的数据组合的熵都算出来,挑选其中熵最大的若干数据组合加入训练。笔者认为这里的计算开销将会极其庞大,本文并没有对这块儿的计算开销进行深入的讨论。当 forget request 到来时,重新计算发生变化的类内数据信息量,然后重新训练模型。这里笔者认为论文存在一个计算错误,重新训练的样本数应该是 个样本,而不是 个样本:

3. 细分组(Training State Saving):将粗分组的分出来的数据集进一步切分成若干小块,这样可以进一步减少 retrain 的开销。同时将其他模型的参数引入 retrain 模型,可以做得快速 retrain:比如第 j 块的数据发生变动,则只需要将第 j-1 块的数据学习出来的模型参数用来初始化第 j 块,然后用第 j 块的数据重新训练。4. 数据排序(Sort):类似于操作系统里的进程排序,也类似于数据结构中的栈:即将经常会发生变化的数据放到一个(或者若干个)数据集里,不经常发生变化的数据集放到一个(或者若干个)数据集里。模型架构:原文有讲他们的模型架构,但笔者认为不重要,所以有兴趣的读者可以考虑看一下他们的原文。
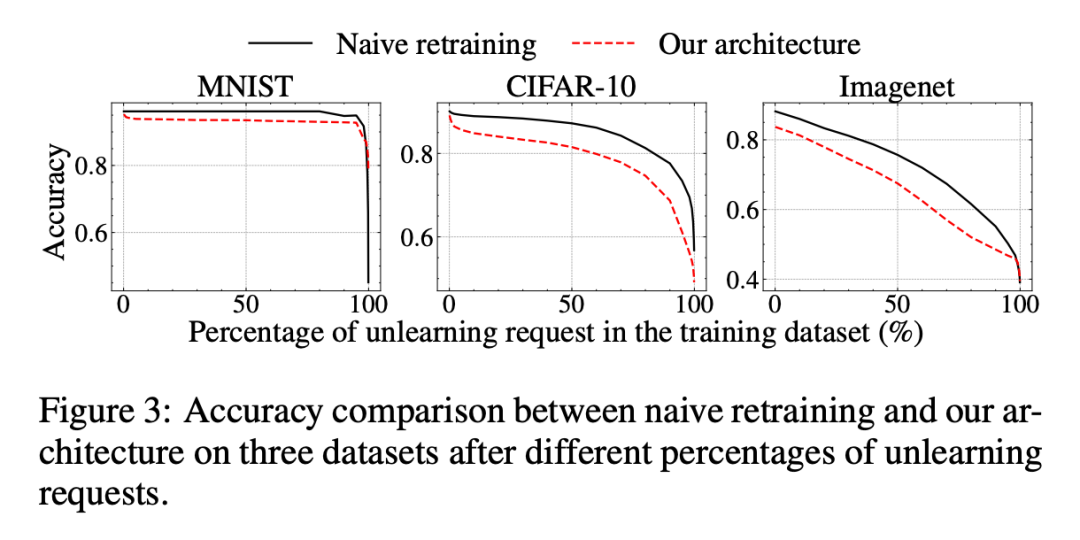
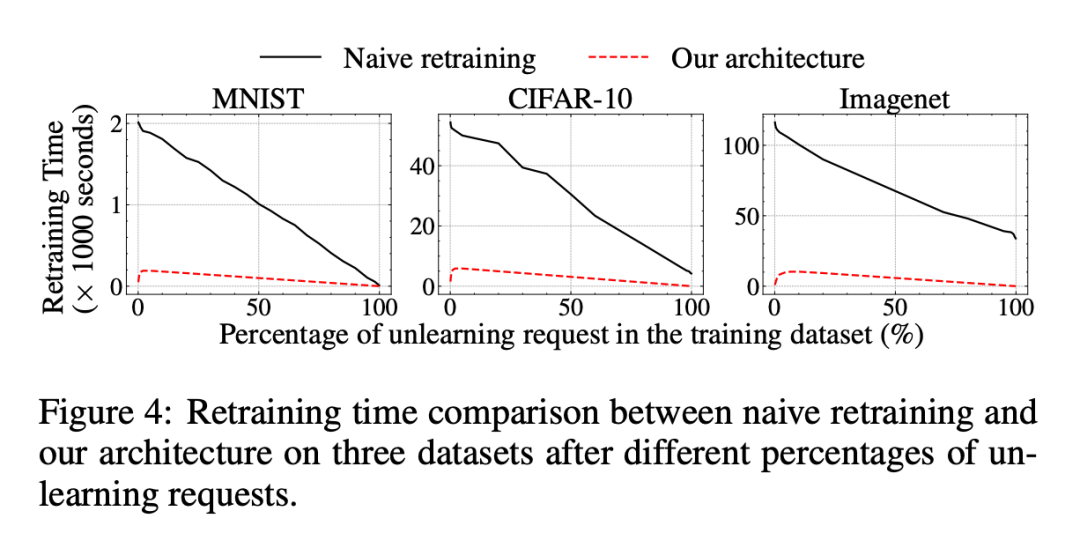

▲ 总体评估-Retrain Samples Number对于数据选择的消融实验:选择不同比例数据时,模型的 Accuracy 和 Time Consume:这块儿的实验并不是很明朗,黑线和红线代表的内容并没有写出,而且没有在此讨论计算开销。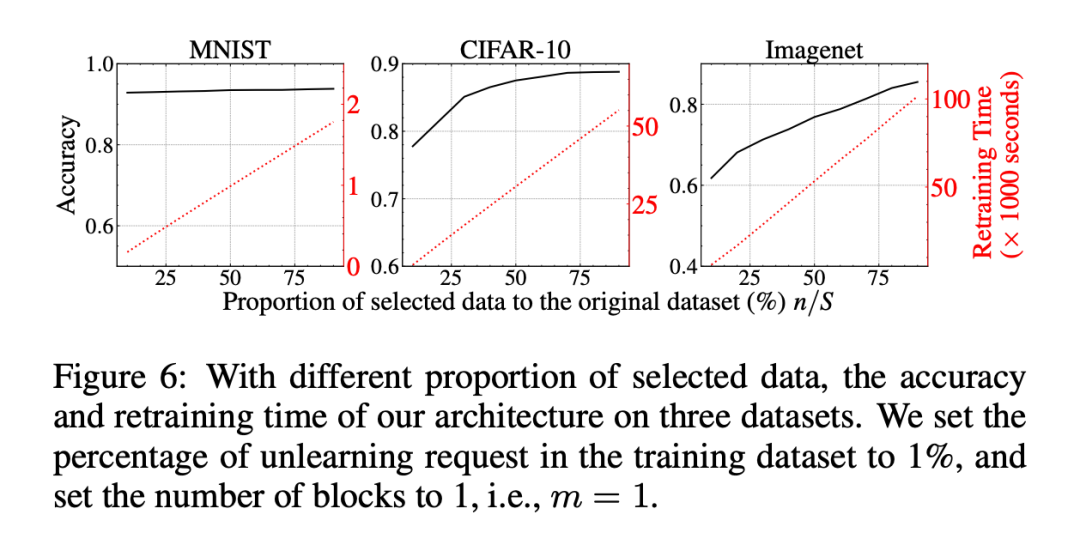
▲ Representative Data Selection的实验对于精分组的消融实验:不同 block number 的设置下,需要遗忘的样本个数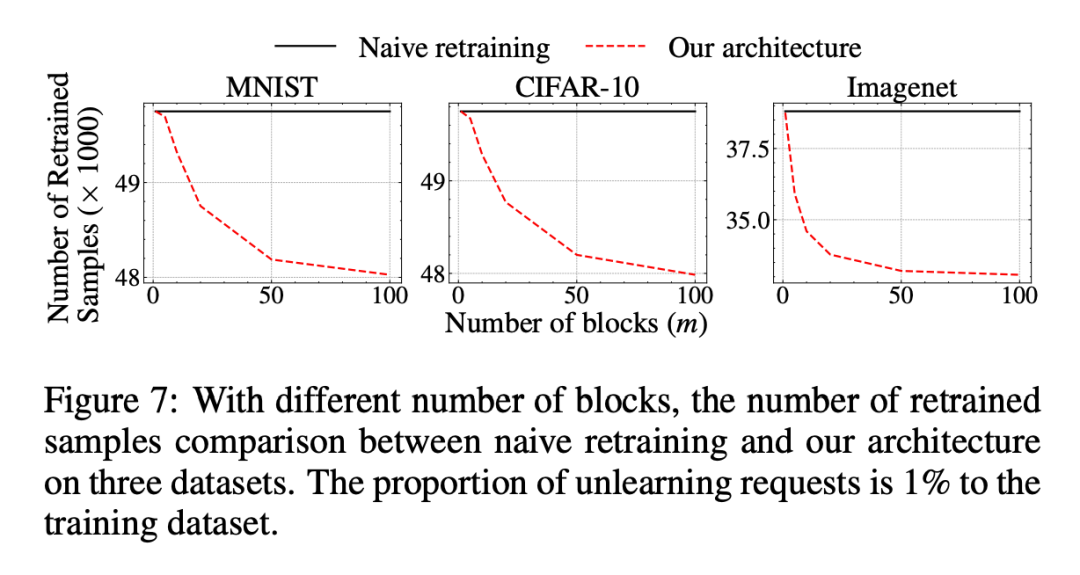
▲ Training State Saving的实验对于排序的消融实验:这里笔者有些没看懂,黑色的线根据解释应该为不加入排序的 ARCANE 方法,但起名为 Naive retraining 感觉会导致理解有些偏差(也有可能是笔者理解确实出现了错误)。对比的内容是随着 unlearning request 的增加,参与重新训练的样本数量:

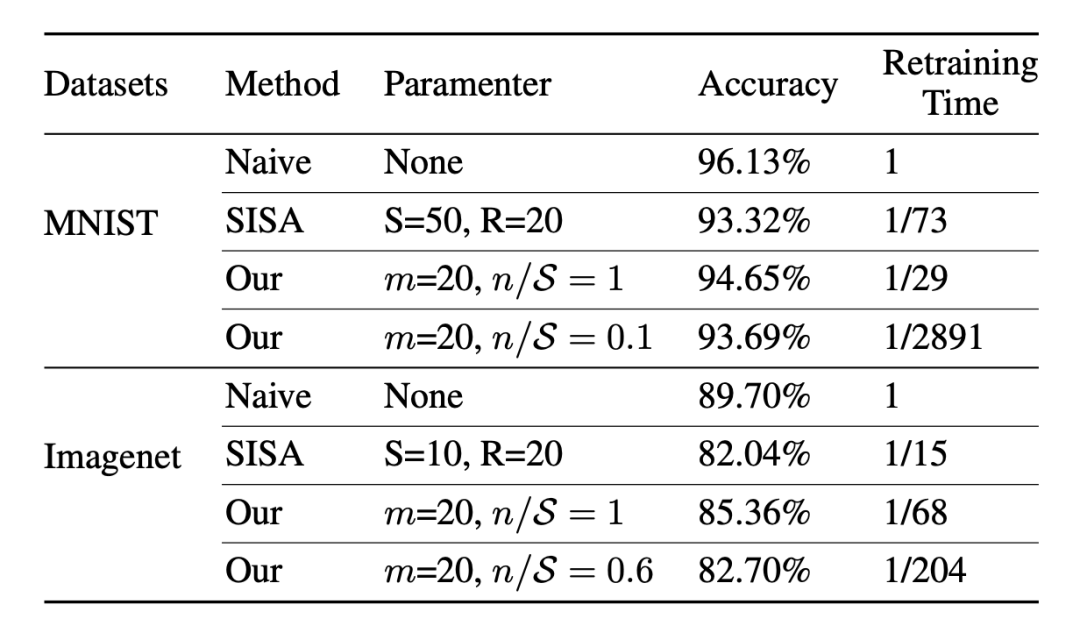
▲ SISA是我在论文最开始讲到的2021年的Machine Unleanring同名文章

总结
Machine Unlearning 是笔者最近调研到的,比较有意思,而且比较新的一个方向。对于数据保护,以及对于模型运行细节比较感兴趣的朋友可以了解一下。本文受限于笔者自身的能力,对于这两篇工作的总结,以及对于整个方向的总结若存在问题,或者其他对这个方向比较感兴趣的研究者,欢迎留言评论或者私聊我。

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
